����Ŀ¼
һ����һ��C++����
����������ʽ��ʼC++���Ե�ѧϰ,��C����һ��,������C++�ĵ�һ����Ӵ�ӡ ��hello world�� ��ʼ:
#include <iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}
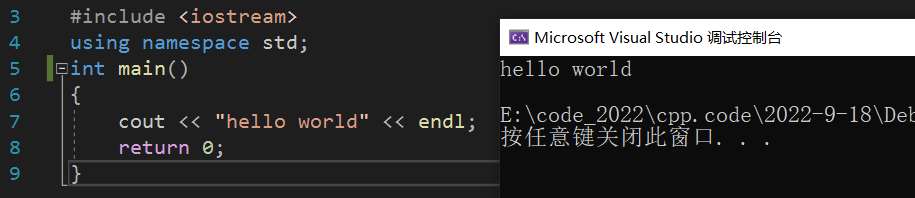
����֪��,C++�Ƕ�C���Ե������Լ��ٷ�չ,����C++�еĺܶණ������C����ʮ�����ε�,����C++Ҳ�Ǽ���C��,Ҳ����˵,������ .cpp �ļ��б�д������ .c ����,������Ҳ���ᱨ��;��ô��ȹ���,����Ҳ�Ͳ��Ѳµ�,���������е� iostream ��ͷ�ļ�,cout ���������,��������˵,Ψһ�е������İ����ֻ�� using namespace std; �������,Ҫ�����������,������ҪѧϰC++�������ռ����֪ʶ��
���������ռ�
1��ʲô�������ռ�
����֪��,��C������,������ǵij����а���ijһͷ�ļ�,��ô���ǾͲ��ܶ�������ͬ����ȫ�ֱ���,����������ͻᱨ��;����,������ij�����,���ǰ����� <string.h> ͷ�ļ�,��ͷ�ļ��к��� trelen ����,������� strlen ��Ϊ�������������,�ͻ�����ض���:
#include <stdio.h>
#include <string.h>
size_t strlen = 10;
int main()
{
printf("%d\n", strlen);
}

����C����ͷ�ļ��еĿ⺯���Ƿdz����,�����ڱ�д������Ŀ��ʱ���������ܻᶨ����⺯��ͬ���ı���,�Ӷ����������ͻ;Ϊ�˽���������,C++�����������ռ�ĸ��
�����ռ�:��C/C++��,�����������ͺ���Ҫѧ������Ǵ������ڵ�,��Щ������������������ƽ����� ����ȫ����������,���ܻᵼ�ºܶ��ͻ��ʹ�������ռ��Ŀ���ǶԱ�ʶ�������ƽ��б��ػ�, �Ա���������ͻ��������Ⱦ,���ж��������ռ�Ĺؼ����� namespace��
2�������ռ�Ķ���
���������ռ�ܼ�,ֻ��Ҫʹ�� namespace �ؼ���,������������ռ������,Ȼ����һ�� {} ����,{} �м�Ϊ�����ռ�ij�Ա��
�����ռ��������ص�:
- �����ռ������������ȡ��;
- �����ռ��п��Զ��庯��/����/����;
- �����ռ����Ƕ��;
- ͬһ���������������ڶ����ͬ���Ƶ������ռ�,���������Ὣ��ϳɵ�ͬһ�������ռ���;
�����ռ��ж��庯��/����/����:
namespace N1
{
//�������
int strlen = 10;
//��������
typedef struct SLNode
{
int data;
struct SLNode* next;
}SLNode;
//���庯��
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
}
�����ռ�Ƕ����:
namespace N1
{
int strlen = 10;
//Ƕ����
namespace N2
{
typedef struct SLNode
{
int data;
struct SLNode* next;
}SLNode;
}
//Ƕ���
namespace N3
{
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
}
}
ͬһ���������������ڶ��������ͬ�������ռ�,���������Ὣ��ϳɵ�ͬһ�������ռ���: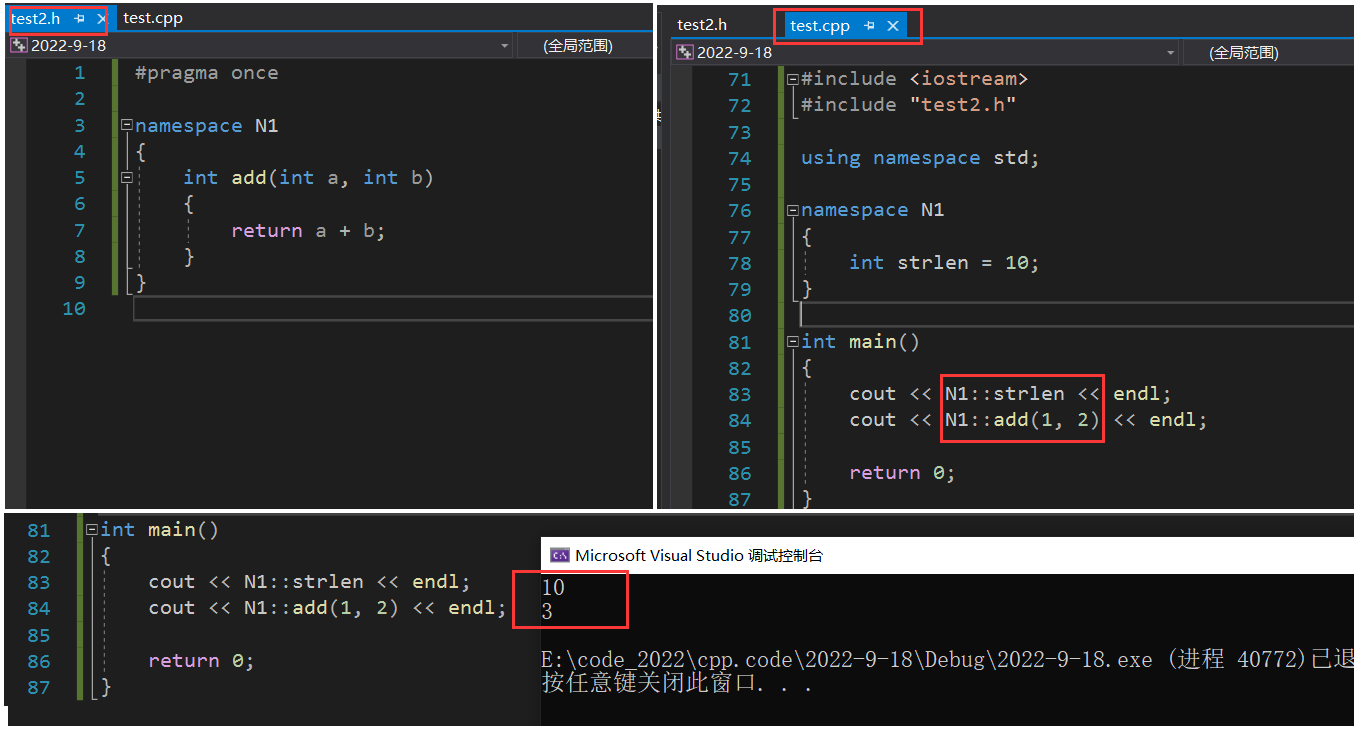
3�������ռ��ʹ��
�����ռ��ʹ�������ַ�ʽ:�����ռ����Ƽ�������������ʹ�� using �������ռ���ij����Ա���롢ʹ�� using namespace �������ռ���������,���е�����������Ϊ:��::��;������������������ռ�Ϊ��:
namespace N
{
int a = 0;
int b = 1;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
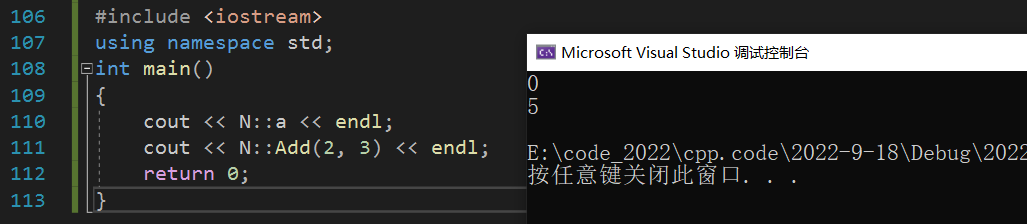
�����ռ����Ƽ�����������:
#include <iostream>
using namespace std;
int main()
{
cout << N::a << endl;
cout << N::Add(2, 3) << endl;
return 0;
}
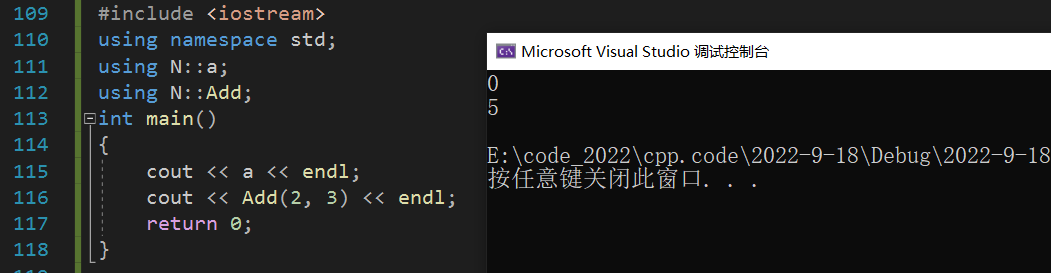
ʹ�� using �������ռ���ij����Ա����:
#include <iostream>
using namespace std;
using N::a;
using N::Add;
int main()
{
cout << a << endl;
cout << Add(2, 3) << endl;
return 0;
}
ʹ�� using namespace �������ռ���������:
#include <iostream>
using namespace std;
using namespace N;
int main()
{
cout << a << endl;
cout << Add(2, 3) << endl;
return 0;
}
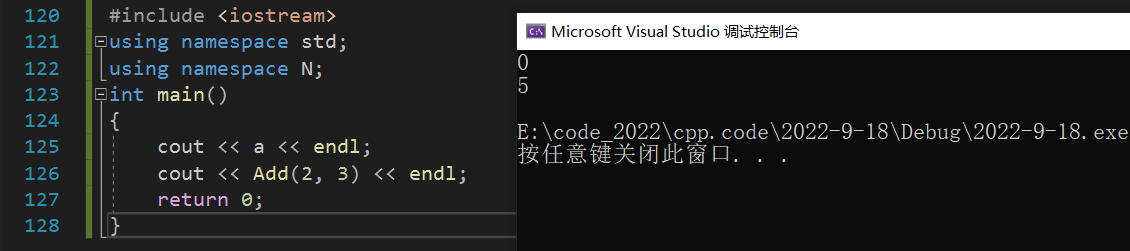
�ܵ���˵,������Ҫʹ�������ռ��еı���,һ�������ַ���:һ����ʹ������������ ::,��һ�������������ռ�,�����������ռ��ַ�Ϊ���������ȫ�����롣
Ƕ����������ռ��ʹ��:����Ƕ����������ռ�,�������ʹ����������������,��ȻҲ����ͨ��������������ռ�ķ�ʽʹ��: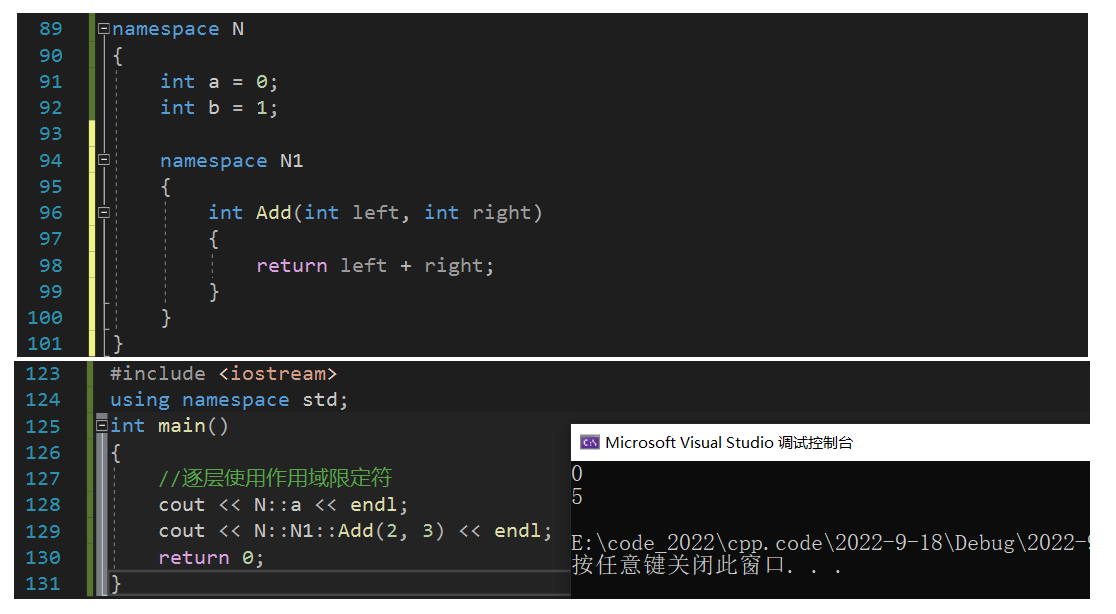
4��ע������
ʹ�������ռ��м�����Ҫ�����ע��ĵط�:
1��һ�������ռ�Ͷ�����һ���µ�������,�������������ռ���,�����ռ��е��������ݶ������ڸ������ռ���;
2�������ռ��ж���ı�������ȫ�ֱ���:����ͼ,�����ռ�N�еij�Ա����a�����ں���test������,˵��a����������ȫ��,����a��ȫ�ֱ���;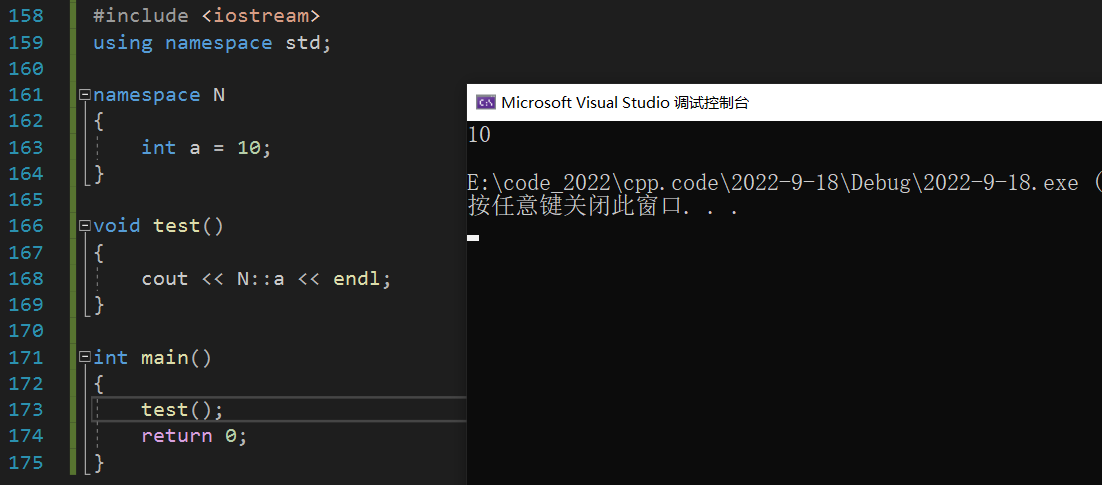
3�����������ұ����Ĺ�����:Ĭ�����ھֲ����в���,����Ҳ���,�ٵ�ȫ������ȥ��,�����ȫ������Ҳû�ҵ��ñ���,�ͱ���;�������ռ�������Ǹı���������ұ����Ĺ���,�ñ������ȵ��ֲ����в���,����Ҳ���,��ֱ�ӵ������ռ���ȥ��,���Ҳ����ͱ�����
����C++���������
C++����������������:
#include<iostream>
// std��C++����������ռ���,C++������Ķ���ʵ�ֶ��ŵ���������ռ���
using namespace std;
int main()
{
int a = 0;
cin >> a; //console in
cout << a << endl; //console out endline
return 0;
}
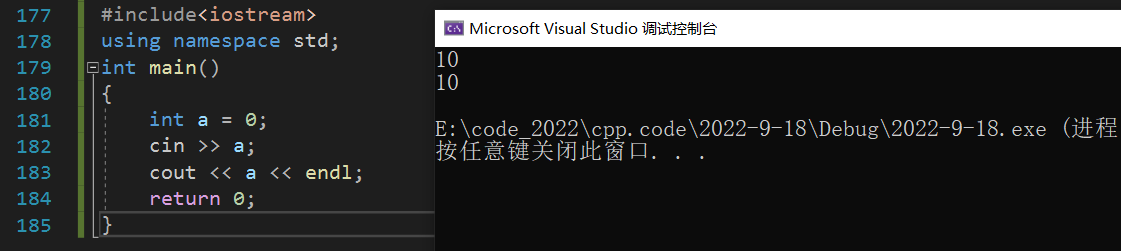
˵��:
1��ʹ�� cout ���������(����̨)�� cin ���������(����)ʱ,������� <iostream> ͷ�ļ� �Լ��������ռ�ʹ�÷���ʹ�� std��
2�� cout �� cin ��ȫ�ֵ�������,endl �������C++����,��ʾ�������,���Ƕ������ڰ��� <iostream>ͷ�ļ��С�
3��<<�������������,>>������ȡ�������
4��ʹ��C++�������������,����Ҫ�� printf/scanf �������ʱ����,��Ҫ�ֶ����Ƹ�ʽ;C++��������������Զ�ʶ��������͡�
5��ʵ���� cout �� cin �ֱ��� ostream �� istream ���͵Ķ���,>>��<<Ҳ�漰��������ص�֪ʶ, ��Щ֪ʶ�������Ǻ����Ż�ѧϰ,������������ֻ�Ǽ�ѧϰ���ǵ�ʹ�á�
ע��:���ڱ��⽫���й�����ȫ������ʵ��,������.h����ͷ�ļ���,ʹ��ʱֻ�������Ӧͷ�ļ�����,��������ʵ����std�����ռ���,Ϊ�˺�Cͷ�ļ�����,ҲΪ����ȷʹ�������ռ�, �涨C++ͷ�ļ�����.h;�ɱ�����(vc 6.0)�л�֧�ָ�ʽ,�����������Ѳ�֧��,����Ƽ�ʹ��+std�ķ�ʽ��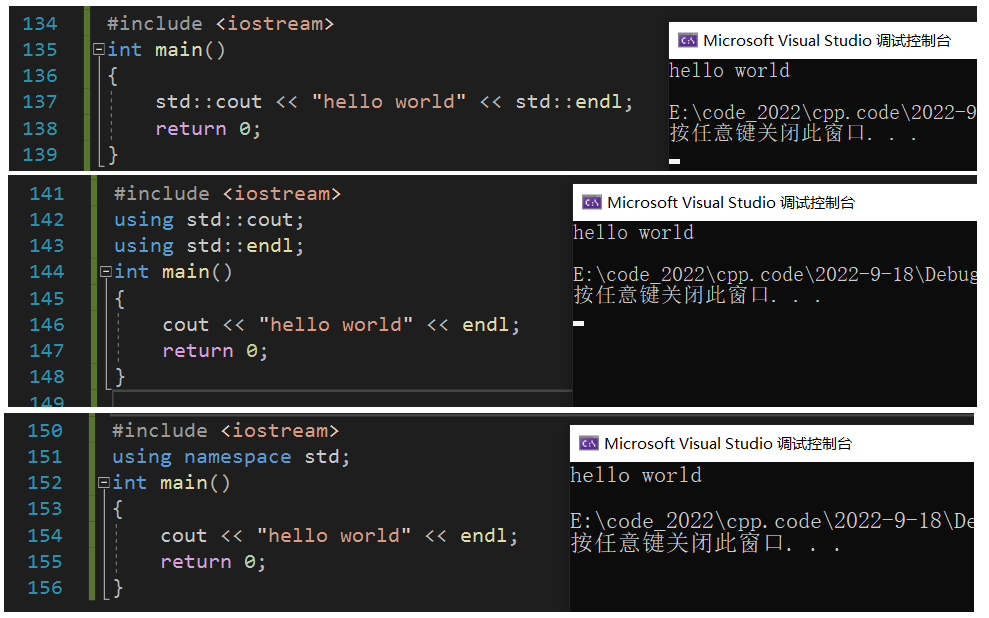
std�����ռ��ʹ�ù���:std��C++����������ռ�,���չ��stdʹ�ø�������?
1�� ���ճ���ϰ��,����ֱ��using namespace std����,��Ϊ�����ܷ��㡣
2��using namespace stdչ����,�����ȫ����¶������,������Ƕ����������������/�� ��/����,�ʹ��ڳ�ͻ����;
3�����������ճ���ϰ�к��ٳ���,������Ŀ�����д���϶ࡢ��ģ��,�ͺ����׳���;���Խ�������Ŀ�������� std::cout ����ʹ��ʱָ�������ռ� + using std::cout ��չ�����õĿ����/���͵ȷ�ʽ��
�ġ�ȱʡ����
1��ȱʡ�����ĸ���
ȱʡ�������������庯��ʱΪ�����IJ���ָ��һ��ȱʡֵ;�ڵ��øú���ʱ,���û��ָ��ʵ ������ø��βε�ȱʡֵ,����ʹ��ָ����ʵ�Ρ�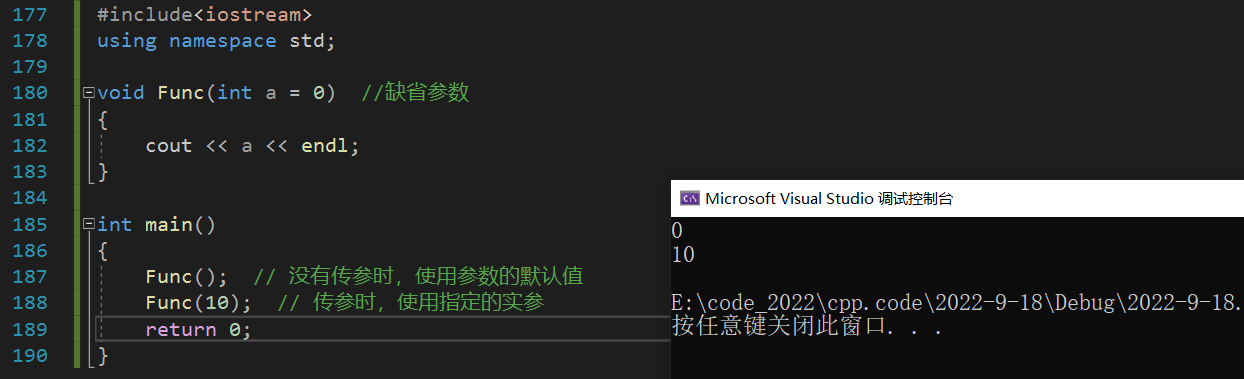
2��ȱʡ�����ķ���
ȱʡ����һ����Ϊ����:ȫȱʡ�����Ͱ�ȱʡ����;
ȫȱʡ����:
void Func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
��ȱʡ����:
void Func(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
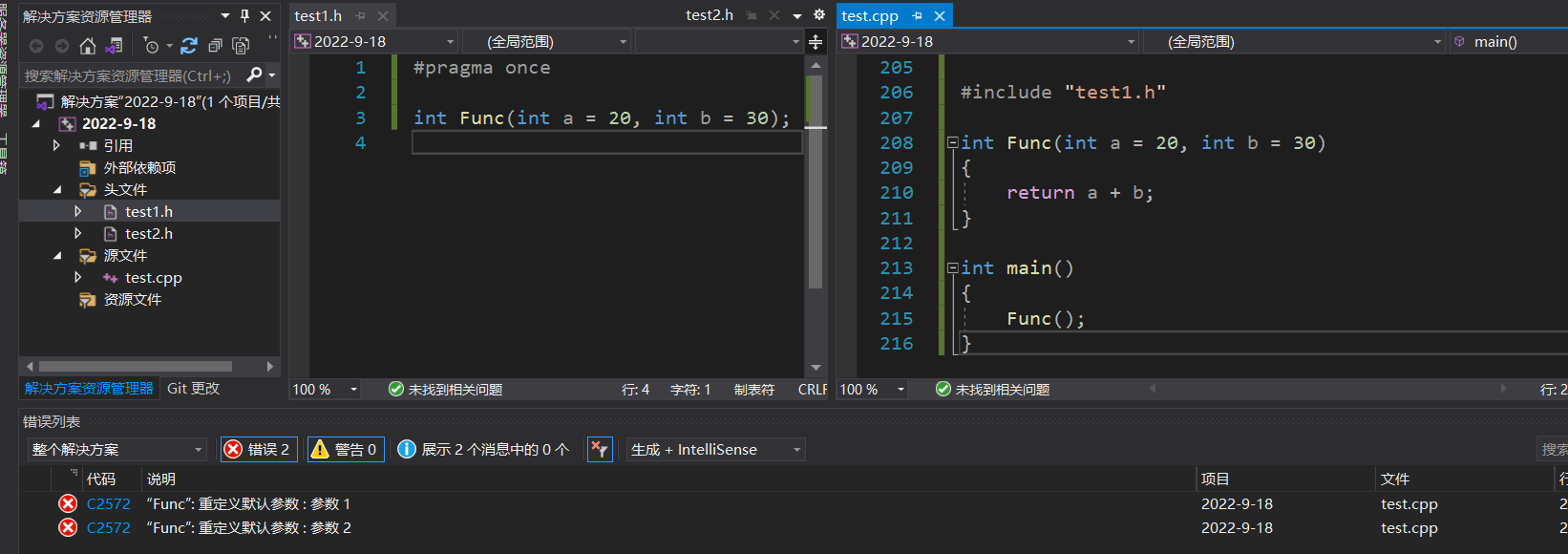
ע������
- ��ȱʡ�������������������������,���ܼ���Ÿ�;
- ȱʡ���������ں��������Ͷ�����ͬʱ����,����ȴ��ں�������,�ִ��ں�������,��ôȱʡ����ֻ���ں�������������;
- ȱʡֵ�����dz�������ȫ�ֱ�����
�塢��������
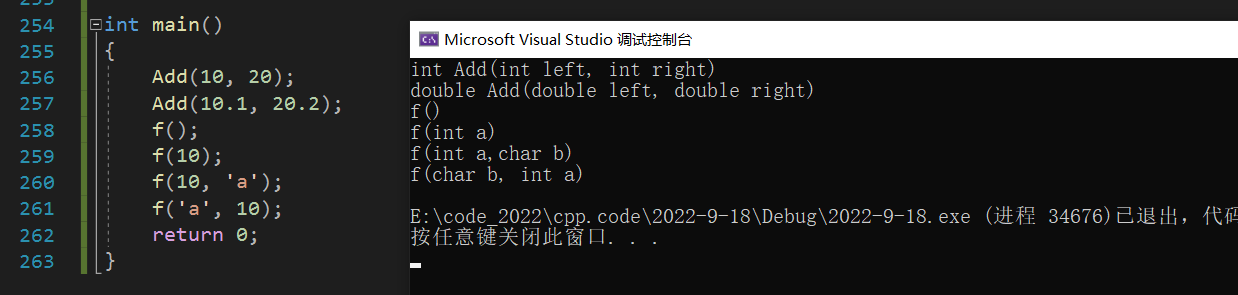
1���������صĸ���
���������Ǻ�����һ���������,C++������ͬһ�����������������������Ƶ�ͬ������,��Щͬ���������β��б�(�������� �� ���� �� ����˳��)��ͬ,����������ʵ�ֹ��������������Ͳ�ͬ�����⡣
#include<iostream>
using namespace std;
//�������Ͳ�ͬ���ɺ�������
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
//����������ͬ���ɺ�������
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
//��������˳��ͬ���ɺ�������
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
return 0;
}
2���������ص�ԭ�� (��Ҫ)
������ѧϰC���� ������Ԥ���� ��ʱ��֪����һ������Ҫ��������,��Ҫ����Ԥ���������롢��ࡢ�����ĸ���;���б���λ���з��Ż���,���λ����ɷ��ű�,�����ӽ����Է��ű����кϲ����ض�λ,���з��ű��Ὣÿһ��������������һ����ַ,�������ַ�Ƿ���Ч��Ҫ�����ӽν��з��ű��ĺϲ����ض�λ��ʱ���ܼ�������
�������������������ɷ��ű���һ��,C��������C++�����������еIJ����Dz�ͬ�� �C C���Ա�������ֱ���ñ亯������Ϊ���ű��еķ���,������Ժ�������������;��C++���������ǻ�Ժ�������������,�����κ�����������ɷ��ű���
ע:����Windows��vs�����ι�����ڸ���,��Linux��g++�����ι������,��������ʹ ����g++��ʾ��������κ�����֡�
����C���Ա������������: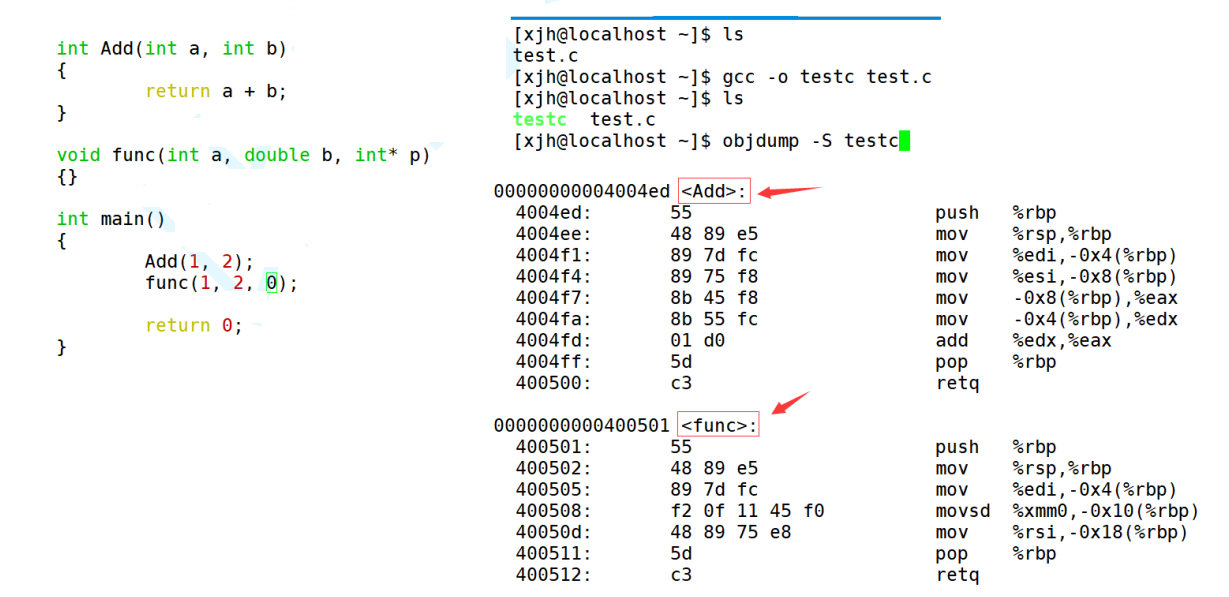
����C++�������������: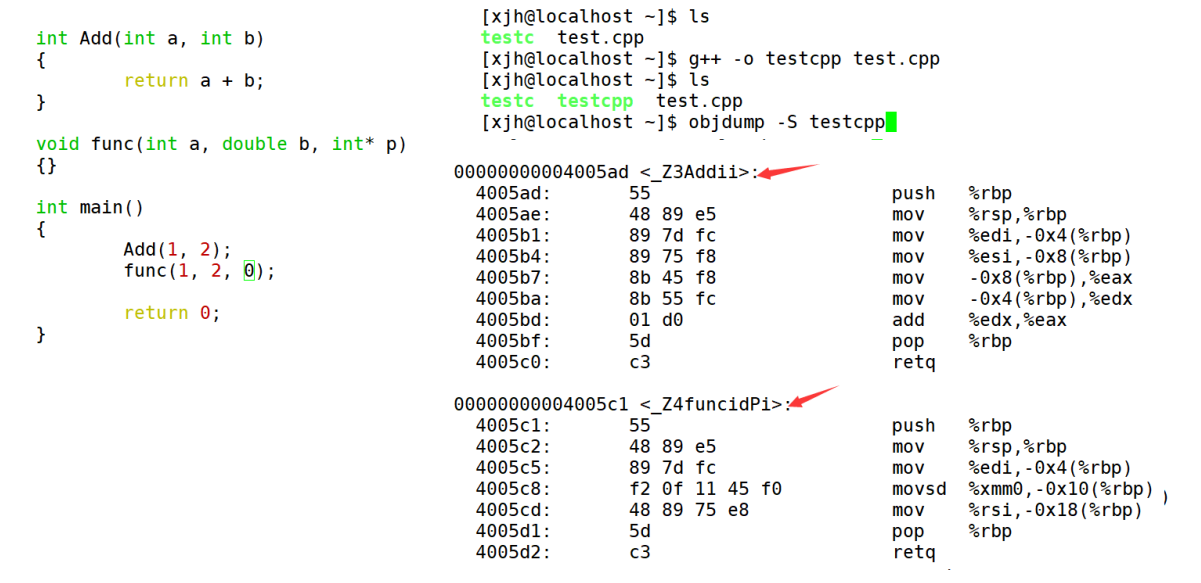
�����ԱȺ����Ƿ���:��linux��,����gcc (C���Ա�����) ������ɺ�,�������ֵ�����û�з����ı�;������g++ (C++������) ������ɺ�,�������ֵ����η����ı�,�������� ǰ_Z+�������� +������+��������ĸ ���,������������������������Ϣ���ӵ����ĺ�������С�
ͨ���������ʵ����������:C����û�취֧����������Ϊͬ������û�취����;��C++��ͨ���������ι���������,ֻҪ�������Ͳ�ͬ,���γ��������־Ͳ�һ��,���Ծ�֧�����ء�
ͬ��,����Ҳ�����������ķ���ֵ��ͬ�Լ�ͬ���Ͳ�����˳��ͬ�Dz�����������,��ΪC++������û�취����;����ʵ��ʹ��C++�������Ѻ����ķ���ֵ����Ҳ�����˺������ι���,Ҳ������������������ǹ��������ض���,��ʵ��ʹ����Ҳ�Dz�����������,��Ϊ��������ʱ�����ᴫ�ݺ����ķ���ֵ����,��ô���ڷ���ֵ��ͬ,���������涼��ͬ�ĺ�������,����ϵͳ�Ͳ�֪��Ӧ�ý��������ݸ��ĸ�����,���ڴ��ݲ���ʱ�����˶�����,��ʱ�����Ҳ�ǻᱨ���ġ�
ע:��C/C++��������Լ�����������ι������Ȥ��ͬѧ������չѧϰһ��������ƪ����,�����ж�vs�º��������ι���Ľ���:C/C++ ��������Լ�� ��
������������ (��Ҫ)
1�����������ĸ���
�� ����ջ֡�Ĵ��������� һ��������֪��:һ�������ڿ�ʼ����ʱ�Ὠ������ջ֡,��������ʱ�����ٺ���ջ֡,������ջ֡�Ľ������������пռ��ʱ���ϵĿ�����;
��ô,�������ܼ����ô����dz����ĺ�����˵,ÿ�ε��ö����¿���ջ֡�Ʊؾͻ����Ч�ʵĽ���;���� hoare ���Ŀ���������,���ǽ�����ÿ�ε���������úܶ�� Swap ����,����˵��������Ҳ�ᱻ�ݹ���úܶ��,�� Swap ���������Ĺ���ǡ��ʮ�ּ�,��ô���������������Ż���?
��C������,����ʹ���꺯��������������:����ֱ�ӽ� Swap ����д�ɺ꺯��,����ʹ�ó�����Ԥ������ֱ�ӽ� Swap �����滻����Ӧ�Ĵ���,�Ӷ����ٽ�������ջ֡��
//Դ����
#include <stdio.h>
#define Add(x,y) ((x)+(y)) //�꺯��
int main()
{
int ret = Add(2, 3);
printf("%d\n", ret);
}
//����Ԥ����֮��Ĵ���
{
//...�˴��� stdio.h չ��������
}
int main()
{
int ret = ((2)+(3));
printf("%d\n", ret);
}
���Ǻ���������Ҫȱ��:
- �겻�ܵ���;
- ��û�����Ͱ�ȫ���;
- ��dz������;
����Ϊʲô������Щȱ���Լ���Щȱ��ľ������ֳ���,���� ������Ԥ���� ���Ѿ��й�����,����Ͳ�������
����C���Ժ꺯������Щȱ��,C++�������������:
�� inline �ؼ������εĺ���������������,����ʱC++���������ڵ������������ĵط�չ�� (�ú������滻�����ĵ���),û�к������ý���ջ֡�Ŀ���,�����������������������е�Ч��;
���������ı�д����������һ��,�������ں����ķ���ֵ����ǰ����һ�� inline �ؼ��� (�����ͽ����C���Ժ꺯������д���Լ�û�����Ͱ�ȫ����ȱ��);
ͬʱ,�� debug ģʽ��,�������������Զ�չ��,��Ҫ���ǶԱ����������������;�� release ģʽ��,�����������Զ�չ�� (���������C���Ժ꺯�������Ե�ȱ��);
����˵:���������ڼ̳���C���Ժ꺯���ŵ��ͬʱ���������������е�ȱ�ݡ�
2�������������弰�鿴
���������Ķ���
//��ͨ����
int Add(int x, int y)
{
return x + y;
}
//��������--����inline�ؼ���
inline int Add(int x, int y)
{
return x + y;
}
���������IJ鿴
1�� �� release ģʽ��,���������Զ�����������չ��,������ release ģʽ������,���������������۲�;
2�� �� debug ģʽ��,��Ҫ�� ��Ŀ->���� �жԱ�����������������,����չ�� (��Ϊ debug ģʽ��,������Ĭ�ϲ���Դ�������Ż�,���¸��� VS2019 �����÷�ʽ)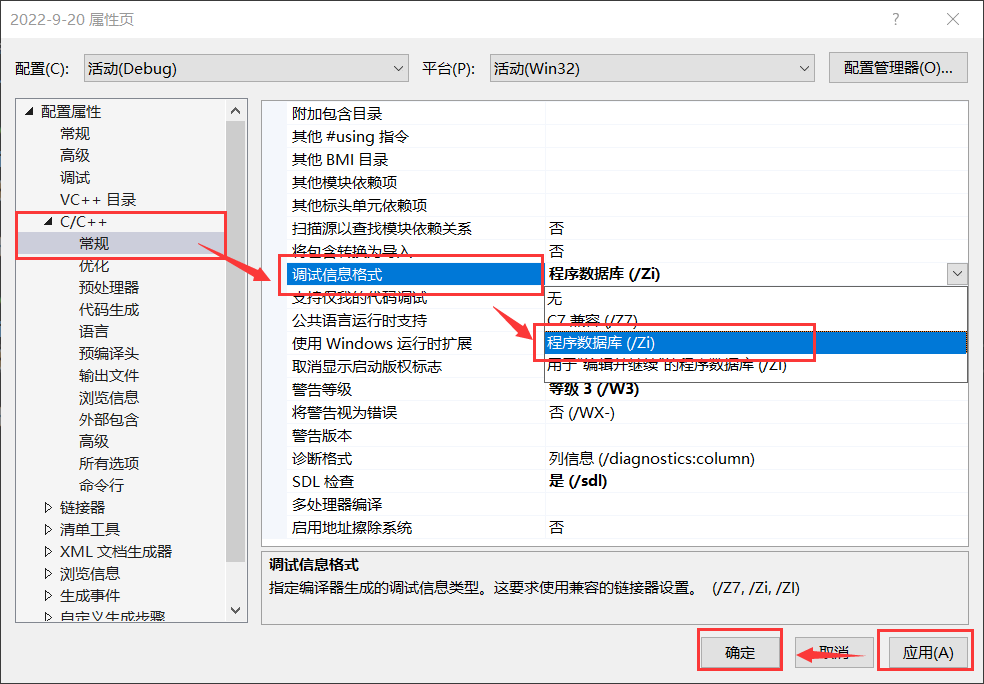
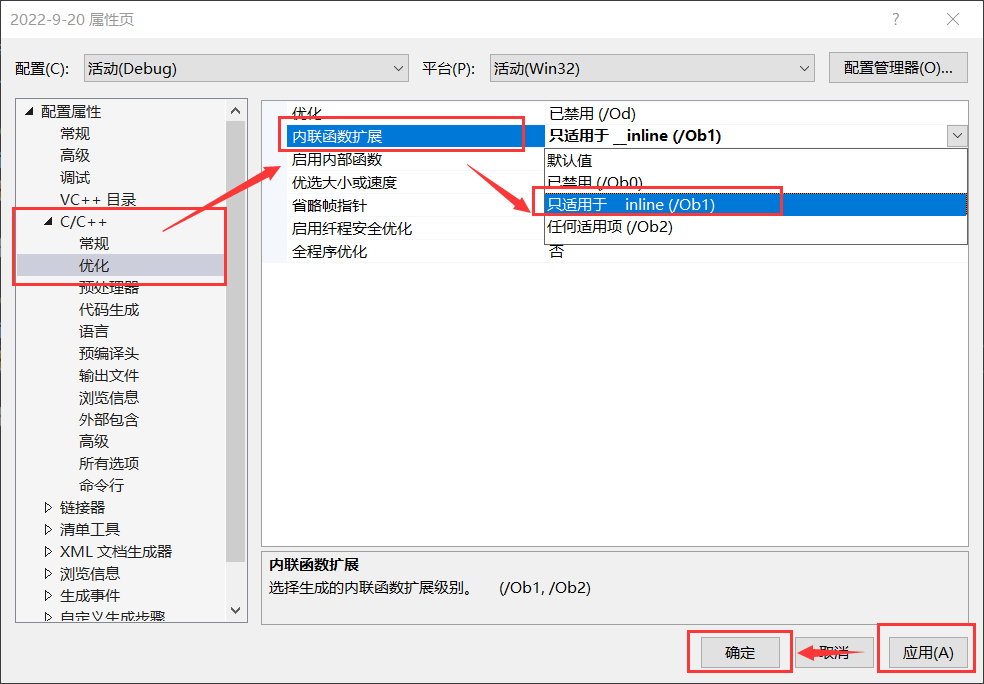
������������ú����� F10 �������,Ȼ���Ҽ�ת�������鿴������:
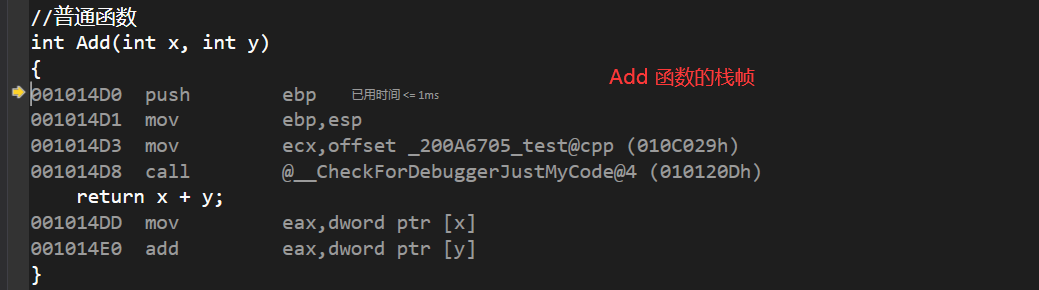
��ͨ�����Ļ�����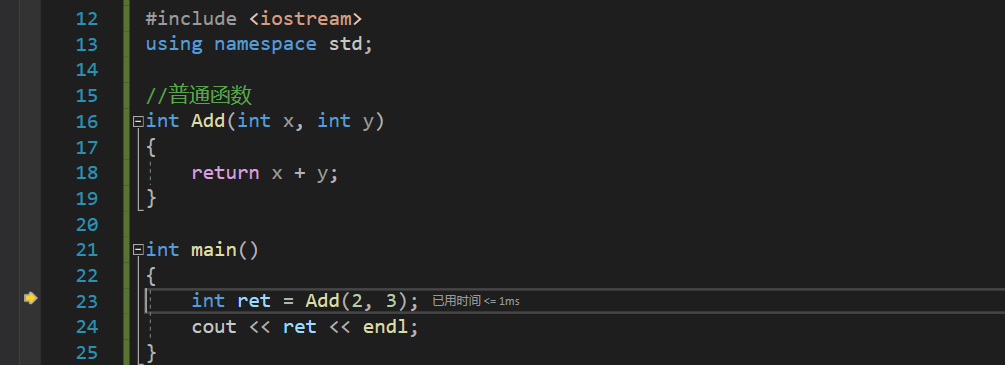

���������Ļ�����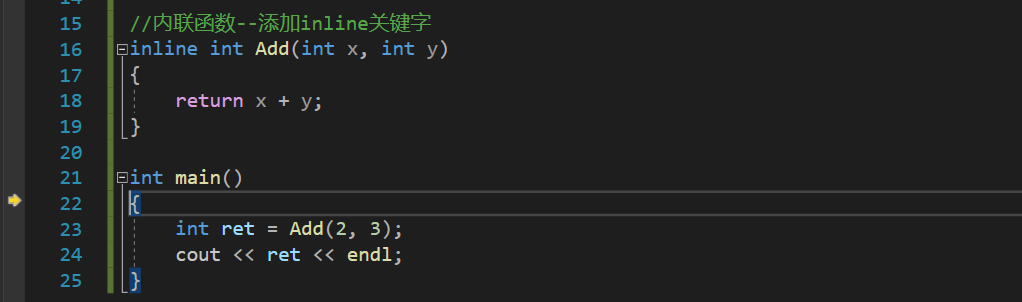

ע:����ڲ������֮��ǵðѱ��������û�ԭ��

3����������������
����1
inline ���ڱ���������ֻ��һ������ (������C���Ե� register �ؼ���),��ͬ���������� inline ��ʵ�ֻ��ƿ��ܲ�ͬ,һ�㽨�齫���������ص�ĺ������� inline ����:
- ������ģ��С (���������Ǻܳ�,����û��ȷ��˵��,ȡ���ڱ������ڲ�ʵ��);
- ���ǵݹ�;
- Ƶ������;
��ͼΪ ��C++prime���������� inline �Ľ���:
���ǿ��Լ�дһ����������֤�����������������:
//��Add���ڲ������ӻ�
inline int Add(int x, int y)
{
int sum = x + y;
sum += x + y;
sum = x + y;
sum /= x + y;
sum = x + y;
sum = x + y;
sum *= x + y;
sum = x + y;
sum = x + y;
sum -= x + y;
sum = x + y;
sum += x + y;
return sum;
}
Add �����Ļ�����: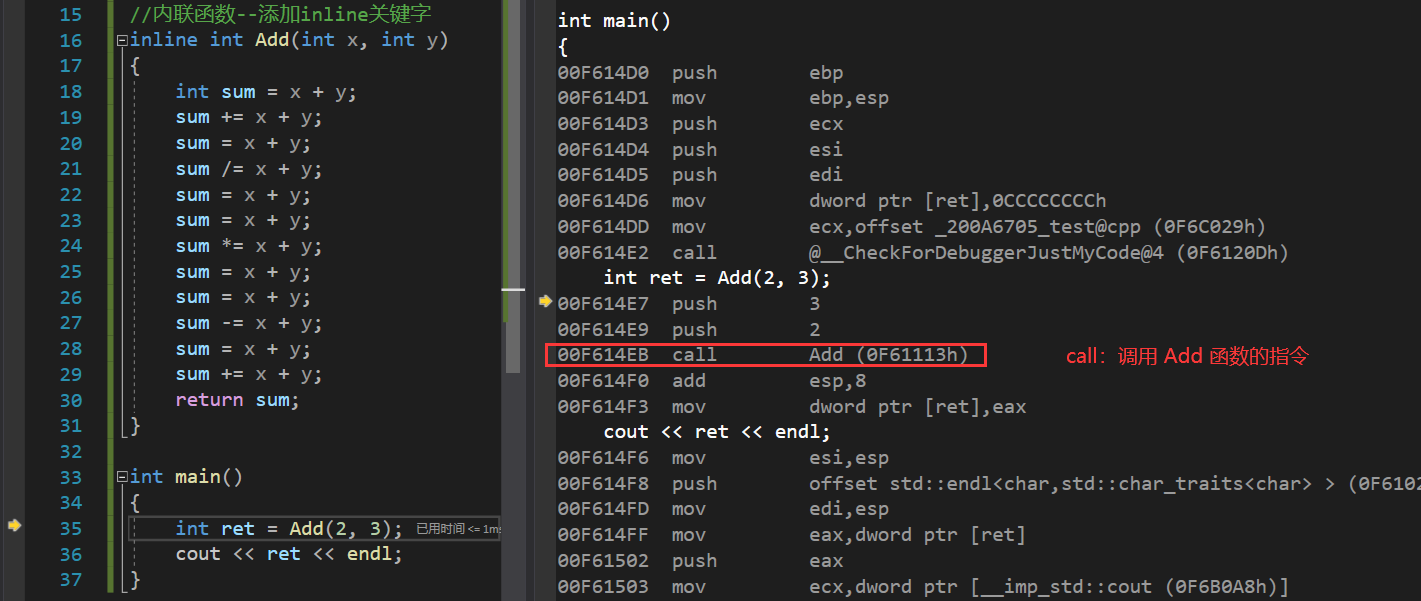
���ǿ��Կ���,�����ǽ� Add �������ڲ������ӻ�֮��,��������ʹ���� inline �ؼ������� Add ����,���� Add ������û�б�չ��,���Ǻ���������һ�����á�����ջ֡��
����2
inline ��һ���Կռ任ʱ��������,�������������������������������,�ڱ���λ��ú������滻��������;�������������Ǽ�����ջ֡�����Ŀ���,����˳�������Ч��;ȱ���ǿ��ܻ�ʹĿ���ļ����
��Ҫע�����,����Ŀռ�ָ������ָ��������ʱռ�õ��ڴ�ռ�,����ָ�����������Ӻ�õ��Ŀ�ִ�г��� (.exe/.o�ļ�) ��ռ�õĿռ�;���ڿ�ִ�г������ԭ��,�����������������Ϊ��:
����һ��Func�����Ļ��ָ����50��,���������Ҫ���ظ�����1W��;
��ô������ͨFunc������˵:����ÿ�ε���Func��Ҫת����һ�� call ������,����1W�ξ���1W�����ָ��;����Func��������ֻ���ں������崦��ת��Ϊ������;������ͨFunc������������֮��Ļ��ָ��һ���� 1W+50 ��;
������ inline ������˵,���� inline �����������е��õĵط�չ��,Ҳ����˵,ÿ����һ��Func����,�ͻ�ת����50����Ӧ�Ļ�����;���� inline Func������������֮��Ļ��ָ��һ���� 50W ��;
�����ָ���������ܻᵼ�����DZ�д�ľ�̬��/��̬������,Ҳ�п��ܵ��±�д�� .exe ����;����ʵ������ν�� ������������,��Ҳ��һ���̶��Ͻ�����Ϊʲô��������������ʱ������������չ����
����3
inline �����������Ͷ������,����ᵼ�����Ӵ���,����ԭ������:
�� ������Ԥ���� ������֪��:�����ڱ���ν��з��Ż���,�������ɷ��ű�,���ӽν��з��ű��ĺϲ����ض�λ;
���ڶ����ڱ��ļ��ڵĺ�����˵,�������ڻ��λ�ֱ�ӵ��øú���,�ڵ��ù����л����ɶ�Ӧ�ķ��ű�,�Ҵ˷��ű��еĵ�ַһ������Ч��,���Գ�����к��������Ӳ���;
�����ڶ����������ļ��еĺ���,�����������ڱ��ļ���Ѱ�Ҹú���������,���������ɵķ��ű��еĵ�ַ����Ч��;��ʱ��������������������Ӳ���;
���ӹ����з��ű��ĺϲ��Ὣ�������ɵ����з��ű��ϲ���һ��,�ϲ�����˼������������ű��еĺ�������ͬ,��ô��������ѡȡ����Ч��ַ������ķ��ű�,��������һ������Ч��ַ������;����ͬʱ���������Ͷ���ĺ����������Ӿ�ֻ��һ�����ű���;
�����һ������ֻ������,��û�ж���Ļ�,��ô���������ű��ĺϲ�֮���������Ȼ��һ����Ч��ַ,�������з��ű����ض�λʱ�ͻᷢ�������Դ���;������ű��й�������һ����Ч��ַ,�ض�λʱ�������ͻ���������ַ�����ú���,�����Ϳ���ʵ�ֿ��ļ����ú���;
���� inline ������˵,������ǽ������Ķ������������,��ô�����������ڻ��λ�����һ�����ű�,�����������һ����Ч�ĵ�ַ;�������� inline ������ֱ��չ����,���Ժ������岿���ڻ��β��������ɷ��ű�;��ʱ��ͳ��������������,�������ű��ĺϲ�֮�� inline ������Ȼ����һ����Ч��ַ,�����ض�λ��ʱ���������Դ�������:
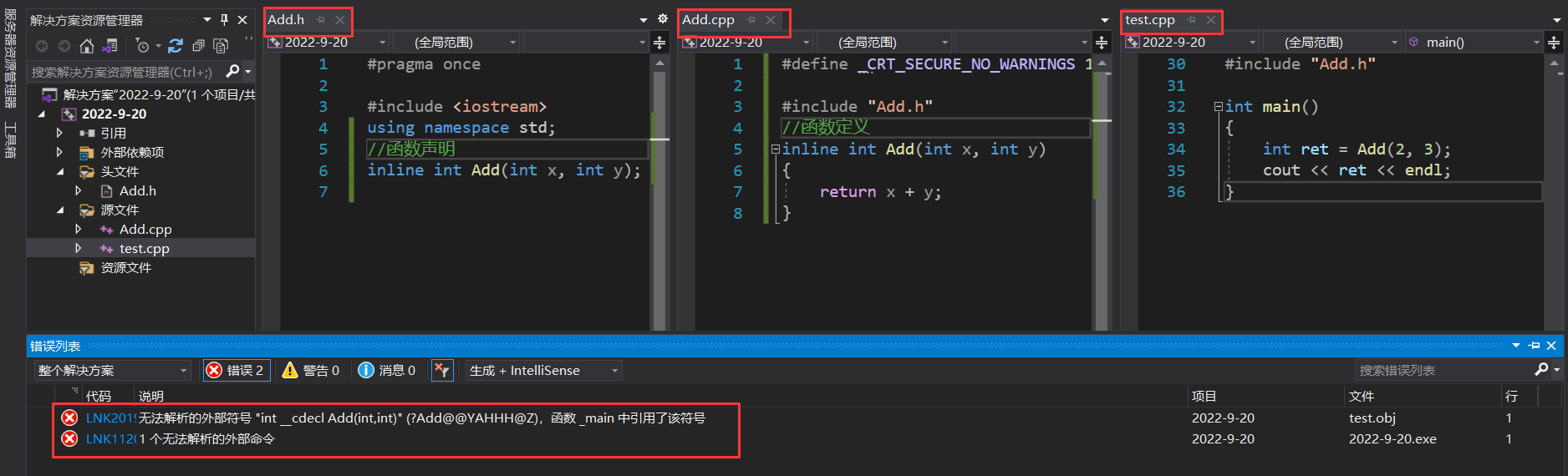
ͼ��,���ǽ� inline �����Ķ������ Add.h ��,����ʵ�ַ��� Add.cpp ��,Ȼ���� test.cpp �а��� Add.h,��������Ԥ����֮��,test.cpp �оͰ����� inline ����������;��ô�������,Add.cpp �е� Add ������������������,��ֱ��չ��,���Բ������ɷ��ű�;
���� test.cpp ��,�������,Add ����������������һ�����ű�,�ҷ��ű��еĵ�ַ����Ч��;�������ӽ�,Add ������Ӧ�ķ��ű��ֲ���ƥ�䵽��Ч�ĵ�ַ (��Ϊ test.cpp �в�û������ Add �����ķ��ű�),�����ض�λʱ���������ʹ��� (LNK ����);
��ȷ��ʹ�÷�������:����� .h �ļ�,�� inline �����Ķ���ֱ�ӷ��� .h �ļ���;���û�� .h �ļ�,��ֱ�ӷ��ڱ��ļ��ڲ�;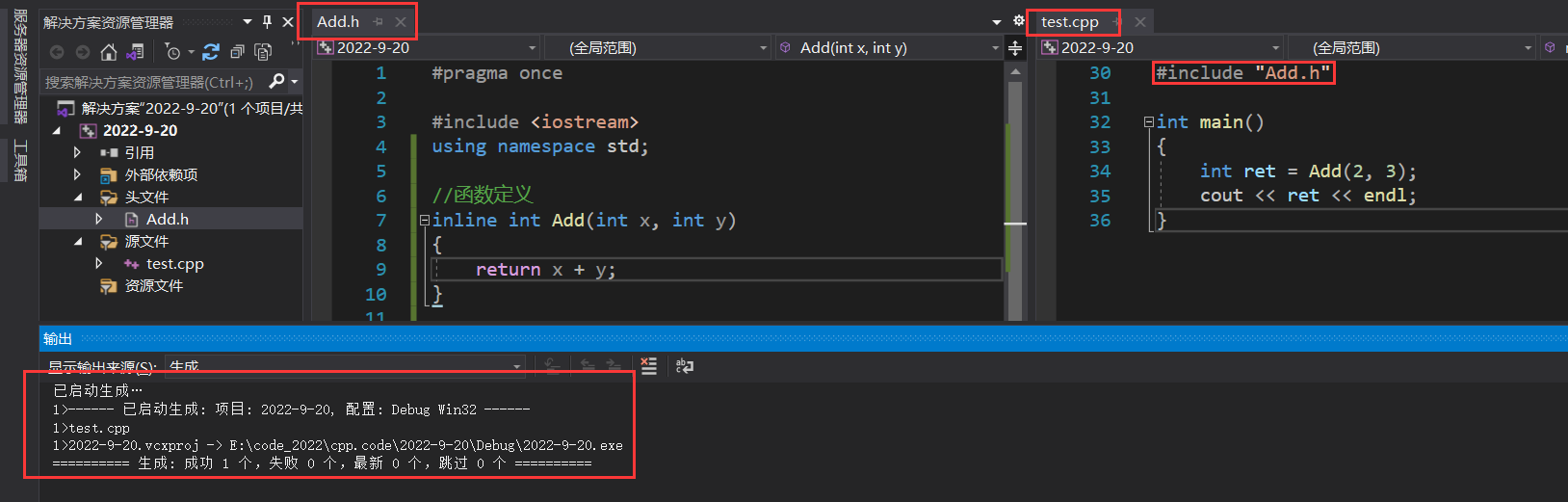
ע:������C������ѧϰ�� ����ջ֡�Ĵ��������� �� ������Ԥ���� ������������Ȼ����,���Ƕ�������C/C++�ĵײ����dz���Ҫ,ϣ������ܶһ��ʱ�����������ǡ�
�ߡ�auto �ؼ��� (C++11)
1��������˼��
�ڴ����д������,���ų���Խ��Խ����,�������õ�������ҲԽ��Խ����,����������:
- ��������ƴд;
- ���岻��ȷ�������׳���;
�������� m �� it ����������:
#include <string>
#include <map>
int main()
{
std::map<std::string, std::string> m{ { "apple", "ƻ��" }, { "orange","����" },{"pear","��"} };
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
//....
}
return 0;
}
std::map::iterator ��һ������,���Ǹ�����̫����,�ر�����д��;���ܴ�����ͬѧ�����Ѿ��뵽:���ǿ���ͨ�� typedef ������ȡ����,����:
#include <string>
#include <map>
typedef std::map<std::string, std::string> Map;
int main()
{
Map m{ { "apple", "ƻ��" },{ "orange", "����" }, {"pear","��"} };
{
//....
}
return 0;
}
ʹ��typedef������ȡ����ȷʵ���Լ���,���� typedef ��ʱ�������µ�����: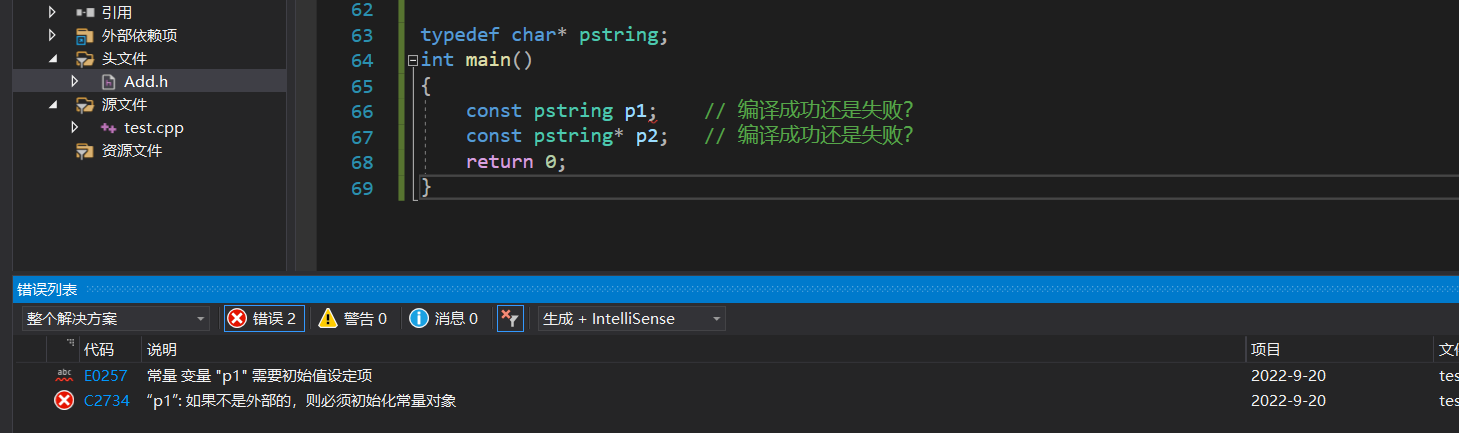
2��auto �ĸ���
������C/C++��auto�ĺ�����:ʹ��auto���εı���,�Ǿ����Զ��洢���ľֲ�����,���ź�����һֱû����ȥʹ����;��Ϊ���������ý�����,������ջ֡�ᱻ����,��ô�����ں���ջ֡�еľֲ�������ȻҲ�ᱻ����,���ʹ�� auto ����ʧȥ������;
����C++11��,��ίԱ�ḳ����autoȫ�µĺ��弴:auto������һ���洢����ָʾ��,������Ϊһ���µ�����ָʾ����ָʾ������,auto�����ı��������ɱ�����������ʱ���Ƶ�������
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = TestAuto();
//auto e; //��ͨ������,ʹ��auto�������ʱ���������г�ʼ��
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
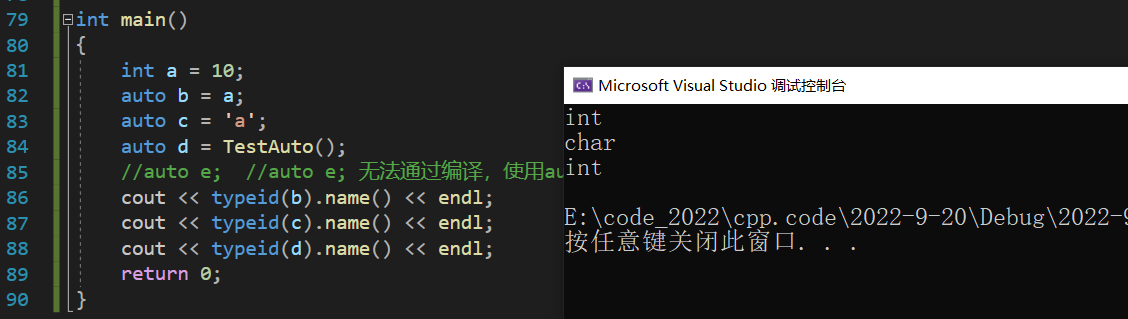
ע��:ʹ��auto�������ʱ���������г�ʼ��,�ڱ���α�������Ҫ���ݳ�ʼ������ʽ���Ƶ�auto ��ʵ������;���auto������һ�֡����͡�������,����һ����������ʱ�ġ�ռλ����,�������ڱ����ڻὫauto�滻Ϊ����ʵ�ʵ����͡�
3��auto ��ʹ��ϸ��
auto��ָ������ý������ʹ��
��auto����ָ������ʱ,��auto��auto*û���κ�����,����auto������������ʱ������&: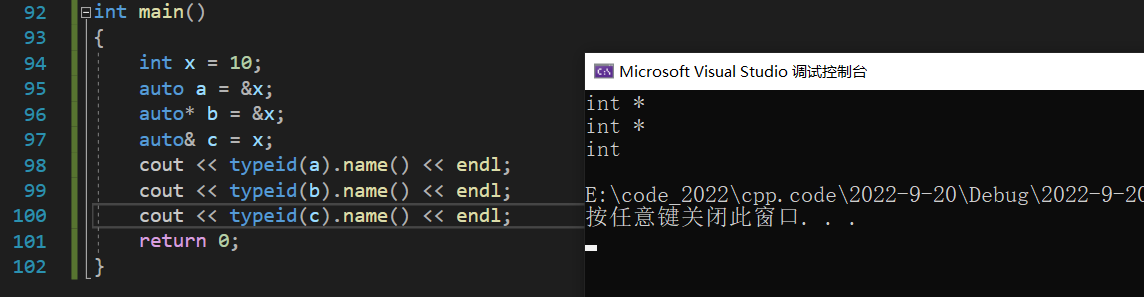
��ͬһ�ж���������
��ͬһ�������������ʱ,��Щ������������ͬ������,������������ᱨ��,��Ϊ������ʵ��ֻ�Ե�һ�����ͽ����Ƶ�,Ȼ�����Ƶ����������Ͷ�����������: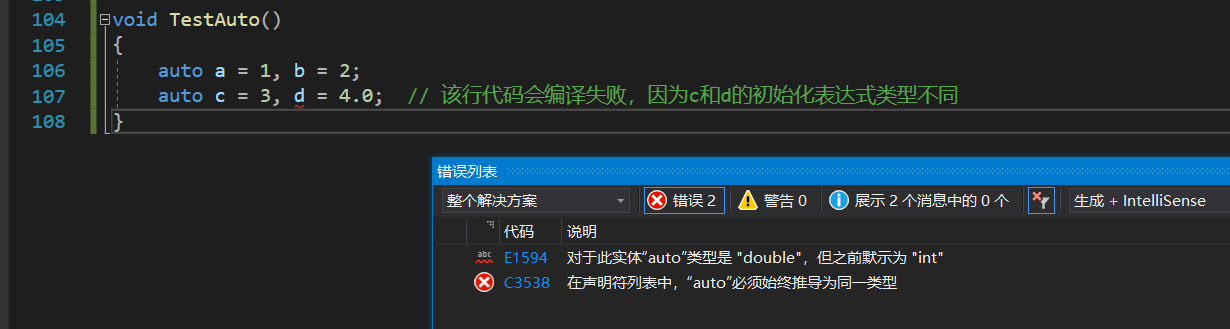
4��auto �����Ƶ��ij���
(1)��auto������Ϊ�����IJ���,��Ϊ�������еIJ������г�ʼ������ʽ,��˱������������Ƶ���a��ʵ������,����ֱ�ӹ涨auto������Ϊ�����β�: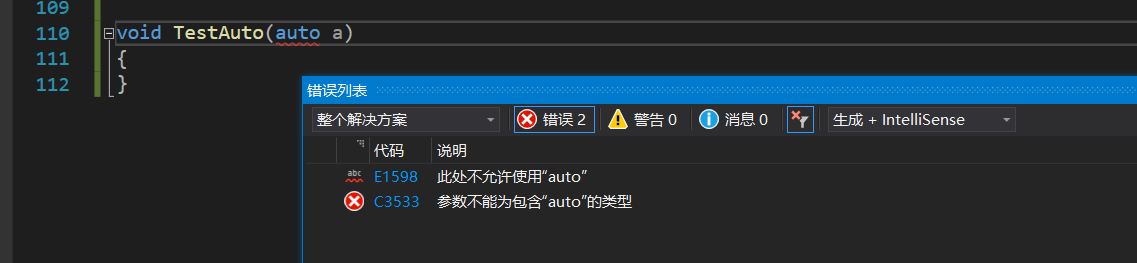
(2)�� auto����ֱ��������������:������Ҫ����Ԫ�����ͼ����������ٿռ�,������������ָ��,��� auto ���Ƶ�:
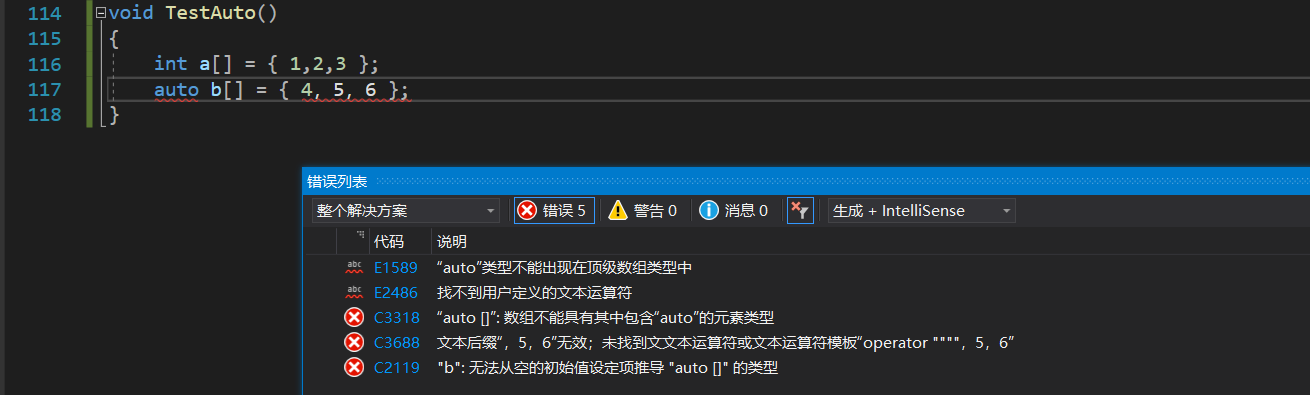
(3)��Ϊ�˱�����C++98�е�auto��������,C++11ֻ������auto��Ϊ����ָʾ�����÷�;
(4)��auto��ʵ��������������÷����Ǹ�C++11�ṩ����ʽforѭ��,����lambda����ʽ�Ƚ������ʹ�á�
�ˡ����ڷ�Χ�� for ѭ�� (C++11)
1����Χ for ���÷�
��C++98�����Ҫ����һ������,���������·�ʽ����:
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)
cout << *p << endl;
}
����һ���з�Χ�ļ��϶���,�ɳ���Ա��˵��ѭ���ķ�Χ�Ƕ����,��ʱ����������;��� C++11 �������˻��ڷ�Χ��forѭ����forѭ��������ű�ð�ŷ�Ϊ������:��һ�����Ƿ�Χ�����ڵ����ı���,�ڶ��������ʾ�������ķ�Χ��
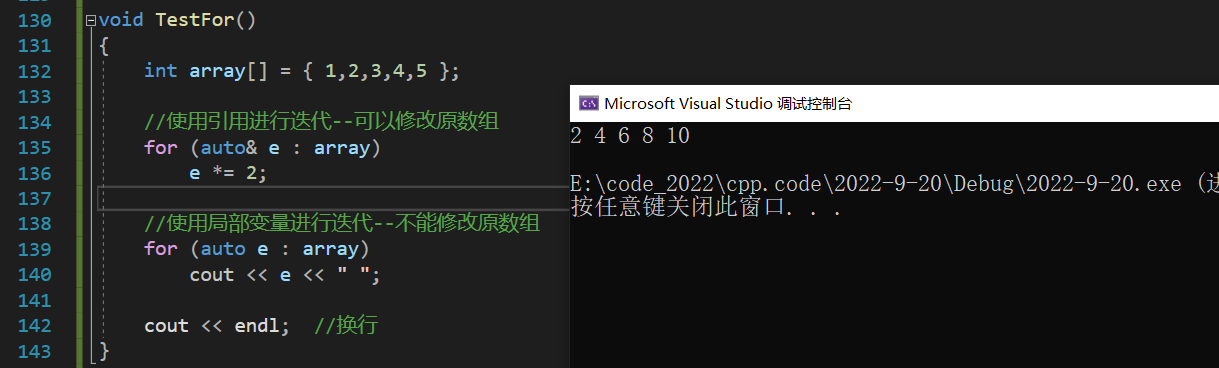
void TestFor()
{
int array[] = { 1,2,3,4,5 };
//ʹ�����ý��е���--������ԭ����
for (auto& e : array)
e *= 2;
//ʹ�þֲ��������е���--������ԭ����
for (auto e : array)
cout << e << " ";
cout << endl; //����
}
ע��:����ͨѭ������,������continue����������ѭ��,Ҳ������break����������ѭ��;
2����Χ for ��ʹ������
��Χ for ��ʹ����������������:
(1)��forѭ�������ķ�Χ������ȷ����:�����������,���������е�һ��Ԫ�غ����һ��Ԫ�صķ�Χ;���������,Ӧ���ṩ begin �� end �ķ���,begin �� end ���� for ѭ�������ķ�Χ;�����������ķ�Χ���Dz�ȷ����:
void TestFor(int array[])
{
for(auto& e : array)
cout<< e <<endl;
}
(2)�� �����Ķ���Ҫʵ��++��==�IJ���;(���ڵ����������Ժ��ѧϰ,���ڴ���˽�һ�¾Ϳ�����)
�š�ָ���ֵ nullptr (C++11)
��C������,ͨ�������ڶ���һ��ָ�������ʱ��Ὣ���ʼ��Ϊ NULL,�������������ʹ�����Ұָ��Խ���������;��ʵ����� NULL ��C�����ж����һ����,�ڴ�ͳ��Cͷ�ļ�(stddef.h)��,���Կ������´���:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
���ǿ��Կ���,����C������˵,NULL ��ʵ������0��ǿתΪָ������,�൱��0���ĵ�ַ;������C++��˵,NULL ��ֱ�ӽ���Ϊ����0;��Ȼ 0 �� (void*)0 ��������ֵ����ͬ,�������ǵ������Dz���ͬ��,һ��������,��һ����ָ��;��͵���ʹ��ʱ�����һЩ����,���������������:
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}

����������ͨ�� f(NULL) ����ָ��汾�� f(int*) ����,��������NULL�������0,��������ij������;
��C++98��,���泣��0�ȿ�����һ����������,Ҳ�����������͵�ָ�� (void*) ����,���DZ����� Ĭ������½��俴����һ�����γ���,���Ҫ���䰴��ָ�뷽ʽ��ʹ��,����������ǿתΪ (void *)0��
Ϊ�˽���������,C++11��ר��Ϊ��ָ�������һ���ؼ��� �C nullptr,�����ֲ�C++98�п�ָ��NULL���ڵ�ȱ�ݡ�(������Ϊ,nullptr ���� (void*)0 )
nullptr ע������
- ��ʹ��nullptr��ʾָ���ֵʱ,����Ҫ����ͷ�ļ�,��Ϊnullptr��C++11��Ϊ�¹ؼ������� ��;
- ��C++11��,sizeof(nullptr) �� sizeof((void*)0)��ռ���ֽ�����ͬ;
- Ϊ����ߴ���Ľ�׳��,�ں�����ʾָ���ֵʱ�������ʹ��nullptr;
���Dz���ͬ��,һ��������,��һ����ָ��;��͵���ʹ��ʱ�����һЩ����,���������������:
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}
![[����ͼƬת����...(img-N67lh0hp-1663750631422)]](https://img-blog.csdnimg.cn/2e4cf382fc664308b4772912b41bd2c5.png)
����������ͨ�� f(NULL) ����ָ��汾�� f(int*) ����,��������NULL�������0,��������ij������;
��C++98��,���泣��0�ȿ�����һ����������,Ҳ�����������͵�ָ�� (void*) ����,���DZ����� Ĭ������½��俴����һ�����γ���,���Ҫ���䰴��ָ�뷽ʽ��ʹ��,����������ǿתΪ (void *)0��
Ϊ�˽���������,C++11��ר��Ϊ��ָ�������һ���ؼ��� �C nullptr,�����ֲ�C++98�п�ָ��NULL���ڵ�ȱ�ݡ�(������Ϊ,nullptr ���� (void*)0 )
nullptr ע������
- ��ʹ��nullptr��ʾָ���ֵʱ,����Ҫ����ͷ�ļ�,��Ϊnullptr��C++11��Ϊ�¹ؼ������� ��;
- ��C++11��,sizeof(nullptr) �� sizeof((void*)0)��ռ���ֽ�����ͬ;
- Ϊ����ߴ���Ľ�׳��,�ں�����ʾָ���ֵʱ�������ʹ��nullptr;