Python操作kafka笔记
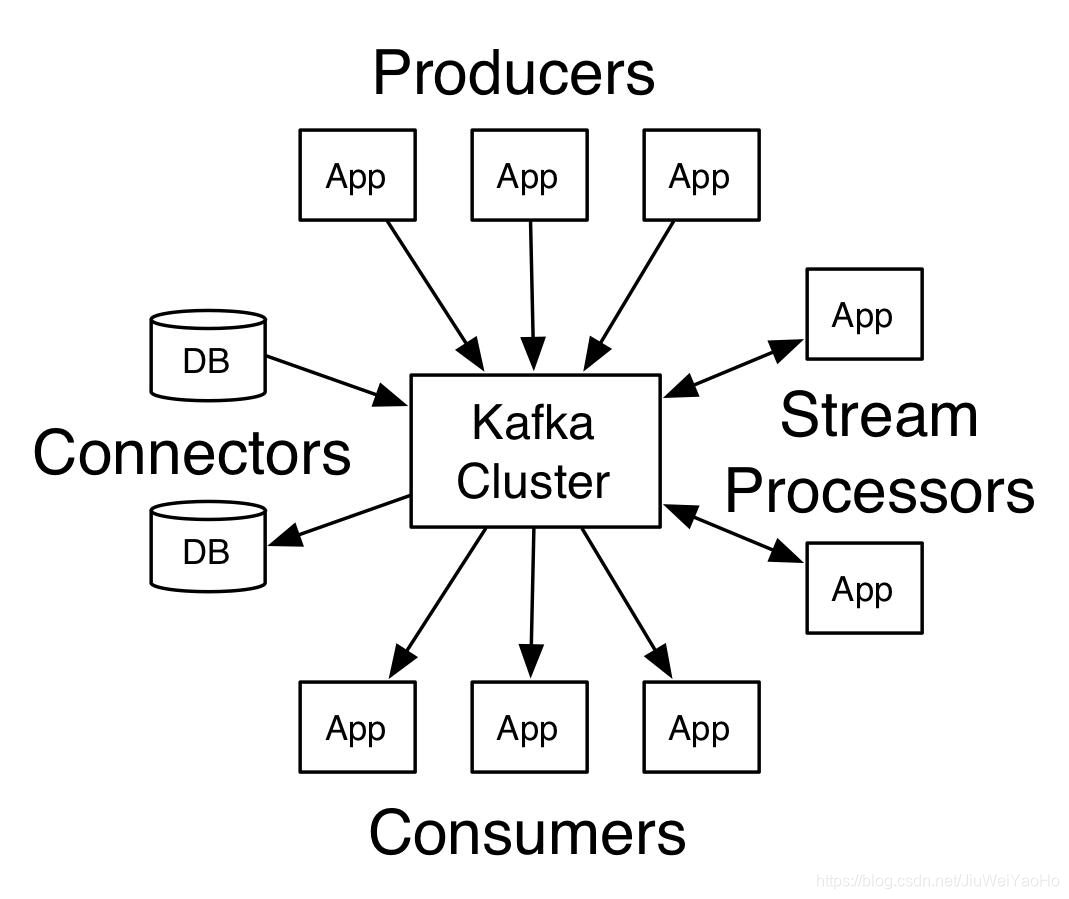
kafka模型
Producers 生产者
Consumers 消费者
Broker:kafka 集群 服务器用于存储消息
topic 主题 相当于库 生产者消费者链接不同的主题存放不同且不相干的数据
生产者与消费者规定那个主题(topic) 然后进行数据交互
topic
既然说topic(主题)类似与某个库,但是每个topic 又可拆成不同的partition(分区) 每个分区则由一条条消息组成,每条消息都会有下标(索引)
既然kafka为分布式存储, 那么好几个partition组成一个topic 而每台服务器则可以使用不同的partition
offset
偏移量 当一条消息进入的时候偏移量为0(索引),第二条偏移量为1(索引)
每个分区(pattition) 偏移量则都为零开始
每个消费者的offset都不同 互不干扰
消息
当生产者 生产一条数据的时候发送到topic中那么会放到那条partition中?
根据分配策略决定 一般就是哈希取模
消息默认保存七天
可自行配置多久清除
消费者组
每个消费者(consumer)有自己对应的偏移量(offset), 每个消费者也有对应的消费组group
各个消费者(consumer)消费不同的partition 一个消息在组内只消费一次
一个消费组内 比如开启两个线程读取两份partition 不能互相读取 所以一个消息只能在组内读一次
如何保证数据读取有序
将topic设置成一个分区
分业务 如果不关心读取顺序,则不需要设置一个分区
pykakfa
按照官方的demo
消费者
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
# consume earliest available messages, don't commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
consumer2 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
生产者
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
log.exception()
pass
# Successful result returns assigned partition and offset
print (record_metadata.topic)
print (record_metadata.partition)
print (record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp):
log.error('I am an errback', exc_info=excp)
# handle exception
# produce asynchronously with callbacks
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)
官方网址
自己封装
正在封装封装完成之后公报。。。。