环境准备
1.打开IDEA新建一个maven项目
2.增加 Scala 插件
Spark 由 Scala 语言开发的,开发前请保证 IDEA 开发工具中含有 Scala 开发插件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nG8iJkqt-1626079796853)(spark快速上手.assets/image-20210123152434018.png)]
3.下载scala
由于需要scala进行编写,所以要安装scala
https://www.scala-lang.org/download/
下载后安装并配置好环境变量
在IDEA项目里面导scala的包,以建立scala类,然后导包
确保有[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mgFduYCm-1626079796856)(spark快速上手.assets/image-20210123152717581.png)]
找到scala后配置scala安装的目录即可。
新建模块,并在此模块加入scala支持
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ZrGM36V-1626079796857)(spark快速上手.assets/image-20210123152636181.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ECWOTile-1626079796859)(spark快速上手.assets/image-20210123152816979.png)]
加入后,我们就可以新建scala程序了
4.增加maven依赖
加入spark的核心依赖
程序要有spark相关的包才可以写,所以要为项目导入相关的包这里在
在pom.xml里面加入依赖并导入
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
spark相关的一些依赖,根据需要添加
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
</dependencies>
添加日志信息,减少信息的打印
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项
目的 resources 目录中创建log4j.properties 文件,并添加日志配置信息
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
WordCount练习
方法一
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RffXPORu-1626079796863)(spark快速上手.assets/image-20210224130125919.png)]
自建包,新建SparkWordCount类(object),在项目目录创建datas文件夹用于存放数据
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
// 1.建立和spark框架的连接
//创建配置对象
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
//创建上下文对象
val sc = new SparkContext(conf)
sc.textFile("datas")
// 2.写操作代码
// 2.1读取文件获得一行一行的数据
val lines: RDD[String] = sc.textFile("datas")
// 2.2将一行行的数据进行拆分,形成一个个单词 // "hello world" => hello, world, hello, world
//扁平化操作:将整体拆分为个体并分成心的集合
val words: RDD[String] = lines.flatMap(_.split(" "))
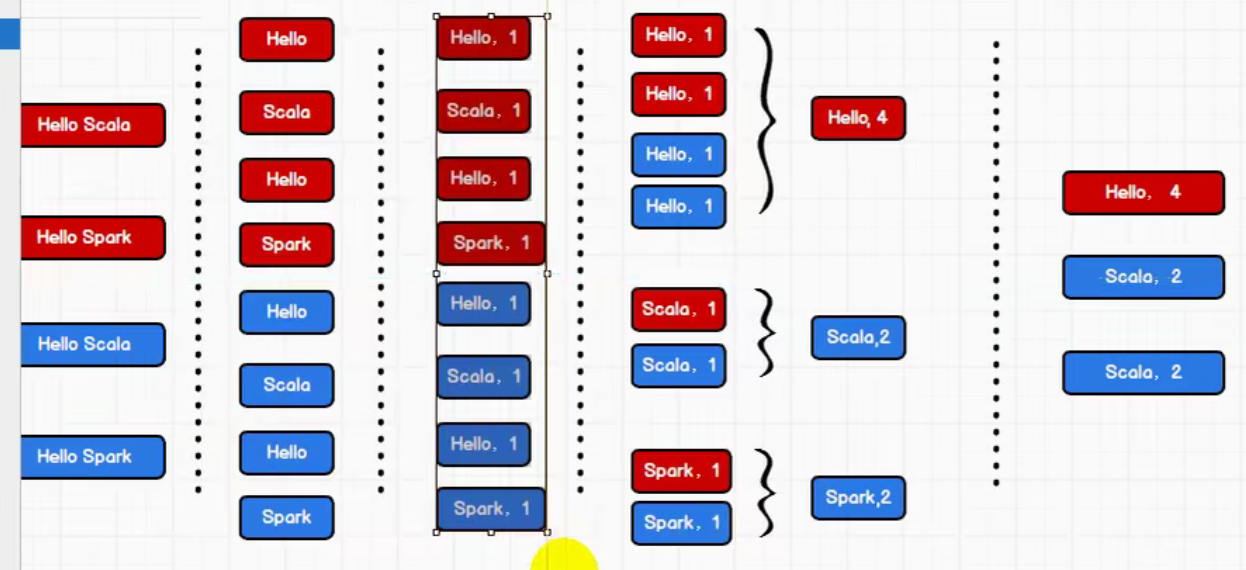
// 2.3将一个个单词进行分组,便于统计 // (hello, hello, hello), (world, world)
val wordgroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
// 2.4将分组后的数据进行统计 // (hello, hello, hello), (world, world)
// (hello, 3), (world, 2)
val word_count: RDD[(String, Int)] = wordgroup.map {
case (word, list) => {
(word, list.size)
}
}
// 2.5打印结果
val result: Array[(String, Int)] = word_count.collect()
result.foreach(println)
// 3.关闭连接
sc.stop()
}
}
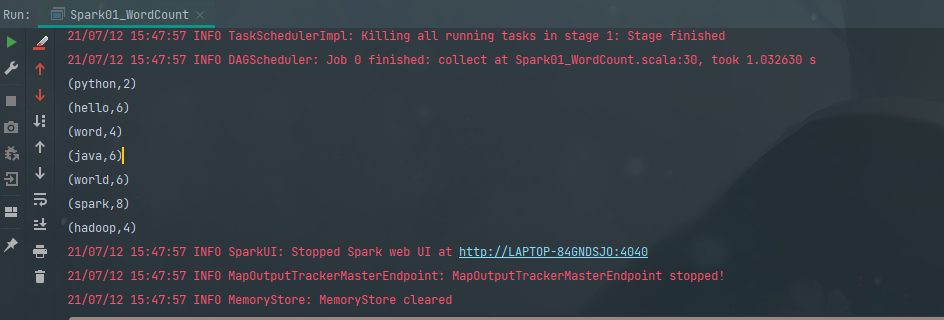
方法二
第一种的词组结果是通过直接分组,没有对分组的数据进行聚合的操作,第二种方法先得到数量后在聚合
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// 1.建立和spark框架的连接
//创建配置对象
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
//创建上下文对象
val sc = new SparkContext(conf)
sc.textFile("datas")
// 2.写操作代码
// 2.1读取文件获得一行一行的数据
val lines: RDD[String] = sc.textFile("datas")
// 2.2将一行行的数据进行拆分,形成一个个单词 // "hello world" => hello, world, hello, world
//扁平化操作:将整体拆分为个体
val words: RDD[String] = lines.flatMap(_.split(" "))
// 将分割后的单词进行格式化,hello -> (hello,1)
val word_one: RDD[(String, Int)] = words.map(word => (word, 1))
// 将相同单词分为一组
val word_group: RDD[(String, Iterable[(String, Int)])] = word_one.groupBy(t => t._1)
// 将每一组相同的单词进行模式匹配
val word_count = word_group.map{
case (word,count) =>{
// 对根据单词分组后的组进行累加操作
count.reduce(
(before,after) => {
(before._1,before._2+after._2)
}
)
}
}
// 打印结果
val result: Array[(String, Int)] = word_count.collect()
result.foreach(println)
// 3.关闭连接
sc.stop()
}
}
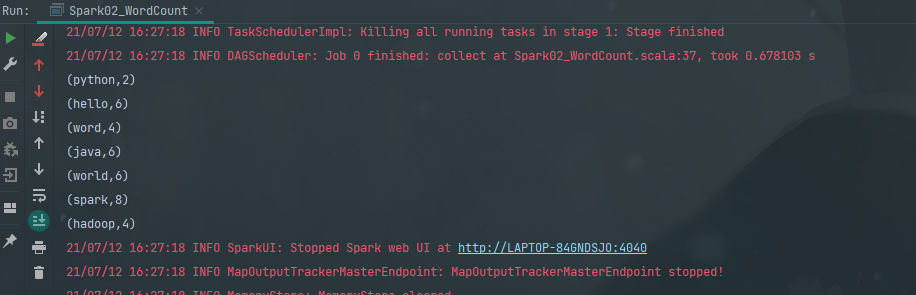
结果相同
方法三
spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现,reduceByKey
package wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// 1.建立和spark框架的连接
//创建配置对象
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
//创建上下文对象
val sc = new SparkContext(conf)
sc.textFile("datas")
// 2.写操作代码
// 2.1读取文件获得一行一行的数据
val lines: RDD[String] = sc.textFile("datas")
// 2.2将一行行的数据进行拆分,形成一个个单词 // "hello world" => hello, world, hello, world
//扁平化操作:将整体拆分为个体
val words: RDD[String] = lines.flatMap(_.split(" "))
// 将分割后的单词进行格式化,hello -> (hello,1)
val word_one: RDD[(String, Int)] = words.map(word => (word, 1))
// 将转换后的数据进行分组聚合
// 相同key可以对value进行聚合操作
// (word, 1) => (word, sum)
val word_count: RDD[(String, Int)] = word_one.reduceByKey(_+_)
// 打印结果
val result: Array[(String, Int)] = word_count.collect()
result.foreach(println)
// 3.关闭连接
sc.stop()
}
}