导学
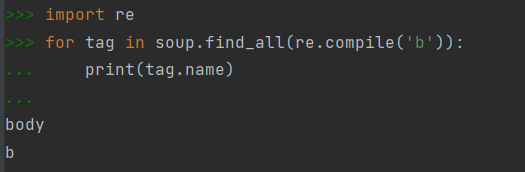
requests库与beautiful soup库结合使用解析html页面
安装命令pip install beautifulsoup4
单元4:Beautiful Soup库入门
beautifulsoup4库的安装
演示hmtl页面地址:http://python123.io/ws/demo.html
识别出源代码
import requests
r = requests.get('http://python123.io/ws/demo.html')
print(r.text)
解析出的html页面文本内容
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
解析成规则html页面
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
from bs4 import BeautifulSoup #重点
soup = BeautifulSoup(demo,"html.parser")#重点
解析出的规则页面
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
</p>
</body>
</html>
Beautiful Soup库的基本元素
是解析html和xml(解析标签维护遍历文’标签树‘)的功能库

最常用引入方式:from bs4 import BeautifulSoup
使用方式:soup = BeautifulSoup("<html>data</html>","html.parser")
soup2 = BeautifulSoup(open("D://demo.hmtl"),"html.parser").
Beautiful Soup解析器

Beautiful Soup类的基本元素

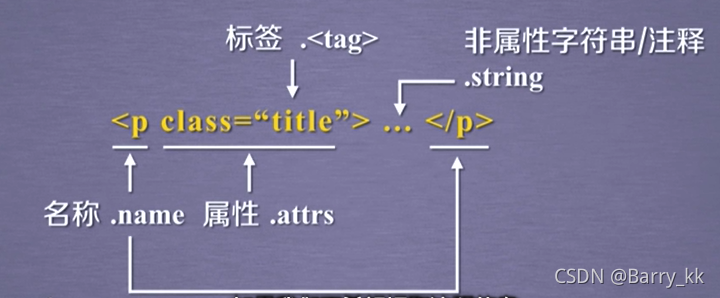
标签tag:
标签的名字Name:
标签的属性Attributes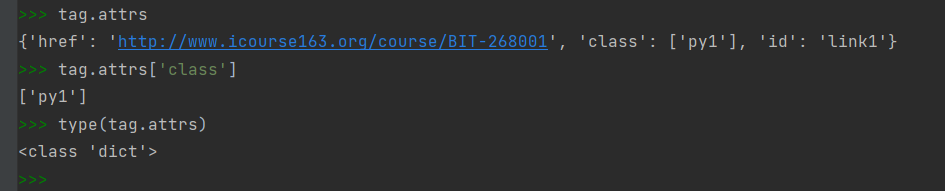
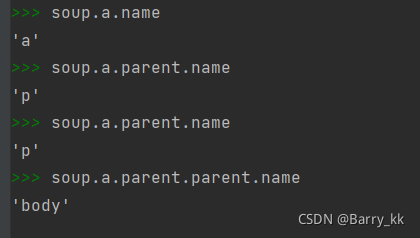
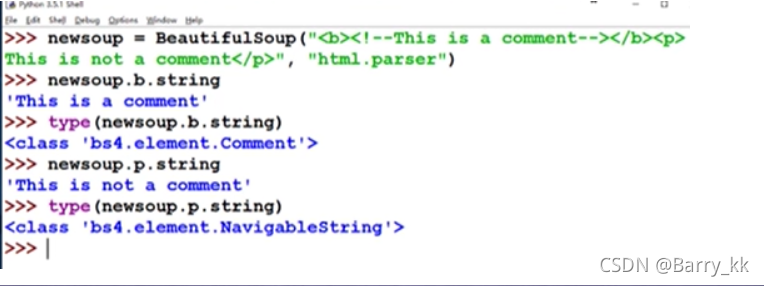
标签内非属性字符串NavigableString(可跨越多个标签层次的)
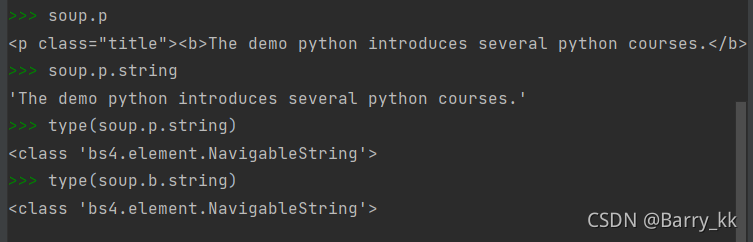
标签内字符串的注释位置Comment
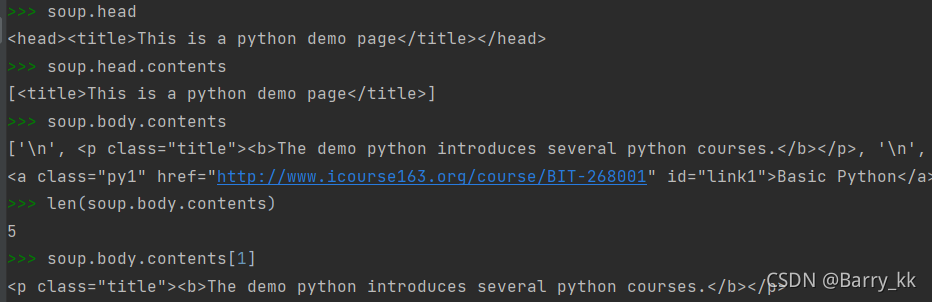
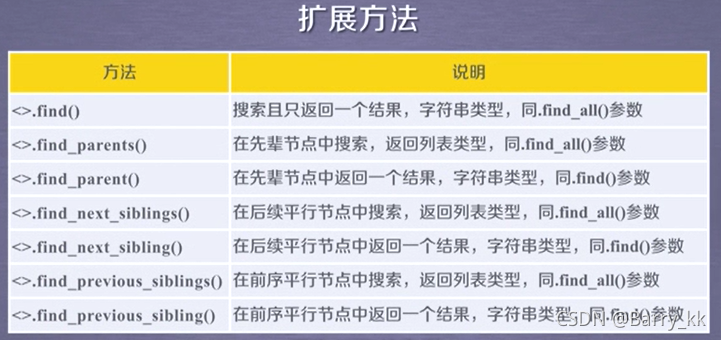
基于bs4库的HTML内容遍历方法



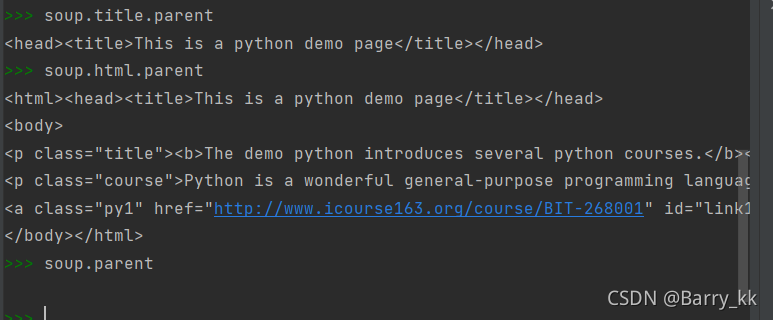
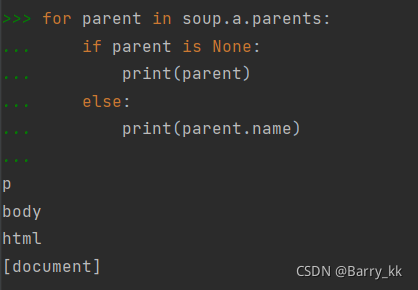

平行遍历发生在同一父节点下


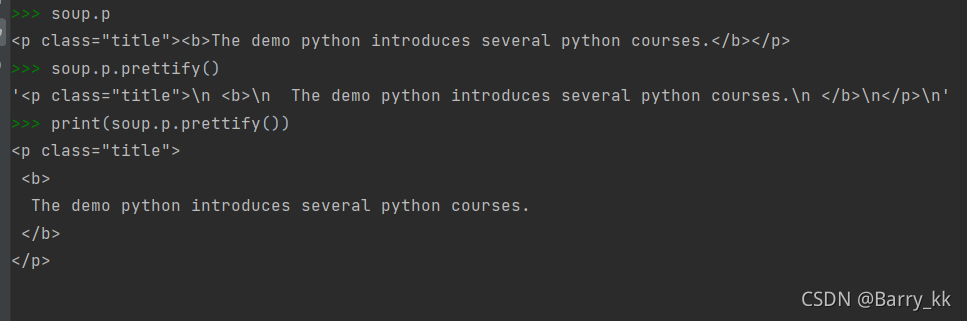
基于bs4库的HTML格式输出
bs库的prettify()方法让html页面更加友好的展示
单元5:信息组织与提取方法
信息标记的三种形式



三种信息标记形式的比较




信息提取的一般方法



**实例:**查找网站所有网页
- 查询所有a标签
- a标签后href
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ls4FipV8-1637937563008)(C:\Users\HQKJ\AppData\Roaming\Typora\typora-user-images\image-20211126173158217.png)]](https://img-blog.csdnimg.cn/f48c473278f04ff4a935a26081ba498f.png)
基于bs4库的HTML内容查找方法

name:
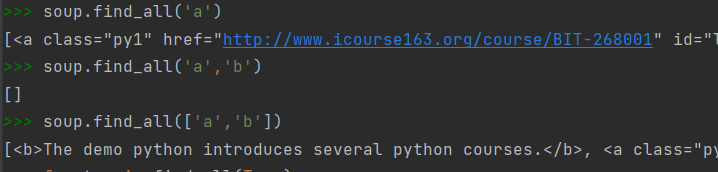
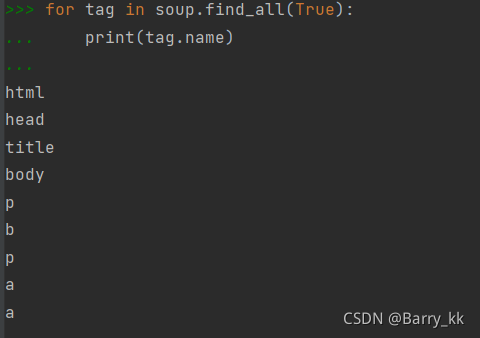
attrs:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pO6yjPjd-1637937563010)(C:\Users\HQKJ\AppData\Roaming\Typora\typora-user-images\image-20211126174814231.png)]](https://img-blog.csdnimg.cn/d2c87b282b124e4696774051fb76320c.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAQmFycnlfa2s=,size_20,color_FFFFFF,t_70,g_se,x_16)
recursive:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F5Imx0CU-1637937563011)(C:\Users\HQKJ\AppData\Roaming\Typora\typora-user-images\image-20211126175029693.png)]](https://img-blog.csdnimg.cn/d765c38e9c374deba42af6afb0527e60.png)
string:
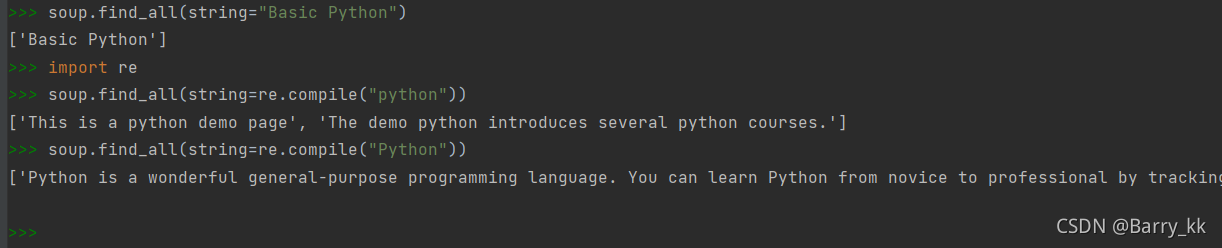
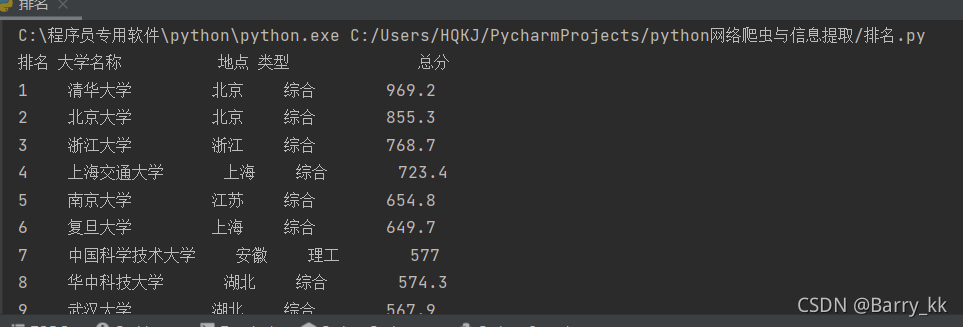
单元6:实例1:中国大学排名爬虫
实例介绍

http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
实例编写
#爬取中国大学排名前十
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
ss = soup.find_all('tbody')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
#大学在a标签当中
ulist.append([tds[0].string.strip(), tds[1].a.string.strip(), tds[2].contents[0].strip(),tds[3].contents[0].strip(),tds[4].string.strip()])
def printUnivList(ulist, num):
for i in range(num):
u = ulist[i]
print("{:<5}{:<12}{:<6}{:9}{:<9}".format(u[0],u[1],u[2],u[3],u[4]))
def main():
uinfo = []
print("{}\t{}\t\t\t{}\t{}\t\t\t\t{}".format("排名","大学名称","地点","类型","总分"))
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 10) #排名前十的大学
main()