??上次用onnx模型实现了c++版的HRNet,加上NanoDet的目标检测,在我的笔记本(GTX960M)上实现了20FPS左右的帧率,参考HRNet C++实现。这次尝试使用了tensorrt对HRNet的onnx模型进行进一步加速,达到了24FPS左右的帧率。如下图所示。

1.生成符合条件的onnx
??由于很多原因,onnx和tensorrt对一些算子的支持并不相同,有些算子在onnx上可以实现但在tensorrt上不能支持。因此需要对原来pytorch版HRNet的一些操作进行修改。
??HRNet的代码解析在很多博客中都有介绍,在修改之前建议阅读一下,主要是对代码里面不同分辨率融合时的upsample操作进行修改。具体的代码在\lib\models\pose_hrnet.py中,将HighResolutionModule类中的_make_fuse_layers函数里的上采样融合删除。

??然后将forward前向函数中的融合部分加上被允许的上采样操作,需要指定上采样后的size大小。
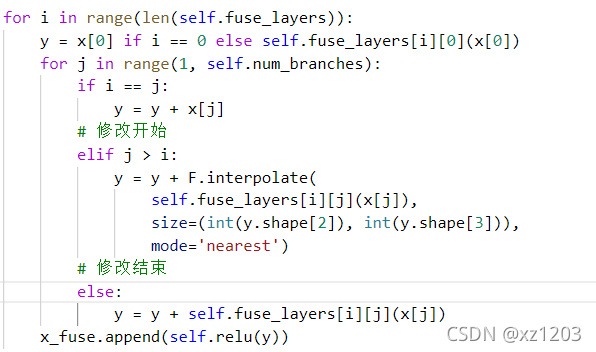
??然后转onnx即可,需要注意的是用opset_version=10去转换,没尝试过11,可能会有问题。
2.onnx转tensorrt
??首先安装Windows版的tensorrt,去官网下载,我安装的是7.0.0.11。环境配置可以参考VS+tensorrt配置。然后写转换代码。首先加载onnx模型:
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
} gLogger;
std::string onnx_filename = "E:/onnx/s2.onnx"; //onnx路径
IBuilder* builder = createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
auto parser = nvonnxparser::createParser(*network, gLogger);
parser->parseFromFile(onnx_filename.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load onnx mnist model...\n");
然后生成推理engine:
// 2、build the engine
unsigned int maxBatchSize = 1;
builder->setMaxBatchSize(maxBatchSize);
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1 << 20);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
之后转换为trt模型,这个部分会根据gpu进行模型转换,时间较长。
// 3、serialize Model
IHostMemory* gieModelStream = engine->serialize();
std::string serialize_str;
std::ofstream serialize_output_stream;
serialize_str.resize(gieModelStream->size());
memcpy((void*)serialize_str.data(), gieModelStream->data(), gieModelStream->size());
serialize_output_stream.open("./s2.trt", std::ios_base::out | std::ios_base::binary);
serialize_output_stream << serialize_str;
serialize_output_stream.close();
到这里就生成了trt模型。之后可以判断本地是否存在trt模型,不存在则调用上述函数,存在则直接反序列化trt模型。
3.调用trt模型
??下面的代码的作用是加载trt模型,需要注意的是,生成和加载trt的时候要把流定义为二进制,否则可能会存在大小不一致的问题。
IRuntime* runtime = createInferRuntime(gLogger);
std::string cached_path = "./s2.trt";
std::ifstream fin(cached_path, std::ios_base::in | std::ios_base::binary);
std::string cached_engine = "";
while (fin.peek() != EOF) {
std::stringstream buffer;
buffer << fin.rdbuf();
cached_engine.append(buffer.str());
}
fin.close();
ICudaEngine* re_engine = runtime->deserializeCudaEngine(cached_engine.data(), cached_engine.size(), nullptr);
IExecutionContext* context = re_engine->createExecutionContext();
加载完成后,获取输入和输出的信息:
for (int i = 0; i < network->getNbInputs(); i++) {
// print input node names
const char* input_name = network->getInput(i)->getName();
printf("Input %d : name=%s\n", i, input_name);
input_node_names_hrnet.push_back(input_name);
// print input shapes/dims
printf("Input %d : num_dims=%zu\n", i, 4);
for (int j = 0; j < 4; j++) {
printf("Input %d : dim %d=%jd\n", i, j, network->getInput(0)->getDimensions().d[j]);
input_tensor_size_hrnet *= network->getInput(0)->getDimensions().d[j];
}
}
for (int i = 0; i < network->getNbOutputs(); i++) {
// print output node names
const char* output_name = network->getOutput(i)->getName();
printf("Output %d : name=%s\n", i, output_name);
output_node_names_hrnet.push_back(output_name);
auto x = network->getOutput(0)->getDimensions().d;
output_node_dims_hrnet = { x[0] ,x[1], x[2], x[3] };
nOutputSize = x[0] * x[1] * x[2] * x[3];
output_dim_hrnet[output_name] = output_node_dims_hrnet;
printf("Output %d : num_dims=%zu\n", i, output_node_dims_hrnet.size());
for (int j = 0; j < output_node_dims_hrnet.size(); j++) {
printf("Output %d : dim %d=%jd\n", i, j, output_node_dims_hrnet[j]);
}
}
最后完成显存和内存的数据交流以及推理操作:
cudaMalloc(&buffers[0], input_tensor_size_hrnet * sizeof(float));
cudaMalloc(&buffers[1], nOutputSize * sizeof(float));
// 创建cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
void* data = malloc(input_tensor_size_hrnet * sizeof(float));
memcpy(data, x_hrnet, input_tensor_size_hrnet * sizeof(float));
// 内存到GPU显存
cudaMemcpyAsync(buffers[0], data, input_tensor_size_hrnet * sizeof(float), cudaMemcpyHostToDevice, stream);
// 推理
context->enqueueV2(buffers, stream, nullptr);
// 显存到内存
float *output_tensors_hrnet = new float[nOutputSize];
cudaMemcpyAsync(output_tensors_hrnet, buffers[1], nOutputSize * sizeof(float), cudaMemcpyDeviceToHost, stream);
// 同步结束,释放资源
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
至此,完成tensorrt对HRNet的加速。
4.总结
??tensorrt实现了对onnx的进一步加速,但是会有很多算子不支持,需要对原来的某些算子进行更改。tensorrt针对不同的gpu会有相应的优化,部署到不同机器上需要重新生成,较为耗时。但更改完之后的加速还是较为明显的,HRNet的部分由以前的0.04s加速至0.03s,加上nanodet的0.01s,大致可以在我的笔记本上达到实时。后续可以考虑部署到更好配置的机器上。至于nanodet,因为它给的onnx在加载时存在算子不兼容问题,因此我就没有对它进行加速。具体的代码后续会开源。
