集群搭建hadoop伪分布式
软件准备:
VMware Workstation Pro
centos 7
xshell5
jdk-8u141-linux-x64.tar.gz
hadoop-2.10.1.tar.gz
一.安装jdk
1.首先在jdk官网中,下载jdk安装包,本文以jdk-8u141-linux-x64.tar.gz为例
2.将安装包传入虚拟机中,本文以xshell5为例
(1).打开xshell5,连接上虚拟机,连接成功之后会有以下提示

(2).输入rz命令,出现传输文件的提示框
选择jdk的安装包传入到虚拟机中,传输完成之后会有提示。
3.文件传输成功后,打开虚拟机,安装jdk
4.解压压缩包
输入命令tar -zxvf jdk-8u141-linux-x64.tar.gz

5.配置环境变量
解压完成之后,配置jdk的环境变量,首先进入root文件,使用ls查看目录文件

进入jdk1.8.0_141文件之中,输入命令,cd jdk1.8.0_141

进入文件之后输入pwd查看jdk文件的路径

查看完文件路径之后,进入配置环境页面,输入命令vi /etc/profile
利用上下键进入页面的最后一行,按i进入编辑模式,在最后一行输入
export JAVA_HOME=jdk的文件路径
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAH?OME/bin:PATH
export CLASSPATH=.:
J
A
V
A
H
O
M
E
/
l
i
b
/
d
t
.
j
a
r
:
JAVA_HOME/lib/dt.jar:
JAVAH?OME/lib/dt.jar:JAVA_HOME/lib/tools.jar

在输入完成环境变量配置之后,按esc退出编辑模式,按shift+:,输入wq保存文件并退出
6.生效环境变量
在退出之后,输入命令source /etc/profile,使环境变量生效,
7.验证配置是否成功,可以输入命令java -version(一定要输入空格),若出现以下内容就证明配置环境变量成功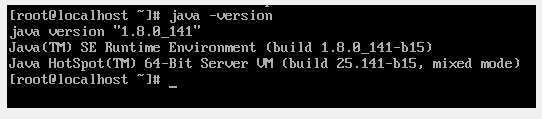
jdk的配置成功
二.ssh免密登录
1.下载ssh服务并启动
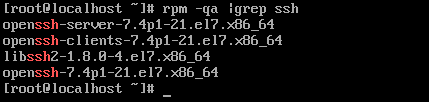
(1).检查是否安装了ssh包,输入命令rpm -qa |grep ssh,输入命令后显示出以下结果就证明安装了ssh包
(2).检查ssh是否为开机启动项,输入命令
chkconfig --list sshd
(3).设置开机启动ssh服务,输入命令
chkconfig --level 2345 sshd on
(4).重启ssh服务,输入命令
service sshd start
(5).验证是否启动了22端口(默认端口),输入命令
netstat -antp |grep sshd

这就证明端口启动成功
2.首先生成密钥对,使用命令
ssh-keygen或者是ssh-keygen -t rsa,第一种是简写形式,在输入命令回车之后,不需要输入任何东西,直接三次回车就好了
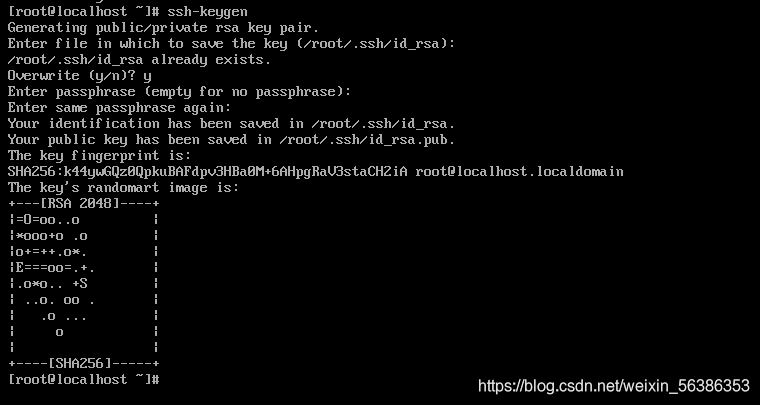
从打印信息中可以看出,私钥id_rsa和公钥id_rsa.pub都已经创建成功,输入命令,进入.ssh文件中,利用ls命令查看文件内容可以看到私钥id_rsa和公钥id_rsa.pub都已经在.ssh文件中了。
进入.ssh文件,输入命令cd /root/.ssh/(隐藏文件夹以.开头),输入ls命令可以看到公钥id_rsa.pub和私钥id_rsa都已经保存在文件当中。
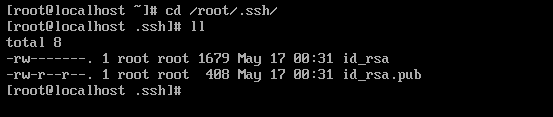
3.将公钥放置到授权列表文件authorized_keys(文件名一定要输对)中,输入命令:
cp id_rsa.pub authorized_keys
4.修改授权列表文件authorized_keys的权限,输入命令
chmod 600 authorized_keys
规定权限只能由拥有者可读可写

5.验证免密登录是否配置成功,输入命令
ssh localhost
或
ssh ip地址(可以使用ifconfig命令进行查看)
或
ssh 主机名(可以使用hostname命令进行查看)
本文使用ssh localhost命令进行验证

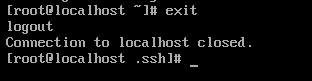
在输入命令之后,可以看到ssh文件夹登陆到了主机中,就证明ssh免密配置成功了。如果想要退出主机登录,可以输入exit退出登录
三.安装hadoop
1.下载安装包
(1).首先登陆hadoop的官网,选择hadoop的版本
官网地址:http://hadoop.apache.org/releases.html
(2).进入官网后,点击mirror site
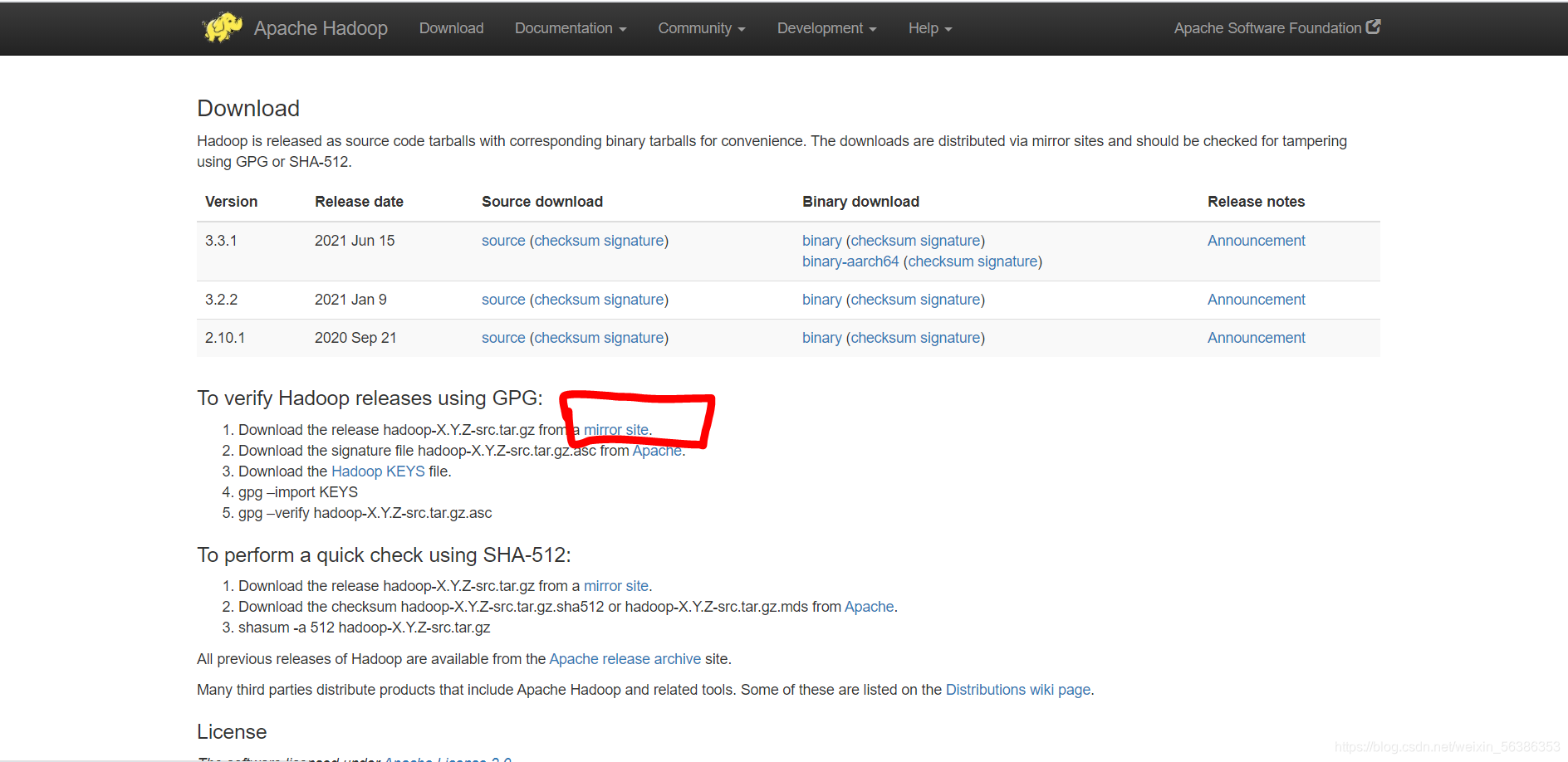
(3).点击mirror site进入页面,选择https://downloads.apache.org/hadoop/common,网址进入hadoop版本选择页面
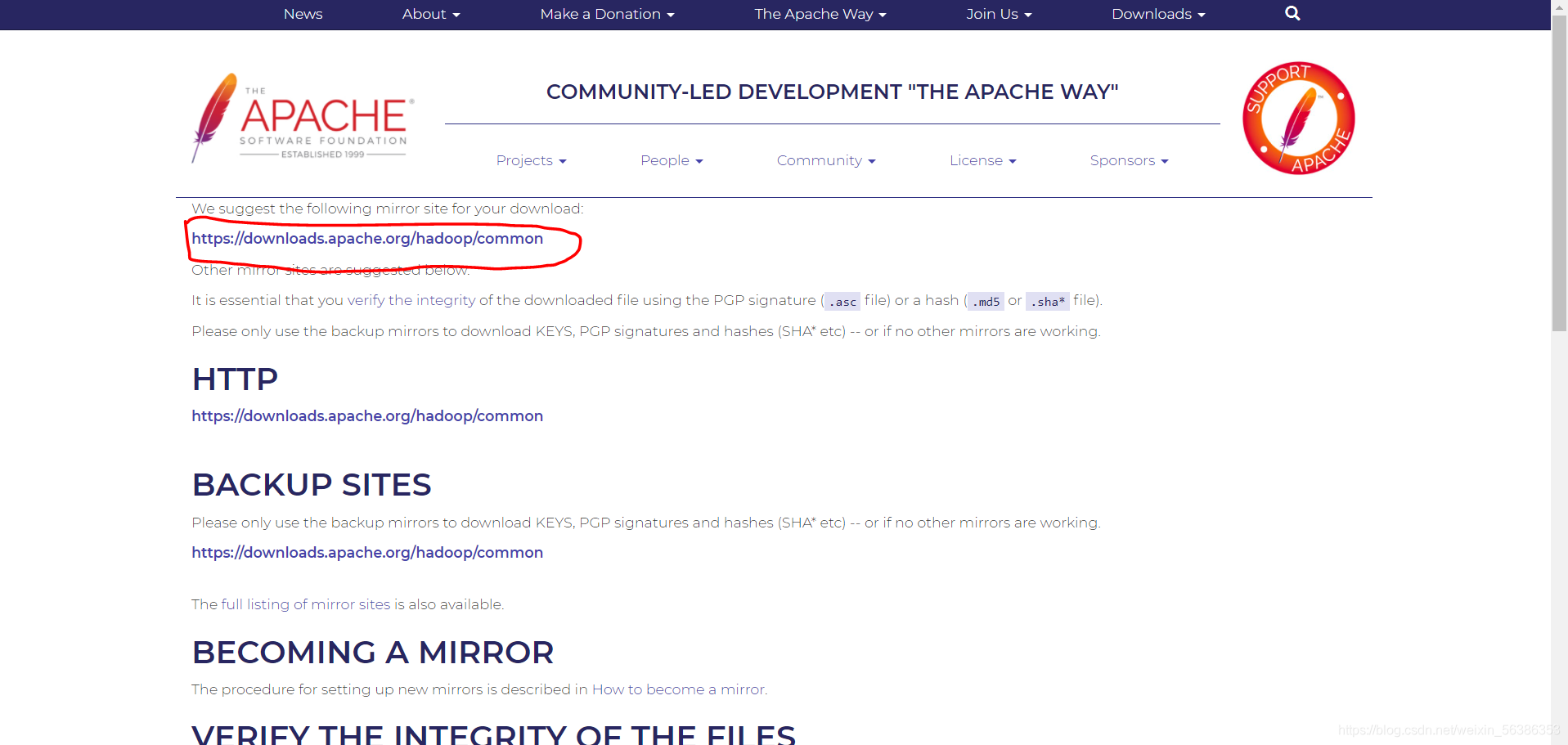
(4).根据自己需要选择hadoop的版本,本文以hadoop-2.10.1为例,下载hadoop安装包。选择结尾是tar.gz的压缩包

2.传输hadoop的压缩包
打开xshell,输入rz命令,出现提示框,选择要传输的文件,将文件传入到虚拟机中
选择文件传输,弹出传输完成的提示框后就证明hadoop文件已经存在在虚拟机中了,可以进入虚拟机中查看,输入ls命令可以查看文件,查看完成之后就可以进行下一步操作了。
3.解压hadoop
输入命令tar -zxvf hadoop-2.10.1.tar.gz -C /输入存储路径,或者直接解压,输入命令
tar -zxvf hadoop-2.10.1.tar.gz(压缩包名)
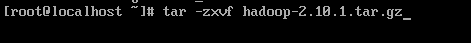
完成对hadoop压缩包的解压
4.配置hadoop
(1).进入文件夹
解压完成之后,在目录文件下输入ls命令查看文件夹

可以看到hadoop的文件夹,输入命令进入hadoop的文件中,输入命令:cd hadoop-2.10.1

(2).查看文件路径
输入pwd命令查看hadoop-2.10.1文件夹所在的工作路径

(4).配置hadoop环境变量
查看完路径之后输入命令:
vim /etc/profile

进入文件配置页面
进入配置页面后按i进入编辑模式,利用上下方向键进入到页面最后一行,输入以下两行命令
export HADOOP_HOME = /root/hadoop-2.10.1(利用pwd查看的文件路径)
export PATH =
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin

编辑完成之后,按esc退出编辑模式,按shift+:输入wq保存并退出
(5).生效环境变量
输入命令:source /etc/profile,生效环境变量。

(6).验证环境变量
验证配置是否成功,输入hadoop version查看文件版本,或者输入echo $PATH来验证hadoop是否安装成功

版本号正确就是说明配置成功
四.配置HDFS
1.配置环境变量hadoop-env.sh
打开hadoop-env.sh文件
输入命令
vim /root/hadoop-2.10.1/etc/hadoop/hadoop-env.sh

进入文件配置页面,找到JAVA_HOME参数位置,将后面的参数位置修改为本机安装的JDK的实际安装位置(在第一步在安装jdk时,使用pwd命令查看过)

完成之后输入命令退出并保存编辑模式
2.配置核心组件core-site.xml
打开core-site.xml文件,输入命令
vim /root/hadoop-2.10.1/etc/hadoop/core-site.xml

将下面的配置内容添加到其中
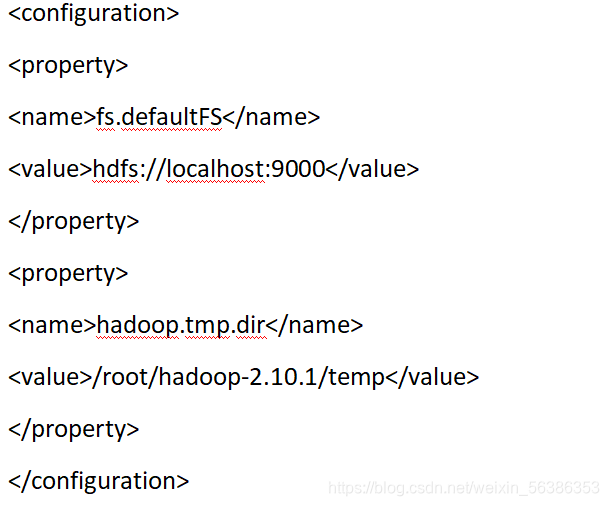
temp文件需要提前创建

3.配置文件系统hdfs-site.xml
首先进入文件,输入命令
vim /root/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
将下面的配置内容添加到其中

data文件和name文件都需要提前创建

4.配置slaves文件
该文件是用来记录hadoop集群所有从节点(HDFS的DataNode和YARN的NodeManager所在主机)的主机名,(配置的前提是本机配置了ssh免密登录)
打开文件,输入命令

打开之后看到只有一台主机名称localhost,因为我们搭建的是伪分布式集群,所以就只有一台主机,不用修改内容
5.格式化文件系统
将以上文件配置完成之后,就可以格式化文件系统了,输入命令
hdfs namenode -format

6.启动hdfs
启动的前提是要配置slaves和ssh免密登录,输入命令,启动hdfs集群
start-dfs.sh

在本机上输入jps命令,打印出来四个进程就表示hdfs启动成功

五.配置yarn
1.配置yarn-env.sh环境变量
进入文件,输入命令:
vim /root/hadoop-2.10.1/etc/hadoop/yarn-env.sh

进入配置页面之后找到java_home的参数位置,去掉前面的#,将后面的参数位置,改为本机中实际安装jdk的路径(在第一步在安装jdk时,使用pwd命令查看过)

2.配置yarn-site.xml文件
打开文件,输入命令:
vim /root/hadoop-2.10.1/hadoop/yarn-site.xml

进入配置页面后将以下内容输入到中
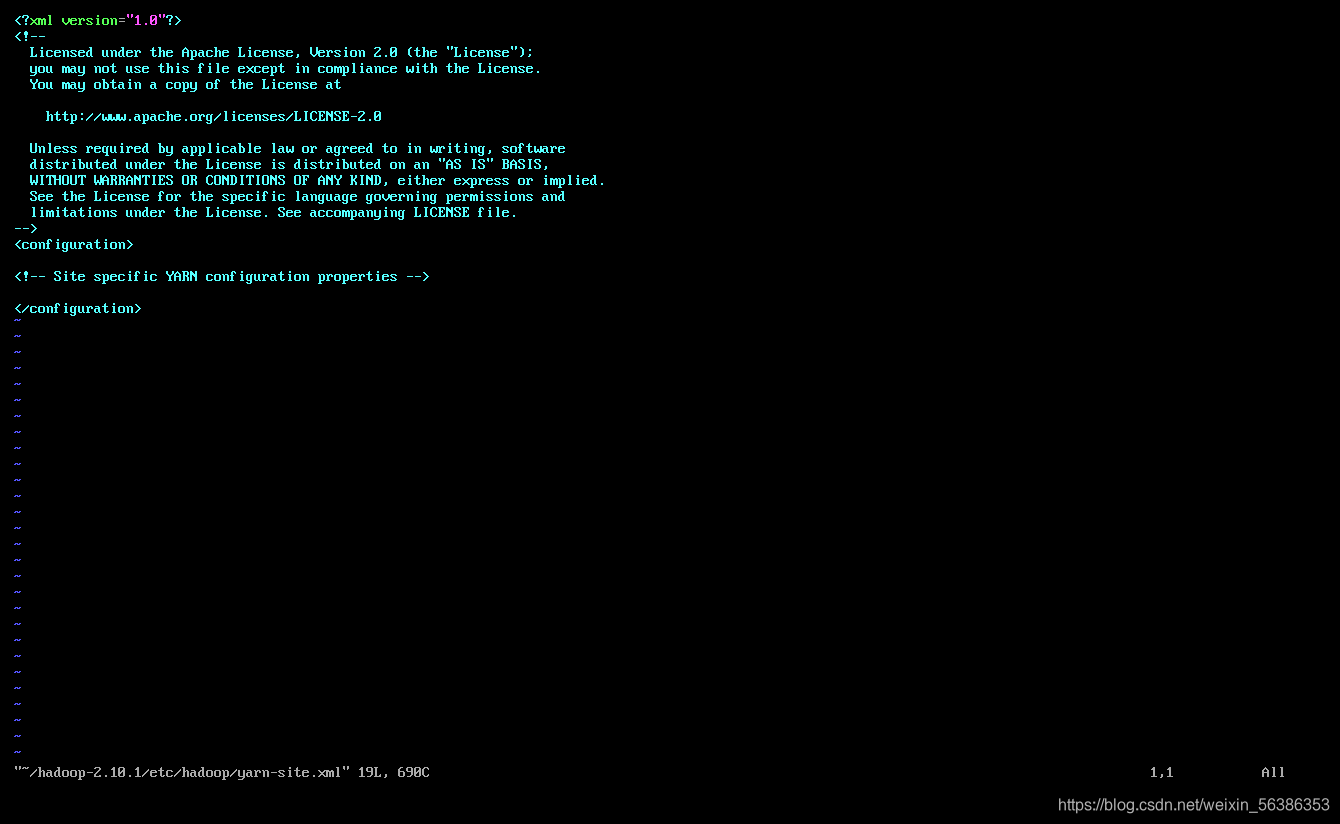
在其中输入以下配置内容


输入完配置文件内容之后,输入命令保存并退出编辑页面
3.启动集群
输入命令:
start-yarn.sh


如果出现了以下的打印信息就算是启动成功了
到这里集群搭建就结束了,我们搭建的是伪分布式,就只有一台主机
在集群搭建中所遇到的问题以及解决方法
1.xshell虚拟机输入rz命令之后没有提示框
这个是由于xshell没有安装rz命令,需要自行安装,输入命令
yum install -y lrzsz
安装rz命令,出现提示框,选择文件,进行文件传输。
2.在进行ssh免密登录的时候,输入命令无法查找到ssh包,这时候就要输入命令,自己安装ssh包,
使用命令:yum install openssh-server,
就可以解决了
3.在进行ssh免密登录的时候,发现无法启动端口,这个时候可能是没有安装netstat命令,netstat命令对系统并没有作用,就可以使用命令yum install net-tools -y,安装netstat命令,启动端口
4.在配置HDFS中输入jps验证是否配置成功时,只出现了jps一个进程,这是我们可以将创建在hadoop中的data这些临时目录文件删除,然后再重新格式化hdfs文件就可以解决了。