���ھ���:
- Modern C++ ѧϰ�ʼǡ��������ԸĽ�ƪ
- Modern C++ ѧϰ�ʼ� ���� ��ֵ���ƶ�ƪ
- Modern C++ ѧϰ�ʼ� ���� ����ָ��ƪ
- Modern C++ ѧϰ�ʼ� ���� lambda����ʽƪ
- Modern C++ ѧϰ�ʼ� ���� C++���������
- Modern C++ ѧϰ�ʼ� ���� C++����ʽ���
Modern C++ ѧϰ�ʼǡ���C++����ʽ���
�ؼ���:lambda����ʽ������ʽ���
����Ŀ¼
����ʽ���
��֮ǰ��ϵ�������н��ܹ����������lambda����ʽ,��ƪ���¾����������ǵ���Ҫ��;��������ʽ��̡�
ʲô�Ǻ���ʽ���?
��ʲô�Ǻ��������?����ʵ��������ѧ�е�����.
f(x) = 2x^2 +x+3
g(x) = 3f(x) + 5 = 6x^2 + 3x + 14
h(x) = f(x) + g(x) = 8x^2 + 4x + 17
�����������ѧ����һ��,���ں���ʽ���,��ֻ�����������������ݺ�������ݵĹ�ϵ,����ѧ����ʽ�����dz���Ϊ�����������һ��ӳ��(map),���ú��������������ݺ�������ݵĹ�ϵ��ʲô���ġ�
�����Ϳ��Եõ����ں���ʽ���һ���ص�:
- ��״̬:������ά���κ�״̬������ʽ��̵ĺ��ľ�����stateless��
- ���ɱ�����:�������ݲ��ɱ�,�����������ݾ���Σ��,����Ҫ�����µ����ݼ���
������ô˵�е����,Ϊ�˸��õİ�������,�پ�һ���������:
int copy_add(int x, int y)
{
return x + y;
}
int nocopy_add(int& x, int& y)
{
x += y;
return x;
}
��������������ʵ���˶����������int����ֵ������Ӳ��ҷ��صĹ���,��һ������ʽ�Ƚϴ���ĺ���,��������������˵�ĺ���ʽ��̵��ص㡣�ٿ��ڶ�������,���������Ϊ����(����Ŀ��,Ϊ�˼���ֵ��������������,���������Ϊ����),��ʹ��������⡪����κ������ں����ڲ����ı䡣
��������Functional Programming in C++��(�dz��Ƽ�����)�и����˹��ں���ʽ��̵Ķ���:
Functional programming is a style of programming that emphasizes the evaluation of expressions, rather than execution of commands. The expressions in these languages are formed by using functions to combine basic values. A functional language is a language that supports and encourages programming in a functional style.
����˵:��OOP(���������)��,������������������,����Ŀ������㷨�IJ���,���Զ���Ĵ��������ں���ʽ���������Ҫѧ�����µ�˼����ʽ:ʲô������,ʲô�����,������Ҫִ����Щת��������ӳ��������
����ʽ���
�ڽ����˺������֮��,���dz���ʹ����˼�������ʵ�ʵ�����:�����и�vector�������ļ��е����е���,��Ҫͳ�������е��ʳ��ֵ�Ƶ��,���Ұ������ʸߵ������Ӧ���ʡ��ͳ������ʽ��̴�Ż���ôд:
void print_word(vector<string>& words) {
unordered_map<string, int> wordCount;
for (auto&& s : words) {
unordered_map<string, int>::iterator iter = wordCount.find(s);
if (iter == wordCount.end()) {
wordCount.insert({s, 1});
} else {
wordCount[s]++;
}
}
vector<pair<int, string>> reverseword;
for (auto it = wordCount.begin(); it != wordCount.end(); ++it) {
reverseword.emplace_back(make_pair(it->second, it->first));
}
sort(reverseword.begin(), reverseword.end(), [](const pair<int, string>& lhs, const pair<int, string>& rhs) {
return lhs.first > rhs.first;
}); // �߽���
for (auto& p : reverseword) {
cout << "word is " << p.second << ", count is " << p.first << endl;
}
}
Ϊ�������Ҫ�Ĺ���,��Ҫ�����¹������:
- �����еĵ��ʲ���unordered_map<string, int>��,��ͳ�Ƴ��ֵĴ���(unordered_mapҪ��map����Щ)
vector< string> -> unordered_map<string, int> - ��unordered_map<string, int>�еļ�ֵ��ת��Ϊpair<int, string>������vector
unordered_map<string, int> ->vector<pair<int, string>> - ������pair<int, string>����
vector<pair<int, string>> -> vector<pair<int, string>> - ����vector,������ʺ�ͳ�ƴ���
vector<pair<int, string>> -> void
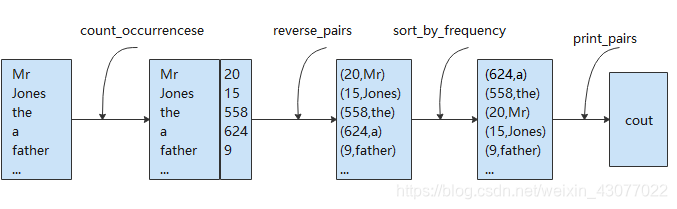
���Կ������ǿ��Բ�Ϊ��С�ĺ���(��������),Ȼ�������������:
unordered_map<string, int> count_occurrencese(vector<string> items);
vector<pair<int, string>> reverse_pairs(unordered_map<string, int> pairs);
vector<pair<int, string>> sort_by_frequency(vector<pair<int, string>>);
void print_pairs(vector<pair<int, string>> pairs);
�Dz��Ƿ�����ʲô����?�ǵ�,���ǿ���ͨ����ϵķ�ʽ�����������ʽ����ͬ���Ĺ��ܡ�
void print_words(vector<string>& words)
{
return print_pairs(
sort_by_frequency(
reverse_pairs(
count_occurrencese(words)
)
);
}
������������Ҳûɶ��,֮ǰ�Ĵ��벻Ҳ�ǰ�����˵��㷨����ʵ�ֵġ���ô���ǿ������³���:���ҵ����벻����vector,����һ���ļ�,ͳ�����е���Ƶ�ʲ����,����ֻ��Ҫ������һ������words: file -> vector<string>����ļ������ʵ�ӳ��,֮�����������ƽ�����ϼ���,�������ٶ�print_words�����ġ�����������ͳ�ƺõ�unordered_mapʱ��,Ҳͬ����
���ǰ�֮ǰ�����DZ�̷�ʽ��������ָ��ʽ���,���Ѻ���ʽ��̷�ʽ������������ʽ��̡��ɲ�ҪС����һ��˼ά��ת��,�������ı仯��ν���൱��ġ��������������,�������Ƕ���ʹ��һЩC++�е����,��ᷢ�����������:
template <typename C, typename T = typename C::value_type>
std::unordered_map<T, unsigned int> count_occurrences(const C& collection)
template <typename C, typename P1, typename P2>
std::vector<std::pair<P2, P1>> reverse_pairs(const C& collection);
�������������,����count_occurrences��ý��ܹ������κμ���,ֻҪ���ܹ��ƶ�������������(C::value_type)���Ӵ������پ�������������������,�����������ͳ���ַ������ַ��������б��е�����ֵ���ַ��������е��ַ����ȵȡ����������ĺ���Ҳ���������Ƶ���չ��
����ʽ��̵��ص�
����ʽ���������������Ϊ����ѧ�ϵĺ���,����һ��������ϵġ��ӳ��������ĺ���һ�㱻��Ϊ������(pure function),��Ҫ������ȷ��������νȷ����,��������ѧ������,f(x) = y �����������ʲô��������õ�ͬ���Ľ����������������еĺܶຯ��������ͬһ������,�ڲ�ͬ�ij����»�������ͬ�Ľ��,������dz�֮Ϊ������ȷ���ԡ���ν��ͬ�ij���,�������ǵĺ�������������е�״̬��Ϣ�IJ�ͬ�������仯��
���ǵĴ���Ҳ�����˺���ʽ��̵�һЩ�ص�:
- ��Ӱ�캯�������ֻ�Ǻ����IJ���,û�жԻ�����������
- ���صĽ�����Ǻ���ִ�е�Ψһ���,�������Ի���������Ӱ�졣
- ������ִ��û��˳���ϵ�����
- ������������ͨ�Ķ���һ�������ݡ�ʹ�ûء�
- ���������˵��ʽ��������ʽ����Ϥ����ʽ��̺�,��ᷢ��˵��ʽ����Ŀɶ��Ա�����ʽ����,�������,�ɸ����Ը��ߡ�
- ��״̬,û��״̬��û���˺�,����û��������û���˺�һ����
����ʽ����õ��ļ���
first class function(ͷ�Ⱥ���)
����ǰ������,�ں���ʽ����к�������ͬ����һ��,���Ա����ݡ�ʹ�á��ء�����Щ��������Ϊͷ�Ⱥ���, Ҳ���˽�����ʽ����еĺ�����Ϊһ�ȹ���
��C++�п���������һ����к�������,lambda����ʽ(�Ƽ��Ķ�[lambda����ʽƪ](https://blog.csdn.net/weixin_43077022/article/details/117926275?spm=1001.2014.3001.5501),�����std::function,std::bind�ȡ�
class filter{ // ��������
public:
students()
{
names.insert("abc");
names.insert("John");
}
bool operator()(std::string name) {
return names.find(name) == names.end();
}
private:
set<std::string> names;
};
// lambda ����ʽ,��auto����������������
auto add2 = [](int x) { return x + 2; }
map & reduce & filter
�ں���ʽ��̺ܶຯ���ѳ�Ϊ�˻����Ĺ��÷�(�ڲ�ͬ�����в�ͬ����),��**map(ӳ��)��reduce(�鲢)��filter(����)**Ϊ������Ϊ����Ҳ����Ϊ������������
map
Map��C++�е�ֱ��ӳ����transform(ͷ�ļ�< algorithm>)��������������Ҳ����ѧ�ϵ�ӳ��,��һ����Χ��Ķ���ת��Ϊ��ͬ����������һЩ����������person,����Ҫ����˵�������ӳ��,��vector<person> -> vector<string>
struct person;
vector<string> GetNames(vector<person> people)
{
vector<string> names;
transform(people.begin(), people.end(), back_inserter(names), [](const person& tmp) {
return tmp.name;
});
return names;
}
std::back_inserter�Ƕ�����ͷ�ļ� <iterator>��,���ڹ��� std::back_insert_iterator �ı�������ģ��[3].
reduce
Reduce��C++�е�ֱ��ӳ����accumulate(ͷ�ļ�< numeric>)�����Ĺ�������ָ���ķ�Χ��,ʹ�ø����ij��ºͺ�������,�����Ҷ���ֵ���й鲢[4]������������ƽ��ֵ��д��:
double average_score_1(const vector<int>& scores)
{
int sum = 0;
for (int socre : scores) {
sum += socre;
}
return sum / (double)scores.size();
}
double average_score_2(const vector<int>& scores)
{
return accumulate(scores.begin(), scores.end(), 0) / (double)scores.size();
}
����,�������ṩ���ĸ�����������������,�������´���ʵ���۳�:
int product = std::accumulate(v.begin(), v.end(), 1, std::multiplies<int>());
�����Ĵ�������Զ����ĵó�,�������ʽ��������˵,����ʽ����ڴ�����Ҫ�������Ķ���(��ͳ����ʽ��������Ҫʹ��for/whileѭ��,Ȼ���ڸ��ֱ����а����ݵ���������ȥ��)������,�ٿ�������֮ǰ˵���ĺ�������״̬��,����ζ�Ų���������,�����ڱ��������ԡ������ٴ���������ʱ,����ʽ����ܹ��ṩ�����ԡ�����C++17������std::reduce[5],�Լ�ִ�в���[6]���䲢�м����Ϊ���ܡ�
int main()
{
std::vector<double> v(10'000'007, 0.5);
{
auto t1 = std::chrono::high_resolution_clock::now();
double result = std::accumulate(v.begin(), v.end(), 0.0);
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> ms = t2 - t1;
std::cout << std::fixed << "std::accumulate result " << result
<< " took " << ms.count() << " ms\n";
}
{
auto t1 = std::chrono::high_resolution_clock::now();
double result = std::reduce(std::execution::par, v.begin(), v.end());
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> ms = t2 - t1;
std::cout << "std::reduce result "
<< result << " took " << ms.count() << " ms\n";
}
}
���ܵ����:
std::accumulate result 5000003.50000 took 12.7365 ms
std::reduce result 5000003.50000 took 5.06423 ms
filter
Filter�Ĺ����ǽ��й���,ɸѡ�����������ij�Ա����C++�е�ӳ����copy_if��partition��
auto is_female = [](const person& tmp) { return tmp.female; };
auto iter = std::partition(people.begin(), people.end(), is_female);
vector<person> females;
std::copy_if(people.cbegin(), people.cend(), std::back_inserter(females), is_female);
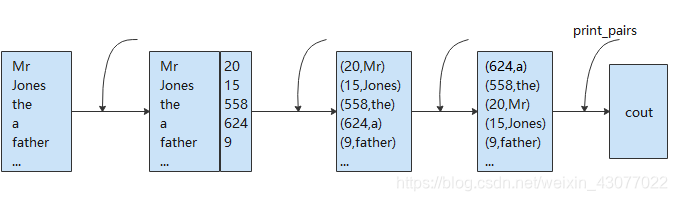
pipeline(�ܵ�)
�ü�������˼��,������ʵ����һ��һ����action,Ȼ��һ�� action �ŵ�һ����������б���,�ٰ����ݴ������ action list,���ݾ���һ�� pipeline һ��˳��ر���������������,���յõ�������Ҫ�Ľ����������ǰ����װ����������
void print_words(vector<string>& words)
{
return print_pairs(
sort_by_frequency(
reverse_pairs(
count_occurrencese(words)
)
);
}
pipeline �ܵ������Unix Shell�Ĺܵ��������������ɸ��������,ǰ������������Ϊ�������������,������һ����ʽ���㡣(ע:�ܵ�������һ��ΰ��ķ���,��������ѧ����KISS �C ��ÿ�����ܾ���һ����,�����������������,����������ƴװ���ø�Ϊ��ֱ�ۡ�)
����shell����:
ps auwwx | awk '{print $2}' | sort -n | xargs echo
�鿴һ���û�ִ�еĽ����б�,�г����Ժ�,Ȼ��ȡ�ڶ���,�ڶ��������Ľ��� ID,�Ÿ���,�ٰ�����ʾ������
��C++20������Χ��(ranges)֮��,����ʹ��operator |����������Χ�������հ�����Ľ�������ڴ�֮ǰ���ǿ��Գ������عܵ���,�ﵽ���Ƶ�Ч�����������ӽ�Ϊ��˵���������
template<typename T, typename F>
auto operator | (T t, F f) -> T
{
return f(t);
}
auto f = [](const int& a) {return a + 1;};
auto g = [](const int& a) {return a * 2;};
auto h = [](const int& a) {return a - 1;};
auto y = 3 | h | g | f;
currying (���ﻯ)
��һ�������Ķ�������ֽ�ɶ������,Ȼ��������װ����,ÿ�㺯��������һ������ȥ������һ������,����Լ����Ķ����������˵���Ǻ�����������
auto addThree = [](int x, int y, int z){
return x + y + z; };
auto addTwoToOne = [addThree](int x, int y) {
return [=](int z) {
return addThree(x, y, z);
};
};
auto addOneToTwo = [addThree](int x) {
return [=](int y, int z) {
return addThree(x, y, z);
};
};
auto addOneByOne = [addTwoToOne](int x) {
return [=](int y) {
return addTwoToOne(x, y);
};
};
cout << "addThree = " << addThree(1, 2, 3) <<endl;
cout << "addTwoToone = " << addTwoToOne(1, 2)(3) <<endl;
cout << "addOneToTwo = " << addOneByOne(1)(2)(4) <<endl;
������Ĵ�����addThree����ʵ���˶�����intֵ������ӵIJ�����Ȼ��Ըú��������˲��,�����ΪaddTwoToOne,������ΪaddOneToOne,�ڵ��õ�ʱ��ͱ����
addOneByOne(1)(2)(4),��������̾ͱ�����currying(���ﻯ)��
�������������Ǹ��������Ҳ���Ǵ��⡣
recursing & tail recursion optimization (�ݹ�&β�ݹ��Ż�)
�ݹ����ĺô����Ǽ���,����һ�����������úܼĴ�������������(ע��:�ݹ�ľ�������������,��Ҳ�Ǻ����DZ�̵ľ���)��
����Ҳ֪���ݹ��Σ��,�Ǿ�������ݹ����Ļ�,stack�ܲ���,���ᵼ�����ܴ�����½������,����ʹ��β�ݹ��Ż���������ÿ�εݹ�ʱ��������stack,�����ܹ��������ܡ�����Stack Overflow�ϵ���ƪ�ʴ��ܹ��������What is tail call optimization?
C++ ���Ⲣ����֤β�ݹ��Ż��ܹ�ִ��,����������C++������(��GCC\Clang\MVSC)����֧��β�ݹ��Ż��ġ�
[1]��Functional Programming in C++��
https://www.manning.com/books/functional-programming-in-c-plus-plus
[2]https://zh.cppreference.com/w/cpp/algorithm/transform
[3]https://zh.cppreference.com/w/cpp/iterator/back_inserter
[4]https://zh.cppreference.com/w/cpp/algorithm/accumulate
[5]https://zh.cppreference.com/w/cpp/algorithm/reduce
[6]https://zh.cppreference.com/w/cpp/algorithm/execution_policy_tag_t
[7]https://zh.cppreference.com/w/cpp/algorithm/partition
[8]https://zh.cppreference.com/w/cpp/ranges
[9]How can currying be done in C++?
https://stackoverflow.com/questions/152005/how-can-currying-be-done-in-c
[10]https://coolshell.cn/articles/10822.html