����㡶���ѧϰ���ʼ�(��)
��ƪ�ǹ����������ʦ�����ѧϰ����ƵP3-P4�ıʼǡ��������ʦ��ϱ����ε����ӽ��ع�,����dz��,���ʺ�����ѧϰ��
һ�� �ع����
-
�ع�(Regression )�Ǽලѧϰ��������ֵ����ķ���,�����ҵ�һ������ functionfunction ,ͨ���������� xx,���һ����ֵ Scalar������,����Ԥ��(Stock market forecast);Pokemon���鹥����Ԥ��(Combat Power of a pokemon)��
-
��ϱʼ�(һ)���ܵĽ���ģ��(����˵Ѱ��function)�IJ���,����ģ�͵IJ���Ϊ:
-
step1:ģ�ͼ���,ѡ��ģ�Ϳ��(����ģ��)
? �������������ĸ���,ѡ��ѵ��ģ�͡���һԪ����ģ��, y = b + w ? x c p y=b+w��x_{cp} y=b+w?xcp?;���Ԫ����ģ��, y = b + �� w i ? x i y=b+\sum w_i��x_i y=b+��wi??xi?;��һԪ���λع�ģ�͵�
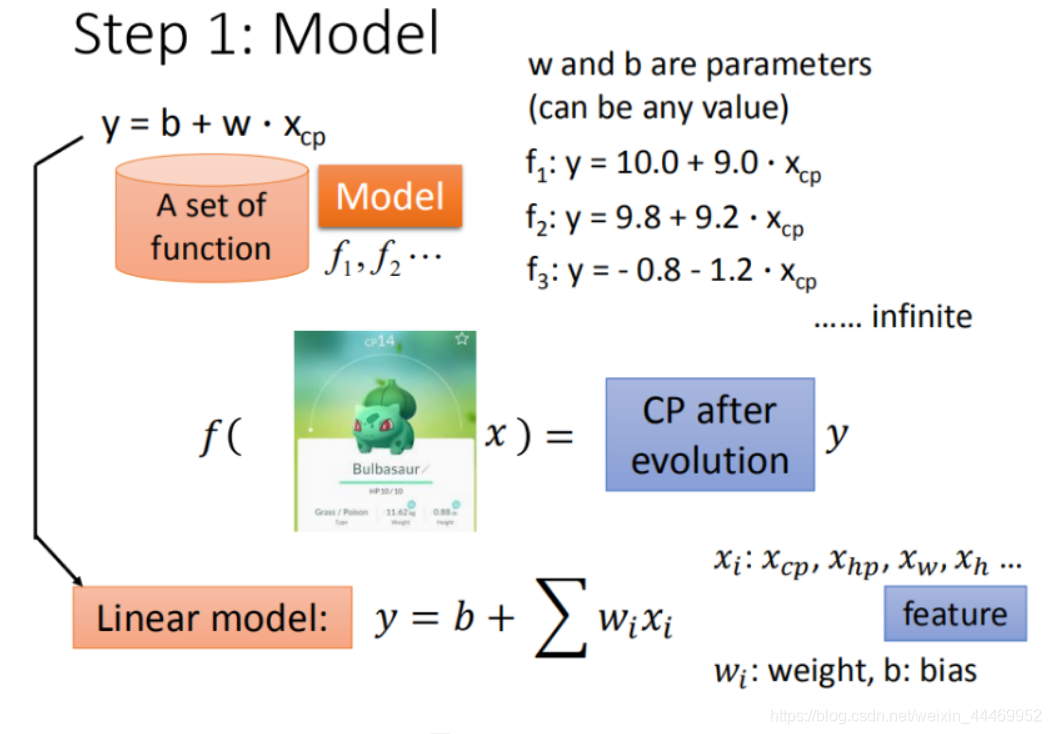
��Ƶ���õľ��DZ����ε�����,Ԥ��������cpֵʱ,����ʹ����������:����ǰ��CPֵ������(Bulbasaur)��Ѫ��(HP)������(Weight)���߶�(Height)�ȡ�
-
step2:ģ������,����ж��ڶ�ģ�͵ĺû�(��ʧ����)
? ����ģ�ͺû��ķ���������ʧ����,��ÿ�����ݵ�ͨ��function�õ���Ԥ��ֵ����ʵֵ֮���ƽ���͡�

-
step3:ģ���Ż�,���ɸѡ���ŵ�ģ��(�ݶ��½�)
? �õ���ʧ�������ص������ó�b��w��ֵ,�����ķ�����������С���˷�(Ordinary Least Squares)��������Ȼ����(Maximum Likelihood Estimate),�ݶ��½���(Gradient Descent)����Ƶ����Ҫ�������ݶ��½�����

-
- ����1:���ѡȡһ�� w 0 w^0 w0
- ����2:������,Ҳ���ǵ�ǰ��б��,����б�����ж��ƶ��ķ���
- ����0�����ƶ�(����w)
- С��0�����ƶ�(����w)
- ����3:����ѧϰ���ƶ�
- �ظ�����2�Ͳ���3,ֱ���ҵ���͵�
��w��bȡֵ�취����:

����,ѧϰ�ʼ��ƶ��IJ���
�������ڽ��ܹ���ѧϰ��(Learning Rate)
https://www.youtube.com/watch?v=W0GdZchasxk&list=PLOXON7BTL9IW7Ggbc09jLqGmzkwPI4-3V&index=11
���Խ�����w��b����õ���ʧ�������Ƴ�ͼ

�������ݶ��½�������,������һЩ����:
- ����1:��ǰ����(Stuck at local minima)
- ����2:����0(Stuck at saddle point)
- ����3:������0(Very slow at the plateau)

���Ƶõ���ͼ�ο��ܻ���ͼ�����һ��ɽ����״,�����ڲ�ͬ�ij�ʼ���õ���ͬ�Ľ��,�����ھֲ����ŵ�������ڸ����ӵ��㷨��,�����������2������3��
��������
��ģ���Ż�ʱ,���Ӹ���IJ����ͱ����ǰ취֮һ�������ڵ�һ��������ǹ����,Ϊ�˽�����������,���ǿ��Բ������ķ�����
����:�����ǽṹ������С�����Ե�ʵ��,��������ʧ����(�������)�ϼ�һ��������(Regularizer)��Ʒ���(Penalty Term)��������,һ����ģ���Ӷȵĵ�����������,ģ��Խ����,����ֵ��Խ��

���������ȥ��ͬ����ʽ,��Ҫ������ L 1 L_1 L1?����: �� 2 ? �O �O w �O �O 2 \frac{\lambda}{2}��||w||^2 2��??�O�Ow�O�O2�Լ�L_2���� �� ? �O �O w �O �O 1 {\lambda}��||w||_1 ��?�O�Ow�O�O1?
�������þ���ѡ���������ģ���Ӷ�ͬʱ�Ƚ�С��ģ��
�����ع����ݶ��½����Ĵ���ʵ��
���ڼ�����10��x_data��y_data,x��y֮��Ĺ�ϵ��y_data=b+w*x_data��b,w���Dz���,����Ҫѧϰ�����ġ�������������ϰ���ݶ��½��ҵ�b��w��
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl # matplotlibû����������,��̬���
plt.rcParams[��font.sans-serif��] = [��Simhei��] # ��ʾ����
mpl.rcParams[��axes.unicode_minus��] = False # �������ͼ���Ǹ��š�-'��ʾΪ���������
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
# loss
for i in range(len(x)):
? for j in range(len(y)):
? b = x[i]
? w = y[j]
? Z[j] [i] = 0 # meshgrid�³����:yΪ��,xΪ��
? for n in range(len(x_data)):
? Z[j] [i] += (y_data[n] - b - w * x_data[n]) ** 2
? Z[j] [i] /= len(x_data)
�ȸ�b��wһ����ʼֵ,�����b��w��ƫ��
# linear regression
#b = -120
#w = -4
b=-2
w=0.01
lr = 0.000005
iteration = 1400000
b_history = [b]
w_history = [w]
loss_history = []
import time start = time.time()
for i in range(iteration):
? m = float(len(x_d))
? y_hat = w * x_d +b
? loss = np.dot(y_d - y_hat, y_d - y_hat) / m
? grad_b = -2.0 * np.sum(y_d - y_hat) / m
? grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
? #update param
? b -= lr * grad_b
? w -= lr * grad_w
? b_history.append(b)
? w_history.append(w)
? loss_history.append(loss)
? if i % 10000 == 0:
? print(��Step %i, w: %0.4f, b: %.4f, Loss: %.4f�� % (i, w, b, loss))
end = time.time()
print(����Լ��Ҫʱ��:��,end-start)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap(��jet��)) # ���ȸ���
plt.plot([-188.4], [2.67], ��x��, ms=12, mew=3, color=��orange��)
plt.plot(b_history, w_history, ��o-��, ms=3, lw=1.5, color=��black��)
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r�� b b b��)
plt.ylabel(r�� w w w��)
plt.title(�����Իع顱)
plt.show()
Ϊ�˱���ѧϰ�ʹ�����С,�ٸ�b��w���ƻ�����Learning rate:
# linear regression
b = -120
w = -4
lr = 1
iteration = 100000
b_history = [b]
w_history = [w]
lr_b=0
lr_w=0
import time
start = time.time()
for i in range(iteration):
? b_grad=0.0
? w_grad=0.0
? for n in range(len(x_data)):
? b_grad=b_grad-2.0*(y_data[n]-n-w*x_data[n])1.0
? w_grad= w_grad-2.0*(y_data[n]-n-w*x_data[n])*x_data[n]
? lr_b=lr_b+b_grad**2
? lr_w=lr_w+w_grad**2
? #update param
? b -= lr/np.sqrt(lr_b) * b_grad
? w -= lr /np.sqrt(lr_w) * w_grad
?
? b_history.append(b)
? w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap(��jet��)) # ���ȸ���
plt.plot([-188.4], [2.67], ��x��, ms=12, mew=3, color=��orange��)
plt.plot(b_history, w_history, ��o-��, ms=3, lw=1.5, color=��black��)
plt.xlim(-200, -100) plt.ylim(-5, 5) plt.xlabel(r�� b b b��)
plt.ylabel(r�� w w w��) plt.title(�����Իع顱)
plt.show()