Apache Hadoop ЭъШЋЗжВМЪНМЏШКДюНЈ
ЛЗОГДюНЈзМБИ
-
ШэМўКЭВйзїЯЕЭГАцБО
HadoopПђМмЪЧВЩгУJavaгябдБраД,ашвЊjavaЛЗОГ(jvm)
JDKАцБО:JDK8АцБО
-
HadoopДюНЈЗНЪН
ЕЅЛњФЃЪН:ЕЅНкЕуФЃЪН,ЗЧМЏШК,ЩњВњВЛЛсЪЙгУетжжЗНЪН
ЕЅЛњЮБЗжВМЪНФЃЪН:ЕЅНкЕу,ЖрЯпГЬФЃФтМЏШКЕФаЇЙћ,ЩњВњВЛЛсЪЙгУетжжЗНЪН
ЭъШЋЗжВМЪНФЃЪН:ЖрЬЈНкЕу,еце§ЕФЗжВМЪНHadoopМЏШКЕФДюНЈ(ЩњВњЛЗОГНЈвщЪЙгУетжжЗНЪН)
-
Ш§ЬЈащФтЛњ(ОВЬЌIP,ЙиБеЗРЛ№ЧН,аоИФжїЛњУћ,ХфжУУтУмЕЧТМ,МЏШКЪБМфЭЌВН)ПЩвдздМКШЅАйЖШ,КѓЦкдкНЋНЬГЬЩЯДЋ
-
дк/optФПТМЯТДДНЈЮФМўМа
mkdir -p /opt/szx/software --ШэМўАВзААќДцЗХФПТМ mkdir -p /opt/szx/servers --ШэМўАВзАФПТМ -
HadoopЯТдиЕижЗ:
https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/HadoopЙйЭјЕижЗ:
http://hadoop.apache.org/ -
ЩЯДЋhadoopАВзАЮФМўЕН/opt/szx/software
МЏШКЙцЛЎ
| ПђМм | linux121 | linux122 | linux123 |
|---|---|---|---|
| HDFS | NameNodeЁЂDataNode | DataNode | SecondaryNameNodeЁЂDataNode |
| YARN | NodeManager | NodeManager | NodeManagerЁЂResourceManager |
АВзАHadoop
-
ЕЧТМlinux121НкЕу;НјШы/opt/szx/software,НтбЙАВзАЮФМўЕН/opt/szx/servers
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/szx/servers -
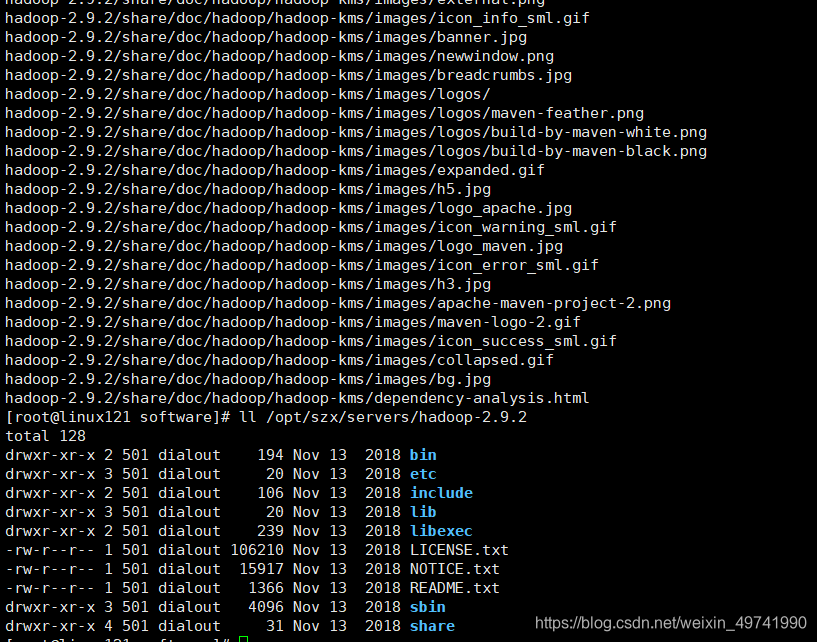
ВщПДЪЧЗёНтбЙГЩЙІ
ll /opt/szx/servers/hadoop-2.9.2
-
ЬэМгHadoopЕНЛЗОГБфСП vi /etc/profile
##HADOOP_HOME export HADOOP_HOME=/opt/szx/servers/hadoop-2.9.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
ЪЙЛЗОГБфСПЩњаЇ
source /etc/profile -
бщжЄhadoop
hadoop version

-
hadoopФПТМ
drwxr-xr-x. 2 root root 194 Nov 13 2018 bin drwxr-xr-x. 3 root root 20 Nov 13 2018 etc drwxr-xr-x. 2 root root 106 Nov 13 2018 include drwxr-xr-x. 3 root root 20 Nov 13 2018 lib drwxr-xr-x. 2 root root 239 Nov 13 2018 libexec -rw-r--r--. 1 root root 106210 Nov 13 2018 LICENSE.txt -rw-r--r--. 1 root root 15917 Nov 13 2018 NOTICE.txt -rw-r--r--. 1 root root 1366 Nov 13 2018 README.txt drwxr-xr-x. 3 root root 4096 Nov 13 2018 sbin drwxr-xr-x. 4 root root 31 Nov 13 2018 share 1. binФПТМ:ЖдHadoopНјааВйзїЕФЯрЙиУќСю,Шчhadoop,hdfsЕШ 2. etcФПТМ:HadoopЕФХфжУЮФМўФПТМ,Шыhdfs-site.xml,core-site.xmlЕШ 3. libФПТМ:HadoopБОЕиПт(НтбЙЫѕЕФвРРЕ) 4. sbinФПТМ:ДцЗХЕФЪЧHadoopМЏШКЦєЖЏЭЃжЙЯрЙиНХБО,УќСю 5. shareФПТМ:HadoopЕФвЛаЉjar,ЙйЗНАИР§jar,ЮФЕЕЕШ
МЏШКХфжУ
HadoopМЏШКХфжУ = HDFSМЏШКХфжУ + MapReduceМЏШКХфжУ + YarnМЏШКХфжУ
-
HDFSМЏШКХфжУ
- НЋJDKТЗОЖУїШЗХфжУИјHDFS(аоИФhadoop-env.sh)
- жИЖЈNameNodeНкЕувдМАЪ§ОнДцДЂФПТМ(аоИФcore-site.xml)
- жИЖЈSecondaryNameNodeНкЕу(аоИФhdfs-site.xml)
- жИЖЈDataNodeДгНкЕу(аоИФetc/hadoop/slavesЮФМў,УПИіНкЕуХфжУаХЯЂеМвЛаа)
-
MapReduceМЏШКХфжУ
- НЋJDKТЗОЖУїШЗХфжУИјMapReduce(аоИФmapred-env.sh)
- жИЖЈMapReduceМЦЫуПђМмдЫааYarnзЪдДЕїЖШПђМм(аоИФmapred-site.xml)
-
YarnМЏШКХфжУ
- НЋJDKТЗОЖУїШЗХфжУИјYarn(аоИФyarn-env.sh)
- жИЖЈResourceManagerРЯДѓНкЕуЫљдкМЦЫуЛњНкЕу(аоИФyarn-site.xml)
- жИЖЈNodeManagerНкЕу(ЛсЭЈЙ§slavesЮФМўФкШнШЗЖЈ)(ШєЭъГЩHDFSМЏШКХфжУЕкЫФВН,ДЫВНПЩЪЁТд)
МЏШКХфжУОпЬхВНжш:
HDFSМЏШКХфжУ
cd /opt/szx/servers/hadoop-2.9.2/etc/hadoop
-
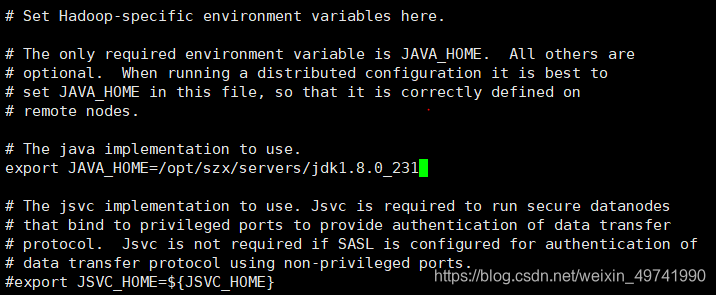
ХфжУ:hadoop-env.sh
НЋJDKТЗОЖУїШЗХфжУИјHDFS
vi hadoop-env.sh export JAVA_HOME=/opt/szx/servers/jdk1.8.0_231
-
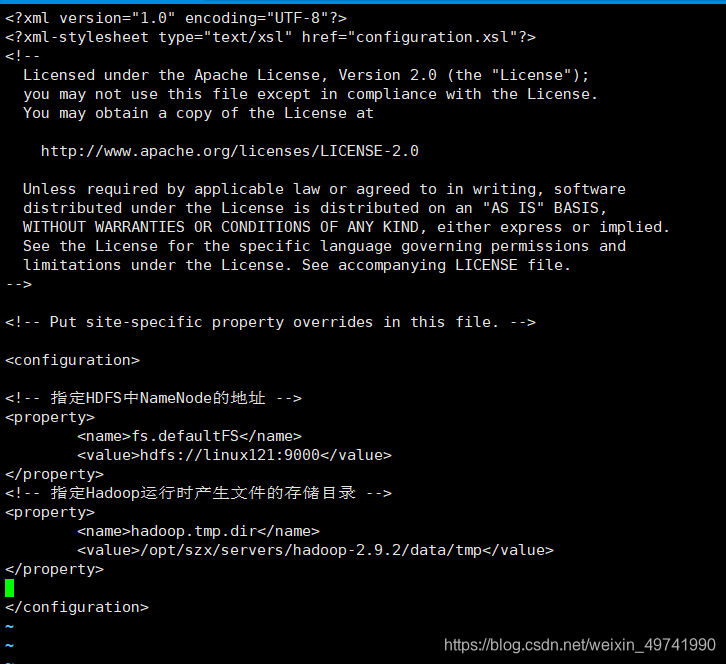
жИЖЈNameNodeНкЕувдМАЪ§ОнДцДЂФПТМ(аоИФcore-site.xml)
vi core-site.xml <!-- жИЖЈHDFSжаNameNodeЕФЕижЗ --> <property> <name>fs.defaultFS</name> <value>hdfs://linux121:9000</value> </property> <!-- жИЖЈHadoopдЫааЪБВњЩњЮФМўЕФДцДЂФПТМ --> <property> <name>hadoop.tmp.dir</name> <value>/opt/szx/servers/hadoop-2.9.2/data/tmp</value> </property>
-
core-site.xmlЕФФЌШЯХфжУ:
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml -
жИЖЈsecondarynamenodeНкЕу(аоИФhdfs-site.xml)
vi hdfs-site.xml <!-- жИЖЈHadoopИЈжњУћГЦНкЕужїЛњХфжУ --> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux123:50090</value> </property> <!--ИББОЪ§СП --> <property> <name>dfs.replication</name> <value>3</value> </property>
ЙйЗНФЌШЯХфжУ
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml -
жИЖЈdatanodeДгНкЕу(аоИФslavesЮФМў,УПИіНкЕуХфжУаХЯЂеМвЛаа)
vi slaves linux121 linux122 linux123

зЂвт:ИУЮФМўжаЬэМгЕФФкШнНсЮВВЛдЪаэгаПеИё,ЮФМўжаВЛдЪаэгаПеааЁЃ
MapReduceМЏШКХфжУ
-
жИЖЈMapReduceЪЙгУЕФjdkТЗОЖ(аоИФmapred-env.sh)
vi mapred-env.sh export JAVA_HOME=/opt/szx/servers/jdk1.8.0_231
-
жИЖЈMapReduceМЦЫуПђМмдЫааYarnзЪдДЕїЖШПђМм(аоИФmapred-site.xml)
mv mapred-site.xml.template mapred-site.xml vi mapred-site.xml <!-- жИЖЈMRдЫаадкYarnЩЯ --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>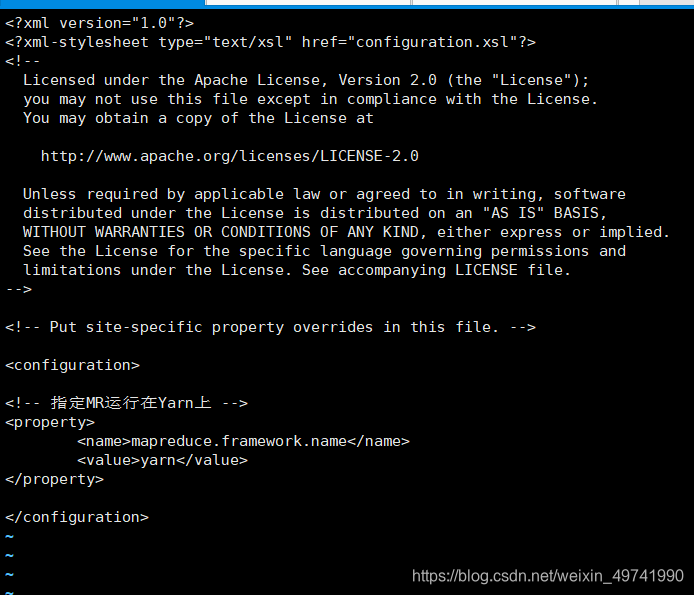
mapred-site.xmlФЌШЯХфжУ:
https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
YarnМЏШКХфжУ
-
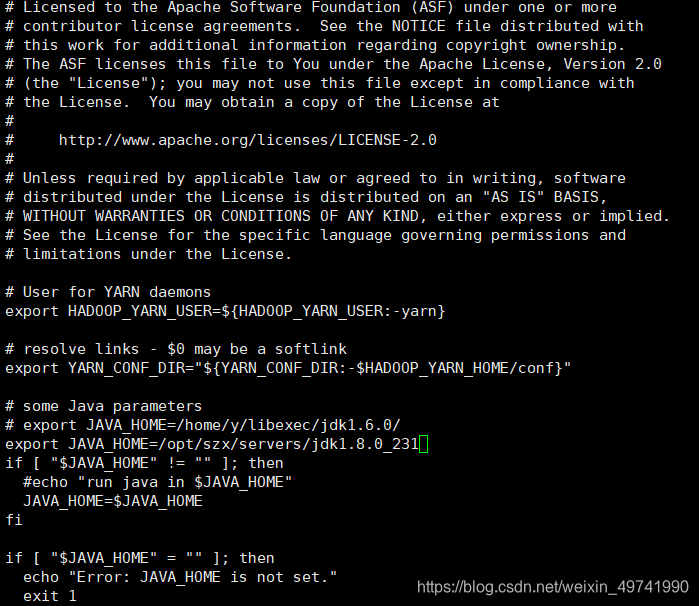
жИЖЈJDKТЗОЖ
vi yarn-env.sh export JAVA_HOME=/opt/szx/servers/jdk1.8.0_231
-
жИЖЈResourceMnagerЕФmasterНкЕуаХЯЂ(аоИФyarn-site.xml)
vi yarn-site.xml<!-- жИЖЈYARNЕФResourceManagerЕФЕижЗ --><property> <name>yarn.resourcemanager.hostname</name> <value>linux123</value></property><!-- ReducerЛёШЁЪ§ОнЕФЗНЪН --><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property>

yarn-site.xmlЕФФЌШЯХфжУ
https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
- жИЖЈNodeManagerНкЕу(slavesЮФМўвбаоИФ)
зЂвт:
HadoopАВзАФПТМЫљЪєгУЛЇКЭЫљЪєгУЛЇзщаХЯЂ,ФЌШЯЪЧ501 dialout,ЖјЮвУЧВйзїHadoopМЏШКЕФгУЛЇЪЙгУЕФЪЧащФтЛњЕФrootгУЛЇ,ЫљвдЮЊСЫБмУтГіЯжаХЯЂЛьТв,аоИФHadoopАВзАФПТМЫљЪєгУЛЇКЭгУЛЇзщ!!
chown -R root:root /opt/szx/servers/hadoop-2.9.2
ЗжЗЂХфжУ
БраДМЏШКЗжЗЂНХБОrsync-script
-
rsync дЖГЬЭЌВНЙЄОп
rsyncжївЊгУгкБИЗнКЭОЕЯёЁЃОпгаЫйЖШПьЁЂБмУтИДжЦЯрЭЌФкШнКЭжЇГжЗћКХСДНгЕФгХЕуЁЃ
rsyncКЭscpЧјБ№:гУrsyncзіЮФМўЕФИДжЦвЊБШscpЕФЫйЖШПь,rsyncжЛЖдВювьЮФМўзіИќаТЁЃscpЪЧАбЫљгаЮФМўЖМИДжЦЙ§ШЅЁЃ
-
ЛљБОгяЗЈ
rsync -rvl $pdir/$fname $user@$host:$pdir/$fnameУќСю бЁЯюВЮЪ§ вЊПНБДЕФЮФМўТЗОЖ/УћГЦ ФПЕФгУЛЇ@жїЛњ:ФПЕФТЗОЖ/УћГЦ
-
бЁЯюВЮЪ§ЫЕУї
бЁЯю ЙІФм -r ЕнЙщ -v ЯдЪОИДжЦЙ§ГЬ -l ПНБДЗћКХСЌНг
-
-
rsyncАИР§
-
Ш§ЬЈащФтЛњАВзАrsync (жДааАВзАашвЊБЃжЄЛњЦїСЊЭј)
yum install -y rsync

-
Абlinux121ЛњЦїЩЯЕФ/opt/szx/softwareФПТМЭЌВНЕНlinux122ЗўЮёЦїЕФrootгУЛЇЯТЕФ/opt/ФПТМ
rsync -rvl /opt/szx/software/ root@linux122:/opt/szx/software
-
-
МЏШКЗжЗЂНХБОБраД
-
ашЧѓ:бЛЗИДжЦЮФМўЕНМЏШКЫљгаНкЕуЕФЯрЭЌФПТМЯТ
rsyncУќСюдЪМПНБД:
rsync -rvl /opt/module root@linux123:/opt/ -
ЦкЭћНХБО
-
ЫЕУї:дк/usr/local/binетИіФПТМЯТДцЗХЕФНХБО,rootгУЛЇПЩвддкЯЕЭГШЮКЮЕиЗНжБНгжДааЁЃ
-
НХБОЪЕЯж
(1) дк/usr/local/binФПТМЯТДДНЈЮФМўrsync-script,ЮФМўФкШнШчЯТ:
touch rsync-scriptvi rsync-scriptдкЮФМўжаБраДshellДњТы
#!/bin/bash#1 ЛёШЁУќСюЪфШыВЮЪ§ЕФИіЪ§,ШчЙћИіЪ§ЮЊ0,жБНгЭЫГіУќСюparamnum=$#if((paramnum==0)); then echo no params;exit;fi#2 ИљОнДЋШыВЮЪ§ЛёШЁЮФМўУћГЦp1=$1file_name=`basename $p1`echo fname=${file_name}#3 ЛёШЁЪфШыВЮЪ§ЕФОјЖдТЗОЖdir_name=`cd -P $(dirname $p1); pwd`echo dirname=${dir_name}#4 ЛёШЁгУЛЇУћГЦuser=`whoami`#5 бЛЗжДааrsyncfor((host=121; host<124; host++)); doecho ------------------- target hostname=linux$host -------------------rsync -rvl ${dir_name}/${file_name} ${user}@linux${host}:${dir_name}done(2) аоИФНХБО rsync-script ОпгажДааШЈЯо
chmod 777 rsync-script(3) ЕїгУНХБОаЮЪН:rsync-script ЮФМўУћГЦ
rsync-script rsync-script
(4) ЕїгУНХБОЗжЗЂHadoopАВзАФПТМЕНЦфЫќНкЕу
rsync-script /opt/szx/servers/hadoop-2.9.2
-
ЦєЖЏМЏШК
зЂвт:ШчЙћМЏШКЪЧЕквЛДЮЦєЖЏ,ашвЊдкNamenodeЫљдкНкЕуИёЪНЛЏNameNode,ЗЧЕквЛДЮВЛгУжДааИёЪНЛЏNamenodeВйзї!!
ЕЅНкЕуЦєЖЏ
hadoop namenode -format


ИёЪНЛЏКѓДДНЈЕФЮФМў:/opt/szx/servers/hadoop-2.9.2/data/tmp/dfs/name/current

-
дкlinux121ЩЯЦєЖЏNameNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start namenode[root@linux121 hadoop-2.9.2]$ jps
-
дкlinux121ЁЂlinux122вдМАlinux123ЩЯЗжБ№ЦєЖЏDataNode
[root@linux121 hadoop-2.9.2]# hadoop-daemon.sh start datanodestarting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux121.out[root@linux121 hadoop-2.9.2]# jps7562 NameNode7738 Jps7660 DataNode#дкЪЙгУИУУќСюЪБВЛвЊЭќМЧИј/etc/profileЮФМўХфжУhadoopЕФТЗОЖ[root@linux122 hadoop-2.9.2]# hadoop-daemon.sh start datanodestarting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux122.out[root@linux122 sbin]# jps7553 DataNode7631 Jps[root@linux123 hadoop-2.9.2]# hadoop-daemon.sh start datanodestarting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux123.out[root@linux123 sbin]# jps7669 DataNode7711 Jps -
webЖЫВщПДHdfsНчУц
http://linux121:50070/dfshealth.html#tab-overview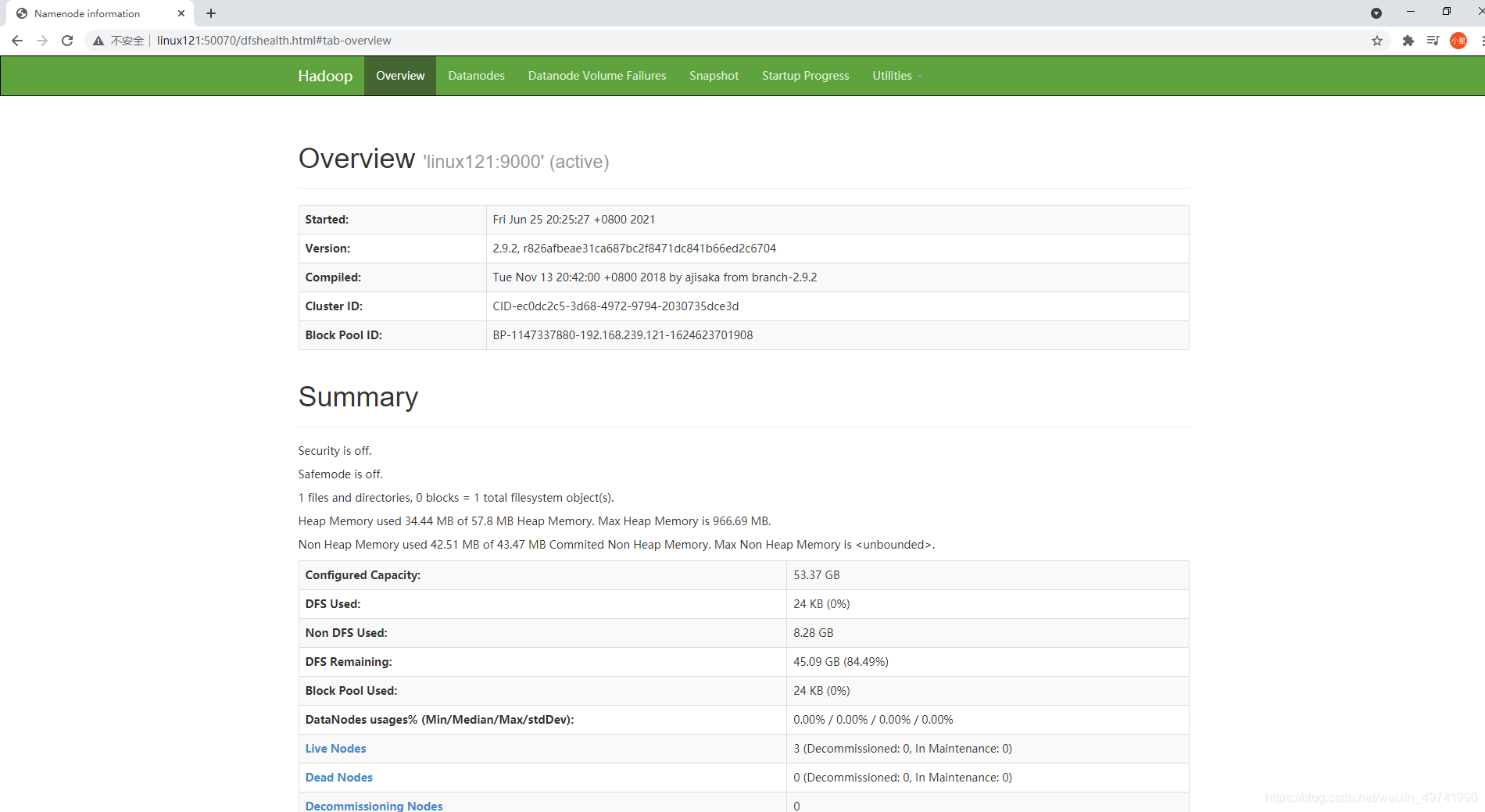
ВщПДHDFSМЏШКе§ГЃНкЕу:

YarnМЏШКЕЅНкЕуЦєЖЏ
[root@linux123 sbin]# yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /opt/szx/servers/hadoop-2.9.2/logs/yarn-root-resourcemanager-linux123.outYou have new mail in /var/spool/mail/root[root@linux123 sbin]# jps8033 Jps7669 DataNode7818 ResourceManager[root@linux122 sbin]# yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /opt/szx/servers/hadoop-2.9.2/logs/yarn-root-nodemanager-linux122.outYou have new mail in /var/spool/mail/root[root@linux122 sbin]# jps7553 DataNode7975 Jps7871 NodeManager[root@linux121 hadoop-2.9.2]# yarn-daemon.sh start nodemanagerstarting nodemanager, logging to /opt/szx/servers/hadoop-2.9.2/logs/yarn-root-nodemanager-linux121.out[root@linux121 hadoop-2.9.2]# jps8017 Jps7562 NameNode7660 DataNode7965 NodeManager
МЏШКШКЦ№
- ШчЙћвбОЕЅНкЕуЗНЪНЦєЖЏСЫHadoop,ПЩвдЯШЭЃжЙжЎЧАЕФЦєЖЏЕФNamenodeгыDatanodeНјГЬ,ШчЙћжЎЧАNamenodeУЛгажДааИёЪНЛЏ,етРяашвЊжДааИёЪНЛЏ!!!
hadoop namenode -format
-
ЦєЖЏHDFS
[root@linux121 sbin]# start-dfs.sh Starting namenodes on [linux121]linux121: starting namenode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-namenode-linux121.outlinux121: starting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux121.outlinux123: starting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux123.outlinux122: starting datanode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-datanode-linux122.outStarting secondary namenodes [linux123]linux123: starting secondarynamenode, logging to /opt/szx/servers/hadoop-2.9.2/logs/hadoop-root-secondarynamenode-linux123.out[root@linux121 sbin]# jps8282 NameNode8413 DataNode8621 Jps[root@linux122 hadoop-2.9.2]# jps8134 DataNode8214 Jps[root@linux123 hadoop-2.9.2]# jps8340 Jps8199 DataNode8297 SecondaryNameNode -
ЦєЖЏYARN
[root@linux123 sbin]# start-yarn.sh
HadoopМЏШКЦєЖЏЭЃжЙУќСюЛузм
-
ИїИіЗўЮёзщМўж№вЛЦєЖЏ/ЭЃжЙ
(1)ЗжБ№ЦєЖЏ/ЭЃжЙHDFSзщМў
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode[root@linux121 hadoop-2.9.2]# hadoop-daemon.sh stop namenodestopping namenode[root@linux121 hadoop-2.9.2]# hadoop-daemon.sh stop datanodestopping datanode(2)ЦєЖЏ/ЭЃжЙYARN
yarn-daemon.sh start / stop resourcemanager / nodemanager[root@linux121 hadoop-2.9.2]# yarn-daemon.sh stop nodemanagerstopping nodemanager -
ИїИіФЃПщЗжПЊЦєЖЏ/ЭЃжЙ(ХфжУsshЪЧЧАЬс)ГЃгУ
(1)ећЬхЦєЖЏ/ЭЃжЙHDFS
start-dfs.sh / stop-dfs.sh(2)ећЬхЦєЖЏ/ЭЃжЙYARN
start-yarn.sh / stop-yarn.sh
МЏШКВтЪд
-
HDFS ЗжВМЪНДцДЂГѕЬхбщ
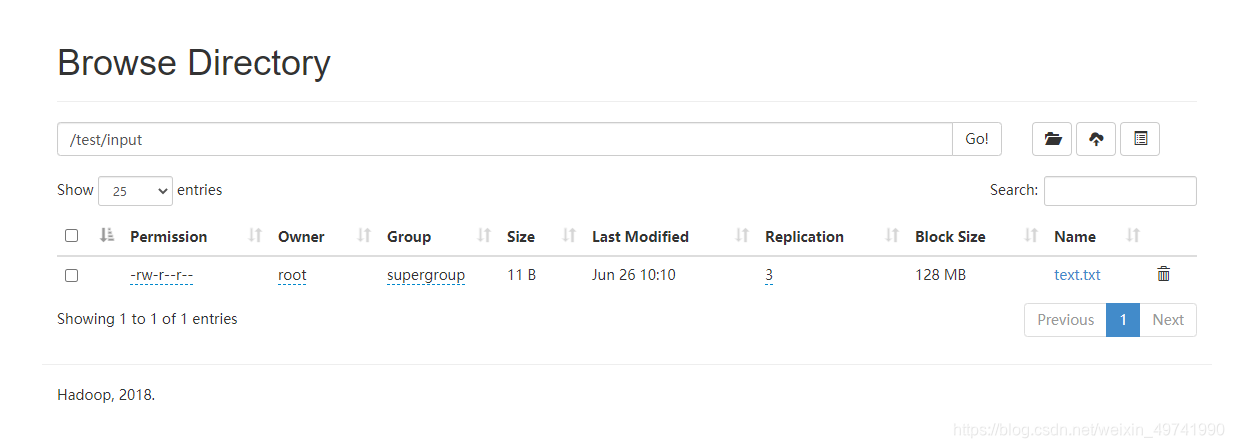
ДгlinuxБОЕиЮФМўЯЕЭГЩЯДЋЯТдиЮФМўбщжЄHDFSМЏШКЙЄзїе§ГЃ
#НјШыrootФПТМcd /root#ДДНЈЮФМўtest.txtvi text.txt#аДШыВтЪдЪ§Онhello hdfs#дкhdfsДДНЈФПТМ,ЪЙгУhdfsгяЗЈhdfs dfs -mkdir -p /test/input#ЩЯДЋlinuxЮФМўЕНhdfshdfs dfs -put /root/text.txt /test/input -- -putВЮЪ§ЪЧЩЯДЋ#ЩОГ§БОЕиДДНЈЕФВтЪдЮФМў,ЪЙгУhdfsЯТдиУќСюЯТдиrm -rf text.txt#ЪЙгУhdfsЯТдиЮФМўhdfs dfs -get /test/input/text.txt -- -getВЮЪ§ЪЧЯТди

-
MapReduce ЗжВМЪНМЦЫуГѕЬхбщ
-
дкHDFSЮФМўЯЕЭГИљФПТМЯТУцДДНЈвЛИіwcinputЮФМўМа
[root@linux121 ~]# hdfs dfs -mkdir /wcinput
-
дк/root/ФПТМЯТДДНЈвЛИіwc.txtЮФМў(БОЕиЮФМўЯЕЭГ)
[root@linux121 ~]# cd /root/[root@linux121 ~]# touch wc.txt -
БрМwc.txtЮФМў
[root@linux121 ~]# vi wc.txt -
дкЮФМўжаЪфШыШчЯТФкШн
hadoop mapreduce yarnhdfs hadoop mapreducemapreduce yarn szxszxszx -
БЃДцЭЫГі
:wq! -
ЩЯДЋwc.txtЕНHdfsФПТМ/wcinputЯТ
[root@linux121 ~]# hdfs dfs -put /root/wc.txt /wcinput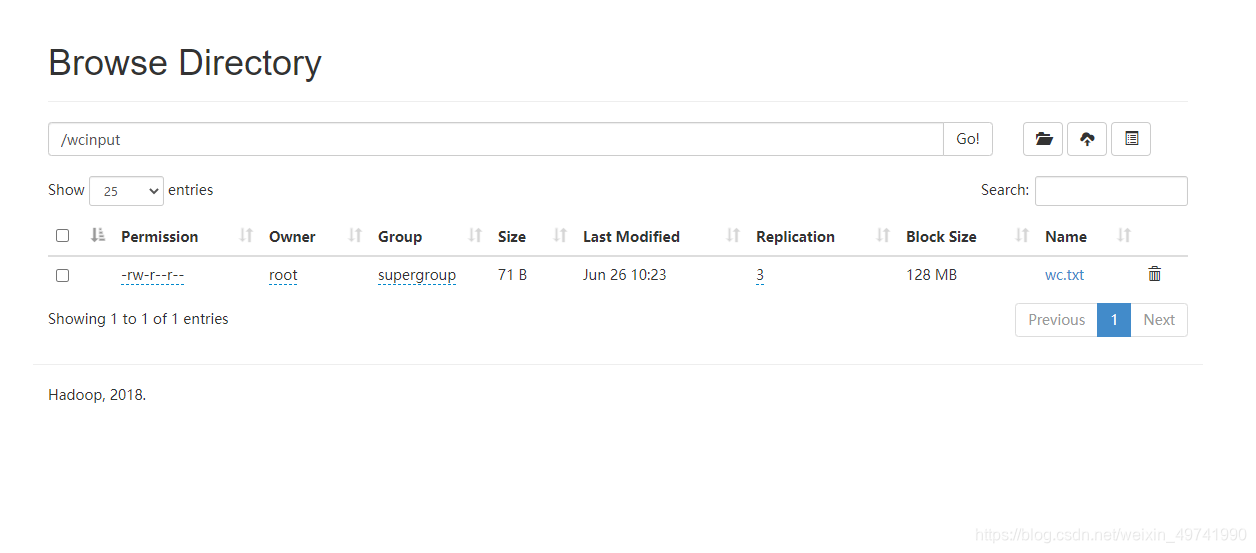
-
ЛиЕНHadoopФПТМ/opt/szx/servers/hadoop-2.9.2
-
жДааГЬађ
#УќСюНтЮі:hadoop jar /hadoopздДјЕФдЫааjarАќТЗОЖ,РрЫЦгкJava /дЫЫуаЮЪН,ПЩвдздМКАйЖШ /ДЫФПТМЮЊздМКЯывЊМЦЫуЪ§ОнДцдкФПТМ,БиаывбОДцдк /ДЫФПТМЮЊНсЙћЪфГіФПТМ,БиаыдкдЫааЧАВЛДцдкhadoop jar /opt/szx/servers/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput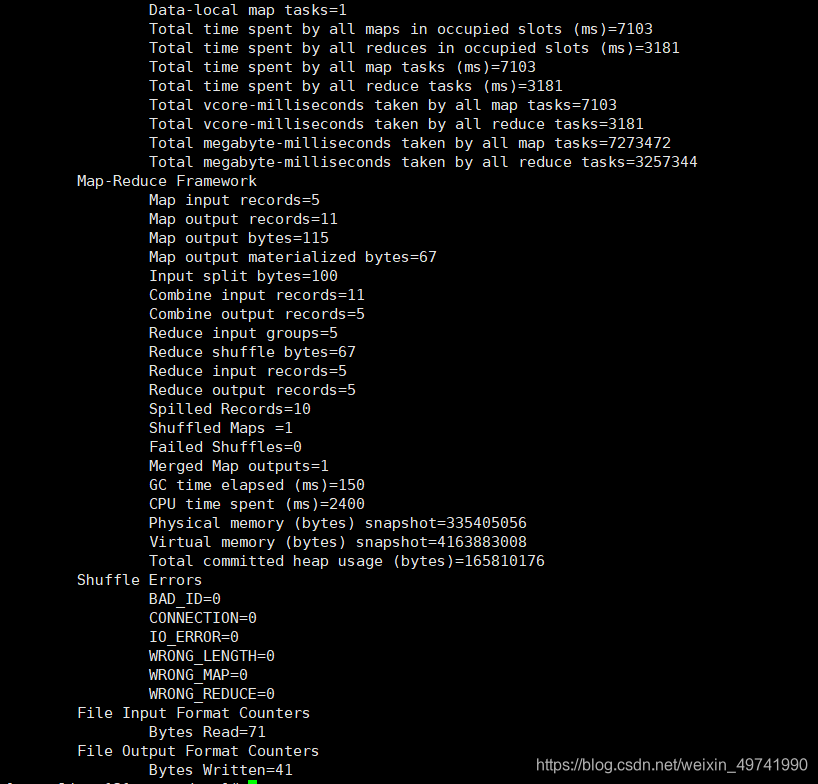
-
ВщПДНсЙћ
[root@linux121 mapreduce]# hdfs dfs -cat /wcoutput/part-r-00000hadoop 2hdfs 1mapreduce 3szx 3yarn 2
-
ХфжУРњЪЗЗўЮёЦї
дкYarnжадЫааЕФШЮЮёВњЩњЕФШежОЪ§ОнВЛФмВщПД,ЮЊСЫВщПДГЬађЕФРњЪЗдЫааЧщПі,ашвЊХфжУвЛЯТРњЪЗШежОЗўЮёЦїЁЃОпЬхХфжУВНжшШчЯТ:
-
ХфжУmapred-site.xml
#НјШыХфжУФПТМcd /opt/szx/servers/hadoop-2.9.2/etc/hadoop/[root@linux121 hadoop]# vi mapred-site.xml<!-- РњЪЗЗўЮёЦїЖЫЕижЗ --><property> <name>mapreduce.jobhistory.address</name> <value>linux121:10020</value></property><!-- РњЪЗЗўЮёЦїwebЖЫЕижЗ --><property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux121:19888</value></property>
-
ЗжЗЂmapred-site.xmlЕНЦфЫќНкЕу
rsync-script mapred-site.xml -
ЦєЖЏРњЪЗЗўЮёЦї
[root@linux121 hadoop-2.9.2]# sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /opt/szx/servers/hadoop-2.9.2/logs/mapred-root-historyserver-linux121.out -
ВщПДРњЪЗЗўЮёЦїЪЧЗёЦєЖЏ
[root@linux121 hadoop-2.9.2]# jps9361 DataNode9874 Jps9622 NodeManager9226 NameNode9805 JobHistoryServer -
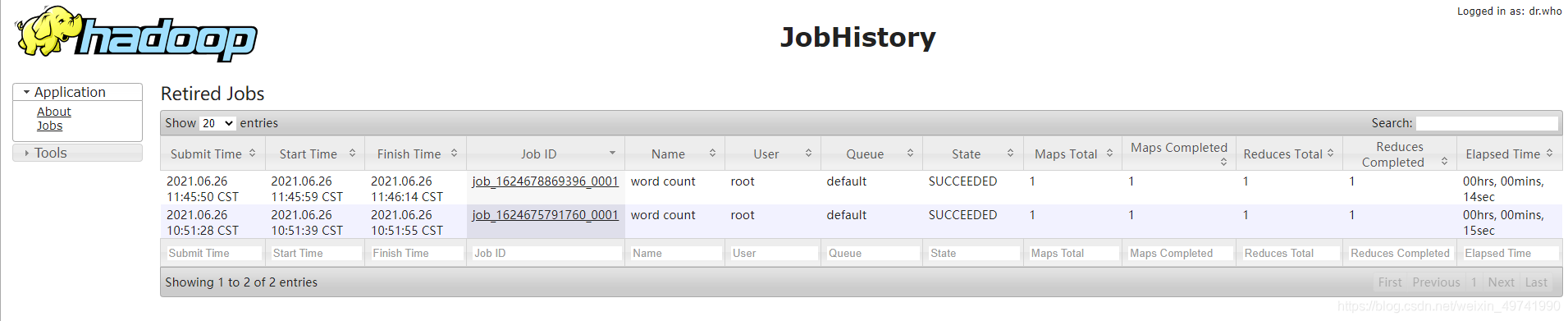
ВщПДJobHistory
http://linux121:19888/jobhistory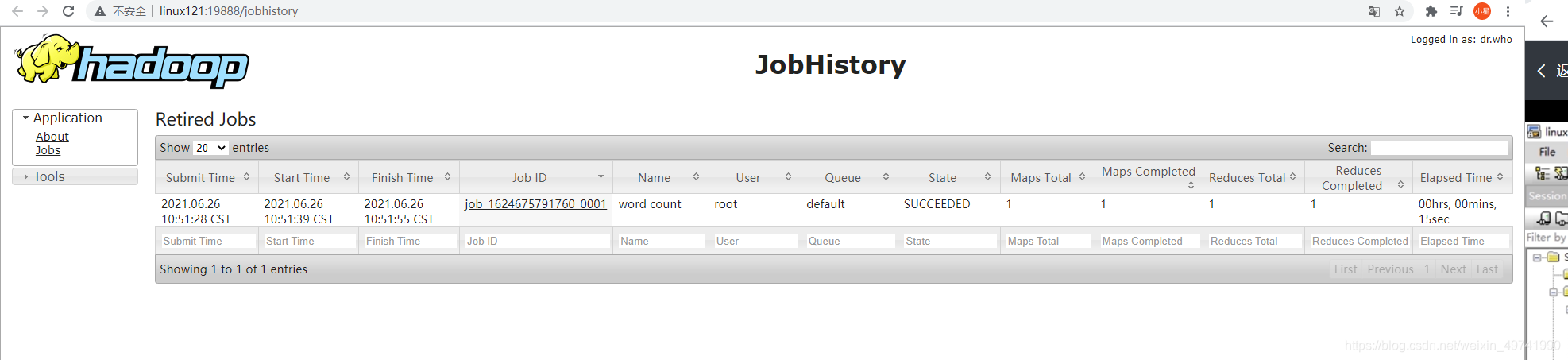
ХфжУШежОЕФОлМЏ
ШежООлМЏ:гІгУ(Job)дЫааЭъГЩвдКѓ,НЋгІгУдЫааШежОаХЯЂДгИїИіtaskЛузмЩЯДЋЕНHDFSЯЕЭГЩЯЁЃ
ШежООлМЏЙІФмКУДІ:ПЩвдЗНБуЕФВщПДЕНГЬађдЫааЯъЧщ,ЗНБуПЊЗЂЕїЪдЁЃ
зЂвт:ПЊЦєШежООлМЏЙІФм,ашвЊжиаТЦєЖЏNodeManager ЁЂResourceManagerКЭHistoryManagerЁЃ
ПЊЦєШежООлМЏЙІФмОпЬхВНжшШчЯТ:
-
ХфжУyarn-site.xml
#НјШыХфжУФПТМcd /opt/szx/servers/hadoop-2.9.2/etc/hadoop/[root@linux121 hadoop]# vi yarn-site.xml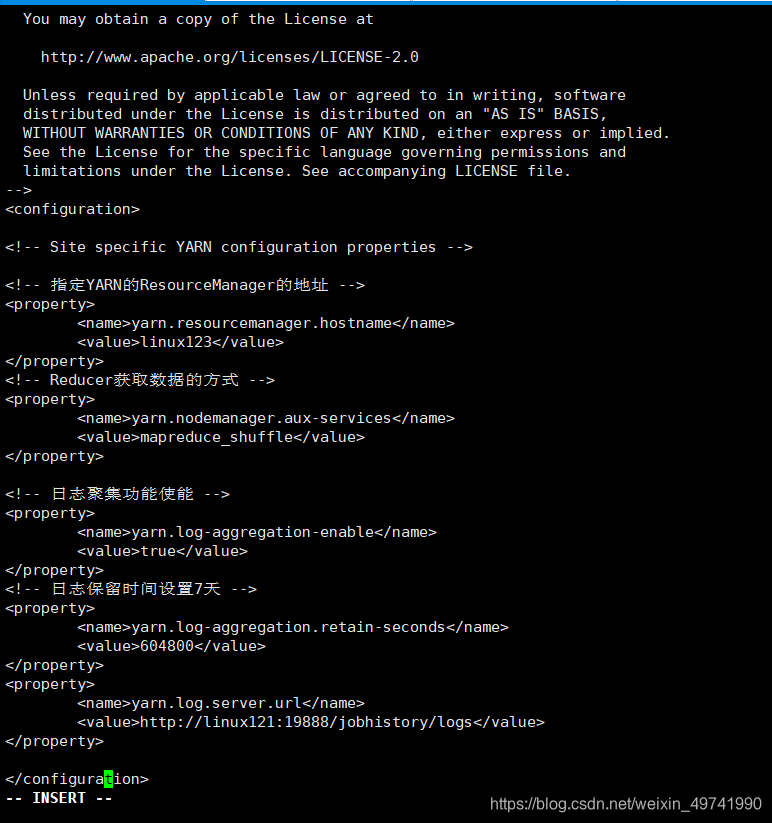
-
ЗжЗЂyarn-site.xmlЕНМЏШКЦфЫќНкЕу
rsync-script yarn-site.xml -
ЙиБеNodeManager ЁЂResourceManagerКЭHistoryManager
жБНгЪЙгУШКЙиМДПЩ(зЂвтЯргІЗўЮёЦїНјаа) -
ЦєЖЏNodeManager ЁЂResourceManagerКЭHistoryManager
жБНгЪЙгУШКЦ№МДПЩ(зЂвтЯргІЗўЮёЦїНјаа) -
ЩОГ§HDFSЩЯвбОДцдкЕФЪфГіЮФМў
hdfs dfs -rm -R /wcoutput -
жДааWordCountГЬађ
hadoop jar /opt/szx/servers/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput -
ВщПДШежО,ШчЭМЫљЪО
http://linux121:19888/jobhistory