🐱����:һֻ������1201
🐱ר��:��C++ѧϰ��
🔥����:��ֻ��Ŭ��,ʣ�µĽ���ʱ��!

C++����֪ʶ(��)
🍜����
🍛���õĸ��ʹ��

����˶���İ����?�������ֽ�����,�ڼҳ�Ϊ"��ţ",�������˳�"������"����Ȼ�ж����ν,���Ƕ�����ָ������ˡ����õ���˼���������ơ�
- ���ò����¶���һ������,���Ǹ��Ѵ��ڱ���ȡ��һ������,����������Ϊ���ñ��������ڴ�ռ�,���������õı�������ͬһ���ڴ�ռ䡣
����һ�����Ƿdz���Ϥ�ĺ���:
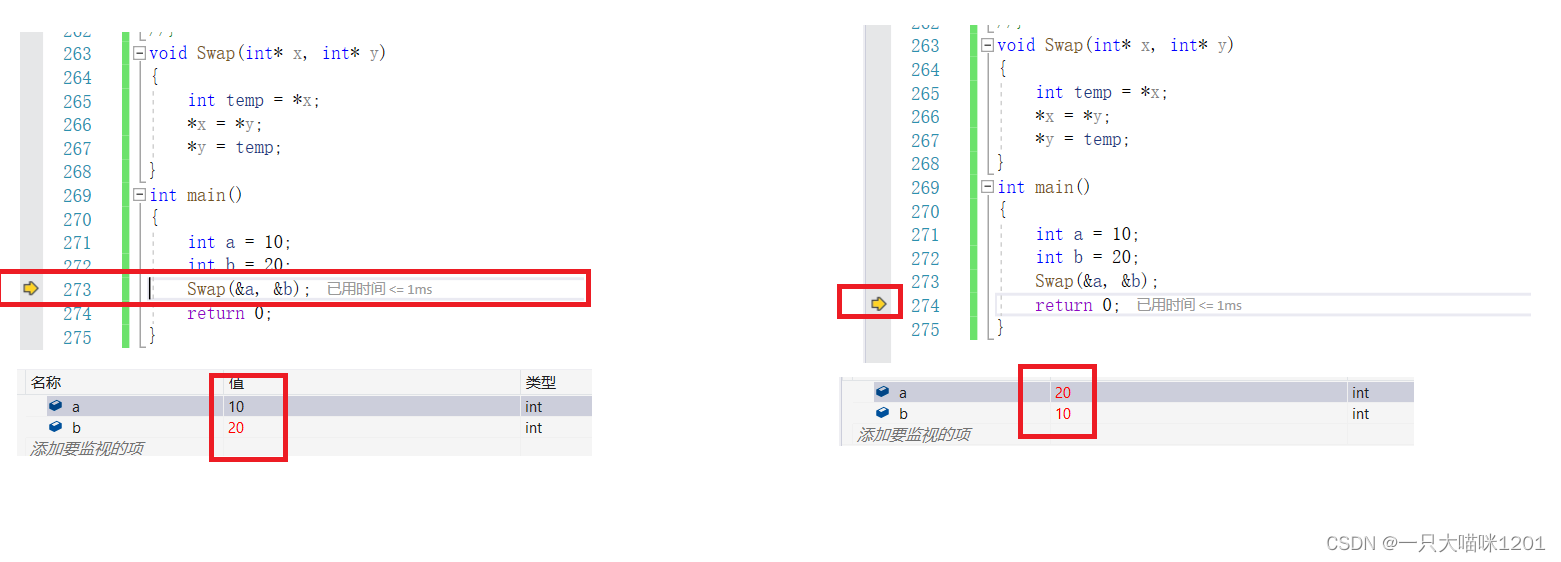
���ǽ����������ĺ���,��ͨ��ָ��ķ�ʽʵ�ֵ�,����ʵ�����ڲ�����a�ͱ���b���ڴ�ռ�,����ԭ���������ن����ˡ�
���ǻ�һ�ַ�ʽ��д:
void Swap(int& ra, int& rb)
{
int temp = ra;
ra = rb;
rb = temp;
}
int main()
{
int a = 10;
int b = 20;
Swap(a, b);
return 0;
}
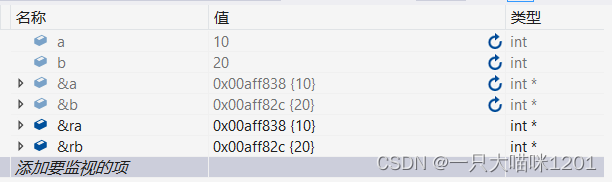
ͨ�����Թ����еļ��Ӵ���,�Ƿ���,��Swap�����е���������ra,rb�ĵ�ַ��main�����еı���a,b�ĵ�ַ����ͬ�ġ�
Ҳ����˵,��ra��rb���д������൱�ڶ�a��b���д���,����Ҳû��ʹ��ָ�롣
��������á�
ͨ������ͼ���ܸ����������ʶ������,�����Ǹ�һ���������������
ע�� :�������ͱ��������ʵ����ͬ�����͵ġ�
���õ�����:
- �����ڶ���ʱ�����ʼ��,�������������ֻ�ж��塣
- һ�����������ж������,Ҳ���ǿ��Ը����������֡�
- ����һ������һ��ʵ��,�ٲ�����������ʵ��,һ������ֻ����Ϊһ������ı���,����ָ����һ������
🍛������
��ν�����þ�����const���ε����ñ���,����ָ��һ��,�漰��һ��Ȩ�����⡣

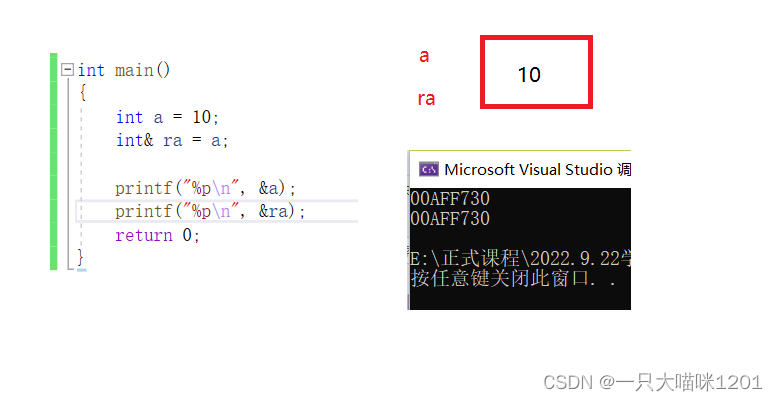
��ͼ�еĴ���,����aԭ���DZ�const���ε�,���г���������,�Dz����Ա��ĵġ�
����ʹ�����ú�,raͬ����ʾ���DZ���a,���Ǵ�ʱ����const������,���Ա����ˡ�
�����Ȩ�ķŴ�,ԭ���Dz����Ա��ĵ�,������������Ժ��������,ԭ���ı����϶��Ͳ�����,�����ڱ����ʱ��ᱨ����
�ٿ�һ�δ���:

��ͼ�еĴ���,����a��û�б�const���ε�,�������ǿ����ĵġ�
ʹ�����ú�,ra��ʾ��Ҳ��a,�����DZ�const���ε�,ra�����Ա��ġ�
�����Ȩ����С,ԭ���ǿ����ĵ�,������˸����ֺ��ܱ�����,��ԭ���ı�����˵����ν,������Ӱ���˼�,�㰮��ô������ô��,��ʱԭ���ı���a�ǿ����ĵ�,����raҲ����Ÿı䡣
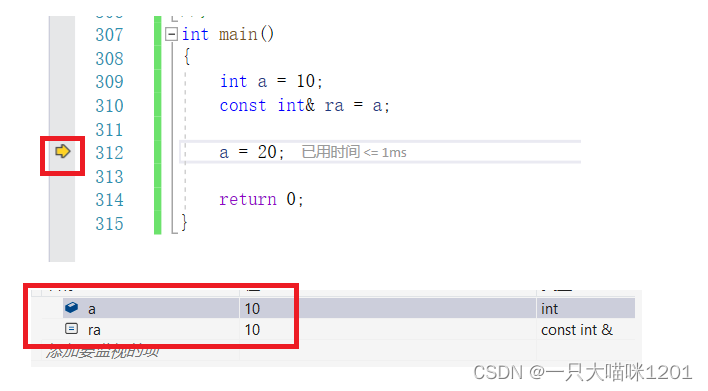
��û��ִ�е��ı�a֮ǰ,ra�е�ֵ��10��

�ڽ�a�ı��20�Ժ�,ra�е�ֵҲ���ű��ˡ�
�ܵ���˵,Ȩ���Ա���С,���Dz����Ա��Ŵ�
🍛���õ�ʹ�ó���
������:
���ǿ�����Ľ�������:
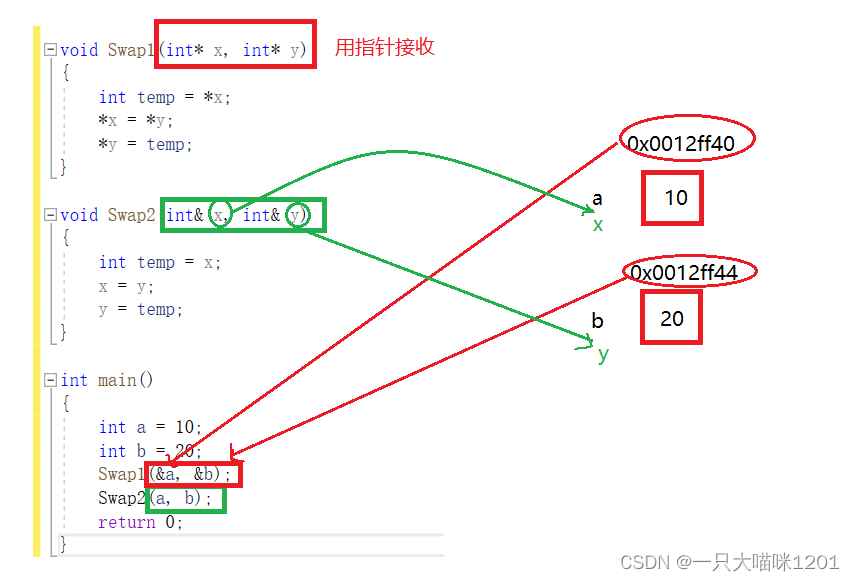
��ǰһֱ����ʹ�õ�Swap1�Ľ�����ʽ,���ǽ�ָ����Ϊʵ�δ�������,�������β�Ҳ��ָ�����,���մ������ĵ�ַ,ͨ�����β�ָ������������Է��ʵ�main�����еı���a��b��
C++��ʹ������,������a��b����ʵ�δ���Swap2,Ҳ���ǽ�����a��b��Ϊ����ʵ��,�������β���int&���������ͱ���,��ʱx��y�ͳ��˱���a��b�ı���,����x��yҲ���Ƿ���a��b��
����Ϊ��Ϊ������ʱ��,���Բ�ʹ��ָ��,�����ββ������ڴ�ռ䡣
������ֵ:
������:
int Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int ret = Count();
return 0;
}
��δ���ܼ�,���ǽ�n��1���ҷ�������
�������Ƿ��������ĵײ���ù���:
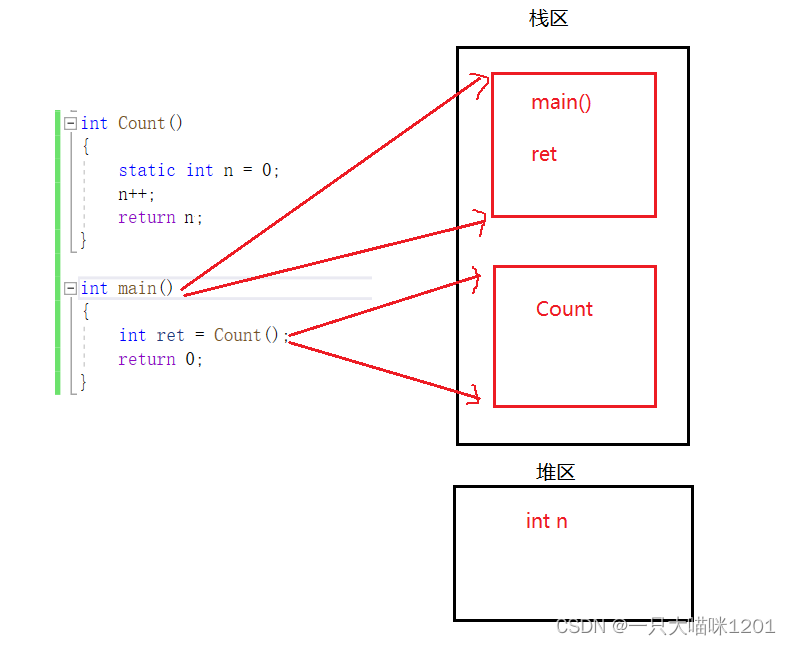
- ������ջ��������main������ջ֡,�����ڸ�ջ֡�д�����int ret����,��ʱret��ֵ�Dz�ȷ����
- ��ִ�е�int ret = Count��ʱ��,��������һ��ջ֡,����Count��ջ֡
- ��ִ��Count��ʽ��ʱ��,�ھ�̬�������˱���n,���ҳ�ʼ��Ϊ0
�����Ǵ���ִ�й����б����Լ�ջ֡�Ĵ������̡�
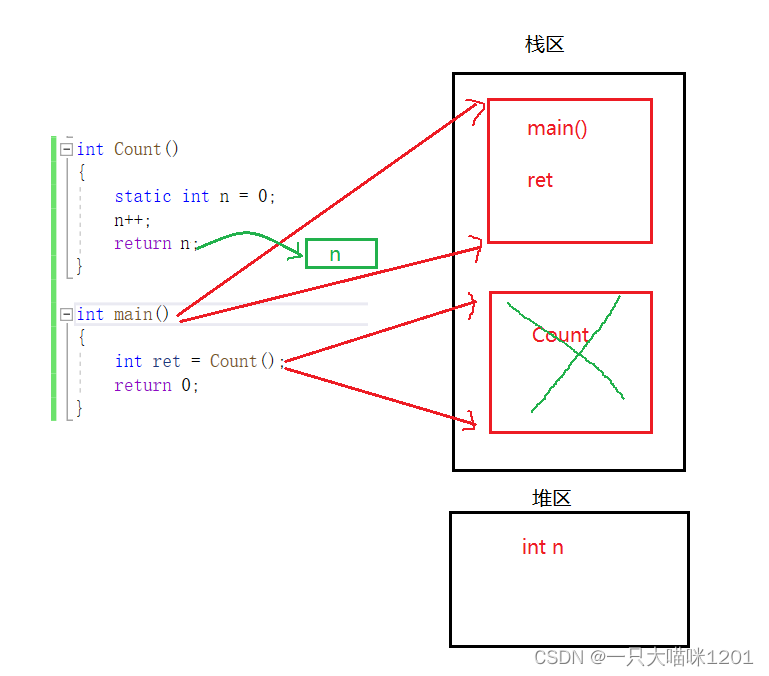
��ִ����Count������ʱ��,�ᴴ��һ����ʱ����(ʵ����һ���Ĵ���),��Ҫ���ص�ֵn������ʱ������,����ͼ�е���ɫС������,���Ҷ�Ӧ��Count������ջ֡Ҳ�������ˡ�
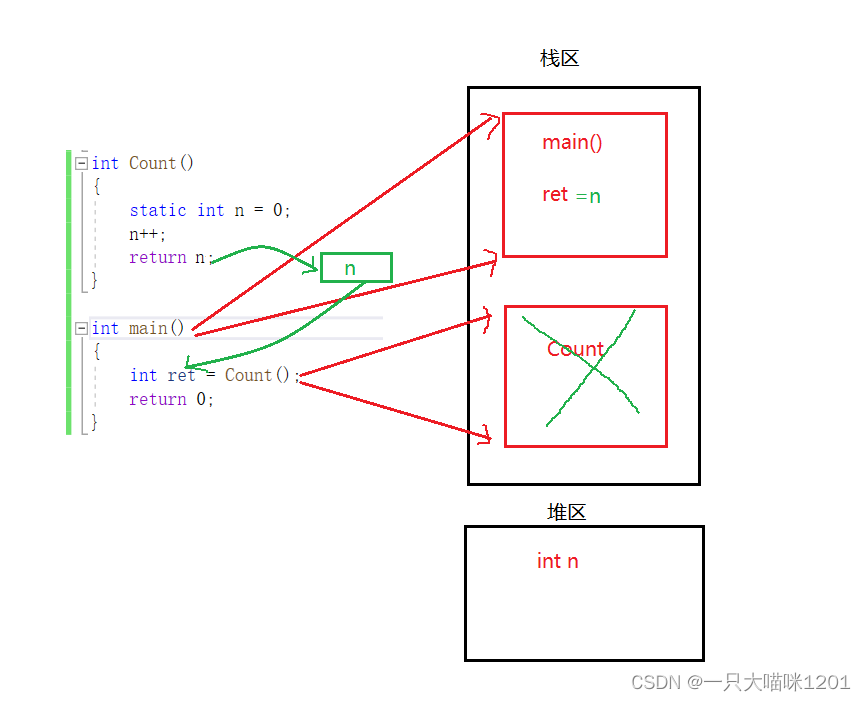
Ȼ����ʱ����n��ֵ����ret,Ҳ���Ƿ�����main����ջ֡�б���ret���ڴ�ռ��С�
˵��:
- ���õĺ����ڷ���ֵ��ʱ��,�Ὣ����ֵ����һ���Ĵ�����,Ҳ����������˵�Ĵ�����һ����ʱ����
- �������ֵռ�õĿռ�ܴ�,��ô�Ͳ��üĴ�������,������main������ջ֡���ٴ���һ������,������ֵ��ǰ���������ʱ�����������ٱ����ú�����ջ֡��
- �ڱ����ú�����ջ֡�����Ժ�,����ֵʱ��ʹ�õļĴ�����������ʱ���ٵı����ռ䶼�ỹ������ϵͳ��
��������ʾ���Ǵ�ֵ����,Ҳ��������һֱʹ�õķ�ʽ,��������C++�е����÷��ء�
��Ȼ���������,ֻ�ǽ������ķ������ij������á�
int& Count()
{
static int n = 0;
n++;
return n;
}
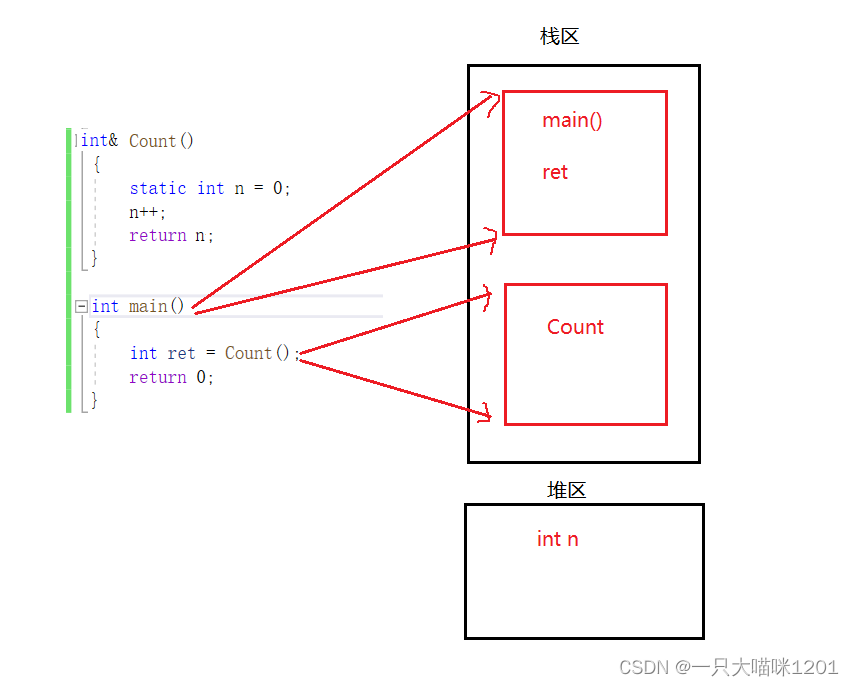
����ջ֡�Լ������Ĵ�����֮ǰ��һ����,�����ڷ��ص�ʱ��:
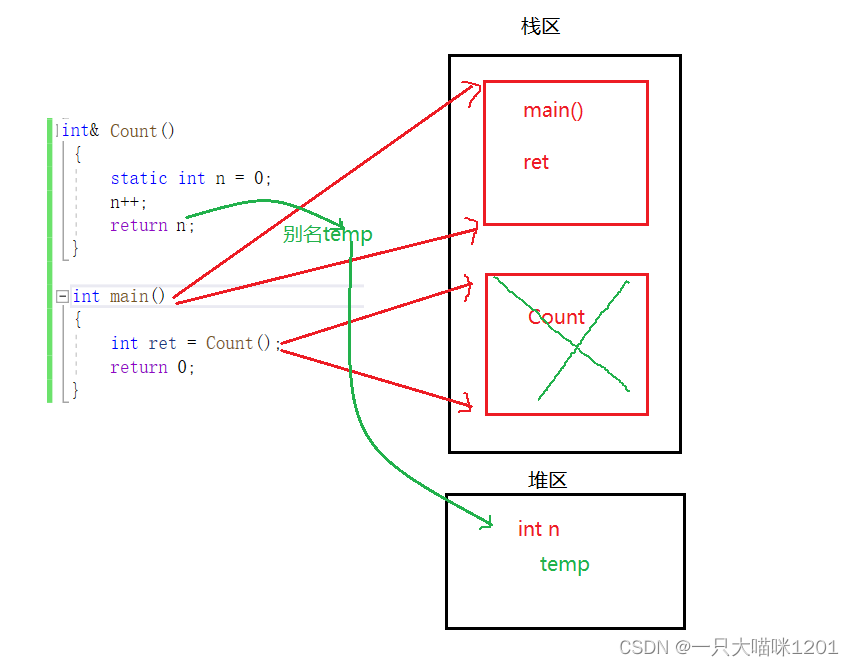
���ص��DZ���n�ı���,���������������temp(ʵ����û��),�������temp�������ڴ�ռ�,�����ڱ���n��ʾ����ͬһ��ռ䡣
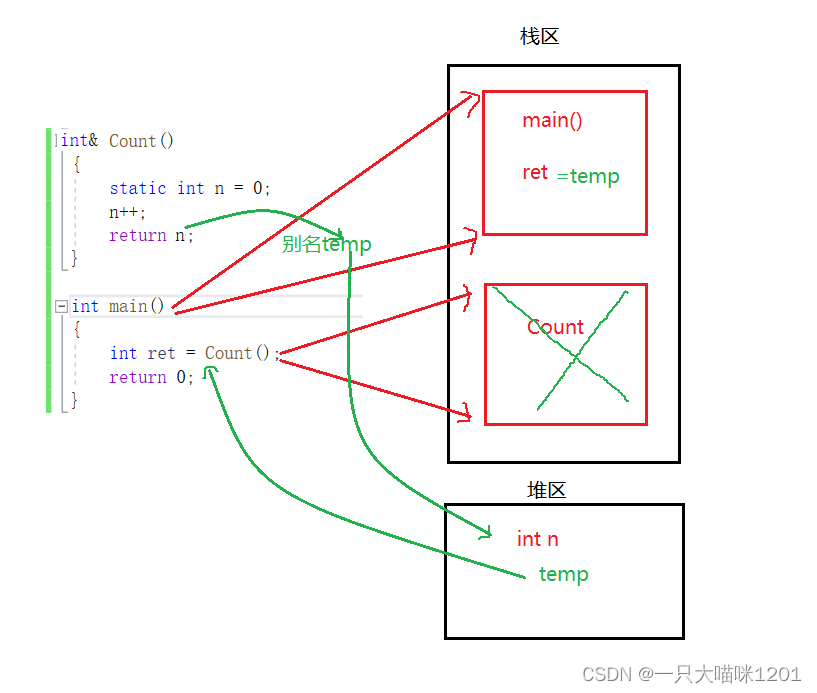
��ʱret�õ���ֵͬ���Ǿ�̬���б���n��ֵ��
��ͬ��:
��Ȼ���ն�����ֵ,����:
- ���÷��صĹ��̲���������ʱ����,����ֱ�ӷ���ԭ�����������ڴ�ռ��е�ֵ��
- ��ֵ���صĹ��̻ᴴ����ʱ����,���ص���ԭ��������������ʱ�����ռ��е�ֵ��
���ڵ��ú����еı����Ǵ����ھ�̬����,���Դ�ֵ���غ����÷��ض�һ��,���ĸ�����,��������ú����еı��������ھ�̬�����߶���,���Ǿ��ڸú�����ջ֡����?��ʱ���÷��صĽ����ʲô?
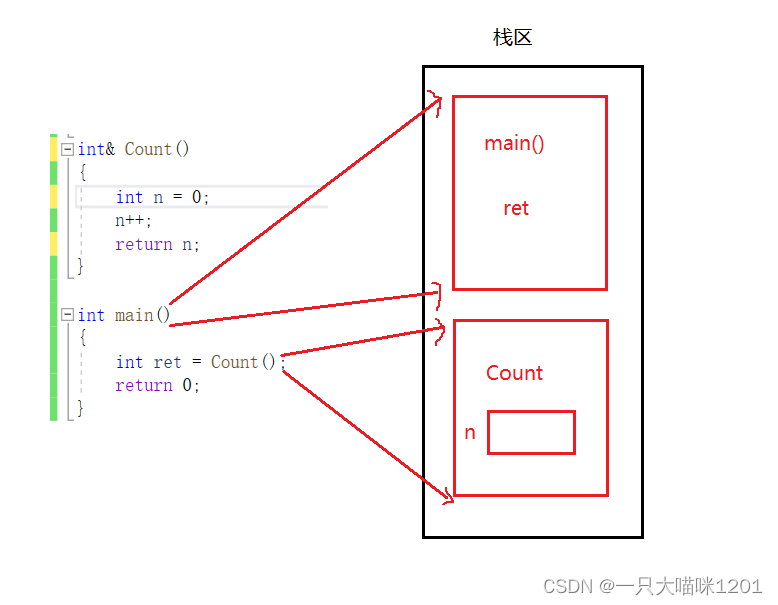
��ʱ����ջ֡�Ĵ������Ǻ�֮ǰһ����,���DZ���n�Ǵ�����Count������ջ֡�еġ�
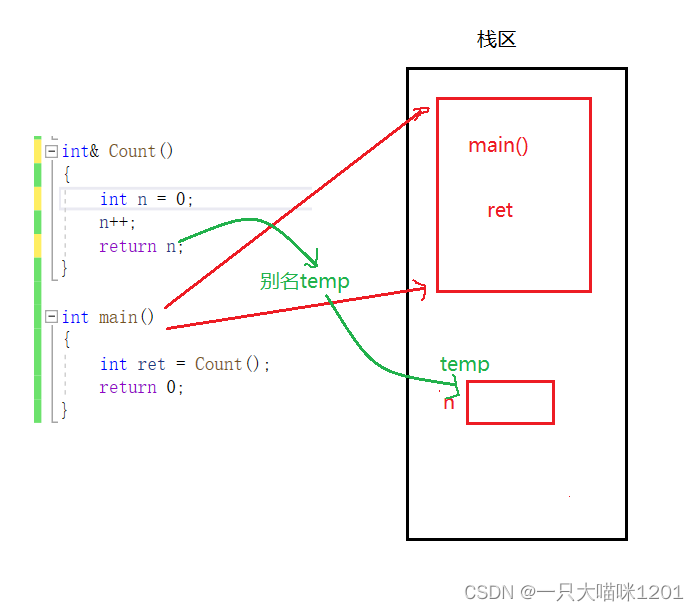
��Count�������ý���ʱ,������ջ֡������,�ڷ���n��ʱ��,��Ϊ���õ������÷���,��������һ����ʱ�ı���,��������������ڴ�ռ�,��ʾ��Ҳ��ԭ���ı���n,��ͼ�еĺ�ɫ����n������
- ��ʱ,ԭ��Count����ջ֡�еı���n���ڵĿռ��Ѿ������˲���ϵͳ
- �������÷��ص�ֵ��Ȼ�ǿռ�n�е�ֵ,����˷Ƿ��ķ��ʡ�
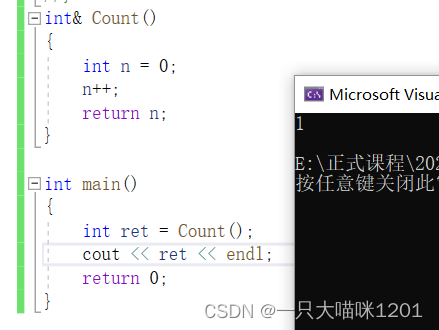
���Ǵ�ʱ�Ľ������1,����Ϊʲô��?
ԭ����,��Ȼ����n���ڵ��ڴ�ռ䷵�����˲���ϵͳ,�����������ֵû�б�����,���Ի����ܹ����ʵ�����ֵ��
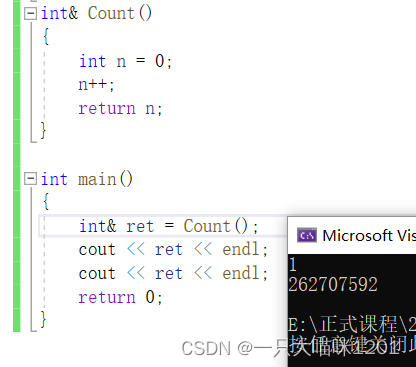
���������ij�����,�ڶ��εõ���ֵ�Ͳ���1��,����������ҷ���һ��ԭ��
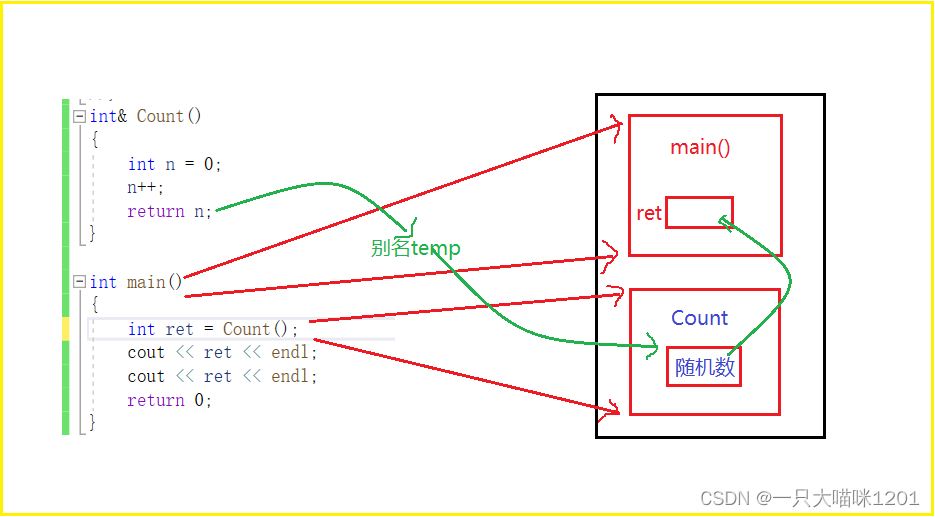
- ����ret�������ñ���ʱ,����main������ջ֡�п����˿ռ�,
- ������Count�������ý���ʱ,�����÷��ص�ֵ�������ret��main����ջ֡�Ŀռ���
- ��ʱԭ��Countջ֡���ڵ�λ����������cout������ջ֡��
- ÿ�δ�ӡ���Ƿ��ʵ�ret�е�ֵ,���Դ�ʱ�Ľ����:

�������������÷��ص�ֵҲʹ�����õ�ʱ��:
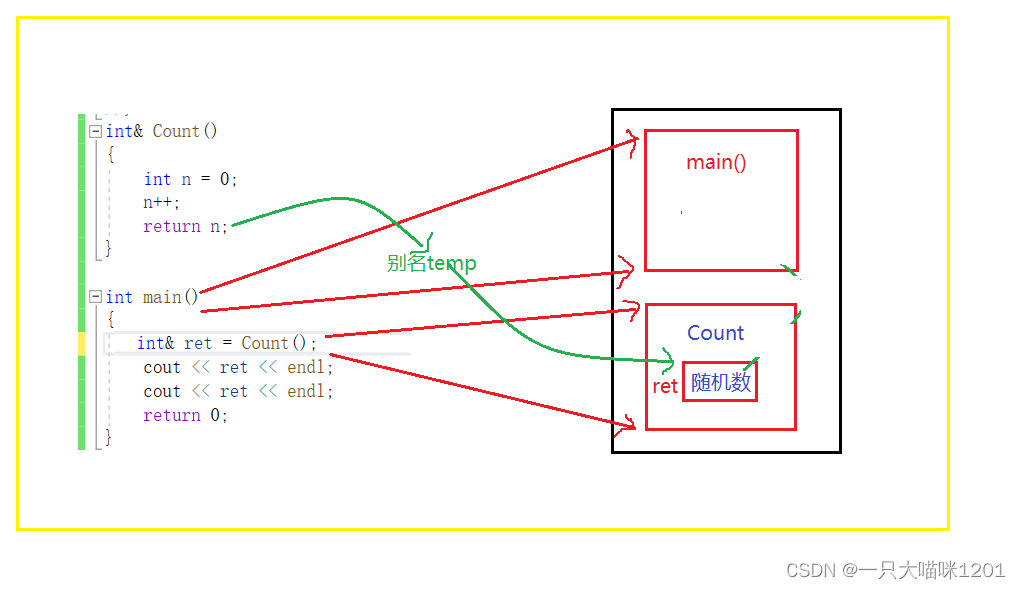
- retʼ�ն���ԭ��count�б���n�ı���
- ��Countջ֡����ʱ,ret�õ�����û���ü��ı��n��ֵ
- ���ÿռ䱻cout��ջ֡ռ�ú�,ԭ������n���ڵ�λ�þͱ�����������ռ��
- ���Դ�ӡ���������ݾͲ�����1��
�������ķ���,��Ӧ���÷������ǿ��Եó�һ������:�����������ʱ,���˺���������,������ض�����(��û����ϵͳ),�����ʹ�����÷���,����Ѿ�����ϵͳ��,�����ʹ�ô�ֵ���ء�
🍛��ֵ��������Ч�ʱȽ�
#include <time.h>
struct A
{
int a[10000];
};
A a;
// ֵ����
A TestFunc1()
{
return a;
}
// ���÷���
A& TestFunc2()
{
return a;
}
void TestReturnByRefOrValue()
{
// ��ֵ��Ϊ�����ķ���ֵ����
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// ��������Ϊ�����ķ���ֵ����
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// �������������������֮���ʱ��
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
}
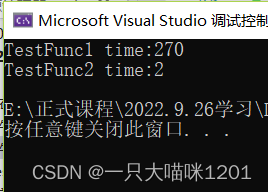
����������˼����,����һ���ṹ�����,�ýṹ������һ��10000��int���ݵ�����,ͨ����ֵ���غ����÷������ַ�ʽ�����������,�������ַ�ʽ�����õ�ʱ���,Ҳ�������ַ�ʽЧ�ʸߡ�
- �����н�����Կ��Կ���,���÷��ص�Ч�ʸ��ڴ�ֵ���ص�Ч��
- ����ǰ�溯��ջ֡���õķ���,����֪��,��ֵ������Ҫ����һ����ʱ����,������ص��������ڿռ�̫��,�ͻ���main������ջ֡�д�����ʱ��������
- �����÷��ز���Ҫ�����κ���ʽ����ʱ����,ֱ�Ӹ�ԭ����������һ������,��ʾ�Ļ���ԭ��������
- ����֪��,ϵͳ�ڴ���������ʱ���������ĵ�,Ҳ������Ҫ����һ����ʱ��
�������ǿ��Եó�:��ֵ����������Ϊ�����Լ�����ֵ������Ч�����ܴ�
🍛���ú�ָ�������
������������þ���һ������,û�ж����ռ�,��������ʵ�干��ͬһ��ռ䡣
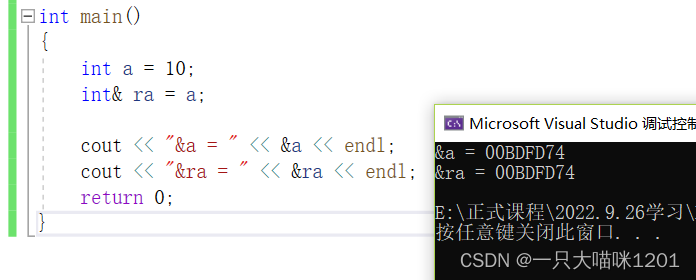
���Կ���,����������ַ��һ����,���ò�û�д����µı����ռ䡣
�������ײ�ʵ����ʵ�����пռ��,��Ϊ�����ǰ���ָ�뷽ʽ��ʵ�ֵġ�

�ӻ�������ǿ��Կ���,�������ñ���ra,�Լ���ra��ֵ���ں�ɫ����,����ָ�������pa,��ͨ��ָ�������a��ֵ������ɫ���ڡ�
- ��ɫ�����ɫ���д������������ͬ��,���ǽ�����a��ֵ��Ϊ20
- �������ǵĻ�����Ҳ����ͬ��,˵�����ú�ָ��ĵײ�ʵ������ͬ�ġ�
���ú�ָ��IJ�ͬ��:
-
���ø����϶���һ�������ı���,ָ��洢һ��������ַ��
-
�����ڶ���ʱ�����ʼ��,ָ��û��Ҫ��
-
�����ڳ�ʼ��ʱ����һ��ʵ���,�Ͳ�������������ʵ��,��ָ��������κ�ʱ��ָ���κ�һ��ͬ����ʵ��
-
û��NULL����,����NULLָ��
-
��sizeof�к��岻ͬ:���ý��Ϊ�������͵Ĵ�С,��ָ��ʼ���ǵ�ַ�ռ���ռ�ֽڸ���(32λƽ̨��ռ4���ֽ�)
-
�����ԼӼ����õ�ʵ������1,ָ���ԼӼ�ָ�����ƫ��һ�����͵Ĵ�С
-
�ж༶ָ��,����û�ж༶����
-
����ʵ�巽ʽ��ͬ,ָ����Ҫ��ʽ������,���ñ������Լ�����
-
���ñ�ָ��ʹ��������Ը���ȫ
🍜��������
����:��inline���εĺ���������������,����ʱC++���������ڵ������������ĵط�չ��,û�к������ý���ջ֡�Ŀ���,�������������������е�Ч�ʡ�
��ʵ��һ���ӷ�����:
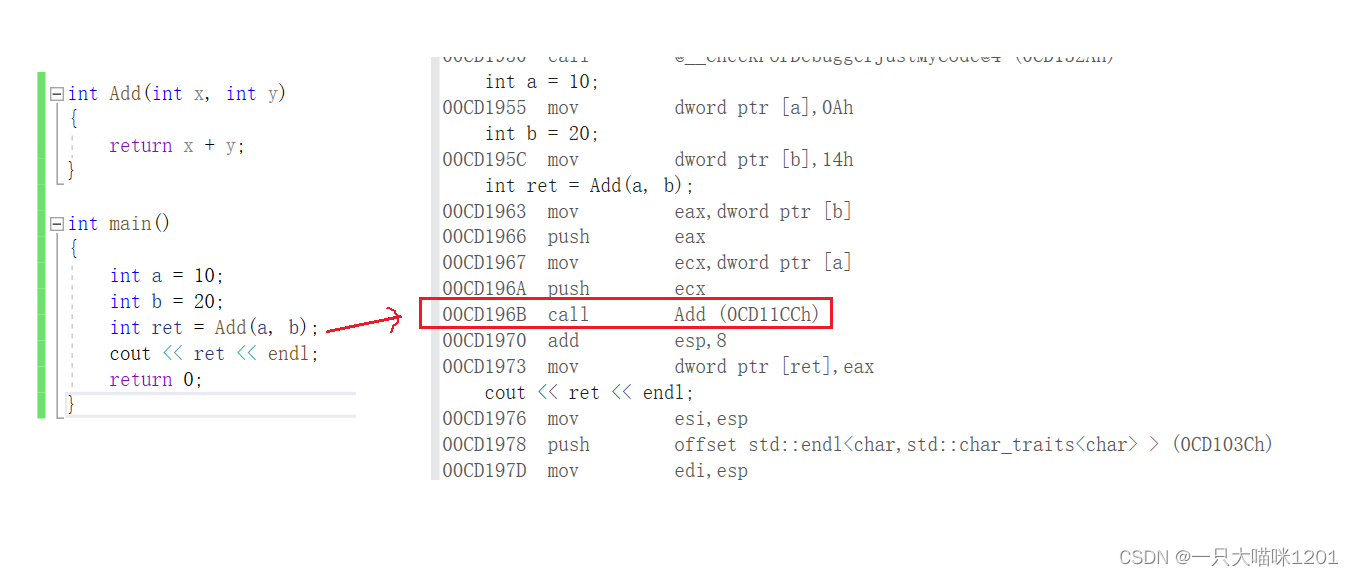
��Ӧ����Ļ��������ǿ��Կ���,�������Ե���һ���������õĹ���,������̻Ὠ������ջ֡��
���ú�дһ���ӷ�����:
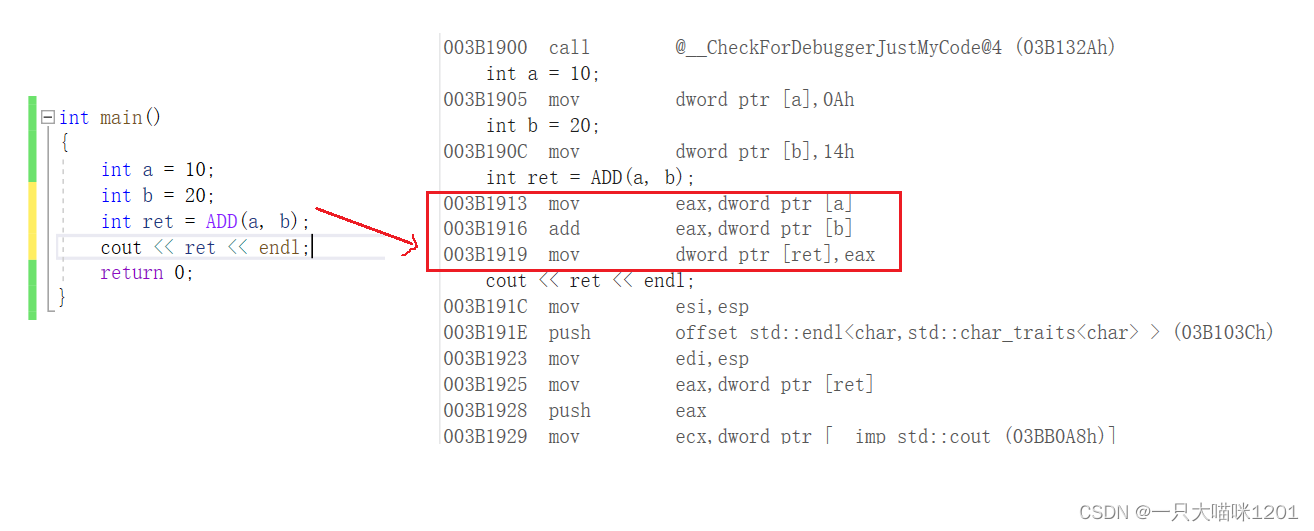
���Կ���,��������,��û�е��ú���,���ǽ����ں�ɫ���λ��չ����,û�н�������ջ֡��
��ʵ,���������ͺ궨��ĺ�����һ����,ͬ�����Ὠ��������ջ֡,���ǻ��ڵ��õ�λ��չ��:
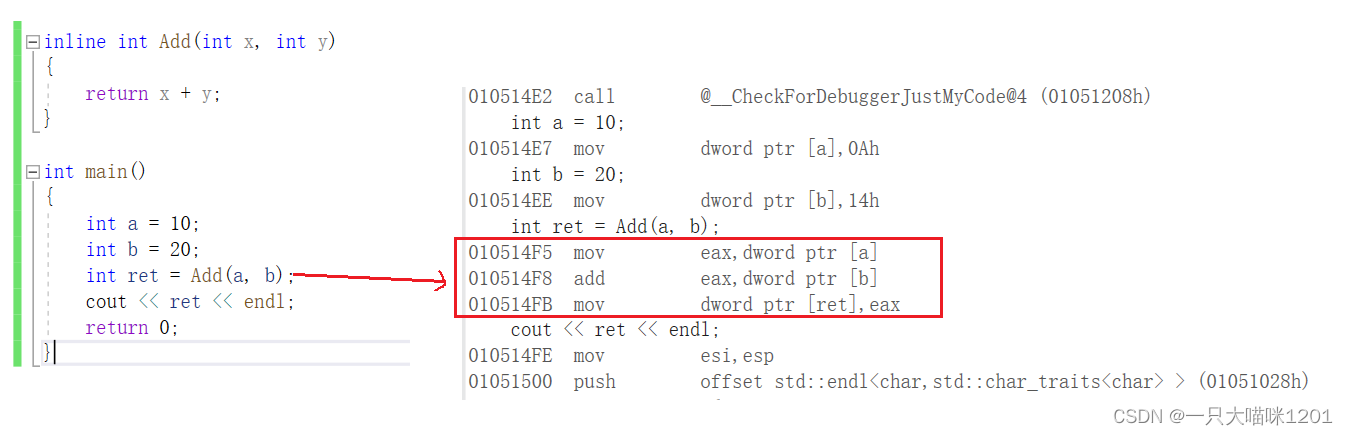
���Կ���,�ں���Addǰ�����inline��,Add�����ͳ�����������,���һ������ͬ��û�е���Add����,���ǽ����ڵ��õ�λ��չ����,û�н���ջ֡��
����֪��,�궨��ĺ����кܶ��ȱ��,����:
- ���ܽ��е���,��Ϊ��Ԥ������ʱ��ͻ��滻��
- ������д��,��Ҫ�Ӻܶ������
- û�����͵ļ��,ʹ����������ȫ
�ڽ��,������Ƶ���õ�С����ʱ,���ǾͿ�������������������궨�塣
��������������:
- inline��һ���Կռ任ʱ�������,�������������������������������,�ڱ����,���ú������滻��������,ȱ��:���ܻ�ʹĿ���ļ����,����:���˵��ÿ���,��߳�������Ч��,��Ϊû�н�������ջ֡��
- inline���ڱ���������ֻ��һ������,��ͬ����������inlineʵ�ֻ��ƿ��ܲ�ͬ,һ�㽨��:��������ģ��С(���������Ǻܳ�,����û��ȷ��˵��,ȡ���ڱ������ڲ�ʵ��)�����ǵݹ顢��Ƶ�����õĺ�������inline����,��������������inline���ԡ�

- ��������,������һ������,��������100�д���,�������ĵط���10000��
- �����ʹ����������,�������10000+100�д���,����10000�ǵ����������,100�Ǻ����е����
- ���ʹ����������,��������10000*100 = 100w�д���,��ʱ�������ͻἱ������,���Ա��������Զ��������ֲ�����������
- nline�����������Ͷ������,����ᵼ�����Ӵ�����Ϊinline��չ��,��û�к�����ַ��,���Ӿͻ��Ҳ�����
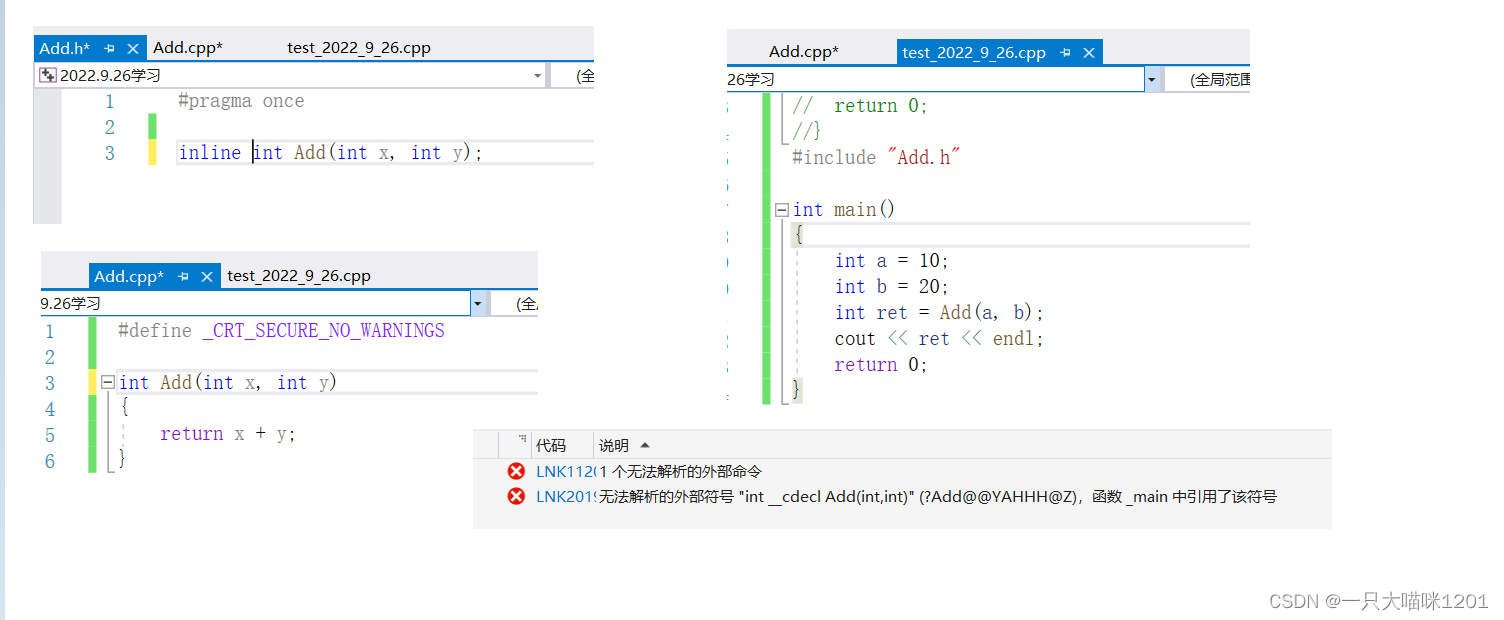
��ͷ�ļ���,����������������inline,����Add����������,�ڵ���Add������ʱ����,�Ҳ���Add����,����ʲôԭ����?
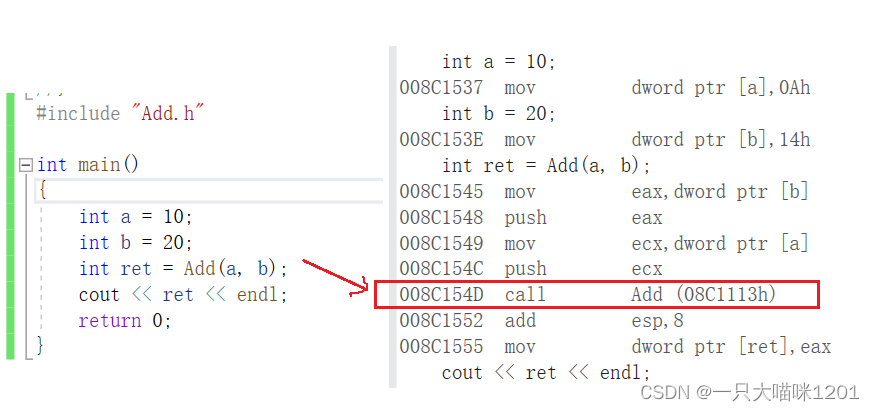
������������,�ڵ���Add������ʱ��,���ǿ����������������������һ����ַ��
����������������Ԥ����������ϸ�����,�����ΪԤ����,����,�����������,��Ԥ������ʱ��,��Add.h�е�����չ�����Ƶ���Դ�ļ���,��ʱԴ�ļ���������:

�ڱ����,���βη��ű�,��Ϊ����Add��inline����,���Ա���������Ϊ����һ��������,���ԾͲ����βη��ű�,Ҳ�����Add�����ַ,���������ڵ������ĵط�չ������
���������������Ժ�,���������,��ʱtest.cpp��Add.cpp��Դ�ļ������ӵ�һ��,���ӵ�ʱ���ȥAdd���������ڵĵ�ַ��Ѱ�Һ���Add���е��á�
����,��Ϊ����inline,��������û�и��������ַ,���������ӵ�ʱ����Ҳ�����Ӧ��Add����,���Ծͻᱨ���Ӵ���
Ϊ�˱�����������ij���,ͨ���������������Ķ���������ֿ�,ֱ���ڶ����ʱ��ʹ��inline���μ���,��Ϊ��������ͨ��Ҳ�Ƚ϶�,���Ծ�д�ڵ������ĺ�����ǰ�漴�ɡ�
🍜auto�ؼ���(C++11)
���ų���Խ��Խ����,�������õ�������ҲԽ��Խ����,����������:
- ��������ƴд
- ���岻��ȷ�������׳���
���Ƿ����������ʲô���ӵ�,�Լ�д�ij����ѵ㻹��д����?
��һ������Ĵ���:
#include <string>
#include <map>
int main()
{
std::map<std::string, std::string> m{ { "apple", "ƻ��" }, { "orange", "����" },{"pear","��"} };
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
//....
}
return 0;
}
����std::map<std::string, std::string>::iterator��һ������,���Ǹ�����̫����,�ر�����д����������ͬѧ�����Ѿ��뵽:����ͨ��typedef������ȡ����,����:
typedef std::map<std::string, std::string> Map;
��ȷʵ�Ǹ��ð취,�������dz�����Ҫ��ֵ��������,��ʱ����Ҫ�ж�Ҫ����ֵ��ʲô����,���ܴ�����Ӧ�ı���,��ʱ��Ҫ�����֪��ֵ�����Ϳɲ�����һ���������顣
����C++11��auto�������µĺ���,
- C++11��,��ίԱ�ḳ����autoȫ�µĺ��弴:
- auto������һ���洢����ָʾ��,������Ϊһ���µ�����ָʾ����ָʾ������,auto�����ı��������ɱ������ڱ���ʱ���Ƶ����á�
Ҳ����,auto���εı�����Ҫ�������Լ�ȥ�жϸñ�����ʲô����,��������Ҫ����ȥ�ж�,�ñ����������Ǹɻ�,�����Dz��Ǻ�ˬ?
int Testauto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = Testauto();
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
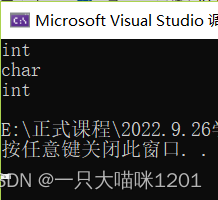
��������?�������ﲢû����������b,c,d��ʲô����,ֻ����auto�����˱�����,�ڴ�ӡ���ǵ����͵�ʱ��,ȷ�Ĵ�ӡ�������ǵ����͡�
ע��:
- ʹ��auto�������ʱ���������г�ʼ��,�ڱ���α�������Ҫ���ݳ�ʼ������ʽ���Ƶ�auto��ʵ�����͡�
- ���auto������һ�֡����͡�������,����һ����������ʱ�ġ�ռλ����,�������ڱ����ڻὫauto�滻Ϊ����ʵ�ʵ����͡�
🍛auto��ʹ��ϸ��
- auto��ָ������ý������ʹ��
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
return 0;
}
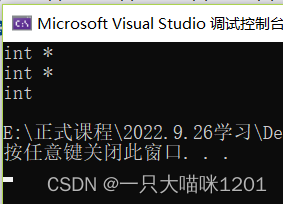
���ݽ�����Կ���:
- auto����ָ�����͵�ʱ��,��û��* ����һ����,������������Ϊauto��auto*���εı�����ָ������
- auto����ָ���ʱ��,����ʹ��&��,��Ϊint&������һ������,������������һ�����á�
- ͬһ�ж���������

���Կ��������б�����
- ��ɫ���е�����ȷ��,��һ�еı�������int���͵�,����auto�ɹ����ƶϳ������ǵ�����
- ��ɫ���е��Ǵ����,��Ϊ��һ�еı�������int��double����,������ͬ�����͡�
- ����auto����һ�ж��������ʱ��,���������ͱ��붼��һ�µ�,��Ϊautoֻ����ݵ�һ��ֵ���������ƶϱ��������͡�
autoҲ�в����ƶϳ��������:
- auto�����������IJ���
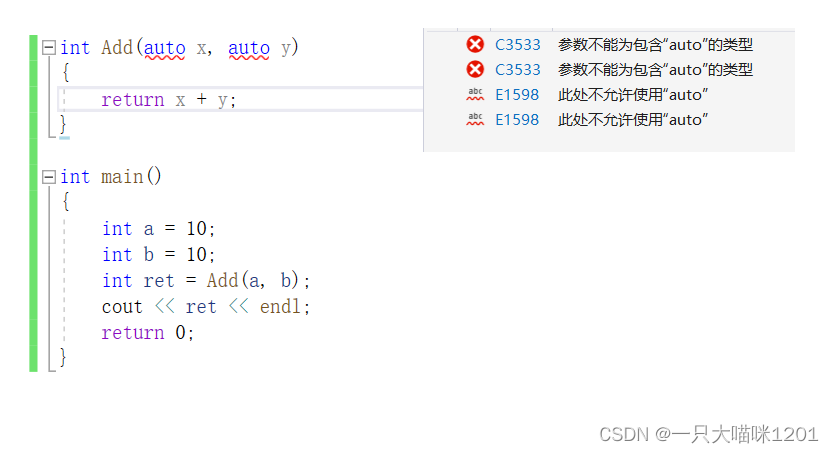
����ֱ�Ӿͻᱨ��,��Ϊ�������������ƶϳ���������������,��Ϊ����ȷ���������IJ�����ʲô����,������ʵ����int����,���������char������?
��Ϊ��ִ�г����ʱ��,Add�����ڴ���ջ֡��ʱ��֪��ʵ����ʲô����,���ԾͲ��ܹ��ƶϳ��βε����͡�
- auto����ֱ��������������
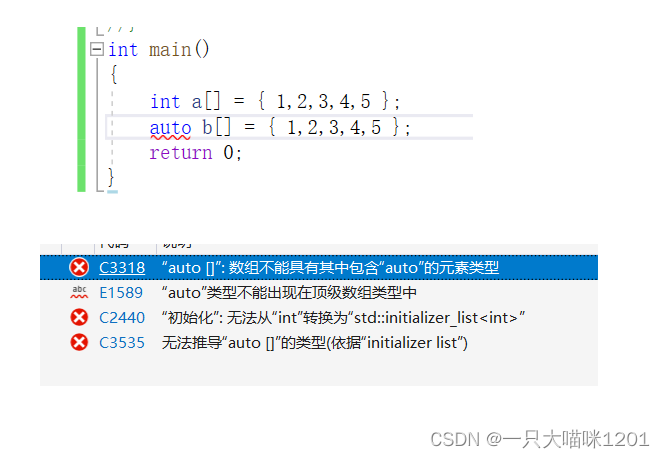
Ϊ�˱�����C++98�е�auto��������,C++11ֻ������auto��Ϊ����ָʾ�����÷���
🍜���ڷ�Χ��forѭ��(C++11)
����һ������,��֮ǰ����ֻ����������ʵ�ֵ�:
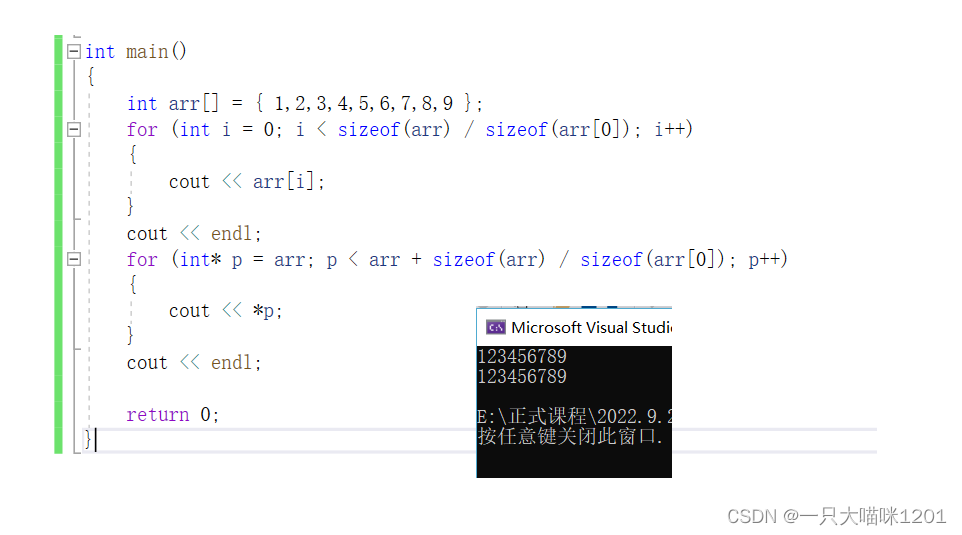
ֻ��ͨ���������е�һ����ʵ��,���ڱ����ٸ��ߴ��һ������:
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9 };
for (auto e : arr)
{
cout << e;
}
cout << endl;
return 0;
}
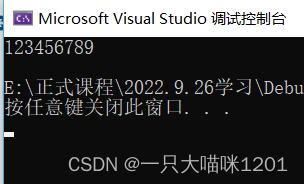
���Կ���,ͬ��ʵ���������ѭ����ӡ��
�������Դ�ӡ,�����Ըı������е�Ԫ��:
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9 };
for (auto& i : arr)
i *= 2;
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
return 0;
}
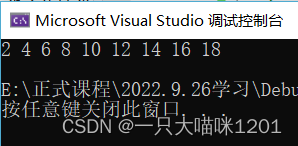
���Կ���,��ʱ�����е����ݶ������˶�����
��������ʹ�õľ���auto�ؼ���,�������ܹ��ƶ���������,�����Խ��л��ڷ�Χѭ����
ע��:
- ����һ���з�Χ�ļ��϶���,�ɳ���Ա��˵��ѭ���ķ�Χ�Ƕ����,��ʱ����������
- ���C++11�������˻��ڷ�Χ��forѭ����forѭ�����������ð�š� :����Ϊ������:��һ�����Ƿ�Χ�����ڵ����ı���,�ڶ��������ʾ�������ķ�Χ��
- ���ﱻ�����ķ�Χ������ȷ���ġ�
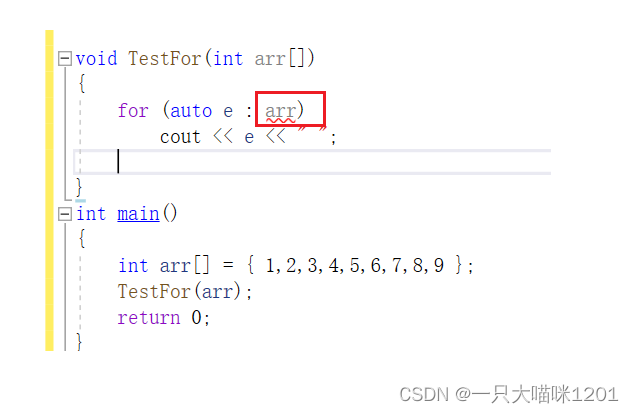
���ʱ�Ͳ����Խ��л��ڷ�Χ��ѭ��,��Ϊ�����Χ����ȷ����
🍜ָ���ֵnullptr(C++11)
- �����õ�C/C++���ϰ����,����һ������ʱ��ø��ñ���һ�����ʵij�ʼֵ,������ܻ���ֲ���Ԥ�ϵĴ���,����δ��ʼ����ָ��,�ͻ����Ұָ��Ĵ���
���һ��ָ��û�кϷ���ָ��,���ǻ������ǰ������·�ʽ������г�ʼ��:
int main()
{
int* p1 = NULL;
int* p2 = 0;
return 0;
}
��C���ԵĴ�����,���Ǿ���ʹ�õ�NULL��ָ��,ʵ����NULL��һ����
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
���Կ���,NULL���ܱ�����Ϊ���泣��0,���߱�����Ϊ������ָ��(void*)�ij��������۲�ȡ���ֶ���,��ʹ�ÿ�ֵ��ָ��ʱ,�����ɱ���Ļ�����һЩ�鷳,����:
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}
����������ͨ��f(NULL)����ָ��汾��f(int*)����,��������NULL�������0,��������ij�����㣡�
��C++98��,���泣��0�ȿ�����һ����������,Ҳ�����������͵�ָ��(void*)����,���DZ�����Ĭ������½��俴����һ�����γ���,���Ҫ���䰴��ָ�뷽ʽ��ʹ��,����������ǿת(void *)0��
��Ϊ���������ߵĸ�������,������C++11��������nullptr��ʾ��ָ�롣
������ǰNULL���÷���һ����,���DZ������ڵ������غ�����һЩ����,���������ڽ��ʹ�ÿ�ָ���ʱ���ʹ��nullptr��
ע��:
-
��ʹ��nullptr��ʾָ���ֵʱ,����Ҫ����ͷ�ļ�,��Ϊnullptr��C++11��Ϊ�¹ؼ�������ġ�
-
��C++11��,sizeof(nullptr) �� sizeof((void*)0)��ռ���ֽ�����ͬ��
-
Ϊ����ߴ���Ľ�׳��,�ں�����ʾָ���ֵʱ�������ʹ��nullptr��
🍜�ܽ�
ͨ��C++����֪ʶ(��)����ƪ����,�����Ѿ��˽���C++����C�IJ���������ӵ�һЩ�����,������Щ֪ʶ,��ζ���Ѿ�����C++�����ִ�,�Ϳ���ȥ��������Ͷ���������ĸ����ˡ�