1.mapreduce的简单介绍
mapreduce是分而治之的思想,其名字来源于函数式编程里的map、reduce两个方程
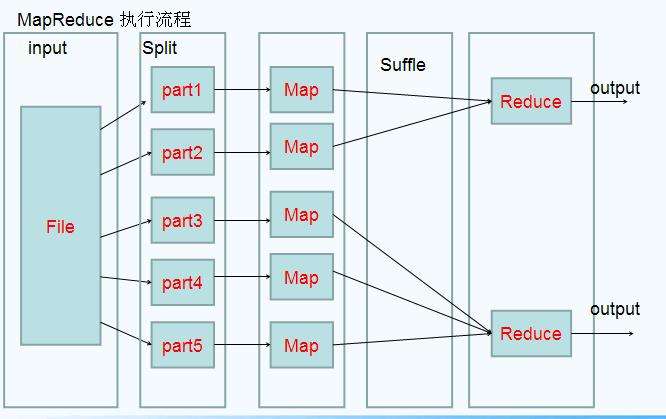
1.1mapreduce的编程规范
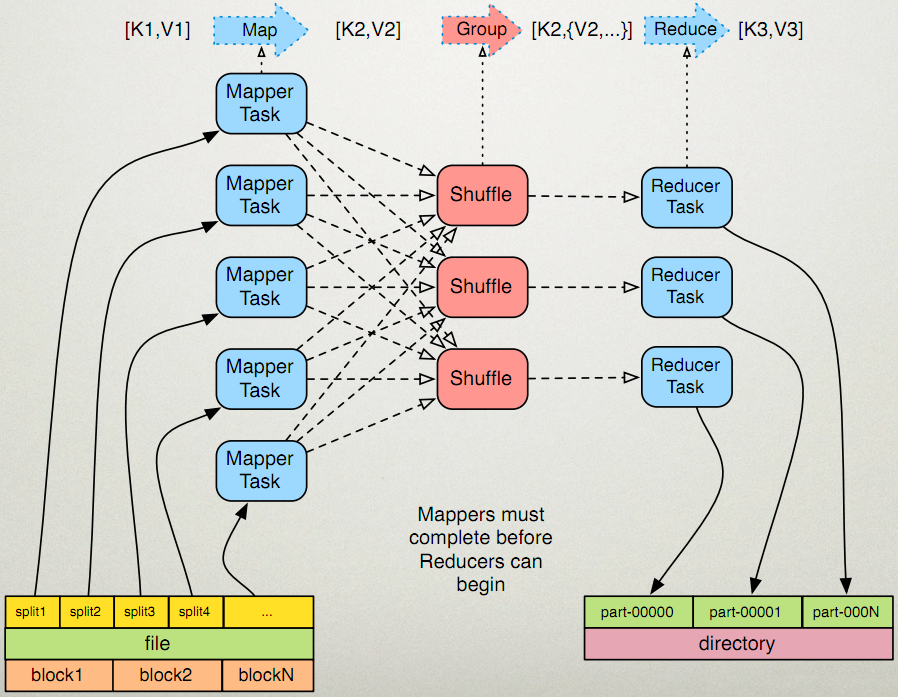
MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
-
map两个步骤
第一步:设置inputFormat类,将我们的数据切分成key,value对,输入到第二步
第二步:自定义map逻辑,处理我们第一步的输入数据,然后转换成新的key,value对进行输出
-
shuffle四个步骤
第三步:对输出的key,value对进行分区
第四步:对不同分区的数据按照相同的key进行排序
第五步:对分组后的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
------------------------------------------map阶段、reduce阶段的分割线-------------------------------------------------
第六步:对排序后的额数据进行分组,分组的过程中,将相同key的value放到一个集合当中
-
reduce两个步骤
第七步:对多个map的任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value对进行处理,转换成新的key,value对进行输出
第八步:设置outputformat将输出的key,value对数据进行保存到文件中
1.2 wordCount示例
- mapper
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
for (String word : split) {
context.write(new Text(word),new LongWritable(1));
}
}
}
- reducer
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
context.write(key,new LongWritable(count));
}
}
- main
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), JobMain.class.getSimpleName());
//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数
job.setJarByClass(JobMain.class);
//第一步:读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://192.168.75.103:8020/wordcount"));
//第二步:设置我们的mapper类
job.setMapperClass(WordCountMapper.class);
//设置我们map阶段完成之后的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三步,第四步,第五步,第六步,省略
//第七步:设置我们的reduce类
job.setReducerClass(WordCountReducer.class);
//设置我们reduce阶段完成之后的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:设置输出类以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.52.100:8020/wordcount_out"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
/**
* 程序main函数的入口类
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Tool tool = new JobMain();
int run = ToolRunner.run(configuration, tool, args);
System.exit(run);
}
}
mapreduce的运行模式主要有两种:
- 本地模式
- 集群运行模式
1.3 MapTask的运行机制
详细步骤:
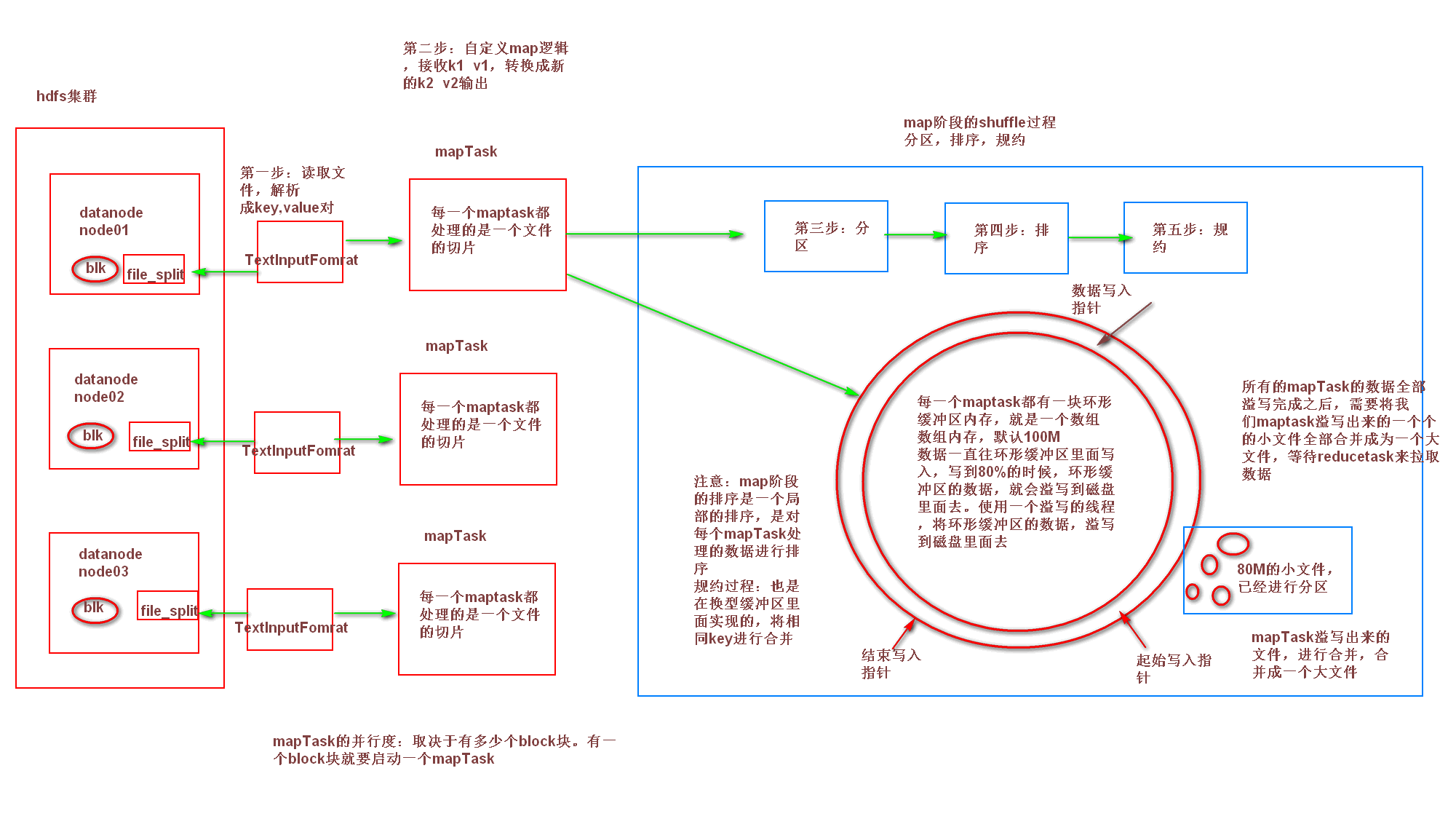
1、首先,读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,有多少个split就对应启动多少个MapTask。split与block的对应关系默认是一对一。
2、将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以/n作为分隔符,读取一行数据,返回<key,value>。Key表示每行首字符偏移值,value表示这一行文本内容。
3、读取split返回<key,value>,进入用户自己继承的Mapper类中,执行用户重写的map函数。RecordReader读取一行这里调用一次。
4、map逻辑完之后,将map的每条结果通过context.write进行collect数据收集。在collect中,会先对其进行分区处理,默认使用HashPartitioner。
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
5、接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
缓冲区是有大小限制,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Maptask的输出结果还可以往剩下的20MB内存中写,互不影响。
6、当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
如果job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。
那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
7、合并溢写文件:每次溢写会在磁盘上生成一个临时文件(写之前判断是否有combiner),如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量。至此map整个阶段结束。
| 项目 | 配置属性 | 默认值 |
|---|---|---|
| 环型缓冲区的内存值大小 | mapreduce.task.io.sort.mb | 100 |
| 溢写百分比 | mapreduce.map.sort.spill.percent | 0.80 |
| 溢写数据目录 | mapreduce.cluster.local.dir | ${hadoop.tmp.dir}/mapred/local |
| 一次最多合并多少个溢写文件 | mapreduce.task.io.sort.factor | 10 |
这些配置是mapred-site.xml
1.4 ReduceTask的运行机制
详细步骤:
1、Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
2、Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。
merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。
默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。
3、合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
4、对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
1.5 shuffle过程
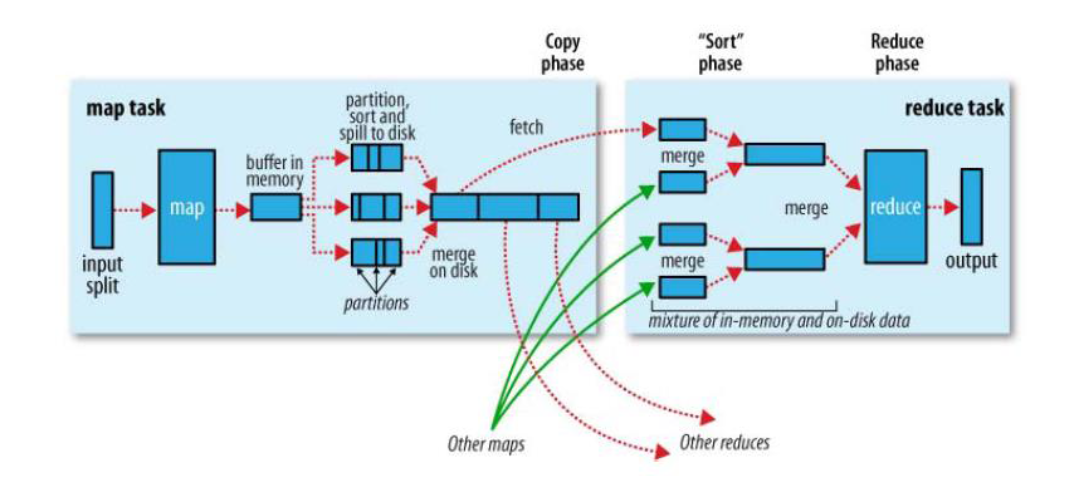
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
- Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
- Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
- Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
- Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
2.mapreduce的增强
2.1 自定义分区
注意:如果自定义分区产生多个reduce的话,则只能集群运行,不能本地运行
/**
* 这里的输入类型与我们map阶段的输出类型相同
*/
public class MyPartitioner extends Partitioner<Text,NullWritable>{
/**
* 返回值表示我们的数据要去到哪个分区
* 返回值只是一个分区的标记,标记所有相同的数据去到指定的分区
*/
@Override
public int getPartition(Text text, NullWritable nullWritable, int i) {
String result = text.toString().split("/t")[5];
System.out.println(result);
if (Integer.parseInt(result) > 15){
return 1;
}else{
return 0;
}
}
}
自定义分区必须继承partitioner类,并重写getPartition方法,其中参数i是我们设定的reduce个数
注意这里的分区数不能大于我们设定的reduce的个数 :partition < reduce
//主类中需要加入的代码
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(2);
2.2 自定义排序及其序列化(重重点)
自定义排序的实现主要是:key2类型的bean对象实现排序功能。由于bean对象我们要进行网络传输,所以我们都要对其进行序列化。(注意:分组是根据key的toString进行的,所以要注意toString的实现)
package com.yuepengfei.demo2.sort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Author day_ue
* @Date 2019/1/10 10:51
* @Description TODO
**/
public class SortBean implements WritableComparable<SortBean>{
private String first;
private Integer second;
public String getFirst() {
return first;
}
@Override
public String toString() {
return first+"/t"+second;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
public SortBean() {
}
public SortBean(String first, int second) {
this.first = first;
this.second = second;
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(first);
out.writeInt(second);
}
//反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.first = in.readUTF();
this.second = in.readInt();
}
//实现比较功能
@Override
public int compareTo(SortBean o) {
int i = this.first.compareTo(o.first);
if(i==0){
i = this.second.compareTo(o.second);
}
return i;
}
}
bean类要继承 WritableComparable类。
1、MapReduce中排序发生在哪几个阶段??这些排序是否可以避免,为什么??
答:一个MapReduce作业由Map阶段和Reduce阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce框架本质就是一个Distributed Sort。在Map阶段,Map Task会在本地磁盘输出一个按照key排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在Reduce阶段,每个Reduce Task会对收到的数据排序,这样,数据便按照Key分成了若干组,之后以组为单位交给reduce()处理。很多人的误解在Map阶段,如果不使用Combiner便不会排序,这是错误的,不管你用不用Combiner,Map Task均会对产生的数据排序(如果没有Reduce Task,则不会排序, 实际上Map阶段的排序就是为了减轻Reduce端排序负载)。由于这些排序是MapReduce自动完成的,用户无法控制,因此,在hadoop 1.x中无法避免,也不可以关闭,但hadoop2.x是可以关闭的。
2、编写MapReduce作业时,如何做到在Reduce阶段,先对Key排序,再对Value排序??
答:该问题通常称为”二次排序“,最常用的方法是将Value放到Key中,实现一个组合Key,然后自定义Key排序规则(为Key实现一个WritableComparable)
3、如何使用MapReduce实现两个表join?
答:可以考虑一下几种情况:(1)一个表大,一个表小(可放到内存中);(2)两个表都是大表
第一种情况比较简单,只需将小表放到DistributedCache中即可;第二种情况常用的方法有:map-side join(要求输入数据有序,通常用户Hbase中的数据表连接),reduce-side join,semi join(半连接),具体资料可网上查询
- 全排序(未完成)
(1)方法一
每个map任务对自己的输入数据进行排序,但是无法做到全局排序,需要将数据传递到reduce,然后通过reduce进行一次总的排序,但是这样做的要求是只能有一个reduce任务来完成。
并行程度不高,无法发挥分布式计算的特点,不可取。
(2)方法二
使用多个partition对map的结果进行分区,且分区后的结果是有区间的,将多个分区结果拼接起来,就是一个连续的全局排序文件。
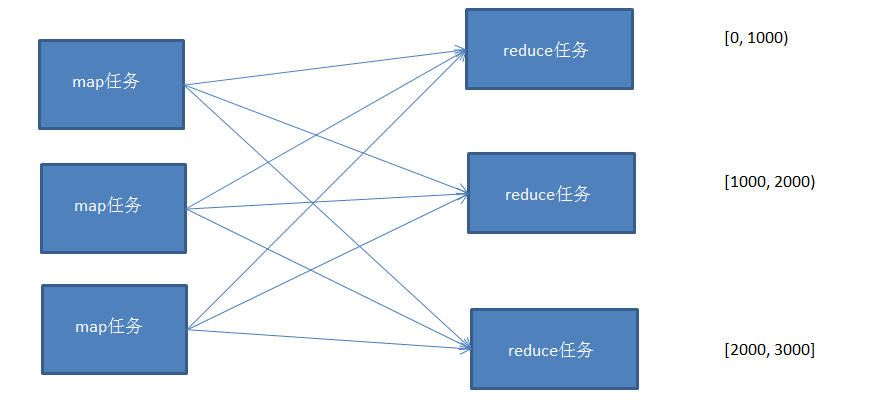
Hadoop自带的Partitioner的实现有两种,一种为HashPartitioner, 默认的分区方式,计算公式 hash(key)%reducernum,另一种为TotalOrderPartitioner, 为排序作业创建分区,分区中数据的范围需要通过分区文件来指定。
分区文件可以人为创建,如采用等距区间,如果数据分布不均匀导致作业完成时间受限于个别reduce任务完成时间的影响。
也可以通过抽样器,先对数据进行抽样,根据数据分布生成分区文件,避免数据倾斜。
这里实现一个通过随机抽样来生成分区文件,然后对数据进行全排序,根据分区文件的范围分配到不同的reducer中。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
import java.io.IOException;
/**
* Created by Edward on 2016/10/4.
*/
public class TotalSort {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//access hdfs's user
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
conf.set("mapred.jar", "D://MyDemo//MapReduce//Sort//out//artifacts//TotalSort//TotalSort.jar");
FileSystem fs = FileSystem.get(conf);
/*RandomSampler 参数说明
* @param freq Probability with which a key will be chosen.
* @param numSamples Total number of samples to obtain from all selected splits.
* @param maxSplitsSampled The maximum number of splits to examine.
*/
InputSampler.RandomSampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.1, 10, 10);
//设置分区文件, TotalOrderPartitioner必须指定分区文件
Path partitionFile = new Path( "_partitions");
TotalOrderPartitioner.setPartitionFile(conf, partitionFile);
Job job = Job.getInstance(conf);
job.setJarByClass(TotalSort.class);
job.setInputFormatClass(KeyValueTextInputFormat.class); //数据文件默认以/t分割
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
job.setNumReduceTasks(4); //设置reduce任务个数,分区文件以reduce个数为基准,拆分成n段
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(TotalOrderPartitioner.class);
FileInputFormat.addInputPath(job, new Path("/test/sort"));
Path path = new Path("/test/wc/output");
if(fs.exists(path))//如果目录存在,则删除目录
{
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job, path);
//将随机抽样数据写入分区文件
InputSampler.writePartitionFile(job, sampler);
boolean b = job.waitForCompletion(true);
if(b)
{
System.out.println("OK");
}
}
}
2.3 规约combiner
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能,是 MapReduce 的一种优化手段之一。
- combiner是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是Reducer
- combiner 和reducer 的区别在于运行的位置
- Combiner 是在每一个maptask 所在的节点运行
- Reducer 是接收全局所有Mapper 的输出结果
具体实现步骤:
- 自定义一个 combiner 继承 Reducer,重写 reduce 方法
- 在 job 中设置: job.setCombinerClass(CustomCombiner.class)
2.4 文件压缩
hadoop支持的压缩算法:
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 否 |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | .snappy | 否 |
各种压缩算法对应使用的java类
| 压缩格式 | 对应使用的java类 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DeFaultCodec |
| gzip | org.apache.hadoop.io.compress.GZipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
常见的压缩速率比较
| 压缩算法 | 原始文件大小 | 压缩后的文件大小 | 压缩速度 | 解压缩速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/S | 74.6MB/s |
2.4.1 代码中设定压缩
这些设定都是在主函数中进行
- map阶段的压缩
Configuration configuration = new Configuration();
configuration.set("mapreduce.map.output.compress","true");
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
- reduce阶段压缩
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
2.4.2 配置文件中设定压缩
- map输出数据压缩
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
- reduce输出数据压缩
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
2.5 自定义分组
注意:分区和分组的区别,分区是确定数据发往哪个reducetask,分组是确定哪些key是一组(即那些key被认为是相同的),相同的key合并,value形成一个集合
package com.yuepengfei.demo12.topN;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @Author day_ue
* @Date 2019/1/12 20:25
* @Description TODO
**/
public class TopNGroupingComparator extends WritableComparator {
public TopNGroupingComparator() {
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean a1 = (OrderBean) a;
OrderBean b1 = (OrderBean) b;
return a1.getOrderID().compareTo(b1.getOrderID());
}
}
注意:这里继承的是WritableComparator,而实现 排序序列化的bean继承的是WritableComparable。
注意:分组是在reduce阶段完成的,数据是经过序列化的,我们要在构造方法中加上bean的类型,以便于我们反序列化。
主类中要加上:
job.setGroupingComparatorClass(TopNGroupingComparator.class);
2.6 计数器
mapreduce中本身自带计数器。我们也可以实现自己的计数器
- 方式一:通过context上下文对象可以获取我们的计数器,进行记录
public class SortMapper extends Mapper<LongWritable,Text,PairWritable,IntWritable> {
private PairWritable mapOutKey = new PairWritable();
private IntWritable mapOutValue = new IntWritable();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//自定义我们的计数器,这里实现了统计map数据数据的条数
Counter counter = context.getCounter("MR_COUNT", "MapRecordCounter");
counter.increment(1L);
String lineValue = value.toString();
String[] strs = lineValue.split("/t");
//设置组合key和value ==> <(key,value),value>
mapOutKey.set(strs[0], Integer.valueOf(strs[1]));
mapOutValue.set(Integer.valueOf(strs[1]));
context.write(mapOutKey, mapOutValue);
}
}
- 方式二:通过enum枚举类型来定义计数器
public class SortReducer extends Reducer<PairWritable,IntWritable,Text,IntWritable> {
private Text outPutKey = new Text();
@Override
public void reduce(PairWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
context.getCounter(Counter.REDUCE_INPUT_RECORDS).increment(1L);
//迭代输出
for(IntWritable value : values) {
context.getCounter(Counter.REDUCE_INPUT_VAL_NUMS).increment(1L);
outPutKey.set(key.getFirst());
context.write(outPutKey, value);
}
}
public static enum Counter{
REDUCE_INPUT_RECORDS, REDUCE_INPUT_VAL_NUMS,
}
}
2.7 自定义InputFormat
无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案:
- 在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS
- 在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并
- 在mapreduce处理时,可采用combineInputFormat提高效率
方式一:就是把一个文件夹下的文件通过LocalFileSystem读取到 FSDataInputStream中,通过流的方式写到一个文件。这种方式只适合用在同类文件的合并,并且文件合并后不能再分开
方式二:通过自定义InputFormat实现文件的合并。其核心机制:
- 自定义一个InputFormat
- 改写RecordReader,实现一次读取一个完整文件封装为KV
- 在输出时使用SequenceFileOutPutFormat输出合并文件
其重点是实现两个类:
- 自定义InputFormat继承FileInputFormat
package com.yuepengfei.demo10.mergefile;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @Author day_ue
* @Date 2019/1/12 15:01
* @Description TODO
**/
public class MyInputFormat extends FileInputFormat<NullWritable,BytesWritable> {
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new MyRecorder();
}
//设定文件不可分割
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
}
- 自定义RecordReader继承RecordReader
package com.yuepengfei.demo10.mergefile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.ByteWritable;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @Author day_ue
* @Date 2019/1/12 15:02
* @Description TODO
**/
public class MyRecorder extends RecordReader {
private Configuration configuration;//用来生成filesystem
private FileSplit fileSplit;
private BytesWritable bytesWritable = new BytesWritable();
private boolean flag = false;
//初始化方法,程序启动我们调用一次,多是用来配置文件
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
this.configuration = taskAttemptContext.getConfiguration();
this.fileSplit = (FileSplit)inputSplit;
}
//读取数据的方法,如果返回true标识已经读取完成,返回false标识没有读取完成
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(!flag){
//获取流
FileSystem fileSystem = FileSystem.newInstance(configuration);
FSDataInputStream inputStream = fileSystem.open(fileSplit.getPath());
//定义一个字节数组来存放我们的文件件内容
byte[] bytes = new byte[(int) fileSplit.getLength()];
//将流里的内容读取到字节数组内
IOUtils.readFully(inputStream,bytes,0,bytes.length);
//将数组的内容写到byteswritable中
bytesWritable.set(bytes,0,bytes.length);
flag = true;
//关闭流
IOUtils.closeStream(inputStream);
fileSystem.close();
return true;
}
return false;
}
//返回当前读取的key
@Override
public Object getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
//返回我们读取的数据
@Override
public Object getCurrentValue() throws IOException, InterruptedException {
return bytesWritable;
}
//返回进度
@Override
public float getProgress() throws IOException, InterruptedException {
return flag?1.0f:0.0f;
}
@Override
public void close() throws IOException {
}
}
注意文件的最终输出类:
job.setOutputFormatClass(SequenceFileOutputFormat.class);
2.8 自定义OutputFormat
现在有一些订单的评论数据,需求,将订单的好评与差评进行区分开来,将最终的数据分开到不同的文件夹下面去,数据内容参见资料文件夹。
- 重写OutputFormat继承FileOutputFormat
package com.yuepengfei.demo11.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Progressable;
import java.io.IOException;
/**
* @Author day_ue
* @Date 2019/1/12 16:27
* @Description TODO
**/
public class MyOutputFormat extends FileOutputFormat<Text,NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSystem fileSystem = FileSystem.newInstance(configuration);
//注意这里的路径写到的最后一位是文件,所以要多写一位文件夹的路径,更蛋疼是这个new path并不会生成文件和文件夹
Path goodPath = new Path("file:///E://大数据课程//离线阶段第二天视频以及第三天资料//第三四五天课程资料//5、大数据离线第五天//自定义outputformat//good//good.txt");
Path badPath = new Path("file:///E://大数据课程//离线阶段第二天视频以及第三天资料//第三四五天课程资料//5、大数据离线第五天//自定义outputformat//bad//bad.txt");
//创建输出流
FSDataOutputStream goodStream = fileSystem.create(goodPath);
FSDataOutputStream badStream = fileSystem.create(badPath);
MyRecoredWriter myRecoredWriter = new MyRecoredWriter(goodStream, badStream);
return myRecoredWriter;
}
}
- 重写RecordWrite继承RecordWrite
package com.yuepengfei.demo11.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
/**
* @Author day_ue
* @Date 2019/1/12 16:28
* @Description TODO
**/
public class MyRecoredWriter extends RecordWriter<Text,NullWritable> {
private FSDataOutputStream goodStream;
private FSDataOutputStream badStream;
public MyRecoredWriter(FSDataOutputStream goodStream, FSDataOutputStream badStream) {
this.goodStream = goodStream;
this.badStream = badStream;
}
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
String[] split = text.toString().split("/t");
String s = split[9];
if(Integer.parseInt(s)<=1){
goodStream.write(text.toString().getBytes());
goodStream.write("/r/n".getBytes());
goodStream.flush();
}else {
badStream.write(text.toString().getBytes());
badStream.write("/r/n".getBytes());
badStream.flush();
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
goodStream.close();
badStream.close();
}
}
2.9 多job串联
一个稍复杂点的处理逻辑往往需要多个mapreduce程序串联处理,多job的串联可以借助mapreduce框架的JobControl实现
ControlledJob cJob1 = new ControlledJob(job1.getConfiguration());
ControlledJob cJob2 = new ControlledJob(job2.getConfiguration());
ControlledJob cJob3 = new ControlledJob(job3.getConfiguration());
cJob1.setJob(job1);
cJob2.setJob(job2);
cJob3.setJob(job3);
// 设置作业依赖关系
cJob2.addDependingJob(cJob1);
cJob3.addDependingJob(cJob2);
JobControl jobControl = new JobControl("RecommendationJob");
jobControl.addJob(cJob1);
jobControl.addJob(cJob2);
jobControl.addJob(cJob3);
// 新建一个线程来运行已加入JobControl中的作业,开始进程并等待结束
Thread jobControlThread = new Thread(jobControl);
jobControlThread.start();
while (!jobControl.allFinished()) {
Thread.sleep(500);
}
jobControl.stop();
return 0;
3. mapreduce的参数优化
3.1 资源相关参数
以下调整参数都在mapred-site.xml这个配置文件当中有
//以下参数是在用户自己的mr应用程序中配置就可以生效
- mapreduce.map.memory.mb: 一个Map Task可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。
- mapreduce.reduce.memory.mb: 一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。
- mapred.child.java.opts 配置每个map或者reduce使用的内存的大小,默认是200M
- mapreduce.map.cpu.vcores: 每个Map task可使用的最多cpucore数目, 默认值: 1
- mapreduce.reduce.cpu.vcores:每个Reduce task可使用的最多cpu core数目, 默认值: 1
//shuffle性能优化的关键参数,应在yarn启动之前就配置好
- mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m
- mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
//应该在yarn启动之前就配置在服务器的配置文件中才能生效。以下配置都在yarn-site.xml配置文件当中配置
- yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存
- yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存
- yarn.scheduler.minimum-allocation-vcores 1
- yarn.scheduler.maximum-allocation-vcores 32
- yarn.nodemanager.resource.memory-mb 8192
3.2 容错相关参数
- mapreduce.map.maxattempts: 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
- mapreduce.reduce.maxattempts: 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
- mapreduce.job.maxtaskfailures.per.tracker:当失败的Map Task失败比例超过该值为,整个作业则失败,默认值为0. 如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业仍认为成功。
- mapreduce.task.timeout: Task超时时间,默认值为600000毫秒,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡主,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒)。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after300 secsContainer killed by the ApplicationMaster.”。
3.3 效率和稳定性相关参数
- mapreduce.map.speculative: 是否为Map Task打开推测执行机制,默认为true,如果为true,如果Map执行时间比较长,那么集群就会推测这个Map已经卡住了,会重新启动同样的Map进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
- mapreduce.reduce.speculative: 是否为ReduceTask打开推测执行机制,默认为true,如果reduce执行时间比较长,那么集群就会推测这个reduce已经卡住了,会重新启动同样的reduce进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
- mapreduce.input.fileinputformat.split.minsize: FileInputFormat做切片时的最小切片大小,默认为0
- mapreduce.input.fileinputformat.split.maxsize: FileInputFormat做切片时的最大切片大小(已过时的配置,2.7.5当中直接把这个配置写死了,写成了Integer.maxValue的值),切片的默认大小就等于blocksize,即 134217728。
4. yarn资源调度
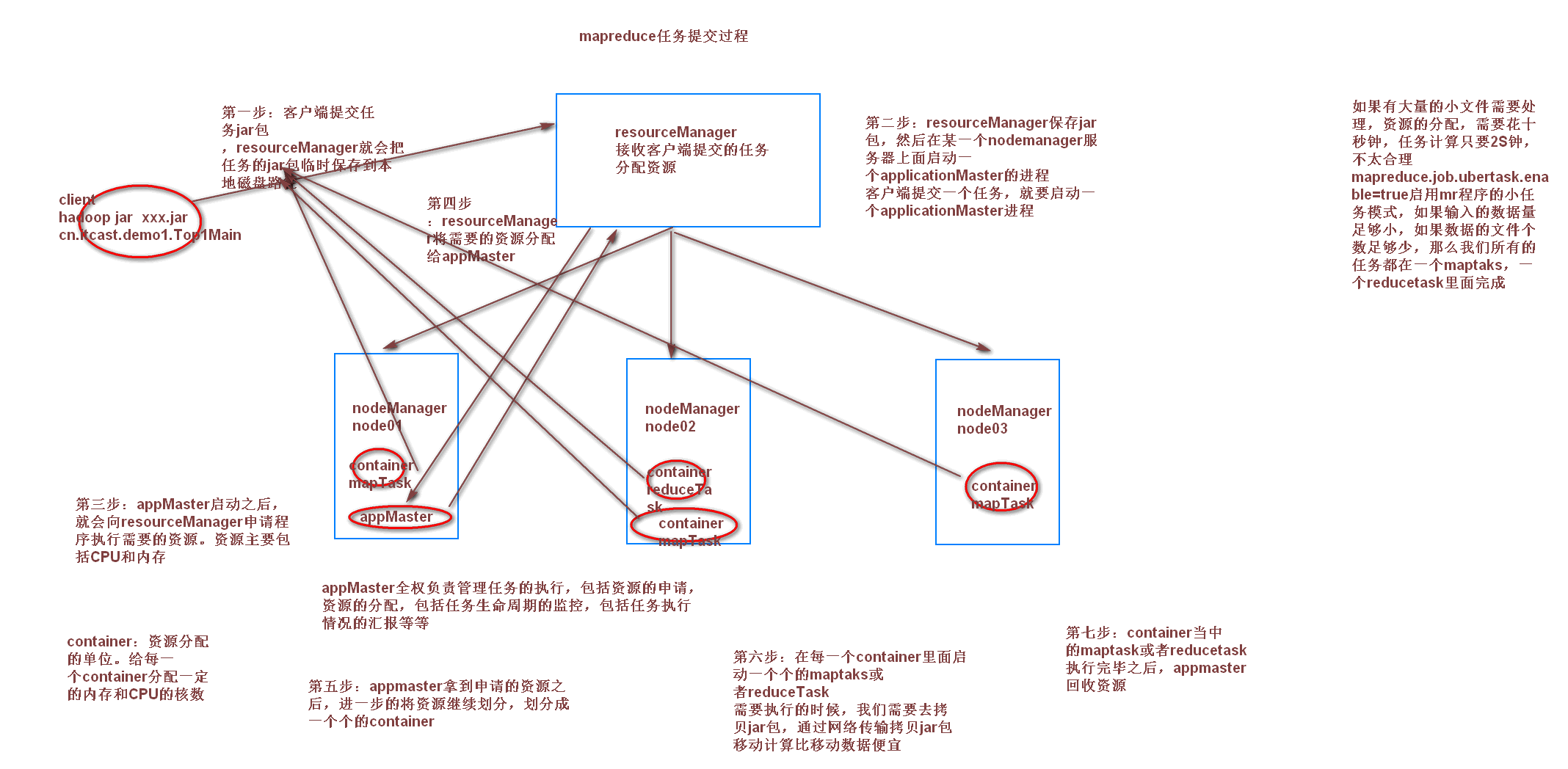
- ResourceManager:yarn集群的主节点,主要用于接收客户端提交的任务,并对资源进行分配
- NodeManager:yarn集群的从节点,主要用于任务的计算
- ApplicationMaster:当有新的任务提交到ResourceManager的时候,ResourceManager会在某个从节点nodeManager上面启动一个ApplicationMaster进程,负责这个任务执行的资源的分配,任务的生命周期的监控等
- Container:资源的分配单位,ApplicationMaster启动之后,与ResourceManager进行通信,向ResourceManager提出资源申请的请求,然后ResourceManager将资源分配给ApplicationMaster,这些资源的表示,就是一个个的container
- JobHistoryServer:这是yarn提供的一个查看已经完成的任务的历史日志记录的服务,我们可以启动jobHistoryServer来观察已经完成的任务的所有详细日志信息
- TimeLineServer:hadoop2.4.0以后出现的新特性,主要是为了监控所有运行在yarn平台上面的所有任务(例如MR,Storm,Spark,HBase等等)
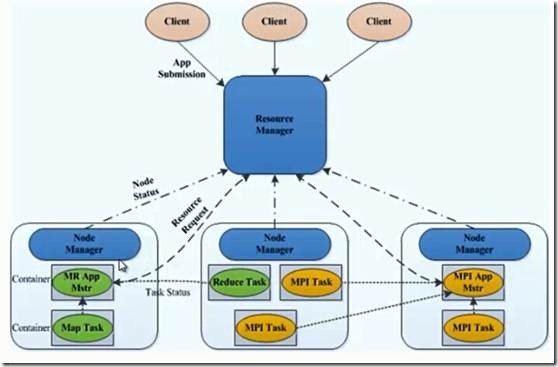
4.1主要组件的作用
- resourceManager主要作用:
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
- NodeManager主要作用:
- 单个节点上的资源管理和任务管理
- 接收并处理来自resourceManager的命令
- 接收并处理来自ApplicationMaster的命令
- 管理抽象容器container
- 定时向RM汇报本节点资源使用情况和各个container的运行状态
- ApplicationMaster主要作用:
- 数据切分
- 为应用程序申请资源
- 任务监控与容错
- 负责协调来自ResourceManager的资源,开通NodeManager监视容的执行和资源使用(CPU,内存等的资源分配)
- Container主要作用:
- 对任务运行环境的抽象
- 任务运行资源(节点,内存,cpu)
- 任务启动命令
- 任务运行环境
从 YARN 的架构图来看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下几个组件构成。
1、 ResourceManager(RM)
? YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
? 总的来说,RM有以下作用
? 1)处理客户端请求
? 2)启动或监控ApplicationMaster
? 3)监控NodeManager
? 4)资源的分配与调度
2、 ApplicationMaster(AM)
? ApplicationMaster 管理在YARN内运行的每个应用程序实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
? 总的来说,AM有以下作用
1)负责数据的切分
2)为应用程序申请资源并分配给内部的任务
3)任务的监控与容错
3、 NodeManager(NM)
? NodeManager管理YARN集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
? 总的来说,NM有以下作用
1)管理单个节点上的资源
2)处理来自ResourceManager的命令
3)处理来自ApplicationMaster的命令
4、 Container
? Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
? 总的来说,Container有以下作用
1)对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息
要使用一个 YARN 集群,首先需要一个包含应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个 ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster 协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
通过上面的讲解,应该明确的一点是,旧的 Hadoop 架构受到了 JobTracker 的高度约束,JobTracker 负责整个集群的资源管理和作业调度。新的 YARN 架构打破了这种模型,允许一个新 ResourceManager 管理跨应用程序的资源使用,ApplicationMaster 负责管理作业的执行。这一更改消除了一处瓶颈,还改善了将 Hadoop 集群扩展到比以前大得多的配置的能力。此外,不同于传统的 MapReduce,YARN 允许使用MPI( Message Passing Interface) 等标准通信模式,同时执行各种不同的编程模型,包括图形处理、迭代式处理、机器学习和一般集群计算。
4.2 yarn的原理
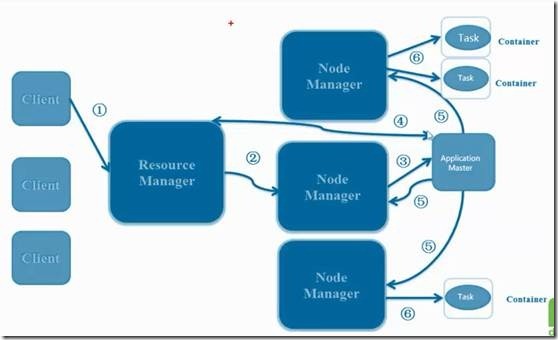
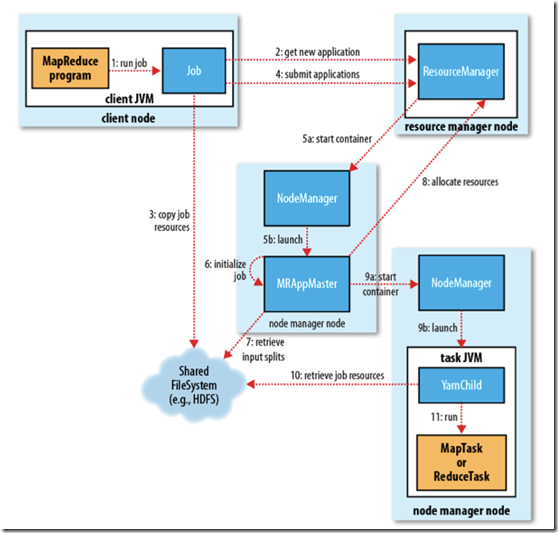
YARN 的作业运行,主要由以下几个步骤组成
1. 作业提交
? client 调用job.waitForCompletion方法,向整个集群提交MapReduce作业 (第1步) 。 新的作业ID(应用ID)由资源管理器分配(第2步). 作业的client核实作业的输出, 计算输入的split, 将作业的资源(包括Jar包, 配置文件, split信息)拷贝给HDFS(第3步). 最后, 通过调用资源管理器的submitApplication()来提交作业(第4步).
2. 作业初始化
? 当资源管理器收到submitApplciation()的请求时, 就将该请求发给调度器(scheduler), 调度器分配container, 然后资源管理器在该container内启动应用管理器进程, 由节点管理器监控(第5步).
? MapReduce作业的应用管理器是一个主类为MRAppMaster的Java应用. 其通过创造一些bookkeeping对象来监控作业的进度, 得到任务的进度和完成报告(第6步). 然后其通过分布式文件系统得到由客户端计算好的输入split(第7步). 然后为每个输入split创建一个map任务, 根据mapreduce.job.reduces创建reduce任务对象.
3. 任务分配
? 如果作业很小, 应用管理器会选择在其自己的JVM中运行任务。
? 如果不是小作业, 那么应用管理器向资源管理器请求container来运行所有的map和reduce任务(第8步). 这些请求是通过心跳来传输的, 包括每个map任务的数据位置, 比如存放输入split的主机名和机架(rack). 调度器利用这些信息来调度任务, 尽量将任务分配给存储数据的节点, 或者分配给和存放输入split的节点相同机架的节点.
4. 任务运行
? 当一个任务由资源管理器的调度器分配给一个container后, 应用管理器通过联系节点管理器来启动container(第9步). 任务由一个主类为YarnChild的Java应用执行. 在运行任务之前首先本地化任务需要的资源, 比如作业配置, JAR文件, 以及分布式缓存的所有文件(第10步). 最后, 运行map或reduce任务(第11步).
? YarnChild运行在一个专用的JVM中, 但是YARN不支持JVM重用.
5. 进度和状态更新
? YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
6. 作业完成
? 除了向应用管理器请求作业进度外, 客户端每5分钟都会通过调用waitForCompletion()来检查作业是否完成. 时间间隔可以通过mapreduce.client.completion.pollinterval来设置. 作业完成之后, 应用管理器和container会清理工作状态, OutputCommiter的作业清理方法也会被调用. 作业的信息会被作业历史服务器存储以备之后用户核查.
4.3 调度器
第一种调度器:FIFO Scheduler (队列调度器)
第二种调度器:capacity scheduler(容量调度器,apache版本默认使用的调度器)
第三种调度器:Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
4.4 yarn常用参数设置
| 项目 | 配置参数 | 默认值 |
|---|---|---|
| container分配最小内存 | yarn.scheduler.minimum-allocation-mb | 1024 |
| container分配最大内存 | yarn.scheduler.maximum-allocation-mb | 8192 |
| container的最小虚拟内核个数 | yarn.scheduler.minimum-allocation-vcores | 1 |
| container的最大虚拟内核个数 | yarn.scheduler.maximum-allocation-vcores | 32 |
| nodeManager可以分配的内存大小 | yarn.nodemanager.resource.memory-mb | 8192 |
我们可以在yarn-site.xml当中修改以下两个参数来改变默认值
| 项目 | 配置参数 | 设定值 |
|---|---|---|
| 定义每台机器的内存使用大小 | yarn.nodemanager.resource.memory-mb | 8192 |
| 定义每台机器的虚拟内核使用大小 | yarn.nodemanager.resource.cpu-vcores | 8 |
| 定义交换区空间可以使用的大小 | yarn.nodemanager.vmem-pmem-ratio | 2.1 |