【01】误差从哪里来
这部分讲了误差来源于bias和variance,各自表现如何,如何定义过拟合与欠拟合,怎么解决,最后给出怎么选模型。
01 bias和variance
偏差和方差

偏差定义为
- 有个推导,为什么是(N-1)/N
02 如何表现
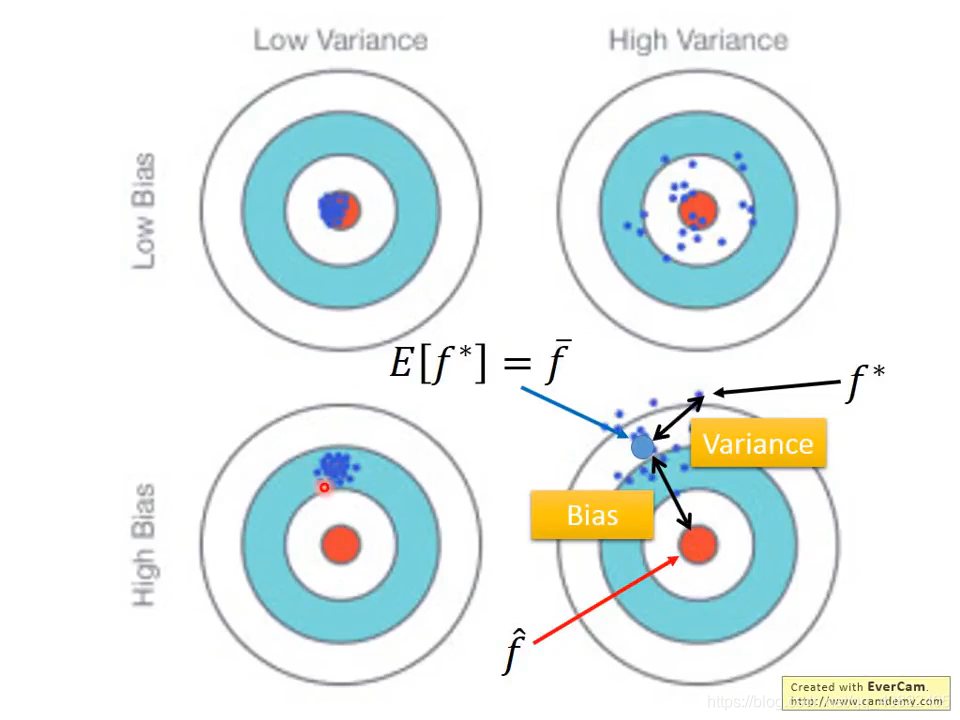
偏差表现为离目标的距离,方差表现为估计的分布情况,越集中越低
2. [ ] 很有意思的事这里是function set的bias和variance
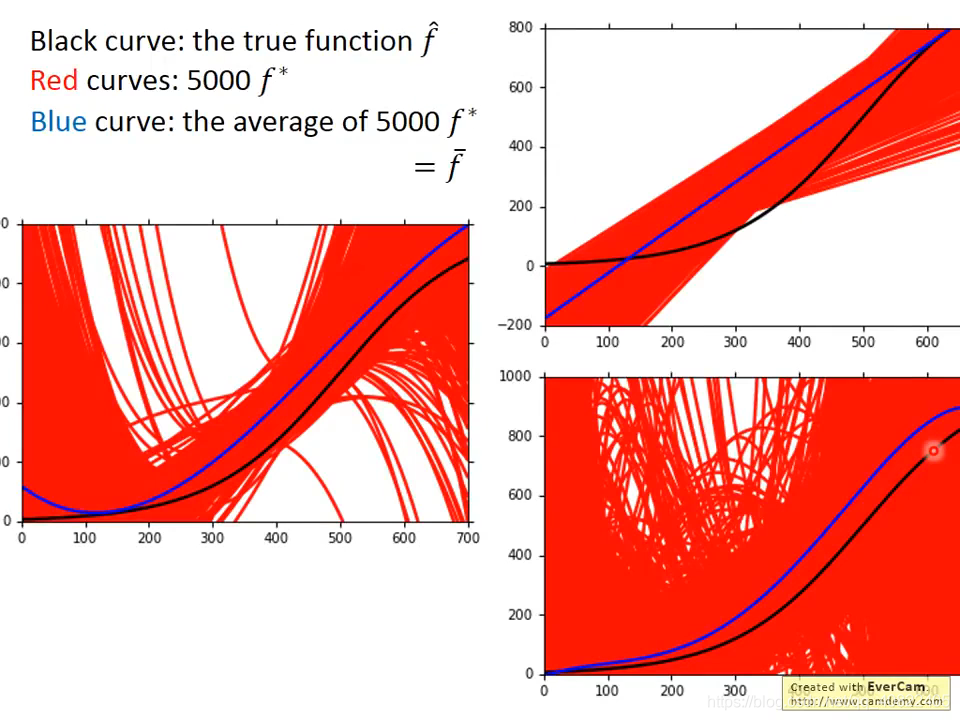
方差大表现为曲线没有大的一致趋势,但是平均值趋势接近。
03 underfitting与overfitting
如果误差来源于偏差,欠拟合;如果来源于方差,过拟合
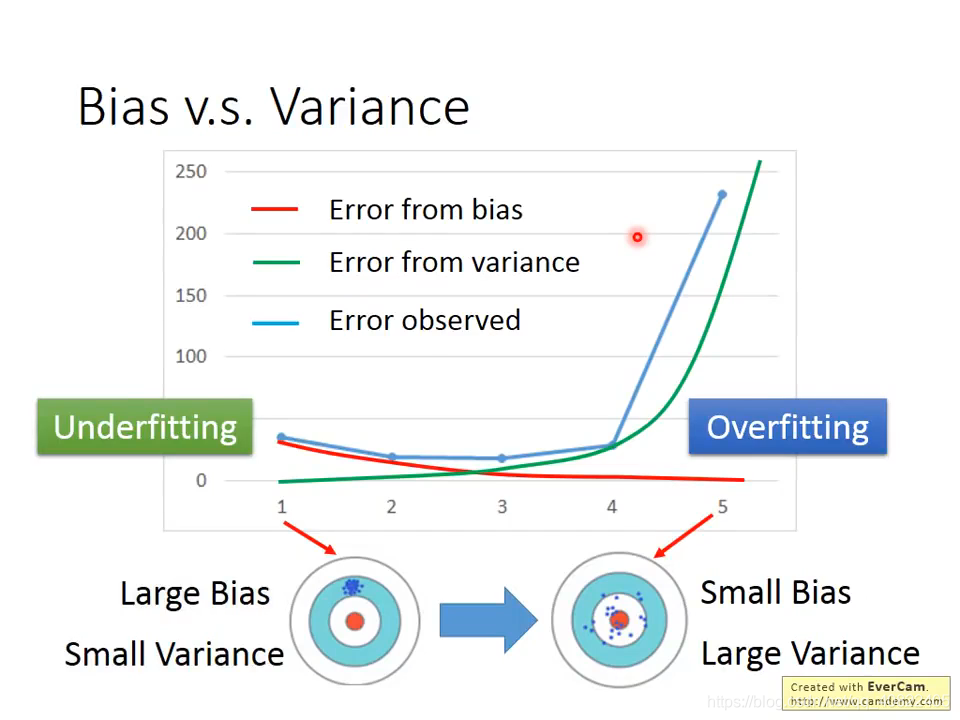
04 如何解决
大偏差

重新设计模型,添加更多特征或者更复杂(比如升次)
大方差
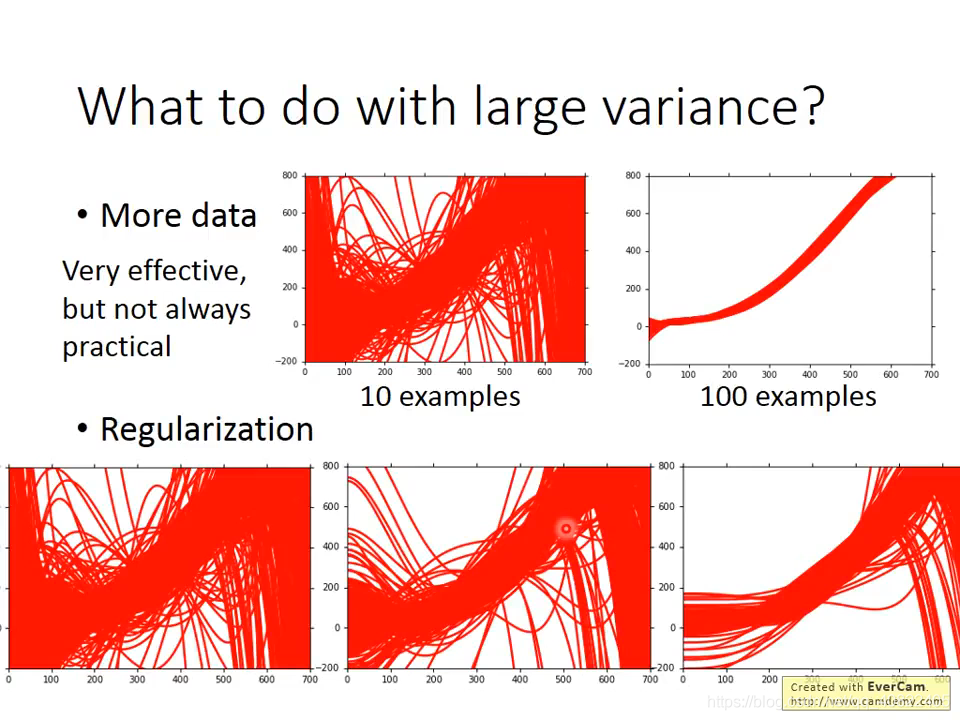
- 更多的数据,万金油的方案,而且几乎都有效,缺点是实际情况中可能难以收集。可以根据自己对问题的理解,来生成“假的”数据。
- 正则化,使曲线更平滑,效果见上图。
05 如何选择模型
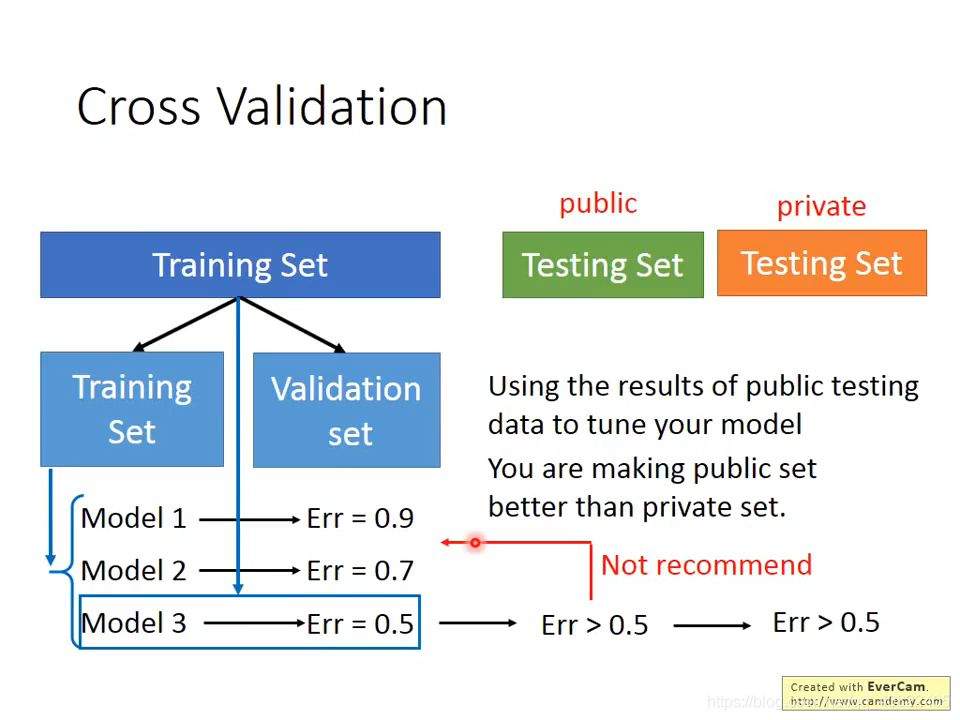
交叉验证,区别于传统的train+test+private的模式,可以让public test与private test(新数据)上的表现更接近。注意,这里并不代表能取得更好的效果,只是说更加可控。
先将training set分为subtraining set和validation set两个部分,并将N个模型放在subtraining set上训练,validation上评估。挑出validation set上效果最好的那个,使用全部的training set进行训练,在public test上进行测试,这时候得到的表现与private test上的会比较接近。
为什么最后可以在整个training set上训练?因为这个时候已经决定好了哪个模型了,不会去改了,所以可以尽可能地增强它。
N-fold交叉验证
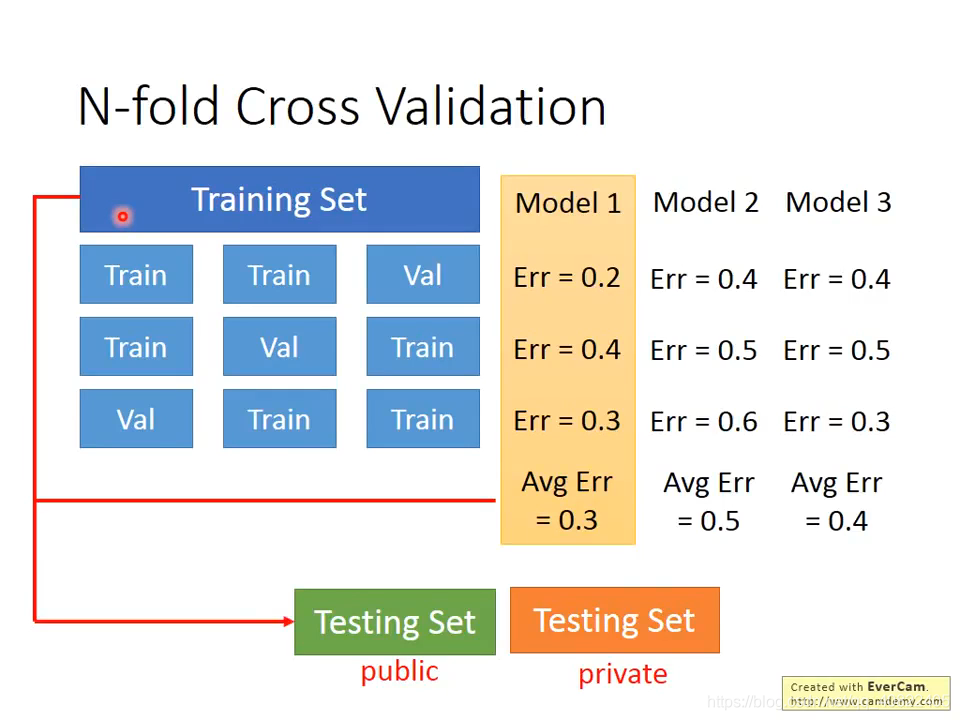
划分数据集的方式不一样,形成N种组合,然后求平均误差,后面跟交叉验证一样。
【02】梯度下降
这部分讲了向量化,学习率,特征缩放,梯度下降的原理
01 向量化
02 学习率
03 特征缩放
04 原理
明天再写