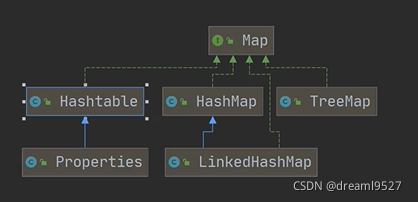
ЧАУцбЇЯАHashSetЕФЪБКђ,вбОЫЕЙ§СЫ,HashSetЕФЕзВуОЭЪЧHashMap,ЕЋЪЧЧАУцЕФМќжЕЖд<key,value>,ЦфжаkeyЪЧдіМгЕФдЊЫи,ЖјvalueЪЧвЛИіPRESENTЁЃ
жаPRESENTетИіОЭЪЧвЛИіОВЬЌfinalГЃСП,РраЭЮЊobjectРраЭ
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
ЖјЯждкбЇЯАЕФmapМЏКЯ,БЃДцЕФЪ§ОнЪЧгГЩфЙиЯЕKey-Value,MapжаЕФKey-ValueПЩвдЪЧШЮвтЕФв§гУРраЭЪ§Он,ЫћУЧЖМЛсЗтзАЕНHashMap$NodeжаЁЃ
MapжаЕФkeyЪЧВЛдЪаэжиИДЕФ,MapжаЕФkeyПЩвдЮЊnull,ЕЋЪЧжЛФмгавЛИі,ЖјvalueЕФЛА,ПЩвдЮЊnull,вВПЩвдЩшжУЖрИіЁЃMapжаЕФkeyГЃЪЧStringРраЭЁЃ
ЬэМгЯрЭЌЕФkey,ЛсИВИЧдРДЕФжЕЁЃ
Key-ValueжЎМфЪЧвЛвЛЖдгІЕФЙиЯЕ,ЫљвдЭЈЙ§key,ПЩвдевЕНvalueжЕЁЃ
?
MapМЏКЯГЃгУЕФЗНЗЈга:
put(Key,Value).
get(key)
remove(key)? ?remove(Key,Value)? ? ЩОГ§дЊЫи,ПЩвдИљОнМќЛђепМќжЕЖдРДЩОГ§
size()? дЊЫиИіЪ§
isEmpty() ЪЧЗёЮЊПе
clear()? ?ЧхГ§ШЋВПдЊЫи
containskey(key) ВщПДМќЪЧЗёДцдк
гЩгкMapВЛФмжБНгnewГіРД,ЫљвдгУЫќзгРрHashMapРДЪЕЯж,ЪЕМЪЩЯбЇЯАHashSetЧАУцвбОЫЕСЫЯТ,ЕЋЪЧЮвЙРУўЮввВУЛЫЕЧхГў,жиаТРД
public class MapStudy {
public static void main(String[] args) {
Map map = new HashMap();
map.put("1","ЮфЕБЩН");
map.put("2","ЖыУМЩН");
????????map.put("1","еХШ§Зс")
map.put("3","ЫЩЩН");
System.out.println(map);
}
}
дДТыЦЪЮі:
Map map = new HashMap();етИіВйзїЕїгУЙЙдьЦїГѕЪМЛЏМгдивђзгLoadFactor(0.75)
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
ШЛКѓдйРДВйзї map.put("1","ЮфЕБЩН");етИіЪЧЬэМгжЕНјШЅ,ШчКЮЬэМгЕФ
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
НјШыputЗНЗЈ,ДЋШыkeyКЭvalueетСНИіжЕ,вВОЭЪЧkey=1,value=ЮфЕБЩНЁЃШЛКѓputРяЛсЗЕЛивЛИіputVal(hash(key), key, value, false, true);етИіЗНЗЈ,етИіЗНЗЈРяЛЙгавЛИіЗНЗЈhash(key)ЁЃ
ЮвУЧЬэМгЪ§жЕНјШЅ,ЪЧЭЈЙ§МЦЫуhashжЕ,ШЛКѓдйЬэМгНјШЅЕФЁЃ
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
ЖјдкетРяЕФhashжЕВЛЭъШЋЕШгкhashcodeЁЃвђЮЊетИіhashжЕЛсетбљШЁ(h = key.hashCode()) ^ (h >>> 16)ЮоЗћКХгввЦ16ЮЛ^дЫЫуетИіh = key.hashCode()ЁЃ
ШЛКѓЗЕЛиетИіhashжЕЁЃШЛКѓдйНјШЅ putVal(hash(key), key, value, false, true)ЗНЗЈжа
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
ЯТУцетИіЪЧКЫаФДњТыЁЃ
Node<K,V>[] tab; Node<K,V> p; int n, i;етИіЖЈвхЕФОжВПБфСП
ЯждкЕФЛА,ЮвУЧЛЙУЛгаДДНЈГі,дЊЫиЗХЕФЕиЗНЁЃ
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
ЪзЯШДњТыЛсНјааifХаЖЯ,ЮвУЧетРяПЊЪМЕФЪБКђДцЗХдЊЫиЕФЕиЗНОЭЪЧПеЕФ(tab = table) == null,ЫљвдЫќЛсНјШЅетРя,n = (tab = resize()).length;ШЛКѓНјаавЛИіРЉШнЕФДІРэresize()ЁЃетРяДцЗХдЊЫиЕФЕиЗНЪЧЪВУДРраЭ,ЕШЯТОЭЛсНвЯў
DEFAULT_INITIAL_CAPACITYФЌШЯЕФРЉШн16,ЯТДЮЕФРЉШнЮЊ
DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY=12,ЦфжаетИіОЭЪЧМгдивђзгDEFAULT_LOAD_FACTOR(0.75)
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
РЉШнВЛЯИЫЕ,ЫќзюКѓЛсЗЕЛи return newTab;ЯждкЫќОЭПЊБйГіСЫШнСПЮЊ16ЕФЪ§зщЁЃдйКѓЫќМЬајifХаЖЯ,ШЛКѓИљОн tab[i] = newNode(hash, key, value, null);newNodeЕФВйзї, newNodeРяЕФnew NodeНјаазАЯфВйзїЁЃ
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
ЭЌЪБдкЖдгІЕФЪ§зщtab[i] = newNode(hash, key, value, null)жаЁЃЕНФПЧАЮЊжЙ,вбОГЩЙІЕФМгШыСЫвЛИідЊЫиЁЃШЛКѓ
++modCount;
if (++size > threshold) resize();
afterNodeInsertion(evict);
return null;
ЯждкЕФЮвУЧвбОПЩвдПДМћСЫ,ЮвУЧЕФЪ§зщРраЭЪЧЩЖзгСЫ--->HashMap$Node
newNode(hash, key, value, null);
ЪЕМЪЩЯЪЧHashMap$Node node=newNode(hash, key, value, null).ЕЋЪЧЮЊСЫЗНБуБщРњЪ§зщ,ЛЙЛсДДНЈEntrySetМЏКЯ,ИУМЏКЯДцЗХЕФдЊЫиЕФРраЭОЭЪЧEntryЁЃ
Set<Map,Entry<key,value>>EntrySet.
ЕЋЪЧЪЕМЪЩЯ,етИіEnteySetжаДцЗХЕФЛЙЪЧетИіHashMap$NodeЁЃЮЊЪВУДетУДЫЕФи?вђЮЊетNode<K,V> implements Map.Entry<K,V> ,вВОЭЪЧNodeЪЕЯжСЫEntry.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
ЙщИљЕНЕз,гУетИіEnteySetЕФдвђОЭЪЧЮЊСЫЗНБуЮвУЧЕФБщРњ
EnteySetЬсЙЉСЫ2ИіЗНЗЈ,вЛИіЪЧgetKey().вЛИіЪЧgetValue().
for(Object obj:set){
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey+"-"+entry.getValue());}
?Set set =map.keySet()? ПЩвдШЁГіkey.
Collection value= map.value() ПЩвдШЁжЕvalue
ЮЊЪВУДSetКЭCollectionФмВйзїетИіЪ§зщжаЕФдЊЫи,двђЪЧSetжИЯђСЫHashMap$NodeЕФKey,ПЩвдВйзїШЁГіетИіжЕЁЃCollectionвВжИЯђСЫHashMap$NodeЕФValue,ЭЌбљПЩвдШЁГіетИіжЕЁЃ
ЕНФПЧАЮЛжУ,ЮвУЧвбОЬэМгШыСЫвЛИідЊЫиСЫЁЃ
ЕкЖўИі map.put("2","ЖыУМЩН");ЭЌбљЪЧЯШНјааМЦЫуhashжЕ,ШЛФъНјШы putValжаНјааХаЖЯЁЃвђЮЊвбОМгШыСЫвЛИідЊЫи,ЫљвдзюЯШЕФетИіХаЖЯВЛНјШы
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
ЛсжБНгНјШыжаНјаа,аТдідЊЫи,гЩгкетИідЊЫиЧАУцУЛгаЬэМг,ЫљвджБНгНјШыетИіtableРяЁЃ
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
ВйзїЕФЛА,ОЭИњЩЯУцвЛбљЁЃ
ЬэМгЯрЭЌЕФkeyжЕ,ЫќЛсИВИЧдРДЕФЪ§ЁЃетИіВйзїЕФБШНЯФбЕу
??map.put("1","еХШ§Зс")
ЭЌбљ,ЫќЛсНјааhashжЕЕУМЦЫу,гЩгкЧАУцвбОМгШыСЫвЛИіЭЌбљЕФkey,ЫљвдЫќВЛЛсНјШЅетИіifХаЖЯ СЫ,if ((p = tab[i = (n - 1) & hash]) == null)? ?ЁЃtab[i] = newNode(hash, key, value, null);
ЫќЛсНјШыЯТУцЕФХаЖЯ,ШЛКѓНјааЬцЛЛжЕ,ШЛКѓЛЙВЛНјаа++modCount;жЎКѓЕФВйзї,вђЮЊЫќжЛЪЧЬцЛЛСЫ,ВЛЪЧаТдівЛИідЊЫиЁЃ
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
ШЛКѓЯТУцЛЙга2ЖЮВйзї,ЗжБ№ЪЧвЛИіСДБэВйзї,вЛИіКьКкЪ§ЪЧВйзїЁЃ
КьКкЪїВйзї
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
КьКкЪїетРя,ЮвУЧОЭЯШВЛЫЕ,ЕШКѓУцдйРД
СДБэВйзї
ЫќЪЧЭЈЙ§forбЛЗБщРњетИіСДБэЕФ,ЖјЧветИіforбЛЗЪЧИіЫРбЛЗ,жЛФмЭЈЙ§breakЬјГі
ЕквЛбЛЗ,ЪЧеввЛШІ,ШЛКѓУЛЗЂЯж,ОЭдкзюКѓвЛИіКѓУцЬэМг,ШЛКѓНјааХаЖЯетИіСДБэГЄЖШЪЧВЛЪЧвбО8СЫ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash);ШЛКѓНјааЪїЛЏВйзїЁЃЕкЖўИіifХаЖЯЪЧ,евЕНвЛИіЯрЭЌЕФ,ОЭЭЫГі,ШЛКѓНјааЬцЛЛЁЃ
зЂвтЕу:СДБэГЄЖШДяЕНАЫ,ВЂВЛЪЧСЂМДЪїЛЏ,ЛЙвЊНјааХаЖЯетИіtableЪЧЗёвбОДѓгкЕШгк64ГЄЖШ,ВХНјааЪїЛЏ
{ for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; }?
if (e != null) { // existing mapping for key V
oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; }
?
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i;//етИіЖЈвхЕФОжВПБфСП if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
mapМЏКЯЕФБщРњЗНЪН
foreachбЛЗКЭЕќДњЦїбЛЗ
1.ЯШШЁГіkey,дйЭЈЙ§keyШЁГіvalueжЕ
Set keySet = map.keySet();
for (Object key:keySet
) {
System.out.println(key+"-"+map.get(key));
}
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key+"-"+map.get(key));
}
2.ЛёШЁvaluesЕФжЕ
Collection values = map.values();
for (Object value:values
) {
System.out.println(value);
}
3.ЛёШЁЫљгаЙиЯЕЕФkey-value
Set entrySet = map.entrySet();
for (Object obj:entrySet
) {
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry);
}
System.out.println("==============");
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
Map.Entry m= (Map.Entry) next;
System.out.println(m.getKey()+"="+m.getValue());
System.out.println(next.getClass());
}
етРяЮвЗИСЫвЛИіаЁДэЮѓIterator,ШЁДэЖдЯѓСЫ,ШЁГЩketSetЕФ,ИуЕФЮвжБНгЛГвЩШЫЩњСЫ,авКУЮвЭЈЙ§СЫgetClass()етИіЗНЗЈ,ЕУЕНСЫЗЕЛиЕФЖдЯѓКЭЮвШЁЕФЖдЯѓВЛвЛбљ,ЮввЛЯТзгОЭЛиЙ§ЩёРДСЫЁЃ
?