MapReduce是一种并行编程模型,用于大规模数据集的并行运算,能够以一种可靠的,具有高容错能力的方式并行地处理TB级别以上的海量数据集。Map(映射)和Reduce(规约)是它的主要思想。
?一、MapReduce工作流程总览
MapReduce Job(作业)是客户端需要执行的一个工作单元:它包括输入数据、MapReduce程序和配置信息。Hadoop将job分成若干个task(任务)来执行。每个task又包括两类任务:map任务和reduce任务。这些任务运行在集群的节点上,并通过YARN进行调度。如果一个task失败,它将在另一个节点上自动重新调度执行。
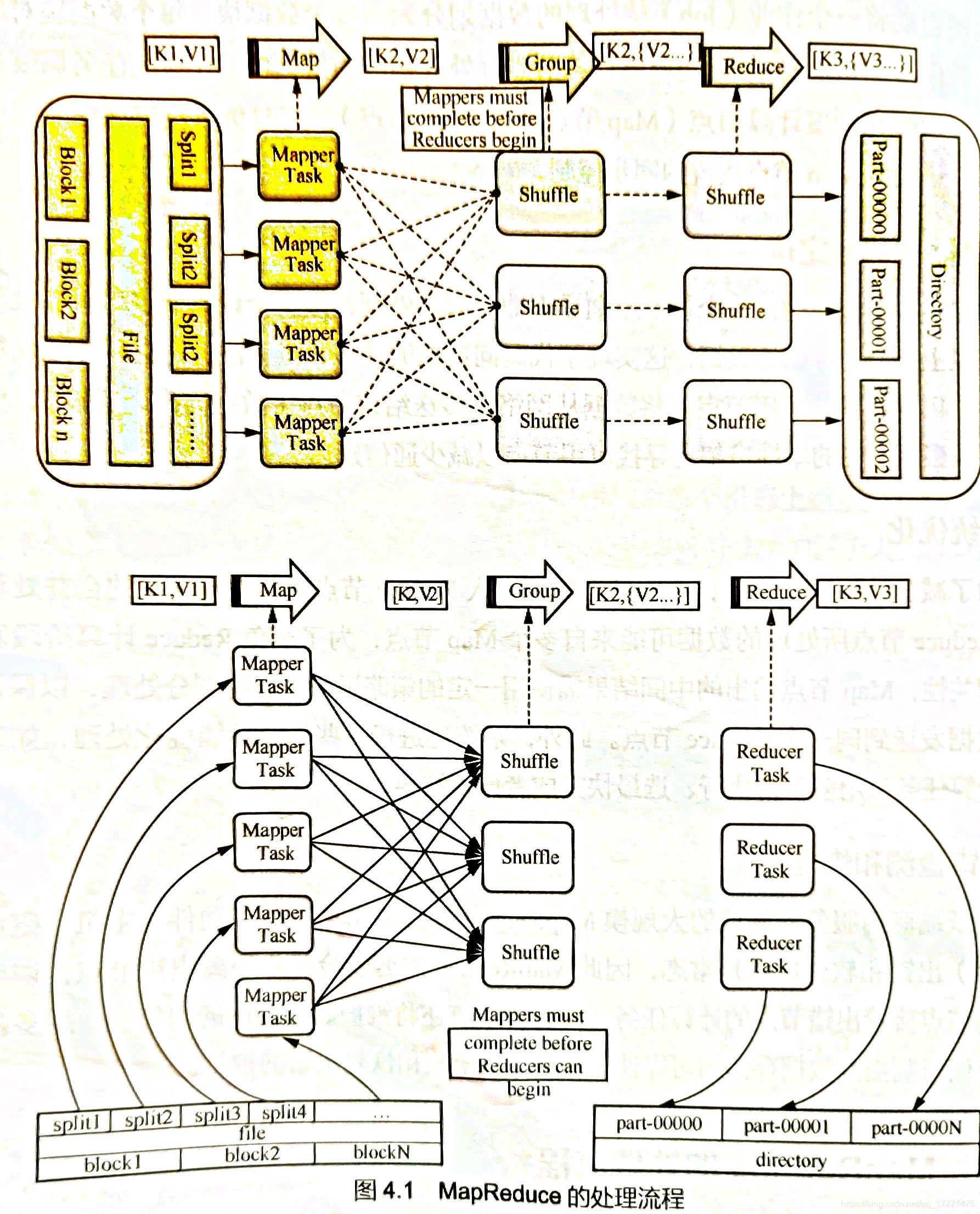
整个MapReduce的处理流程如上图所示。
其中Map是映射,负责数据的过滤分发,将原始数据转化成键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。为了让reduce可以并行处理map的结果,必须对map的输出进行一定的排序与分割,然后再交给对应的reduce,这个将map输出进行进一步整理并交给reduce的过程就是Shuffle。
一个统计单词个数的MapReduce大致流程如下:
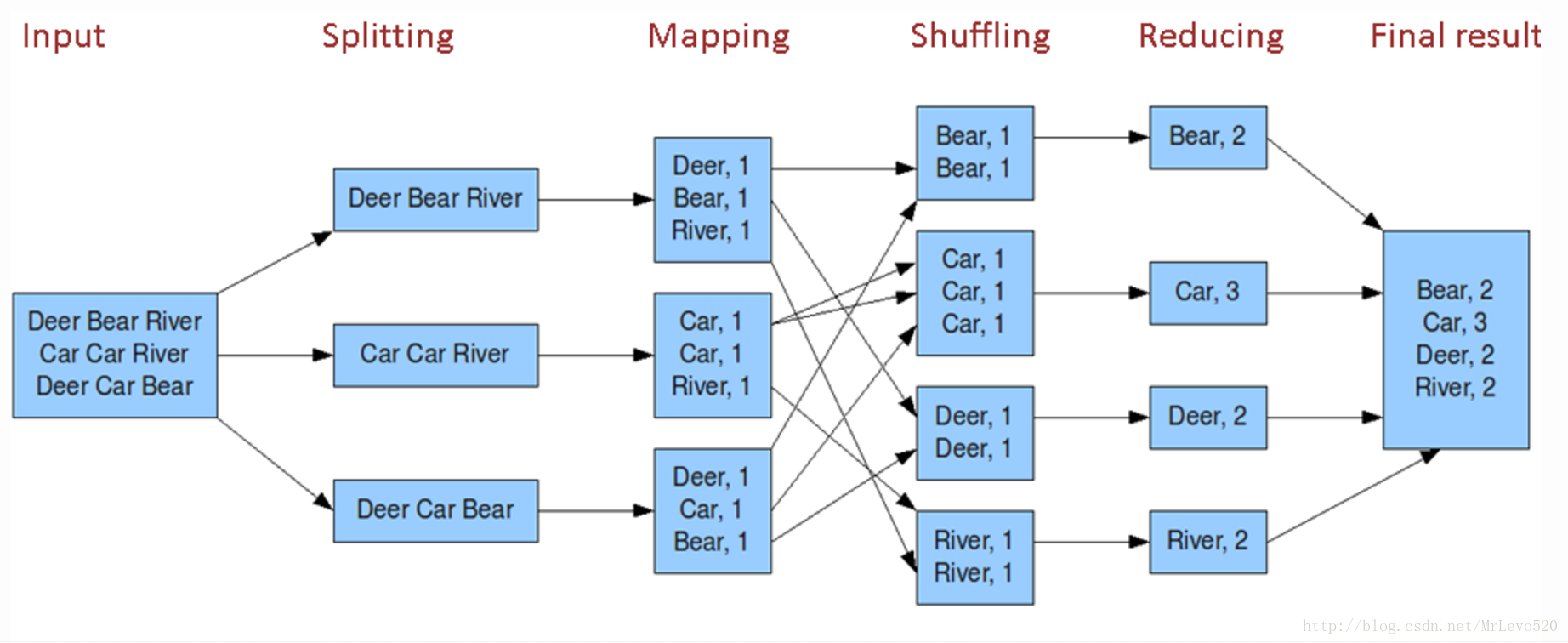
二、MapReduce工作流程之Map阶段
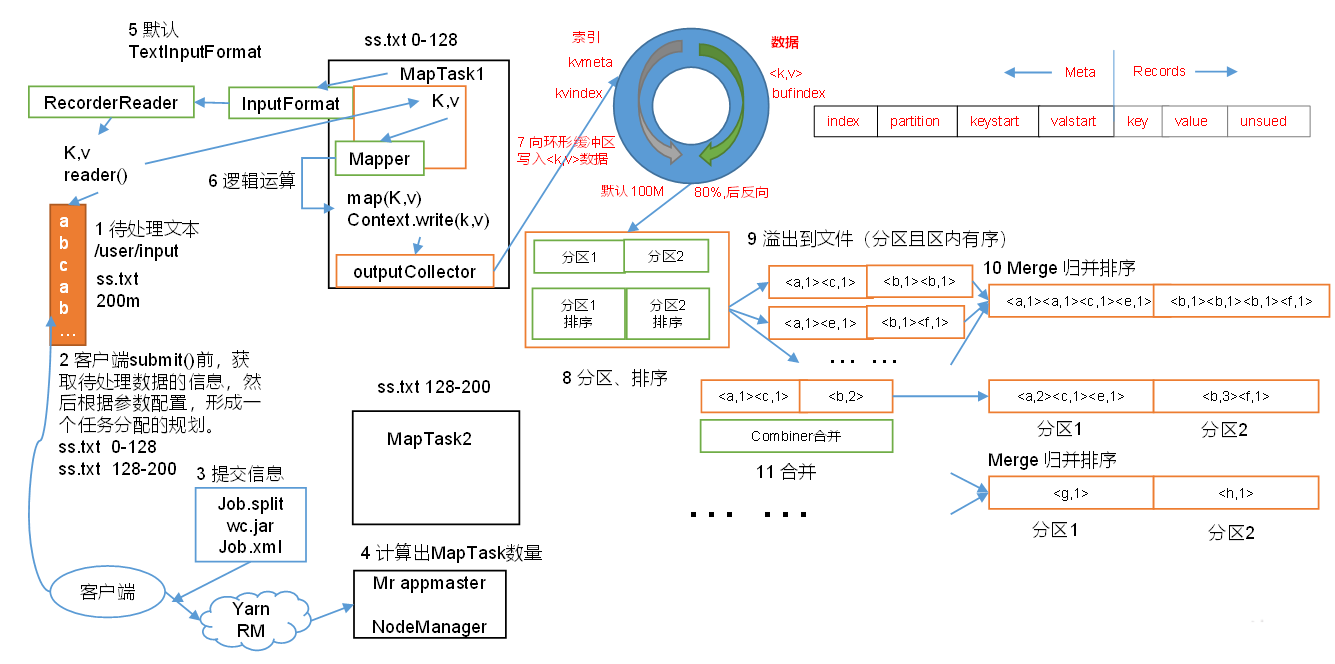
假设有一个待处理的文本文件:ss.txt,大小为200MB。
1. 切片(splitting):Hadoop将MapReduce的输入数据拆分成一些小数据块,称为输入分片(InputSplit)。Hadoop会为每个分片创建一个MapTask,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。这里需要特别注意block和split的区别:block(块)是物理划分,存储文件的具体内容。而split是逻辑划分,只存储文件的元信息(HDFS文件地址、该split的起始位置、该split的文件长度),用于MapTask获取实际文件内容。
将输入数据拆分成输入分片(InputSplit)的类是InputFormat,它的主要作用如下:
- 将输入的数据切分为多个逻辑上的InputSplit,其中每一个InputSplit作为一个map的输入。
- 提供一个RecordReader,用于将InputSplit的内容转换为可以作为map输入的k,v键值对。
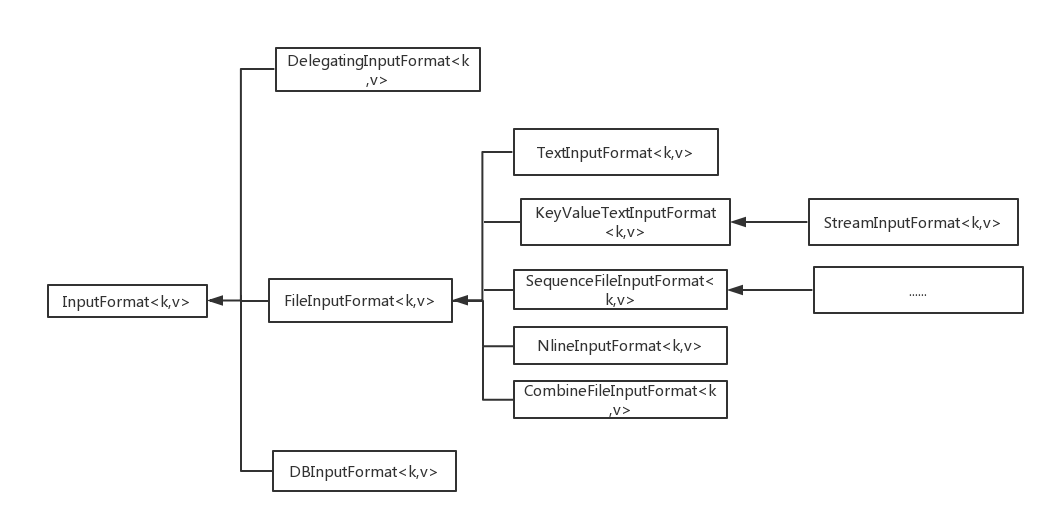
如上图所示,InputFormat是一个抽象类。Hadoop默认使用的是TextInputFormat,并且默认切片大小等同于block大小(128MB),因此ss.txt输入文件在切片时会被分成两个InputSplit:0-128MB和128-200MB。最后,Hadoop会将切片信息写到一个切片规划文件中。
关于InputFormat的扩展阅读:MapReduce InputFormat介绍? ??InputFormat子类介绍
2. 提交(Submit):客户端向Yarn集群提出请求创建Mr appmaster并提交切片等相关信息:job.split、wc.jar(集群模式才需要)、job.xml。Yarn调用ResourceManager来创建Mr appmaster,而Mr appmaster则会根据切片的个数来创建MapTask(等同于InputSplit个数)。
3. Map阶段:到这里,Map阶段才正式开始。
整个MapTask分为Read阶段,Map阶段,Collect阶段,spill(溢写)阶段和combine阶段
- Read阶段:MapTask首先调用InputFormat中的createRecoderReader方法,获取RecordReader。并通过RecordReader从InputSplit中解析出一个个键值对,然后传递给map方法。
- Map阶段:该阶段主要是将解析出的键值对交给用户编写map()函数处理,并产生一系列新的键值对,最终写入本地硬盘(因为Map的输出是中间结果,当Job完成后该结果就会删除,因此没必要存入HDFS)
到此,其实map阶段的逻辑处理已经结束了,我们可以直接将此中间结果传给reduce进行处理。但是为了减少数据通信开销,中间结果数据进入Reduce节点前会进行一定的合并处理。一个Reduce节点所处理的数据一般来着于许多个Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的中间结果需使用一定的策略进行适当的划分处理,以保证相关性数据发送到同一个Reduce节点。此外,系统还进行一些计算性能优化处理,如对最慢的计算任务采用多备份执行,选最快完成者作为结果等。
因此,在将Map阶段产生的中间结果传给Reduce前,我们需要进行Map端的shuffle操作:数据分区、排序和缓存。
- Collect(收集)阶段:在map()函数中,当数据处理完成后,会调用OutputCollector.collect()将生成的数据进行分区(调用Partitioner),并写入一个环形内存缓冲区中。环形缓冲区主要是两部分,一部分写入文件的元数据信息,另一部分写入文件的真实内容。环形缓冲区的默认大小是100MB,当缓冲的容量达到默认大小的80%时,会进行反向溢写。
- 在溢写之前会将缓冲区的数据按照指定的分区规则进行分区和排序,之所以反向溢写是因为这样就可以边接收数据边往磁盘溢写数据
- 在分区和排序之后,溢写到磁盘,可能发生多次溢写,溢写到多个文件
- 对所有溢写到磁盘的文件进行归并排序
- 最后,Hadoop允许用户针对map任务的输出指定一个Combiner(合并),来对每个MapTask的输出进行局部汇总,以减少网络传输量。但是不管调用Combiner几次(0或N次),Reduce的输出结果都是应该一致的。如下,如果要求最大值,那么使用Combiner找出每个map任务输出结果的最大值(局部汇总)是可以的。但是如果是要求平均值,那么使用Combiner去求局部平均值是不对的。
![]()

- Spill(溢写)阶段:当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
三、MapReduce工作流程之Reduce阶段
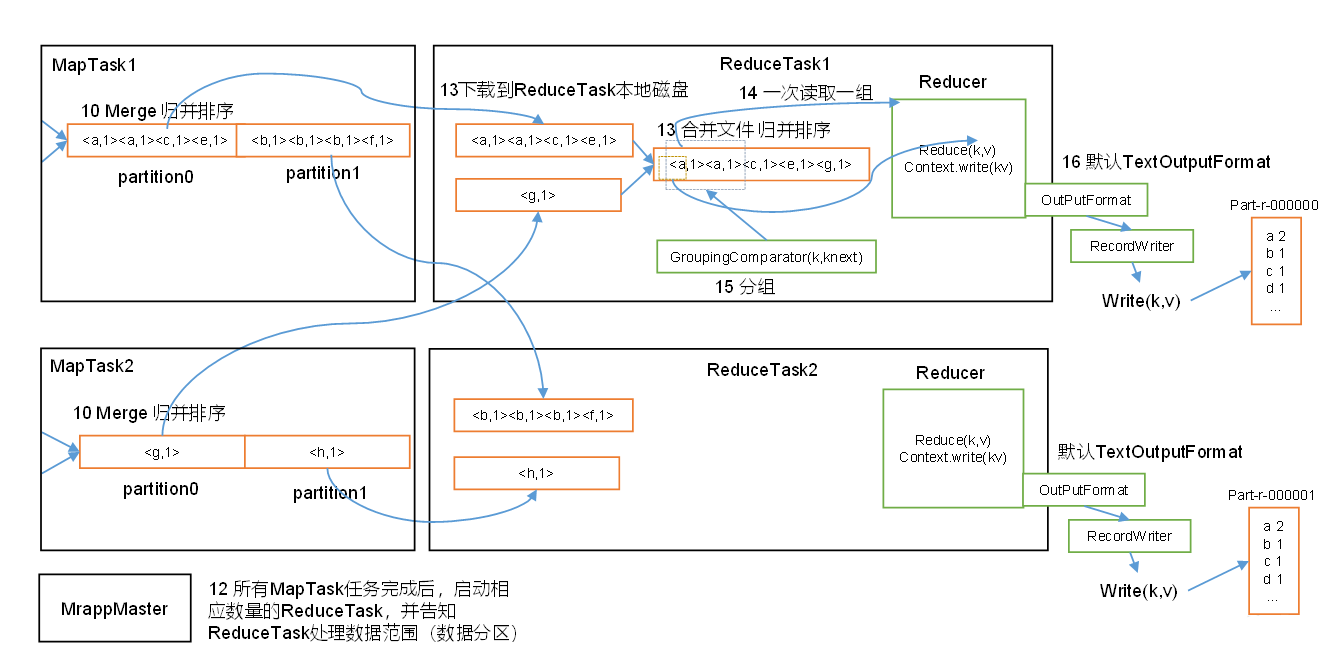
?在所有MapTask任务都完成之后,会根据分区的数量来启动相应数量的ReduceTask,并告知ReduceTask处理的数据范围(即数据分区,有几个数据分区partition就启动几个ReduceTask,每个ReduceTask专门处理同一个分区的数据,比如ReduceTask1专门处理MapTask1中partition0和MapTask2中partition0的数据)
整个ReduceTask可分为Copy阶段,Merge阶段,Sort阶段,Reduce阶段。其中Copy阶段,Merge阶段和Sort阶段属于是Reduce端的shuffle操作。
1. Copy阶段:ReduceTask根据自己的分区号,去各个MapTask机器上拷贝相应分区内的数据到本地内存缓冲区,缓冲区不够的话就溢写到磁盘。
2.?Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3.?Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4.?Reduce阶段:执行reduce()函数,并将最终结果写到HDFS上。
四、参考文献
https://zhuanlan.zhihu.com/p/85666077