1. 介绍
本工作的贡献在于提出了一种利用一维log Gabor滤波器评估的虹膜编码生成可消除虹膜图案的方法。虹膜编码经过分割、特征提取等必要的虹膜预处理后,有意识地转化为行矢量。在该方法中,行向量被分割成一组固定长度的词,并将这些词映射为十进制向量。
最后,利用查找表生成可取消的虹膜模板。为了保持所提出系统的精度,还考虑了旋转不变性。实验评估证实了所提工作的有效性。
2. 相关工作
3. 提出的方法
在所提出的方法中,使用传统的定位虹膜图案的算法[23]、[24]对虹膜图像进行预处理以定位和归一化。采用一维Log-Gabor滤波器[22]进行相位量化,提取虹膜编码特征,生成旋转不变码。将按位生物特征模板转换为一维行向量,该一维行向量被分成大小为M的字数。这里,通过模板的不同直方图的统计来评估M。通过使用M的定义划分行向量来生成十进制向量。维护查找表以映射十进制向量,并从查找表中选择某些数字以生成最终模板。图1显示了所建议的方法的框图。
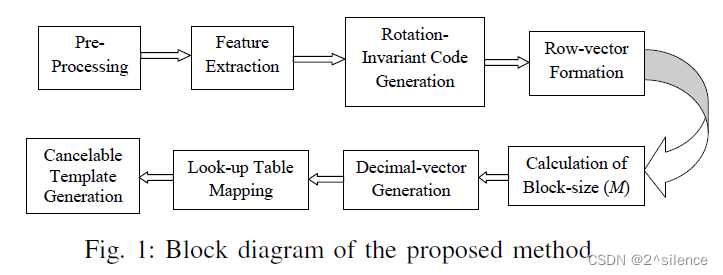
A. Pre-Processing
预处理包括虹膜分割和图像增强。虹膜分割的目的是将虹膜区域从人眼图像中分离出来,去除眼皮、睫毛等噪声,提高匹配性能。在我们的工作中,圆Hough变换[20]被用来使用半径和中心坐标参数来寻找圆。用抛物线参数代替前面讨论的圆参数从图像中检测眼皮[19]。虹膜可以以不同的成像距离捕获不同大小的虹膜。由于照明的变化,瞳孔的径向大小可能会相应地改变。由此产生的虹膜纹理变形将影响后续特征提取和匹配阶段的性能。因此,需要对虹膜区域进行归一化,以补偿这些变化。归一化采用了道格曼的橡皮板模型[21]。均匀橡皮片模型将虹膜区域内的每个点重新映射到极坐标。归一化后的虹膜图像对比度低,光源位置引起的光照不均匀。对归一化后的虹膜图像进行局部直方图分析[24],以减少光照不均匀的影响,得到分布均匀的纹理图像。反射区域的特征是高强度值接近255。执行简单的阈值操作来去除反射噪声。图2显示了增强的虹膜图像。
B. Feature Extraction
归一化虹膜图像经过一维Gabor滤波器卷积后变换为0-1形式的矩阵[22]。Gabor小波是一个由实部和虚部组成的复值函数。根据系数的符号用1或0对Gabor系数值进行编码。Gabor函数用等式表示:
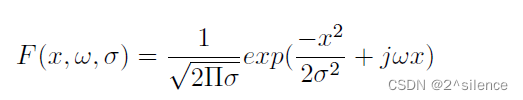
?这里,σ是具有θ方向和ω频率分量的空间扩展[22]。该函数产生实部和虚部,对它们进行相位量化(设复数为A+Bi,那么相位就是arctan(B/A)∈[-1, 1]。),得到0-1形式的虹膜编码。
C. Rotation Invariant Code Generation
虹膜图案可能会受到旋转的影响,最大旋转8列会产生对虹膜图像的最大5.625度旋转。很难匹配旋转的图像,因为这降低了系统的性能[23]。
即使是正品,也可能导致匹配不佳。因此,必须采用旋转不变机制。为了部署旋转不变性,我们为每个受试者拍摄了8张图像。从这些图像中选择一个图像作为参考图像。
我们通过移位一列来计算参考图像和其他图像之间的汉明距离。整个圆形虹膜图案被认为有512列,因此一列图像的平移相当于最多8列图像产生5.625度旋转。如图3所示,虹膜编码中的一个右移导致0.703125度旋转。分析了不具有旋转不变的图像之间的汉明距离大于具有旋转不变的图像之间的汉明距离。考虑到这种移位,具有最小汉明距离的虹膜码被考虑用于进一步的处理。

?D. Row Vector Function
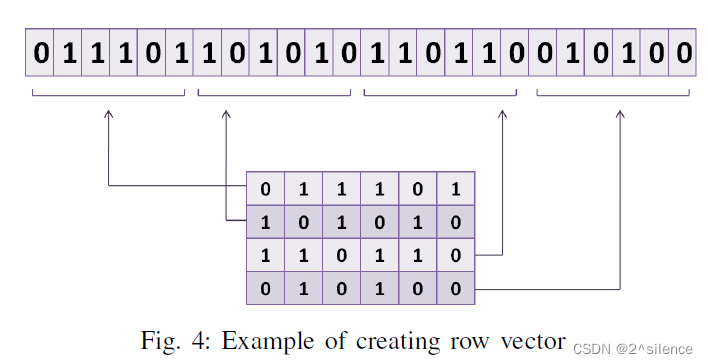
与虹膜编码相比,无旋转模板是移位不变的。为了便于计算,将旋转不变模板变换为行向量。此外,行向量可以轻松地部署到任何转换。行向量是通过将下一行合并到前一行来创建的。如图4所示,从4×6的虹膜编码得到1×24的行向量。
?E. Calculation of Block Size M
如果行矢量的位数很大,则很难对所有位应用任何变换函数。因此,行向量被分割成大小为M的多个块。M的值可以静态地或动态地选择,并且对于每个图像是不同的。但动态方法使用起来更安全,因为它很难破解M的值,而M是要使用的关键。我们根据虹膜编码生成的直方图来确定每个图像的M。在我们的方法中,我们获取0、1、00、11、000、111等的直方图。通过生成这些位的组合的直方图来选择M的值。对于同一个人的不同图像,直方图的值会不同,所以我们取这些值的范围。块大小的选择方式应使其具有均匀的直方图分布。通过改变M的取值可以生成任意数量的可取消模板,M的取值过大可能会导致较大的小数向量和查找表,从而影响方法的性能。因此,M的选择应该以能够产生较高识别率的方式进行。
F . Decimal V ector Generation
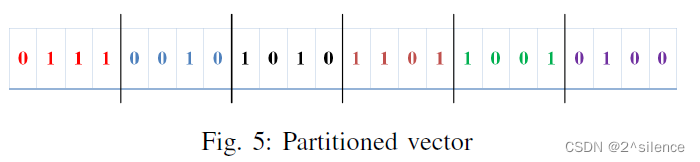
十进制向量是通过使用大小为M的固定长度的字来划分行向量来构造的。十进制向量具有与行向量中的字数相同的正整数数量。将一个字从二进制转换为正整数时,最左边的位就是最高有效位。这些整数被表示成这个向量。使用这个向量,我们可以很容易地将每个单词映射到唯一的查找表行。设给定行向量的M值为4。
因此,行向量被分成6个字,每个字有4位,如图5所示。十进制向量的大小为,正整数的范围是0到
。
?如果字长很大,则十进制向量具有较大的正整数。因此,可以使用合适的归一化函数将十进制向量转换为合适的范围。M的值应该是2的幂的倍数,才能得到M比特的一致字。如果不是,则分区将不是完美的,并且将留下一些位。不需要存储图像的M,因为我们是动态计算它。这将增加该方法的安全性和不可撤销性。
G. Look-up Table Mapping
为了区分不同的单词,我们使用查找表将十进制向量映射到相应的单词。多个单词可以映射到同一个正整数,因此反向映射非常困难。行向量字被映射到相应的十进制值。可以有许多十进制值为0的单词。如果向量的十进制值为0,则可以将该单词映射到下一个十进制值。给定行向量的映射如图6所示。
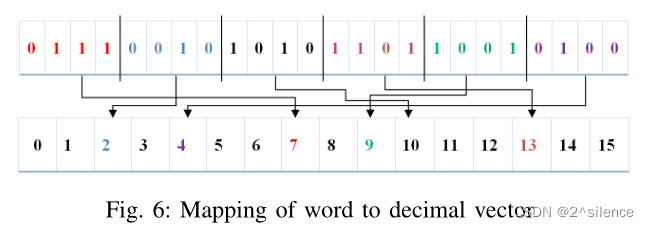
?
查找表由随机值0和1生成。表的最小大小(行)取决于M的值。例如,如果字长为4,则最大十进制整数为15。因此,表中必须有大于或等于15的条目。有可能特定行或多行的所有条目都为0。在这种情况下,使用这些条目很容易受到隐私侵犯,因为这使得冒名顶替者的任务变得容易。因此,查找表应该以随机化的方式使0和1的数目大致相同。对于给定行向量,查找表的大小将是R×C,其中R表示要映射的十进制向量的大小,C表示每个字的大小。在我们的例子中,R是13,C是4。查找表的每一行都由随机生成的0或1填充。
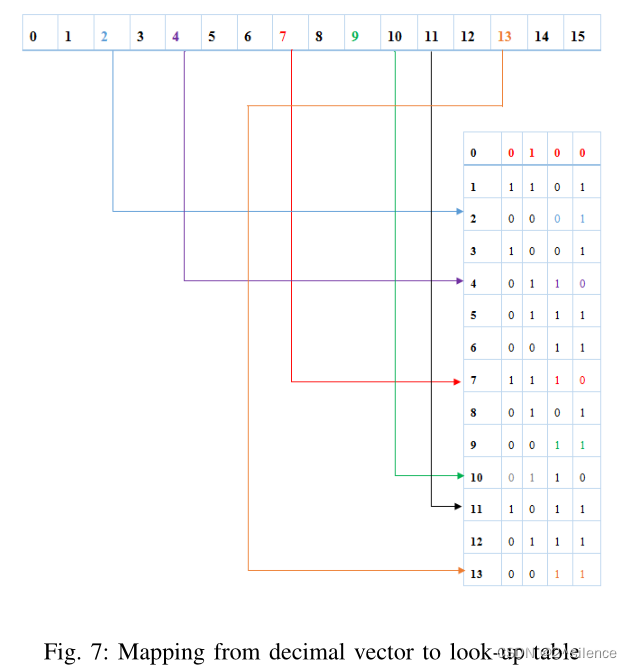
?H. Generate Cancelable Templates
将十进制向量映射到随机生成的查找表的对应行。则从查找表的每一行中选择d个比特。这里,d表示部署到最终模板中的位数。例如,如果d=2,则将从查找表中取出来自每行中任何位置的2位,用于最终的模板生成。最多将每行查找表中的d比特存储在数据库中。因此,如果我们如图8所示从每个字中选择2位,则最终模板由12位组成。

?
可以为不同的M值生成许多模板,但对于每M个值,查找表将是固定的。为了执行匹配,已经部署了所提出的方法。
我们计算存储的模板和评估的模板之间的汉明距离。使用汉明距离和阈值来确认接受或拒绝决定。
4. 实验装置
CASIA-iris V3-Interval
False Accept Rate (FAR),False Reject Rate (FRR) and Equal Error Rate (EER).
提出的方法使用两个不同的参数,这两个参数是生成不同的可取消模板所必需的。
这也是本文提出的方法的效率所在。
(I)使用字长M将行向量分成固定长度的段。不同的M值对同一对象产生不同的汉明距离,因此参数M对所提出的方法的效率有影响。此外,M的改变可能导致不同生物测定模板的生成。第五节给出了不同M值的结果。
(2)查找表也可被视为影响所提议方法的效率和可撤销的参数。可以使用随机生成的值来设计不同的查找表。有时,表可能偏向于0或1,这使得所提议方法不可撤销。第五节给出了不同查找表值的结果。
5. 结果和讨论
从M值和查找表两个参数对该方法的实现和测试结果进行了分析。
A. Effect of parameter M
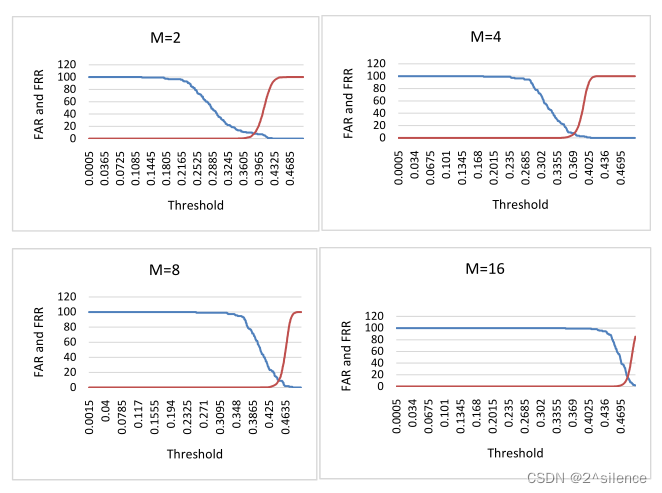
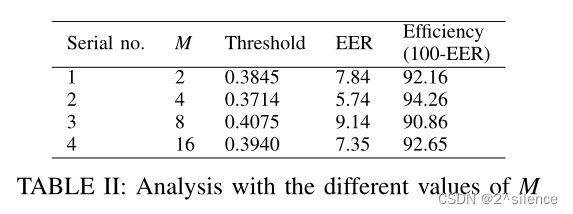
类内汉明距离表示一个主题的一个模板与同一主题的其他模板的匹配。使用不同的M值对20个被试进行了FAR、FRR和EER的测定。在我们的实验中,我们认为M的值为2、4、8、16。
通过将主题的一个模板与数据库中的所有模板进行匹配来计算类间汉明距离。理想情况下,类间的汉明距离应该大于类内的汉明距离,因为在类间的情况下比特差异将更大。对于不同的M值的结果如图10所示。最初,当M=2时,有16384个不同的字,每个字2比特,因此比特的变化较小。这导致类内比较的差异非常小。对于M=4,位差增大。M值越高,位差(转换成十进制的整数值)越大。M值越小,效率越高。这增加了类内变化,从而使得模板匹配变得容易。
M值越小,效率越高。对于该方法,当M=4时,最大效率为94.26%。
?B. Effect of Look-up Table
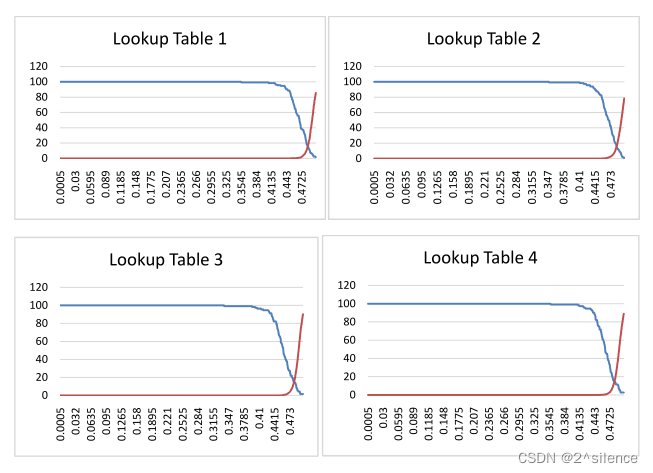
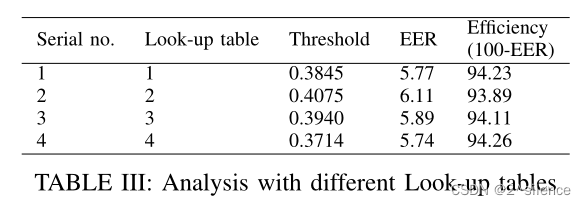
最终的模板是通过考虑查找表中的比特数来生成的,因此查找表中的比特序列对匹配性能有影响。为最终的模板生成维护相同的查找表。
查找表中的修改导致改变随机比特导致生成模板的改变,由于比特序列的改变,我们可能具有离散的阈值和性能。虽然这一差异很小,但它仍然对所提出的方法的性能产生影响。对于20个不同的人,我们将M作为16,并通过采用不同的查找表来生成最终的模板。不同查找表的结果如图11所示。该方法不允许保存除查找表以外的任何参数,因此黑客必须知道该方法的所有内容以及不同的M值会危及虹膜模板的安全性。
?
?C. Results
最后的测试是对100名受试者进行的,每个受试者有9到5张图像。对于类内,我们获取每个模板的一幅参考图像,与同一人的其他图像进行匹配,总共匹配388次。在类间匹配的情况下,将一个人的模板与其他人的其他模板匹配。总共执行了48312次匹配,其中一些重叠区域表示一些类间汉明距离在类内。效率达到94.26%。最终测试结果如图12所示。
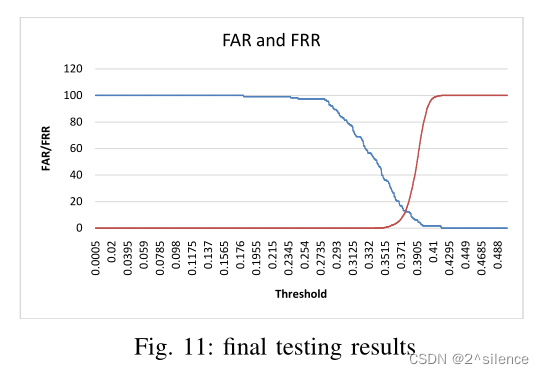
当M设置为4时达到最大效率。由于M值和查找表的不同,每种情况下的效率不会相同。查找表4的最大效率达到了94.26%。