�Hbase�ı���ģʽ��α�ֲ�ģʽ��ȫ�ֲ�ģʽ��HA
�ֶ�������,��ֹת��: ԭ����ַ https://blog.csdn.net/lys_828/article/details/119030423(CSDN����:Be_melting)
֪ʶ��������,�������Ͷ��ɹ�,���½�������CSDN��վ��,��������վ�����ò��ľ�����δ��������Ȩ�Ķ�����ȡ��Ϣ
0 ��ͬ����
(1)��ѹ:tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training/
(2)���û�������
vi ~/.bash_profile
HBASE_HOME=/root/training/hbase-1.3.1
export HBASE_HOME
PATH=$HBASE_HOME/bin:$PATH
export PATH
���������� :source ~/.bash_profile
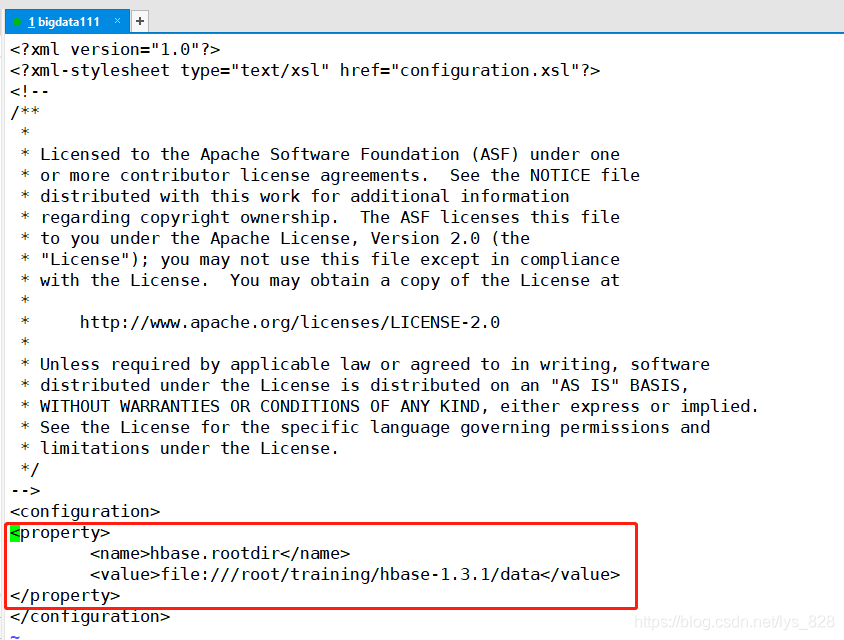
(3)���������ļ� conf/hbase-site.xml
1 �Hbase�ı���ģʽ
1.1 �����
�ص�:����ҪHDFS��֧��,ֱ�Ӱ����ݴ洢�ڲ���ϵͳ��
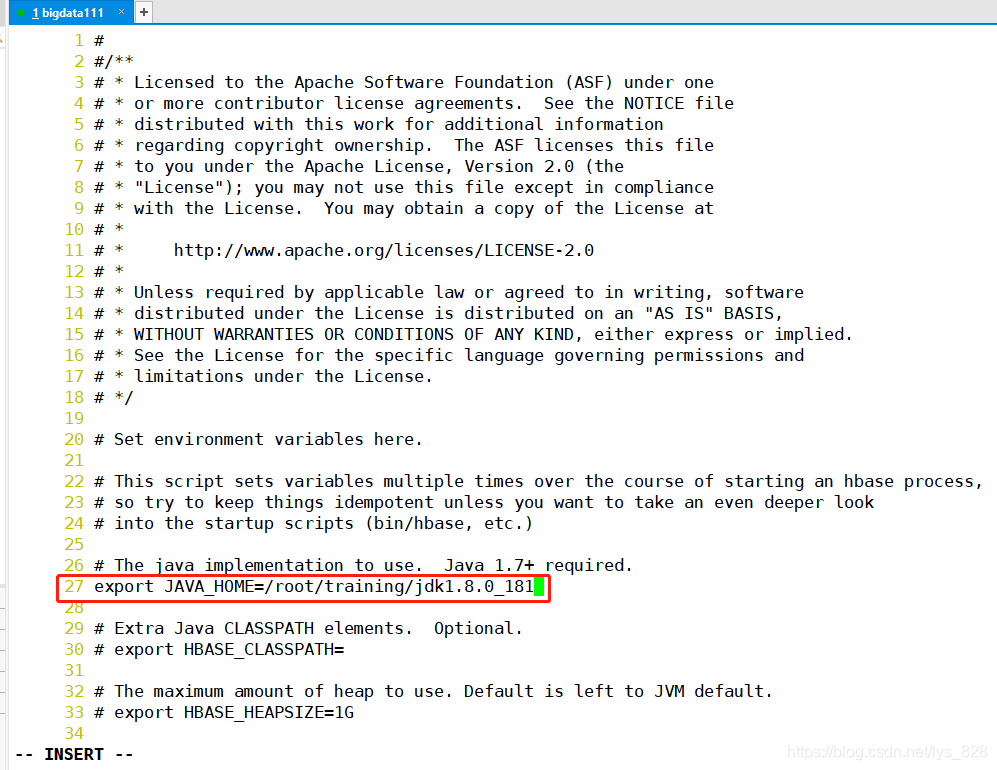
hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_181
hbase-site.xml��������HBase���ݴ洢��·��
<property>
<name>hbase.rootdir</name>
<value>file:///root/training/hbase-1.3.1/data</value>
</property>
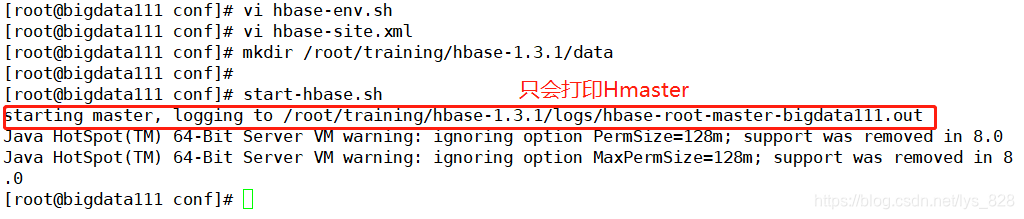
����HBase:start-hbase.sh
��־:starting master, logging to /root/training/hbase-1.3.1/logs/hbase-root-master-bigdata111.out
1.2 �ʵ��
1.2.1 ��ͬ��������
���Ƚ���װ��Hbase�����ϴ���Linux�������,���ʹ�õ������Ϊbigdata111��tools�ļ�����
��ʵtools�ļ������ǹ������ϴ���Hbase����
���ļ����н�ѹ,���ǰѰ�װ���ļ���������training�ļ�����(��װ������tools�ļ���),ִ�н������

��ѹ��Ϻ���Ҫ����һ��ϵͳ��������,��.bash_profile�ļ�,���л�������������
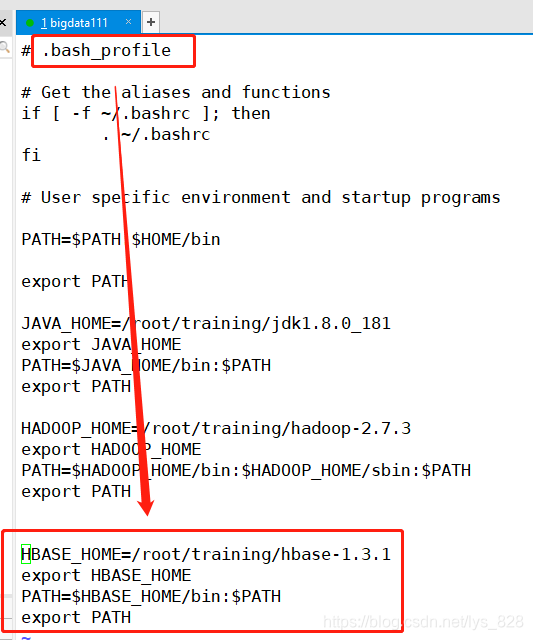
ȷ���������˳�,��Ч��������,�����ǹ��ɹ�����

���Ͼ��ǹ�ͬ�����Ĺ���,���������DZ���ģʽ��Ҫ�ĵIJ���
1.2.2 ����ģʽ��������
��Ҫ�����õ��ļ�����������(��һ�������ڹ�ͬ������ʱ���Ѿ��������)

�Ȳ鿴һ��֮ǰ���õ�Java�����Ͷ�ӦҪ�ĵ��ļ���λ��

���ĵ�һ������е��ļ�,���27�а�ע�͵�����ȡ��,Ȼ����д��Ӧ��ֵ(���Ǹող鿴����Java�ĵ�ַ)
���ĵڶ�������е��ļ�����,��һ����������Hbase���ݴ洢·��,�����DZ���ģʽ,���Ա���Ҫ��һ���ط�������,������ļ�·��Ҫ��ǰ������
������ɺ�Ϳ��Խ�������,�����Ѿ����ú���ϵͳ�Ļ�������,���κεط����ǿ���ִ��Hbase��ָ��,�����DZ���ģʽ,����������,������־ֻ��ӡ��Hmasterһ����¼,û��Zookeeper������
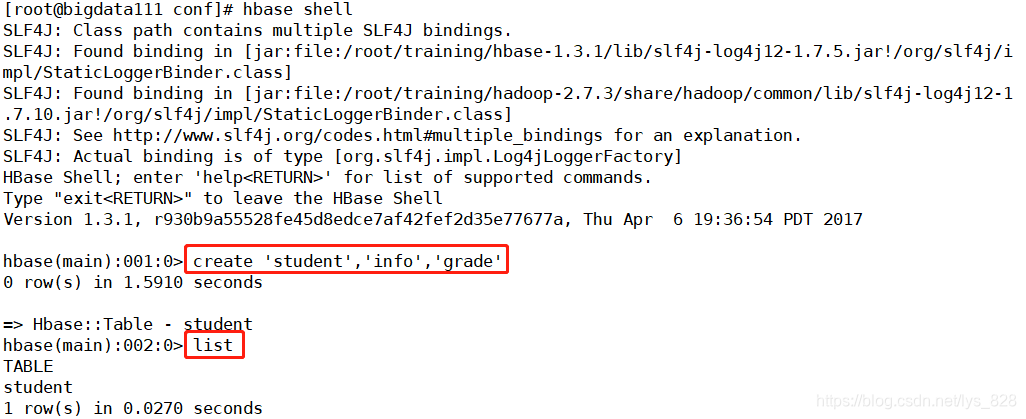
������Ϳ��Դ������ݿ�һ��
- ����Hbase����:
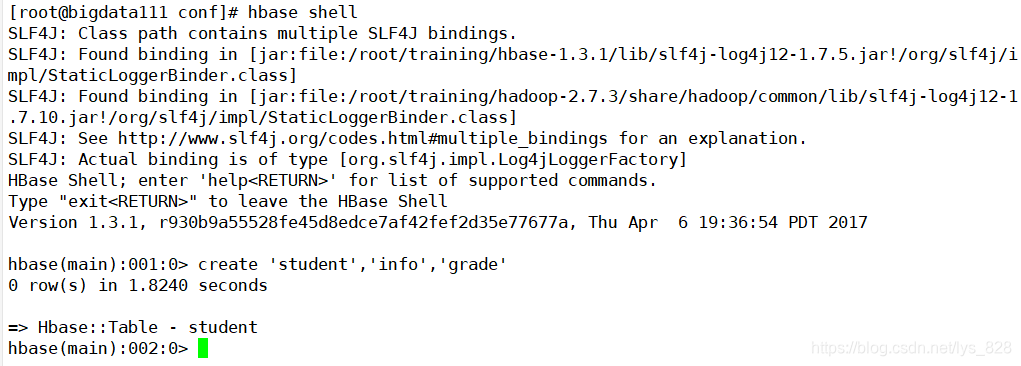
hbase shell - ������:
create 'student', 'info', 'grade'(��һ���DZ�����,ʣ�µľ�������) - �鿴��:
list
����һ�����ݵ����ݿ��п���Ч��,���гɹ����˳����ݿ�,��֮ǰָ�������ļ���λ�ÿ��Կ����ոռ�������ݾͷ���������ļ�����(����Ӧһ���ļ���,��������ֱ��Ӧ���ļ���)
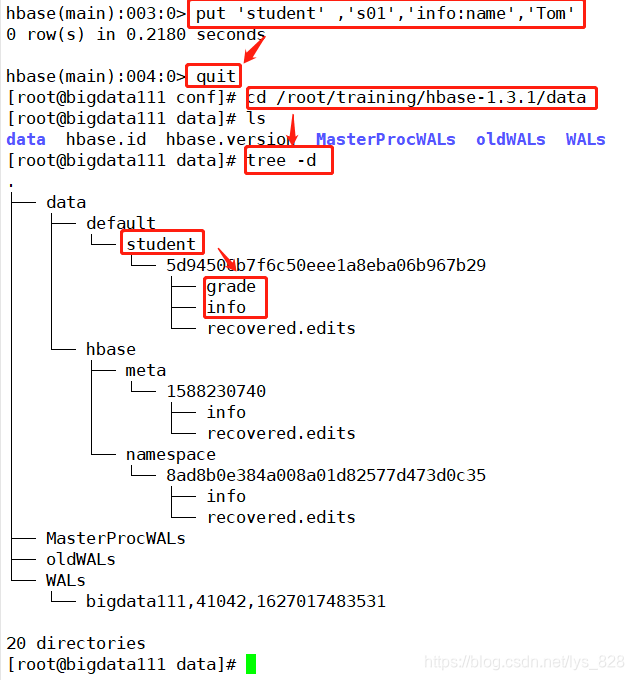
��һ���������еĽ���,ͨ��jps�鿴,������ֻ��HMaster����(ʣ�µĶ���HDFS�еĽ���)
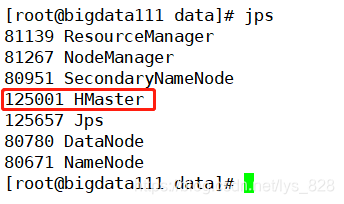
��ʵû�������,����ִ��ֹͣ����IJ���,��ʼ�α�ֲ���ģʽ(���˱���ģʽ�ʹ���)

2 �Hbase��α�ֲ�ģʽ
�ص�:�ڵ�����ģ��һ���ֲ�ʽ�Ļ���;�߱�HBase���еĹ���;�����ڿ����Ͳ���(ZooKeeper��HMaster��RegionServer�Ƚڵ�Ҳ�Ͷ�����)
��Ҫ���õ��ļ�����,��Щ����֮ǰ�Ѿ����ù���
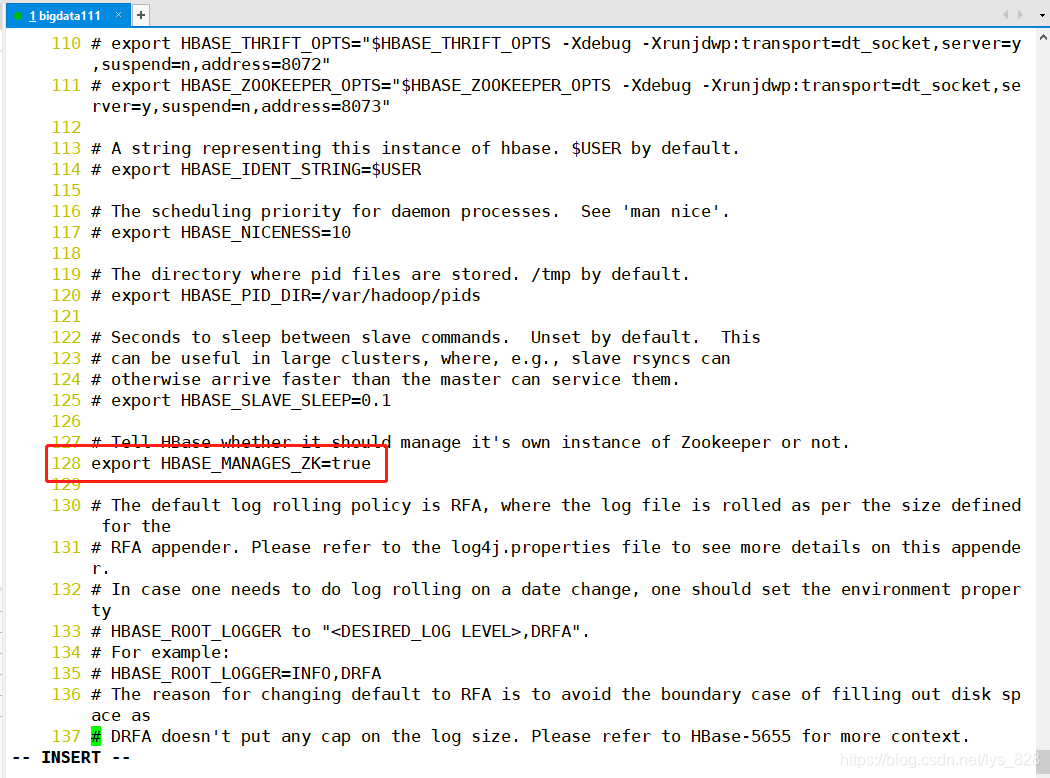
������hbase-env.sh�ļ�,���ļ�����128��ȡ��ע�ͼ���(���д����ʾʹ��hbase�Դ���ZooKeeper)
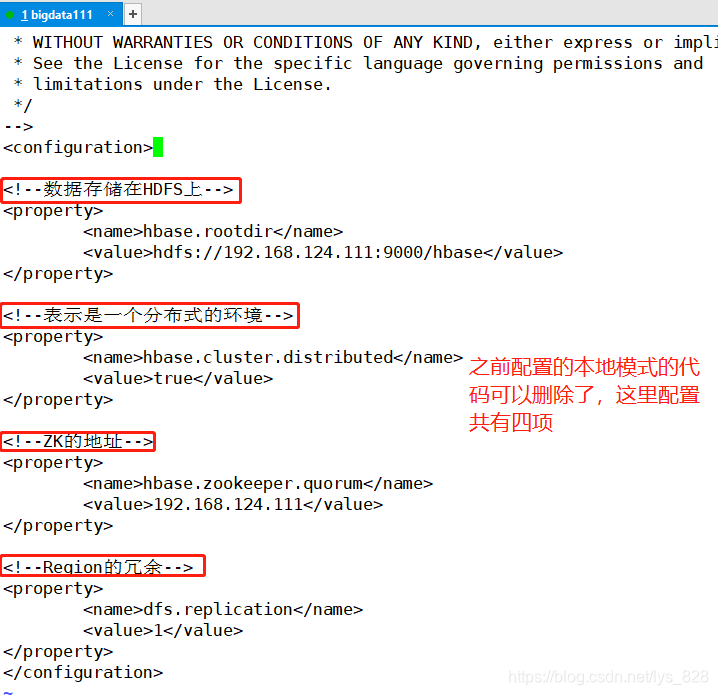
�ĵڶ����ļ�hbase-site.xml
���õ������ļ�regionservers,���ӱ��������ip��ַ
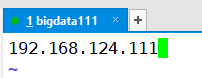
������Ҫ���õ������ļ����Ѿ����������
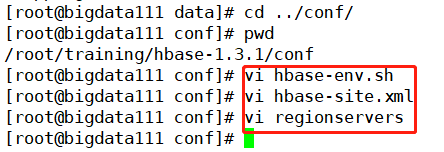
����һ�¼��鿴���ǹ�����,��֮ǰ�ı���ģʽ�����Ľڵ��������,����û�б���,��������(HQuorumPeer������Ǵ���ZooKeeper����)
������Ϻ�����ݿⴴ������,�����ݽ�ȥ�������
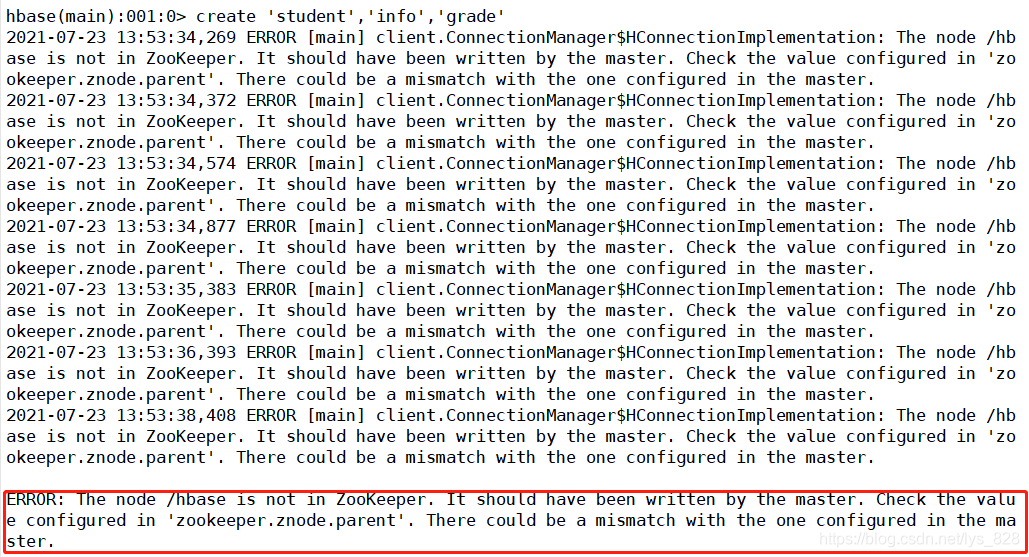
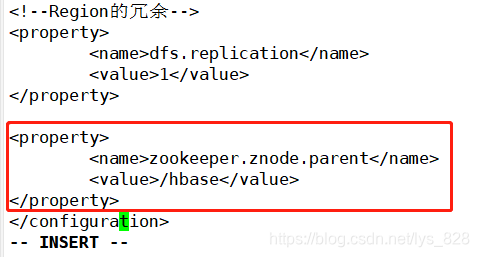
������������������,ֱ����ʾ������,������Ϣ��ERROR: The node /hbase is not in ZooKeeper. It should have been written by the master. Check the value configured in ��zookeeper.znode.parent��. There could be a mismatch with the one configured in the master. ��ô����Ҫ���һ�������ļ�,���к�ʵ
����hbase�����,��hbase-site.xml�ļ�,�������ϵ���Ϣ����,����һ����Ϣ����
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
��Ӧ���ļ��е���������
������˳�,��������hbase,�������ݿⴴ����,��ξ�������ʵ����(�ܿ���)
����һ������,���Ǻ�ԭ����һ��

�鿴�����Ƿ�����HDFS��,����ֱ��ͨ���������Web Console��һ��
����ֱ��ͨ�������еķ�ʽ�鿴Ҳ��,������hbase�ļ����µ�data�ļ��µ�default�ļ�����
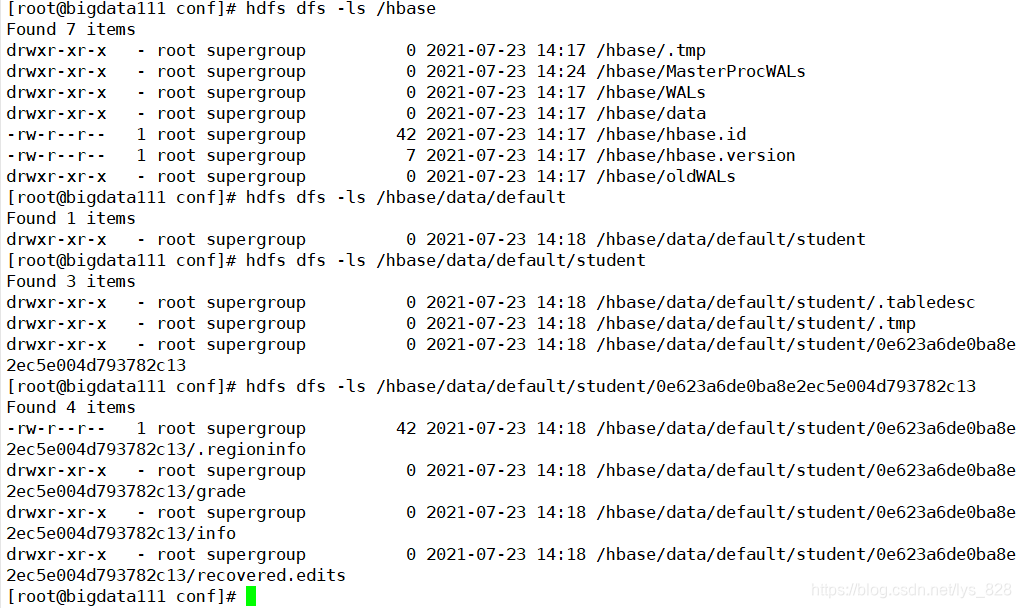
�����������ֶ����Ǻܿ��ӻ�,����ͨ��ZooKeeper���ӻ��˿�����һ��,�ṩ�������jar��,ֱ�ӵ�����к������Ӧ���������ip��ַ����
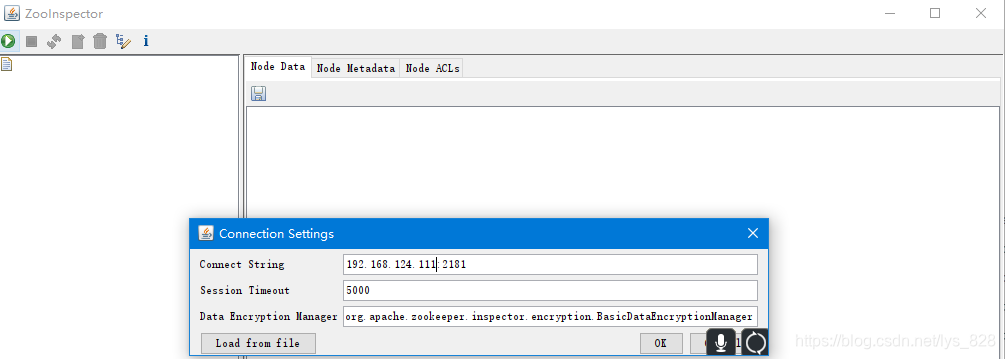
�Ե�һ���ͻ�Ѹո����ɵ��ļ���Ϣȫ����ʾ������(���ַ�ʽ�������Ŀ��Կ���Hbase��ZooKeeper�д洢������)
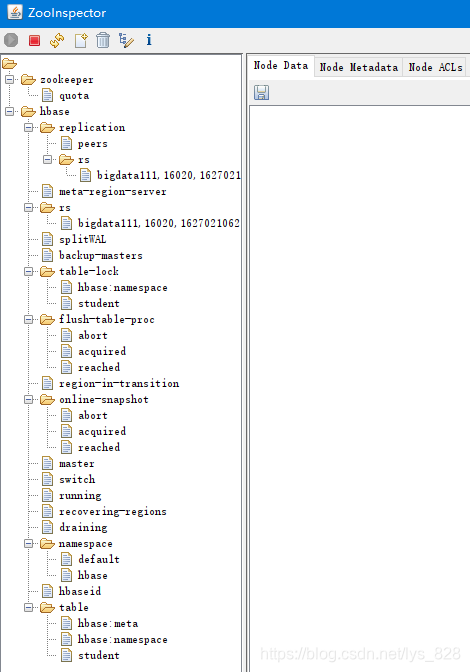
3 �Hbase��ȫ�ֲ�ģʽ
3.1 ͬ��ʱ�䡢����Hadoop
��Ҫ3̨�����,����bigdata112��bigdata113��bigdata114��̨�����,��xshell�����ú�ͬ��ģʽ,Ȼ��ȷ��һ��ÿ̨�������ʱ���Ƿ�ͬ��(֮ǰ�ڴHadoop��ȫ�ֲ�ģʽ���Ѿ�ͬ��ʱ����,�����ڵ㶼����bigdata112��)
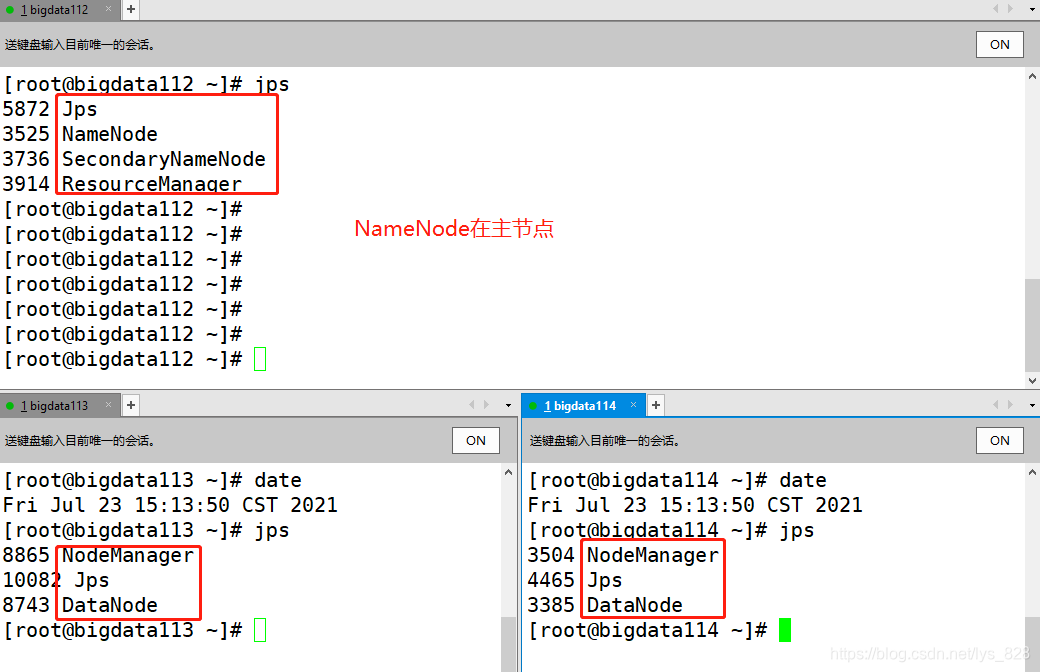
������bigdata112�Ͽ���hadoop����,��װhbase���Ǻ�֮ǰ��װhadoopһ�����������ڵ�����ݺ�,ʣ����̨������ֱ�Ӹ��ƹ�ȥ������(jps�鿴���������ڵ���������ĸ�����֤���������)
3.2 ���û�������
����֮ǰ�Ƚ�Hbase�����ϴ���bigdata112��,�����ǰ����ܵ�һģһ��(��tools�ļ�����������ҵ���Ӧ���ļ�)

���ž���ִ�й�ͬ����,���н�ѹ�ͻ�������������(���н�ѹ��װ����bigdata112�ϵ�������,���û���������Ҫ����̨���������ͬʱ����),��������ѹ��װhbase
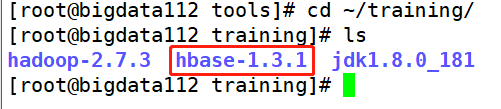
Ȼ����̨����ͬʱ���û�������
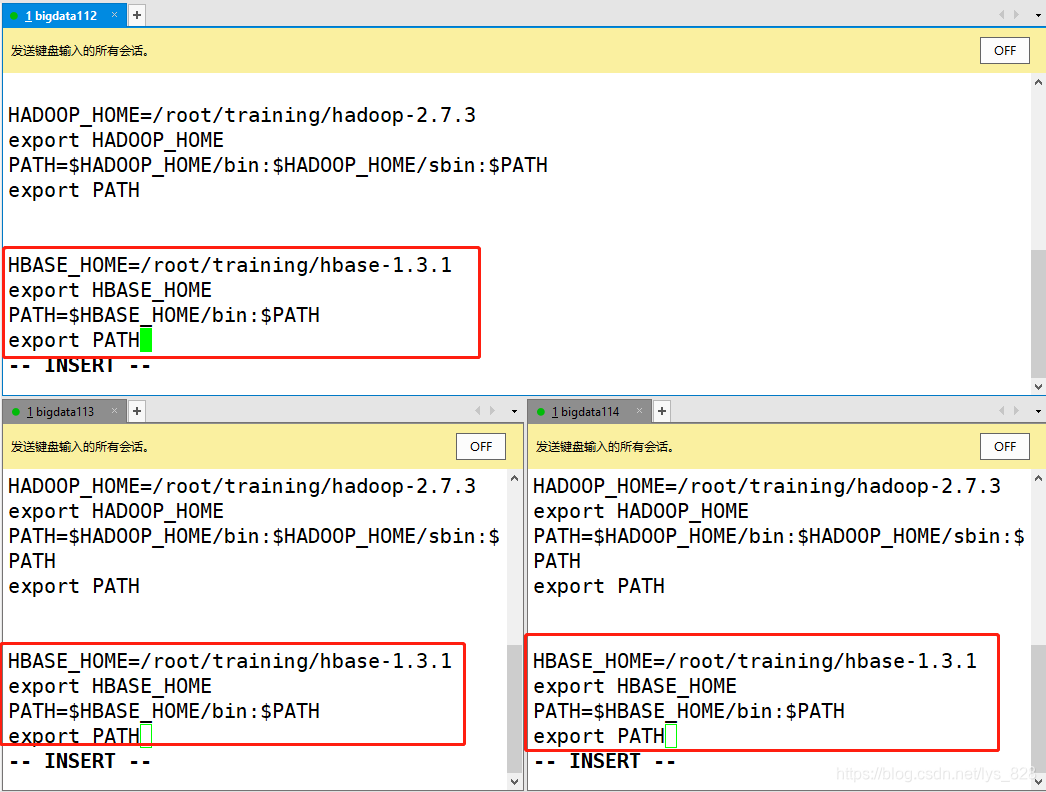
ʹ����������Ч,��������֤(���Է���ֻ����bigdata112�������氲װ�ɹ���,��������������bigdata112�Ϳ�����)
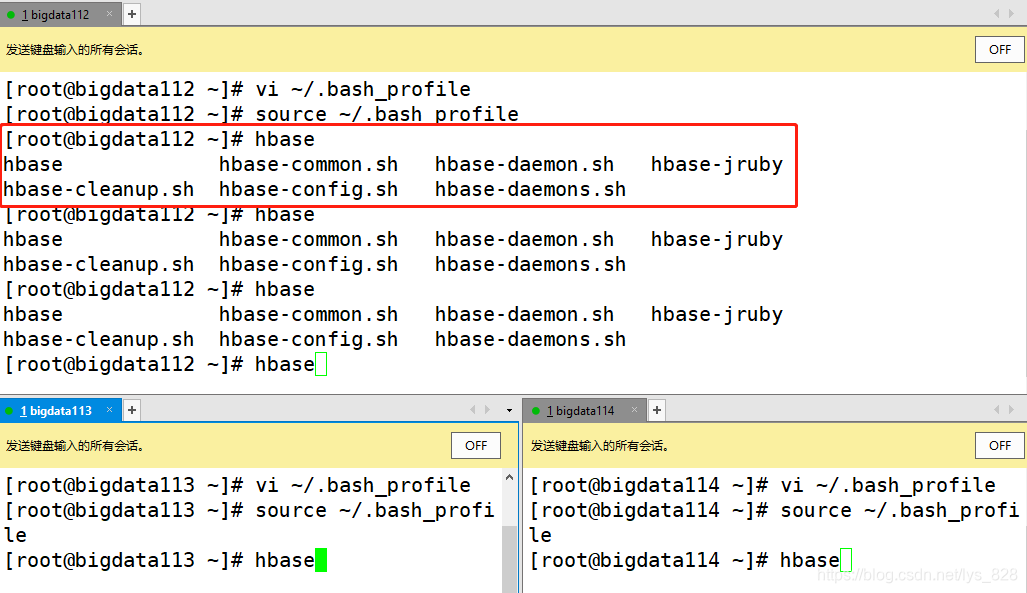
��Ҫ���õ��ļ�����(�Ա�α�ֲ�����������������,���з���˵Ķ˿�����)
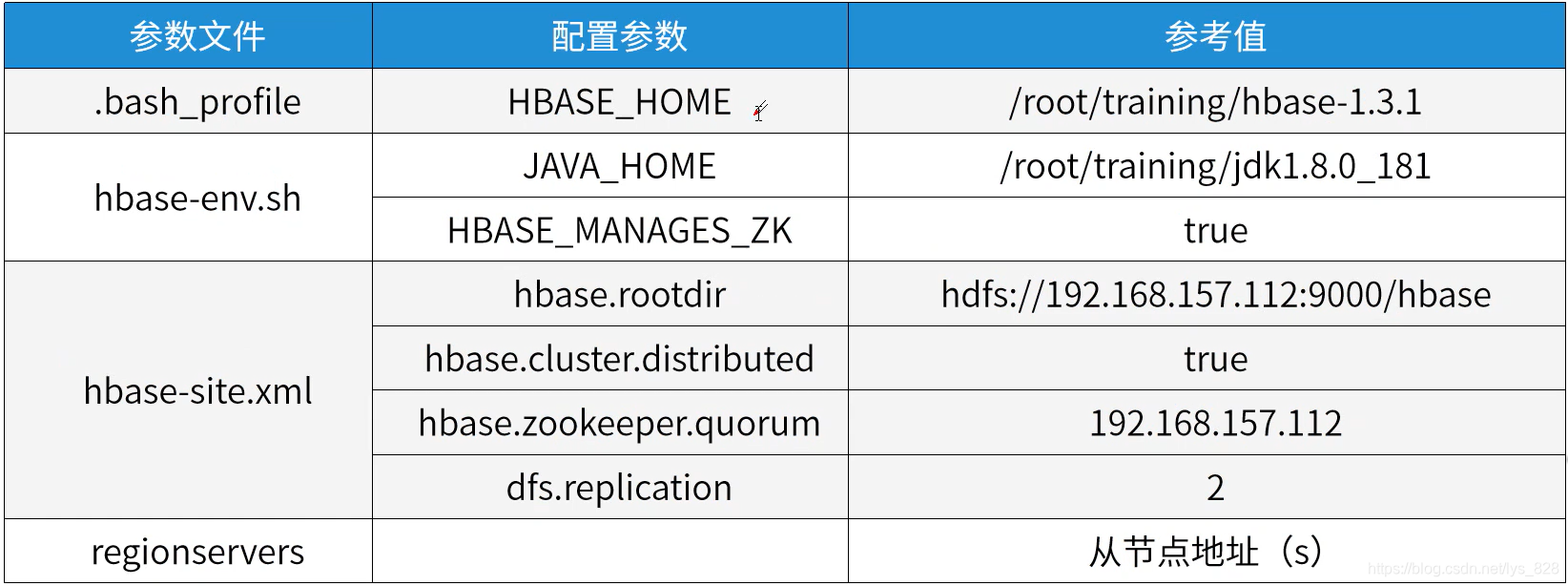
3.3 ����hbase-env.sh�ļ�
�ȸĵ�һ��hbase-env.sh�ļ�,��27�����ñ��ص�Java·��
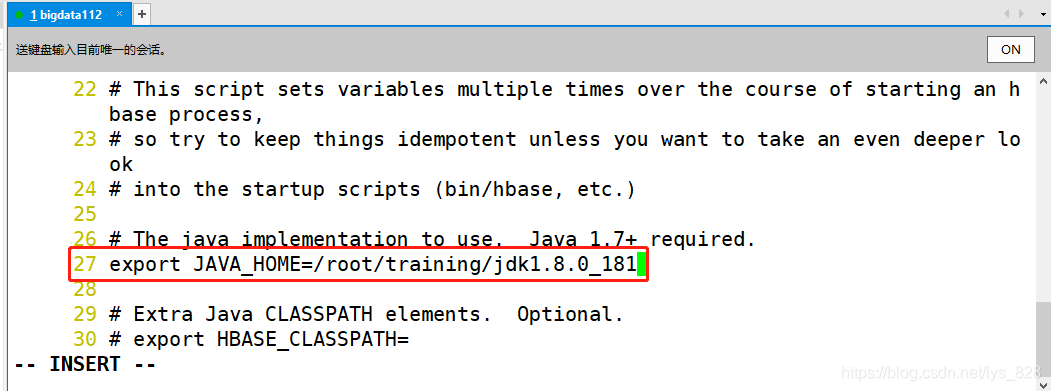
��128��ȡ��ZooKeeper��ע�ͺ�

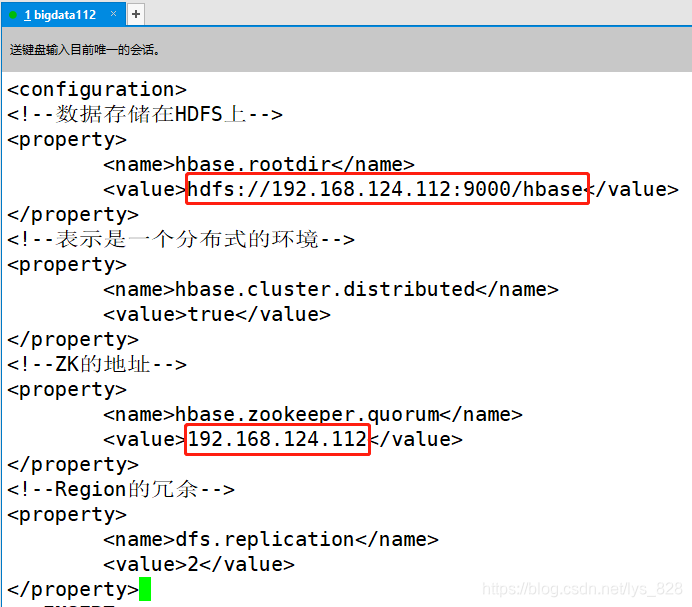
3.4 ����hbase-site.xml�ļ�
����hbase-site.xml�ļ�,����ע��ip��ַ����(������bigdata112)
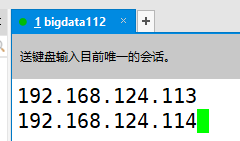
3.5 ����regionservers�ļ�
�������ļ�regionservers����ָ���ӽڵ��ַ�����˾���������ڵ��ȫ������
Ȼ����ļ����Ƶ�������̨�������,ִ�д���Ϊ:
scp -r hbase-1.3.1/ root@bigdata113:/root/trainingscp -r hbase-1.3.1/ root@bigdata114:/root/training
���е����ù������Ѿ���ɺ�,��������������Hbase����(ע��ԱȺ�α�ֲ�ģʽ��������ip��ַ)
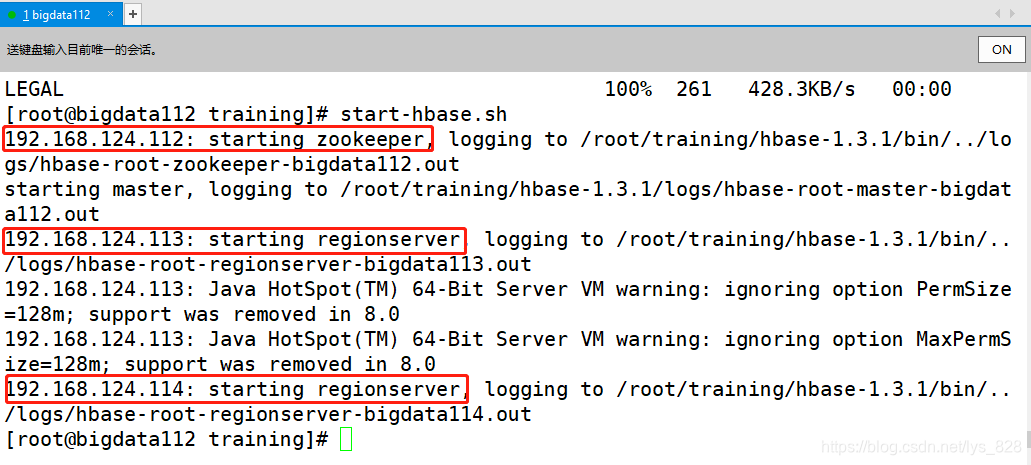
ͨ��jps�鿴ÿ̨����������Ľ���(����ȷ��,ȫ�ֲ���ģʽ�����ϴ���)
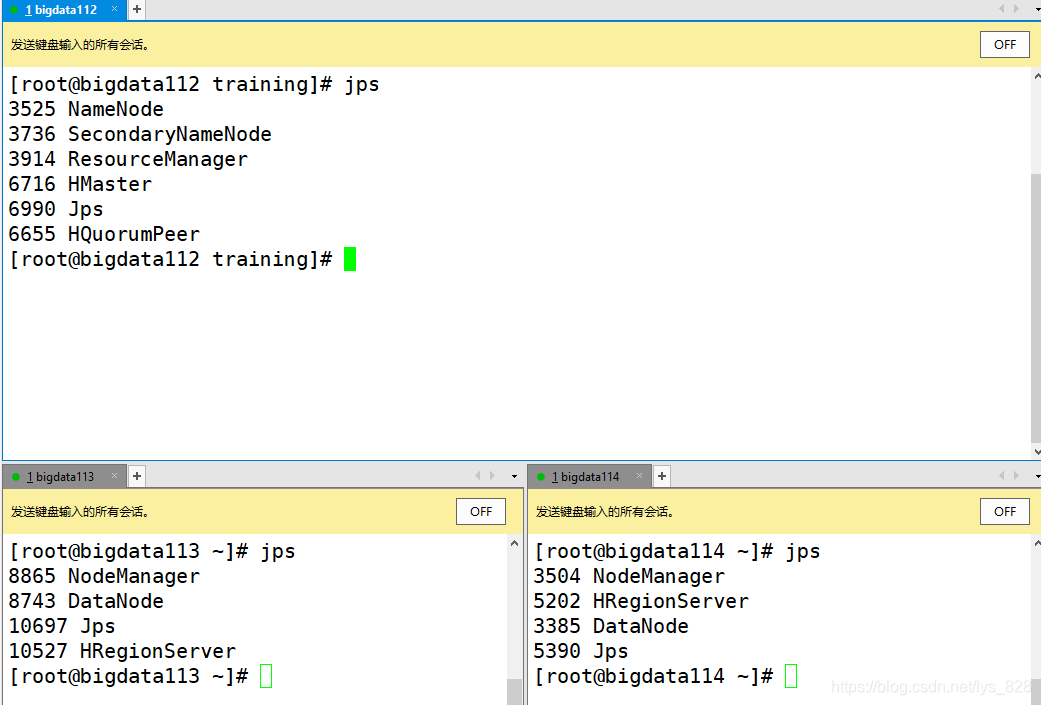
�����ݿⴴ��������ʵһ��,���� �����֮ǰ������α�ֲ����Ǹ�����(����û������),����ȫ�ֲ���ģʽ�ʹ�����
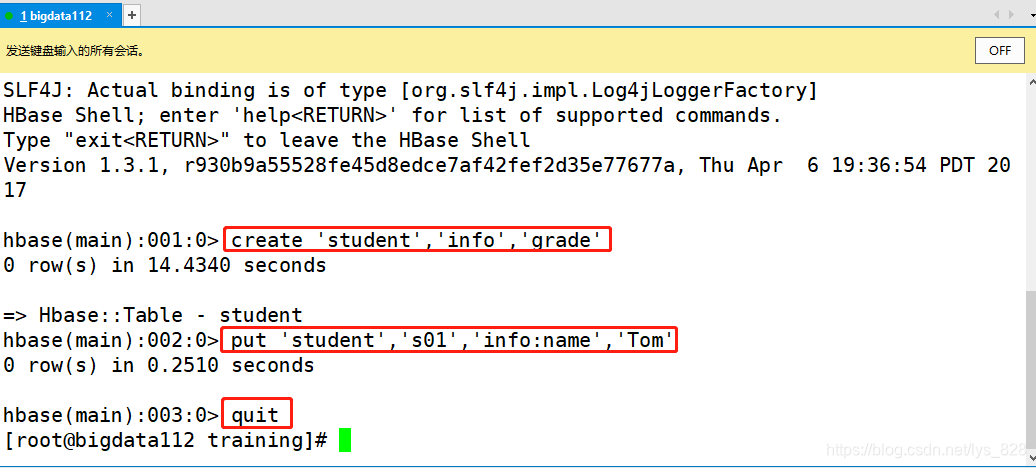
Ȼ����ͨ��ZooKeeper�鿴���ɵ������ļ�,��ʱ��Ķ�Ӧ��ip��ַӦ��������Ϊ112,����Ľ������(���Կ��Կ���������������ӽڵ��Ӧ����Ϣ)
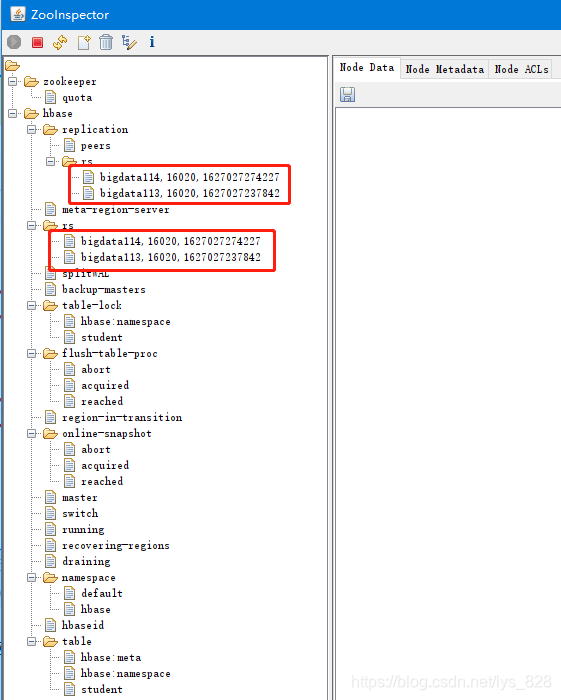
4 �Hbase��HAģʽ
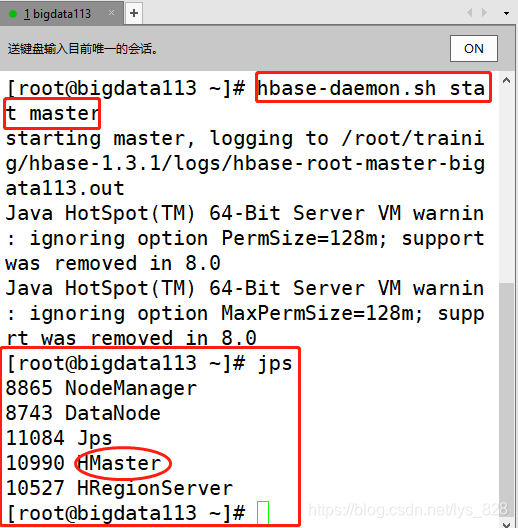
������,����Ҫ�����,ֻ��Ҫ��ij���ӽڵ���,�ֶ�����һ��Master�Ϳ���,������bigdata113������һ��master,Ȼ����ͨ��jps�鿴����,����HMaster֤��������һ���������ڵ�
����,���ڴHbase�ı���ģʽ��α�ֲ�ģʽ��ȫ�ֲ�ģʽ��HAģʽ֪ʶ��������������,����??�c(�㨌��)��?