- ���ܹ�
- �ܹ�ͼ

?
- ���˵��
-
?Client
�ṩ�˷���HBase��һϵ��API�ӿ�,��Java Native API��Rest���http API��Thrift API��scala��,��ά��cache���ӿ��HBase�ķ���
-
Zookeeper
��֤�κ�ʱ��,��Ⱥ��ֻ��һ��master
��������Region��Ѱַ��ڡ�
ʵʱ���Region server�����ߺ�������Ϣ,��ʵʱ֪ͨMaster
�洢HBase��schema��tableԪ����
-
Master
ΪRegion server����region
����Region server�ĸ��ؾ���
����ʧЧ��RegionServer�����·������ϵ�region
�����û���table����ɾ�IJ���
-
RegionServer
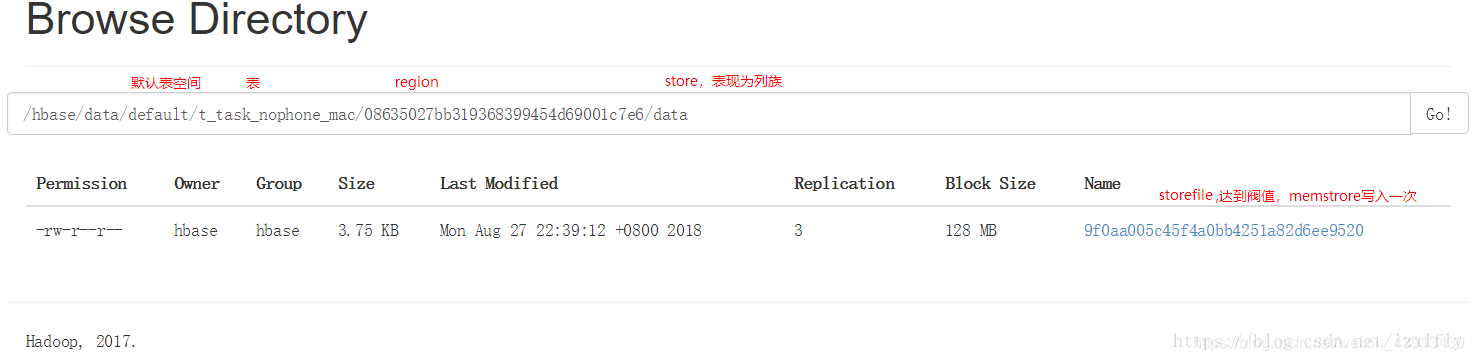
(1)Region serverά��region,��������Щregion��IO����,��HDFS�ļ�ϵͳ�ж�д���ݡ�
һ��RegionServer�ɶ��region���,һ��region�ɶ��store���,һ��store��Ӧһ��CF(����),��һ��store����1��storefile����,?ÿ��storefile��HFile��ʽ������HDFS�ϡ�д������д��memstore,��memstore�е����ݴﵽij����ֵʱ,RegionServer������flashcache����д��storefile,ÿ��д���γɵ�����һ��storefile��
(2)Region server�����з������й����б�ù����region
ÿ����һ��ʼֻ��һ��region,���ű����ݲ��ϲ���,����Խ��Խ��,storefileҲԽ��Խ��,��storefile�ļ�������������һ����ֵ��,ϵͳ����кϲ�(minor��major compaction),minor��Ҫ�Ǻϲ�һЩС���ļ�,����ɾ��,��������,��majar�ںϲ������л���а汾�ϲ���ɾ������,�γɸ����storefile��
(3)��һ��region����storefile�Ĵ�С����������һ����ֵ��,��ѵ�ǰ��region�ָ�Ϊ�����µ�region(�ѱ�),ÿ��region����һ������������Ƭ��,�������,�ͻ���Խ��Խ���region,����Master���䵽��Ӧ��RegionServer������,����һ�������ı��������ڶ��Regionserver?��,ʵ�ָ��ؾ��⡣
-
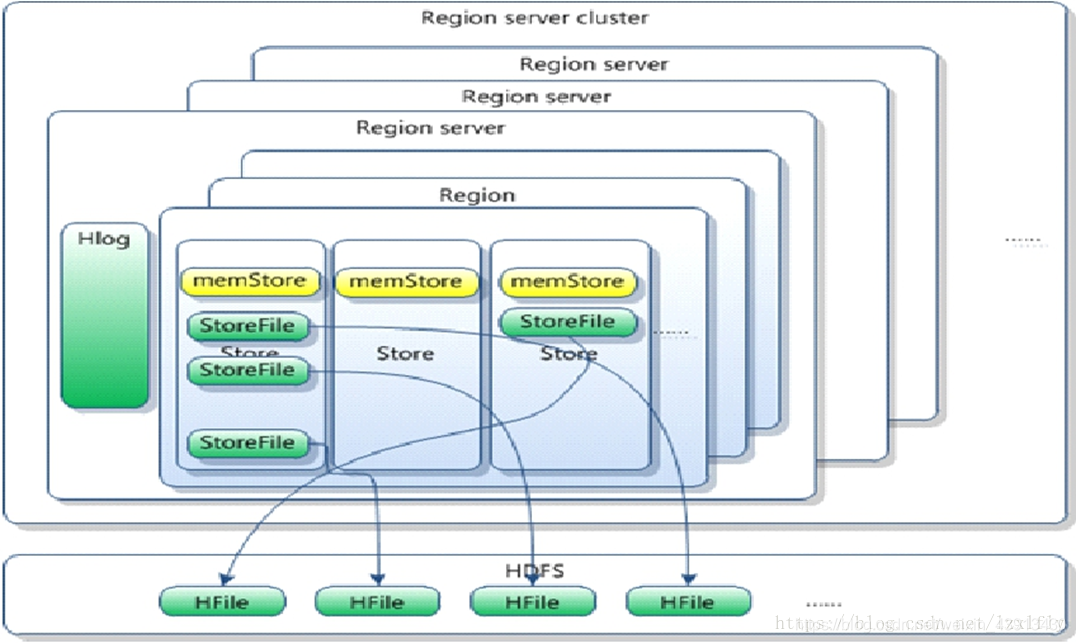
?Region
HRegion��HBase�зֲ�ʽ�洢���ؾ������С��Ԫ����С��Ԫ�ͱ�ʾ��ͬ��HRegion���Էֲ��ڲ�ͬ��?HRegion server�ϡ�
HRegion��һ�����߶��Store���,ÿ��store����һ��columns family��ÿ��Strore����һ��memStore��0�����StoreFile���,ÿ��storefile��HFile��ʽ������HDFS��,HFile��Hadoop�Ķ����Ƹ�ʽ�ļ�,ʵ����StoreFile���Ƕ�HFile������������װ,��StoreFile�ײ����HFile,����ͼ��

-
HLog(Write Ahead Log)
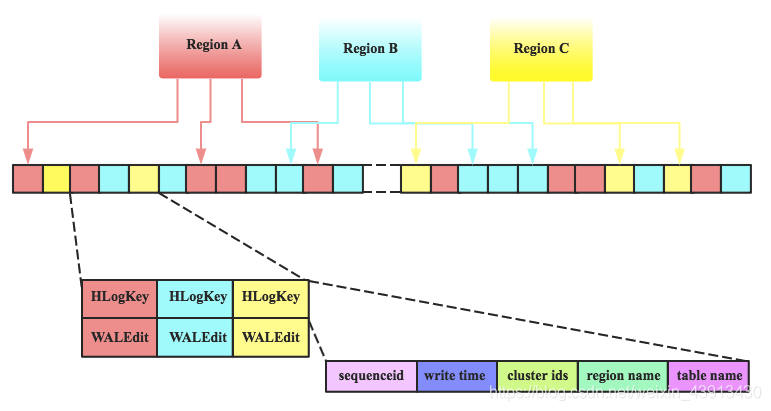
�ڷֲ�ʽϵͳ������,������ϵͳ��������崻�,���һ��HRegionServer�����˳�,MemStore�е��ڴ����ݽ��ᶪʧ,�����Ҫ����HLog�ˡ�ÿ��HRegionServer�ж���һ��HLog����,HLog��һ��ʵ��Write Ahead Log����,��ÿ���û�����д��MemStore��ͬʱ,Ҳ��дһ�����ݵ�HLog�ļ���(HLog�ļ���ʽ������),HLog�ļ����ڻ�������µ�,��ɾ���ɵ��ļ�(�ѳ־û���StoreFile�е�����)����HRegionServer������ֹ��,HMaster��ͨ��Zookeeper��֪��,HMaster���Ȼᴦ��������?HLog�ļ�,�����в�ͬRegion��Log���ݽ��в��,�ֱ�ŵ���Ӧregion��Ŀ¼��,Ȼ���ٽ�ʧЧ��region���·���,��ȡ ����Щregion��HRegionServer��Load Region�Ĺ�����,�ᷢ������ʷHLog��Ҫ����,��˻�Replay HLog�е����ݵ�MemStore��,Ȼ��flush��StoreFiles,������ݻָ�
HLog�ļ�����һ����ͨ��Hadoop Sequence File,Sequence File?��Key��HLogKey����,HLogKey�м�¼��д�����ݵĹ�����Ϣ,����table��region������,ͬʱ������?sequence number��timestamp,timestamp�ǡ� д��ʱ�䡱,sequence number����ʼֵΪ0,���������һ�δ����ļ�ϵͳ��sequence number��HLog SequeceFile��Value��HBase��KeyValue����,����ӦHFile�е�Key��Value
-
- hlog�Ļ����ṹ
- ��ͼ
- hlog ���ɹ���

hlog ����:regionserver����һ���̶߳���(�ɲ�����hbase.regionserver.logroll.period������,Ĭ��1Сʱ)��hlog���й���,���´���һ���µ�hlog.,����,regionserver�Ͼͻ�����ܶ�С��hlog �ļ�,hbase��������ԭ���ǵ�hbase������Խ��Խ��ʱ,hlog�Ĵ�С�ͻ�Խ��Խ��memorystore ˢд������ʱ,���ڵ�hlog ��û�����ñ��ɾ��,һ����С��hlog�ļ�����ɾ����
hlogʧЧ:��memorystore flush �����̺�,��hlog������seqId��memorystore������seqId���бȽ�,���С��memorystore�е�seqId,���hlogʧЧ,�㽫��hlog�Ƶ���wals�ļ����Ƶ�oldwals�ļ���ȥ
hlogɾ��:��hlogʧЧ��,������ɾ������Ϊregion replica�������ڶ�hlog���ж�д,����regionserver����һ���߳�ÿ��һ��ʱ��(�ɲ�����hbase.master.cleaner.interval��,Ĭ��1����)�Լ���hlog�Ƿ���Ա�ɾ��,��oldwals�ļ����е�hlog�ļ����й���ʱ��,Ĭ��(�ɲ�����hbase.master.logcleaner.ttl������)Ϊ10����
- ��ͼ
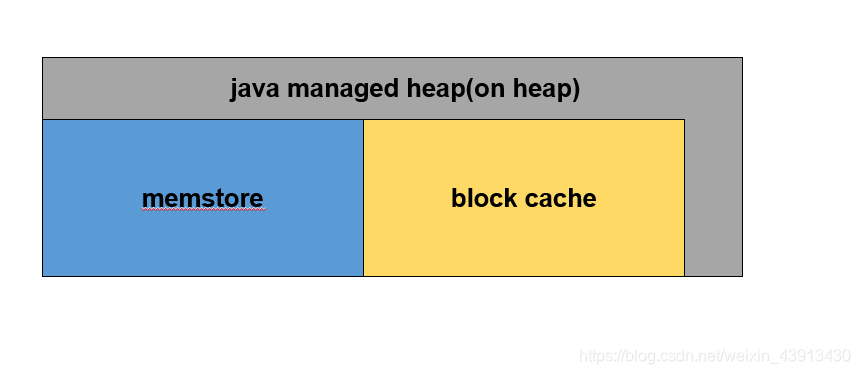
- �ڴ沼��
- ��ͼ

- JVM�ڴ漴����ͨ���׳ƵĶ����ڴ�,����ڴ�����Ĵ�С������HBase�Ļ����ű�������,�ڶ����ڴ�����Ҫ�������ڴ�����,
- 20%�����hbase regionserver rpc������м�һЩ��������
- 80%�����memstore + blockcache
- java direct memory�������ڴ�,
- ����һ�����ڴ�����HDFS SCR/NIO����
- ��һ�������ڶ����ڴ�bucket cache,���ڴ��С�ķ���ͬ����hbase�Ļ��������ű���ʵ��
- ��ͼ
- ���̷���
- �����

- client--->wal---->Memstore
- memstore����ݲ��Խ������ݳ־û��������ļ�
- ʲôʱ�����Memstore Flush
- Region ������ MemStore ռ�õ��ڴ泬�������ֵ
- ���� RegionServer �� MemStore ռ���ڴ��ܺʹ��������ֵ
- WAL�������������ֵ
- �����Զ�ˢд
- ���ݸ��³���һ����ֵ
- �ֶ�����ˢд
- Region ������ MemStore ռ�õ��ڴ泬�������ֵ
- ��ֵ��?
hbase.hregion.memstore.flush.size?��������,Ĭ��Ϊ128MB - ��С����?RegionServer_heapsize*?hbase.regionserver.global.memstore.size��
- hbase.hregion.memstore.block.multiplierĬ��ֵΪ4
- ������regionServer������regionռ��memstore�Ĵ�С����hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier����ˢ��
- ��ֵ��?
- ���� RegionServer �� MemStore ռ���ڴ��ܺʹ��������ֵ
- ���� RegionServer �� MemStore ռ���ڴ��ܺʹ��� hbase.regionserver.global.memstore.size.lower.limit * hbase.regionserver.global.memstore.size *RegionServer_heapsize ��ʱ�����ᴥ�� MemStore ��ˢд��
- ���� hbase.regionserver.global.memstore.size.lower.limit ��Ĭ��ֵΪ 0.95��
hbase.regionserver.global.memstore.size?��Ĭ��ֵ�� 0.4
- WAL�������������ֵ
- ���ij�� RegionServer �� WAL ����һ��������ʱ����һ��ˢд������
- �����ֵ(maxLogs)�ļ��㹫ʽ����:��������� hbase.regionserver.maxlogs,�Ǿ������������ֵ;������ max(32, hbase_heapsize * hbase.regionserver.global.memstore.size? / logRollSize)
- logRollSize=WAL blocksize? * 0.95#? Ĭ��blocksize=128MB
- �����Զ�ˢд
- ������Ǻܾ�û�ж� HBase �����ݽ��и���,��ʱ��Ϳ�����������ˢд�����ˡ�
- RegionServer ��������ʱ�������һ���߳� PeriodicMemStoreFlusher
- ÿ�� hbase.server.thread.wakefrequency ʱ��ȥ���������� RegionServer �� Region��û�г���һ��ʱ�䶼û��ˢд,
- ���ʱ������ hbase.regionserver.optionalcacheflushinterval �������Ƶ�,Ĭ���� 3600000,
- Ҳ����1Сʱ�����һ��ˢд
- ���ݸ��³���һ����ֵ
- ��� HBase ��ij�� Region ���µĺ�Ƶ��,
- ���Ҽ�û�дﵽ�Զ�ˢд��ֵ,
- Ҳû�дﵽ�ڴ��ʹ������,
- �����ڴ��еĸ��������Ѿ��㹻��,
- ���糬�� hbase.regionserver.flush.per.changes ��������,Ĭ��Ϊ30000000,
- ��ôҲ�ǻᴥ��ˢд�ġ�
- ��ȡ����
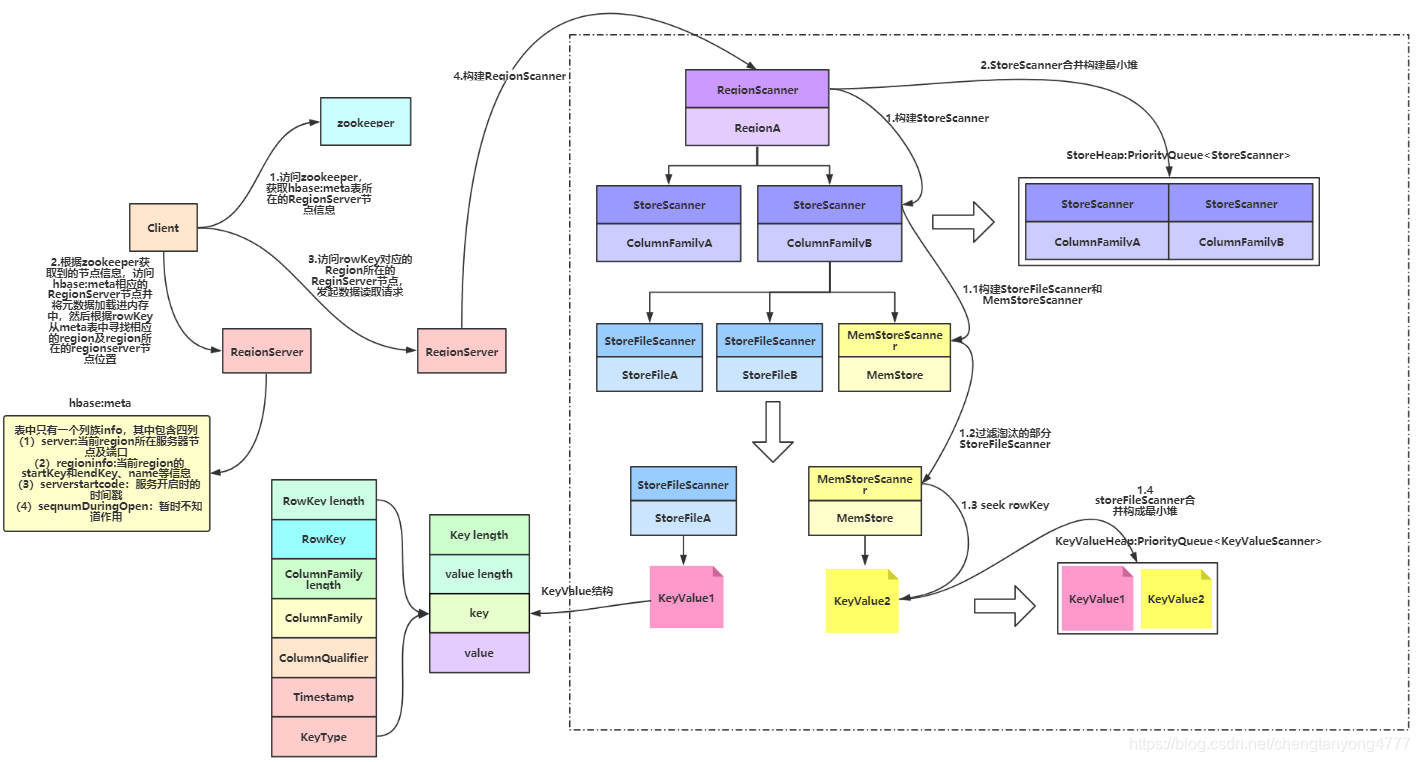
- Client����zookeeper,��ȡhbase:meta����RegionServer�Ľڵ���Ϣ��
- Client����hbase:meta���ڵ�RegionServer,��ȡhbase:meta��¼��Ԫ���ݺ��ȼ��ص��ڴ���,Ȼ���ٴ��ڴ��и�����Ҫ��ѯ��RowKey��ѯ��RowKey���ڵ�Region�������Ϣ(Region����RegionServer)
- Client����RowKey����Region��Ӧ��RegionServer,�������ݶ�ȡ����
- RegionServer����RegionScanner(��Ҫ��ѯ��RowKey�ֲ��ڶ��ٸ�Region�о���Ҫ�������ٸ�RegionScanner),���ڶԸ�Region�����ݼ���
- RegionScanner����StoreScanner(Region���ж��ٸ�Store����Ҫ�������ٸ�StoreScanner,Store������ȡ����Table��ColumnFamily������),���ڶԸ���������ݼ���
- ���StoreScanner�ϲ�������С��(���������ȫ������)StoreHeap:PriorityQueue<StoreScanner>
- StoreScanner����һ��MemStoreScanner��һ������StoreFileScanner(����ȡ����StoreFile����)
- ���˵�ijЩ�ܹ�ȷ����Ҫ��ѯ��RowKeyһ������StoreFile�ڵĶ�Ӧ��StoreFileScanner��MemStoreScanner
- ����ɸѡ�����µ�Scanner��ʼ����ȡ���ݵ���,����Ӧ��StoreFile��λ�������RowKey����ʼλ��
- �����е�StoreFileScanner��MemStoreScanner�ϲ�������С��KeyValueHeap:PriorityQueue<KeyValueScanner>,����Ĺ�����KeyValue��С��������
- ��KeyValueHeap:PriorityQueue<KeyValueScanner>�о���һϵ��ɸѡ��һ���еĵõ���Ҫ��ѯ��KeyValue��
- �ϲ�����
- HBase Compaction��Ϊ����:Minor Compaction �� Major Compaction,ͨ�����Ǽ��ΪС�ϲ�����ϲ�

- Minor Compaction:ָѡȡһЩС�ġ����ڵ�HFile�����Ǻϲ���һ�������HFile��Ĭ�������,minor compaction��ɾ��ѡȡHFile�е�TTL�������ݡ�
- Major Compaction:ָ��һ��Store�����е�HFile�ϲ���һ��HFile,������̻���������û�����������:��ɾ��������(����Delete��ǵ�����)��TTL�������ݡ��汾�ų����趨�汾�ŵ����ݡ�����,һ�������,Major Compactionʱ�������Ƚϳ�,�������̻����Ĵ���ϵͳ��Դ,���ϲ�ҵ���бȽϴ��Ӱ�졣���,����������ͨ���ر��Զ�����Major Compaction����,��Ϊ�ֶ���ҵ��ͷ��ڴ�����
- Compaction ��������
- memstore flush:����˵compaction�ĸ�Դ������flush,memstore �ﵽһ����ֵ����������ʱ�ͻᴥ��flushˢд����������HFile�ļ�,������ΪHFile�ļ�Խ��Խ�����Ҫcompact��HBaseÿ��flush֮��,�����ж��Ƿ�Ҫ����compaction,һ������minor compaction��major compaction��������ᴥ��ִ�С�
- ��̨�߳������Լ��: ��̨�߳� CompactionChecker �ᶨ�ڼ���Ƿ���Ҫִ��compaction,�������Ϊhbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier,������Ҫ���ǵ���һ��ʱ����û��д��������Ȼ��Ҫ��compact��顣���в��� hbase.server.thread.wakefrequency Ĭ��ֵ 10000 �� 10s,��HBase������̻߳���ʱ����,����log roller��memstore flusher�Ȳ��������Լ��;���� hbase.server.compactchecker.interval.multiplier Ĭ��ֵ1000,��compaction���������Լ��������ӡ�10 * 1000 s ʱ����Լ����2hrs, 46mins, 40sec��
- �����Ż�
- ģ�Ͳ����Ż�
- ����hbaseʹ����;�����ڴ�������
- ����
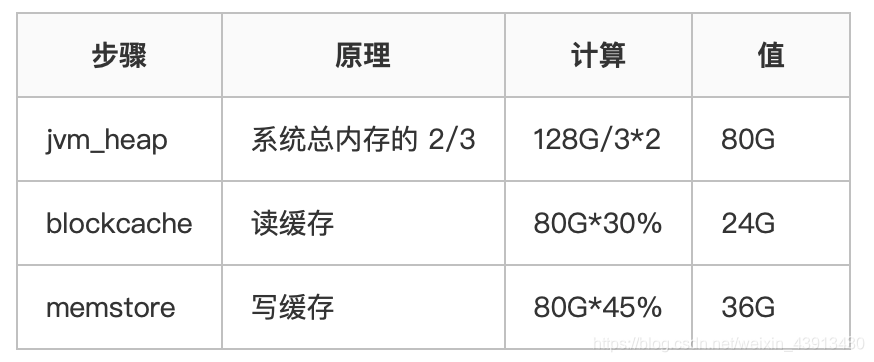
- hbase-site.xmll
<property> <name>hbase.regionserver.global.memstore.size</name> <value>0.45</value> </property> <property> <name>hfile.block.cache.size</name> <value>0.3</value> </property>
- �����
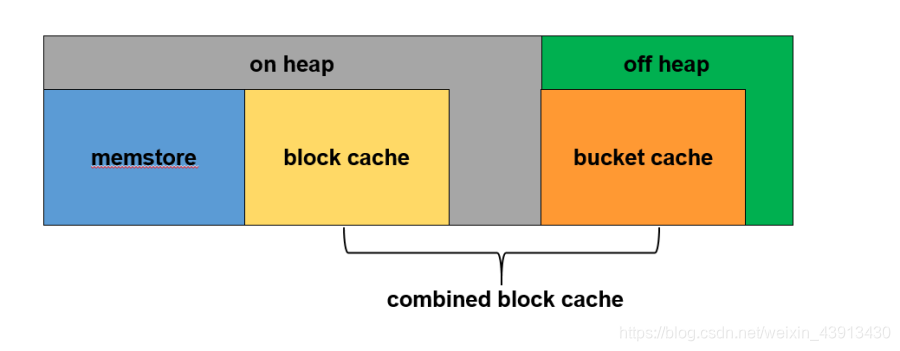
-
���� ԭ�� ���� ֵ RS���ڴ�ϵͳ���ڴ�� 2/3 128G/3*2 80G combinedBlockCache ����������Ϊ����RS�ڴ��70% 80G*70% 56G blockcache ��Ҫ�������ݿ�Ԫ����,��������Խ�С������Ϊ�����������10% 56G*10% 6G bucketcache ��Ҫ�����û����ݿ�,��������Խϴ�����Ϊ�����������90% 56G*90% 50G memstore д��������Ϊjvm_heap��60% 30G*60% 18G jvm_heap rs���ڴ�-�����ڴ� 80G-50G 30G - hbase-site.xml
<property> <name>hbase.bucketcache.combinedcache.enabled</name> <value>true</value>#��������Ϊtrue </property> <property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> #ͬʱ��Ϊmaster��rsҪ��heap </property> <property> <name>hbase.bucketcache.size</name> <value>50176</value> #��λMB�����ֵ����Ҫ��bucketcacheС1G,��Ϊmaster��rs��heap,��ô����Ҫ��<1��ֵ��Ϊ��heap�з����bucketcache�İٷֱ� </property> <property> <name>hbase.regionserver.global.memstore.size</name> <value>0.60</value> #heap��С��,��ôheap������memstore�İٷֱ�Ҫ������ܱ�֤����memstore���ڴ��ԭ��һ�� </property> <property> <name>hfile.block.cache.size</nname> <value>0.20</value> #ʹ����bucketcache��Ϊblockcache��һ����,��ôheap������blockcache�İٷֱȿ��Լ�С </property> - hbase-env.sh
?export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms30g �CXmx30g -XX:MaxDirectMemorySize=50g?
- ���������Ż�
- *hbase.hstore.blockingStoreFiles:Ĭ��ֵ7.���storefile��������������ֵ,�ͻ�����flush,compact�߳̽��кϲ�,�����������д�����ƽ������ҵ��д������,���Կ��������ֵ��
- *hbase.hregion.memstore.flush.size:Ĭ��ֵ128MB,ָ����region��memstoreʹ���ڴ泬��������flush�����region����д�����ݳ�����ֵ��ִ��flush�������ɸ���ʵ������������ȷ���Ƿ���Ҫ�����ֵ��
- *hbase.hregion.memstore.block.multiplier:Ĭ��ֵ4.ָmestore���ڴ��С����hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier�ͻ�����д�����������������ܴ��������ֵ,Ҳ���������úܴ�,���̫���������������RS��memstore�ڴ泬��memstore.upperLimit���ƵĿ�����,����������������RS��д�ļ���
- *hbase.regionserver.global.memstore.upperLimit: Ĭ��ֵ0.4��regionserver����memstoreռ���ڴ������ڴ��е�upper����,���ﵽ��ֵ,��������regionserver���ҳ�����Ҫflush��region����flush,ֱ�����ڴ����������������,����Ĭ��ֵ���ɡ�
- *hbase.regionserver.global.memstore.lowerLimit:Ĭ��ֵ0.35,����Ĭ��ֵ���ɡ�
- *hfile.block.cache.size:Ĭ��ֵ0.25,regionserver��block cache���ڴ��С����,��ƫ�����ҵ����,�����ʵ������ֵ,��Ҫע�����hbase.regionserver.global.memstore.upperLimit��ֵ��hfile.block.cache.size��ֵ֮�ͱ���С��0.8��
- *hbase.regionserver.handler.count:Ĭ��ֵ10,ÿ��regionserver������RPC Listenerʵ������,hbase.master.handler.count������˼��������һ����handler��������Խ��Խ��,��������˹����handler���ܵõ�һ���ʵ��䷴�Ľ���������read-only�ij���,handler�ĸ����ӽ���cpu�����ȽϺá��ڵ����ò���ʱ��,��������Ϊcpu�����ı���,������cpu������ʼ������
- *hbase.hregion.max.filesize:Ĭ��ֵ10G������region split�ķ�ֵ,��Ҫע��:����ж���д�,�����ĸ��дشﵽ�˸�ֵ,�ͻᴥ��split,������region�����,�����������дص�hfileֵ����С��Ŀǰ��˵,�Ƽ������region sizeΪ10-20G,��ȻҲ�������õĸ���,����50G(���������ѹ��,��ֵָ����ѹ��֮��Ĵ�С)
- hbase.regionserver.region.split.policy = SteppingSplitPolicy? ?split�㷨
- *zookeeper.session.timeout:Ĭ��ֵ90000�������øò���ֵ��Ҫע��,Ҫ��עzookeeper server��Minimum session timeout��Maximum session timeout,zookeeperĬ��Minimum session timeout Ϊ 2 * tick time,Maximum session timeout Ϊ 20*tick time,tick timeΪ�������(Ĭ��2��)Ҳ����˵����hbase�����õ����Ự��ʱʱ��������client���������õ�,�������ջ�����zookeeper serverΪ��
- *hbase.regionserver.thread.compaction.small:Ĭ��ֵ1������minor compact���߳���,��compact quene�Ƚϸߵ�ʱ��,�������Ӹ�ֵ����������Ϊ5��
- *hbase.regionserver.thread.compaction.large:Ĭ��ֵ1��regionserver��Major Compactionʱ�̳߳����߳���Ŀ,��������Ϊ8��
- *hbase.hregion.majorcompaction:Ĭ��ֵ1�� major compactʱ������,Ĭ��1��,���Ǵ���ʱ���������������ѵġ�����һ�����ϻ���������major compact(����Ϊ0),Ȼ���ں��ʵ�ʱ���ֶ�ִ��
- *hbase.hstore.compaction.min:Ĭ��ֵ3,����κ�һ��store���storefile����������ֵ,�ᴥ��Ĭ�ϵĺϲ�����,��������5~8,���ֶ��Ķ���major compact�н���storefile�ļ��ĺϲ�,���ٺϲ��Ĵ���,��������ӳ��ϲ���ʱ��,��ǰ�Ķ�Ӧ����Ϊhbase.hstore.compactionThreshold��
- hbase.hstore.compaction.max:Ĭ��ֵ10,һ�����ϲ����ٸ�storefile,����OOM
- hbase.regionserver.hlog.blocksize :Ĭ��ֵ128MB��Ĭ�ϼ���,������Ҫ�˽����WALһ���ڴﵽ��ֵ��95%��ʱ��ͻ����
- *hbase.regionserver.maxlogs :Ĭ��ֵ32������WAL Files������,WAL files���ٵĻ�,�ᴥ�������flush,̫��Ļ�,hbase recoveryʱ���Ƚϳ������Բο� max(32, hbase_heapsize * hbase.regionserver.global.memstore.size? / logRollSize)
- *hbase.wal.provider:�������ó�mutiwal��Ĭ�������,һ��regionserverֻ��һ��wal�ļ�,����region��walEntry��д�����wal�ļ���,��HBase-5699֮��,һ��regionserver�������ö��wal�ļ�,�����������дWALʱ������,������������д��ʱ
- hfile.block.index.cacheonwrite:��indexд���ʱ������put��(non-root)�Ķ༶�����鵽block cache��,Ĭ����false,����Ϊtrue,���������ܸ���,�����Ƿ��и����û������
- hbase.rs.cacheblocksonwrite:Ĭ��false,
- dfs.socket.timeout:Ĭ��ֵ60000(60s),�������ʵ��regionserver����־��ط������쳣���к���������,����������Ϊ900000,�������������Ҫͬʱ����hdfs-site.xml
- dfs.datanode.socket.write.timeout:Ĭ��480000(480s),��ʱregionserver���ϲ�ʱ,���ܻ����datanodeд��ʱ����,�������������Ҫͬʱ����hdfs-site.xml
- HBase�����Ե���
- *Compression
1.����ѡ�����NONE, GZIP, SNAPPY, �ȵ� 2.ָ��ѹ����ʽ:create ��test', {NAME => ��cf', COMPRESSION => 'SNAPPY��}} 3.��ʡ���̿ռ� 4.ѹ����Ե���������,��get��scan��̫�Ѻ� 5.������ʱ��ʹ��ѹ��,����ָ��hbase.block.data.cachecompressed = true, �������Ի������Ŀ�,���Ƕ�ȡ����ʱ��,��Ҫ���н�ѹ�� - HFile Block Size
1. ����ͬ��HDFS block size 2. ָ��BLOCKSIZE���� create ��test��,{NAME => ��cf��, BLOCKSIZE => ��4096'} 3.Ĭ��64KB,��Scan��Get��ͬ�ij����Ƚ��Ѻ� 4.���Ӹ�ֵ������scan 5.��С��ֵ������get
- *Compression
- *RegionServer�ڵ�Ӳ������
- Ӳ�̺��ڴ����
Disk/Heap ratio=RegionSize / MemstoreSize *ReplicationFactor *HeapFractionForMemstores * 2 - ��ô��Ĭ�������,�ñ�������:10gb/128mb * 3 * 0.4 * 2 = 192���ڴ�����ÿ�洢192�ֽڵ�����,��Ӧ�ѵĴ�СӦΪ1�ֽ�,��ô�������32G�Ķ�,������Ҳ���ǿ��Դ洢���6TB������(32gb * 192 = 6tb)
- ����״����regionserver��Ӳ������:
1.ÿ���ڵ�<=6TB�Ĵ��̿ռ� 2.regionserver heap Լ���ڴ��̴�С/200(����ı�����ʽ) 3.����hbase����cpu�ܼ���,���Խ϶��cpu core�������ʺ� 4.���������ʹ�����������ƥ��ֵ: (����:����ʹ�ô�ͳHDD,I/O 100M/s) CASE1:1GE������,�䱸24�����,�������Ĵ����Dz�̫�����,��Ϊ1GE��������������125M/s,��24����̵����������2.4GB/s,������Ϊƿ�� CASE2:10GE������,�䱸24�����,�Ƚ����� CASE3:1GE������,����4-6�����,Ҳ�DZȽ������
- Ӳ�̺��ڴ����
- ? ? Hbase Client���Ż�
1.hbase.client.write.buffer:Ĭ��Ϊ2M,д�����С,�Ƽ�����Ϊ5M,��λ���ֽ�,��ȻԽ��ռ�õ��ڴ�Խ��,������Թ���Ϊ10M�µ��������,����û��5M��hbase.client.write.buffer:Ĭ��Ϊ2M,д�����С,�Ƽ�����Ϊ5M,��λ���ֽ�,��ȻԽ��ռ�õ��ڴ�Խ��,������Թ���Ϊ10M�µ��������,����û��5M��2.hbase.client.pause:Ĭ����1000(1s),�����ϣ������ʱ�Ķ�����д,������Ϊ200,���ֵͨ������ʧ������,regionѰ�ҵ�hbase.client.pause:Ĭ����1000(1s),�����ϣ������ʱ�Ķ�����д,������Ϊ200,���ֵͨ������ʧ������,regionѰ�ҵ�3.hbase.client.retries.number:Ĭ��ֵ��10,�ͻ���������Դ���,������Ϊ11,�������IJ���,������ʱ��71shbase.client.retries.number:Ĭ��ֵ��10,�ͻ���������Դ���,������Ϊ11,�������IJ���,������ʱ��71s4.hbase.ipc.client.tcpnodelay:Ĭ����false,������Ϊtrue,�ر���Ϣ����hbase.ipc.client.tcpnodelay:Ĭ����false,������Ϊtrue,�ر���Ϣ����5.hbase.client.scanner.caching:scan����,Ĭ��Ϊ1,����ռ�ù����client��rs���ڴ�,һ��1000���ں���,���һ������̫��,��Ӧ������һ����С��ֵ,ͨ��������ҵ�������һ�β�ѯ����������hbase.client.scanner.caching:scan����,Ĭ��Ϊ1,����ռ�ù����client��rs���ڴ�,һ��1000���ں���,���һ������̫��,��Ӧ������һ����С��ֵ,ͨ��������ҵ�������һ�β�ѯ���������� �����ɨ�����ݶ��´β�ѯû�а���,���������scan��setCacheBlocksΪfalse,����ʹ�û���;6.table������ر�,�ر�scannertable������ر�,�ر�scanner7.��ɨ�跶Χ:ָ���дػ���ָ��Ҫ��ѯ����,ָ��startRow��endRow��ɨ�跶Χ:ָ���дػ���ָ��Ҫ��ѯ����,ָ��startRow��endRow8.ʹ��Filter�ɴ���������������ʹ��Filter�ɴ���������������9.ͨ��java���߳����Ͳ�ѯ,�����Ƴ�ʱʱ�䡣����Ṳ�����ҵ�hbase�������߳����Ĵ���ͨ��java���߳����Ͳ�ѯ,�����Ƴ�ʱʱ�䡣����Ṳ�����ҵ�hbase�������߳����Ĵ���10.����ע������:����ע���������������rowkey ����Ԥ���� ����bloomfilter - zookeeper����
1.zookeeper.session.timeout:Ĭ��ֵ3����,��������̫��,����session��ʱ,hbaseֹͣ����zookeeper.session.timeout:Ĭ��ֵ3����,��������̫��,����session��ʱ,hbaseֹͣ����2.zookeeper����:����5������7���ڵ㡣��ÿ��zookeeper 4G���ҵ��ڴ�,����ж����Ĵ��̡�zookeeper����:����5������7���ڵ㡣��ÿ��zookeeper 4G���ҵ��ڴ�,����ж����Ĵ��̡�3.hbase.zookeeper.property.maxClientCnxns:zk�����������,Ĭ��Ϊ300,���������hbase.zookeeper.property.maxClientCnxns:zk�����������,Ĭ��Ϊ300,���������4.���ò���ϵͳ��swappinessΪ0,���������ڴ治��������²Ż�ʹ�ý�������,����GC����ʱ�Ứ�Ѹ����ʱ��,������zk��session��ʱʱ��������regionserver崻��������ò���ϵͳ��swappinessΪ0,���������ڴ治��������²Ż�ʹ�ý�������,����GC����ʱ�Ứ�Ѹ����ʱ��,������zk��session��ʱʱ��������regionserver崻����� - hdfs����
1.dfs.name.dir:namenode�����ݴ�ŵ�ַ,�������ö��,λ�ڲ�ͬ�Ĵ��̲�����һ��nfsԶ���ļ�ϵͳ,����namenode�����ݿ����ж������dfs.name.dir:namenode�����ݴ�ŵ�ַ,�������ö��,λ�ڲ�ͬ�Ĵ��̲�����һ��nfsԶ���ļ�ϵͳ,����namenode�����ݿ����ж������2.dfs.namenode.handler.count:namenode�ڵ�RPC�Ĵ����߳���,Ĭ��Ϊ10,��������Ϊ60dfs.namenode.handler.count:namenode�ڵ�RPC�Ĵ����߳���,Ĭ��Ϊ10,��������Ϊ603.dfs.datanode.handler.count:datanode�ڵ�RPC�Ĵ����߳���,Ĭ��Ϊ3,��������Ϊ30dfs.datanode.handler.count:datanode�ڵ�RPC�Ĵ����߳���,Ĭ��Ϊ3,��������Ϊ304.dfs.datanode.max.xcievers:datanodeͬʱ�����ļ�������,Ĭ��Ϊ256,��������Ϊ8192dfs.datanode.max.xcievers:datanodeͬʱ�����ļ�������,Ĭ��Ϊ256,��������Ϊ8192 - regionserver��region������Ҫ��1000,�����region�ᵼ�²����ܶ�memstore,���ܻᵼ���ڴ����,Ҳ������major compact�ĺ�ʱ