刚入门,记录一下读过文章的重点。
摘要
? ? ? 本文介绍了一种双临界强化学习(RL)框架来解决HEVC/H.265中的帧级比特分配问题,目标是在速率约束下最小化GOP的失真。之前基于RL的方法通常是结合了失真和码率奖励的单个奖励函数来解决这样的约束优化问题。然而,如何组合这些奖励的方式通常是具有特异性的,不能很好地推广到各种编码条件和视频序列的情况下。为了克服这个问题,我们将深度确定性策略梯度(DDPG)强化学习算法用于两个批评者,一个学习预测失真奖励,另一个学习预测码率奖励。其中,当满足速率约束时,失真critic网络用来更新agent,相反的,码率critic在agent超出比特预算时,使速率约束成为优先。在常用数据集上的实验结果表明,我们的方法在提供相当精确的速率控制的同时,在速率失真性能方面显著优于x265和single-critic中的比特分配方案。
2.1、system overview
- 首先,评估输入帧的状态信号(2.2节)。
- 状态信号被馈送到由神经网络实现的代理(2.5节),以确定用于编码当前帧的QP。?
- 基于所选择的QP,当前帧由指定的编解码器(例如x265)编码和解码,以更新状态信号,供代理决定下一视频帧的QP。此外,两种不同的类型的奖励(即失真和码率奖励)计算出来用来指示所选QP的好坏(第2.3节)。这些步骤重复迭代,直到达到最终状态(即一个episode)。训练让代理与编解码器多次交互,以便它可以学习最大化回报(第2.4节)。
2.2、state signal

- 帧间特征
- 帧内特征
- 剩余帧的平均帧间特征
- 剩余帧的平均帧内特征
- 剩余比特数百分比
- GOP中剩余帧
- 当前帧的时间信息
- GOP的目标比特

? ? ? 这些状态信息中包含了一些帧内的和帧间的特征,这些特征描绘了GOP和residual frames中的统计信息。状态依赖于一个GOP中剩余视频帧的统计这一事实表明了一种前瞻策略。也即当参考帧还没有被编码时,使用其原始和未压缩版本来计算剩余帧。
2.3、distortion and rate rewards
?????? 我们的任务是最小化受速率限制的GOP的失真。Distortion reward在完成对视频帧的编码后作为即时奖励进行评估,反映了目前选择的QP有多好。它被定义为压缩视频帧的归一化负失真(均方误差):
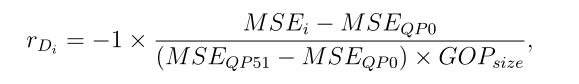
Rate reward与针对每个视频帧的distortion reward不同,它在每个episode结束后计算实际比特率和目标比特率之间的绝对偏差。RGOP是GOP级的位预算,QPi是在GOP中为第i帧选择的QP。
2.4、Dual critics
? ? ? ?学习两个critics,一个用于预测失真奖励,一个用于预测码率回报。Agent会自适应的根据其中一个critic进行更新。不断在训练中将agent应用于编码一个GOP,如果产生了超过了RGOP的比特率,就是用rate critic QR 去更新它的网络参数。目的是优化代理以实现精确的速率控制。另一方面,当实际的比特率低于目标比特率时,则会更新QD去最小化重建GOP的失真。具体算法如下:
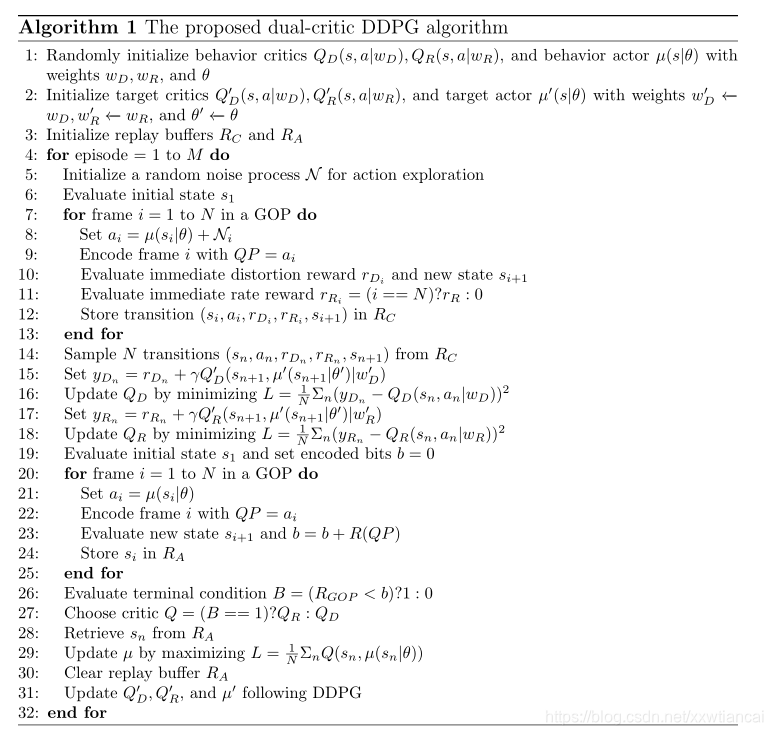
算法分为两个部分:1、5-18行对应于该策略的推出以及一个噪声处理过程,在重放缓冲区RC中收集状态、动作和奖励的转换,其数据用于基于普通DDPG(deep deterministic policy gradient,深度确定性策略梯度算法)算法更新两个批评者QD和QR。请注意,在每一步都记录零即时速率奖励,直到最后一步(终端步骤/状态),在该步,整个GOP的比特率偏差RRo作为即时速率奖励给出。19-30行第二部分是该政策的另一个展示,但没有噪音处理过程。经历的状态转换存储在单独的重放缓冲区中。在部署结束时,将使用的实际比特率与目标比特率进行比较,以决定应该使用这两种批评中的哪一种来更新代理。
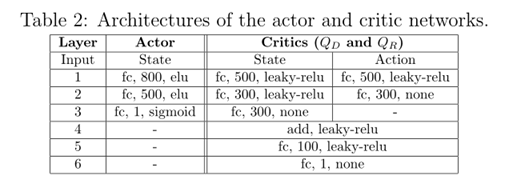
2.5 Network Architecture
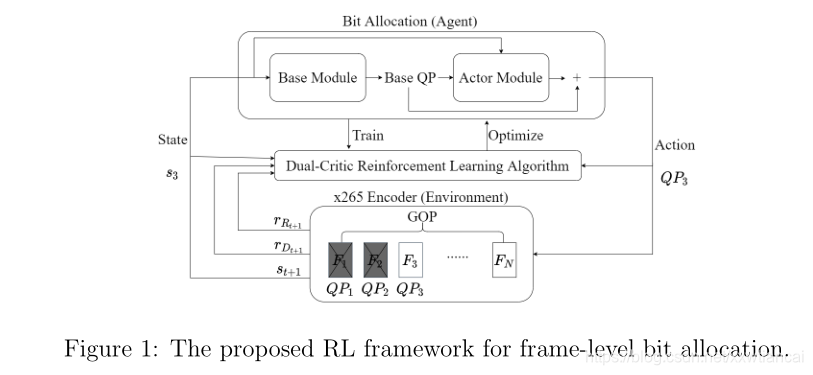
Agent由base和actor两个模块组成,base模块经过预训练模仿选择的编码器x265的QP控制过程,但是actor模块是使用根据我们的dual-critic RL网络进行学习使用区间[-10,10]的变化区间去更新base模块的QP。在actor的训练过程中,base模块被停止。base模块的引入限制了actor模块学习时的探索空间。这是有益的,对于具有QP选项的广阔探索空间的双批评家训练来说,收敛可能是一个问题。Base模块和actor有相同的结构,除了将base QP作为输入这一操作。
?实验结果
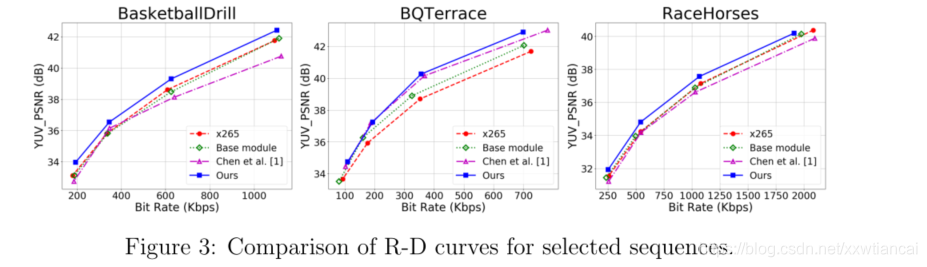
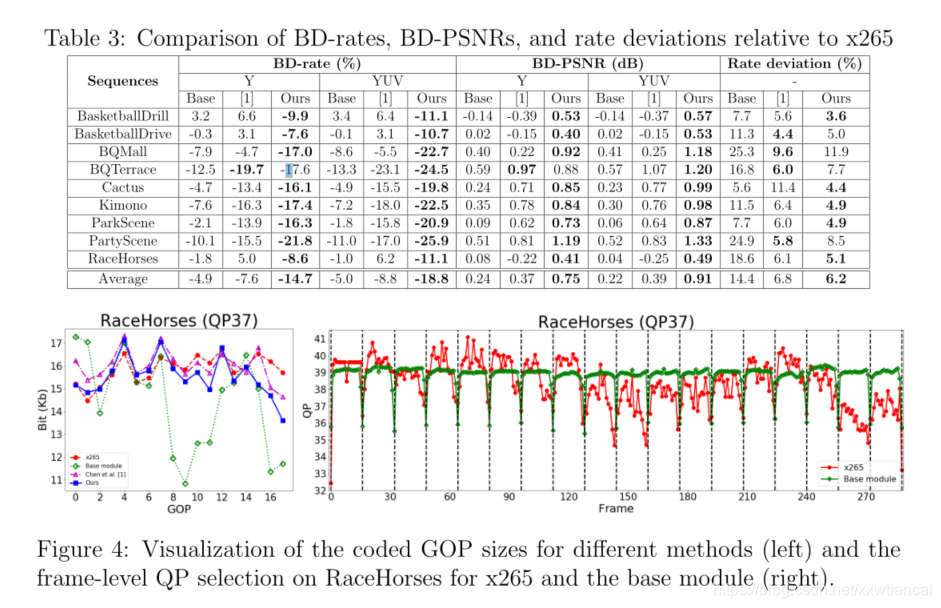
?
?Videos are provided at http://mapl.nctu.edu.tw/RL_Rate_Control/.
Conclusion
? ? ? ?本文介绍了HEVC/H.265中用于帧级比特分配的基于双评论家的RL框架,受单一评论家的设计的启发克服了结合码率和失真奖励的需要。该方法具有良好的研发性能和相当精确的速率控制精度。虽然我们目前还不知道双批评家训练的收敛保证,但是它能够在现实中找到一个合理的好的解决方案。这仍然是我们未来工作中有待解决的一个问题。