kafka的副本管理
kafka实现高可靠性的基础是使用副本机制,具体实现方式是,同一个分区下的多个副本分散在不同的broker机器上,它们保存相同的消息数据以实现高可靠性。下面将谈谈kafka的副本机制。
基础概念
-
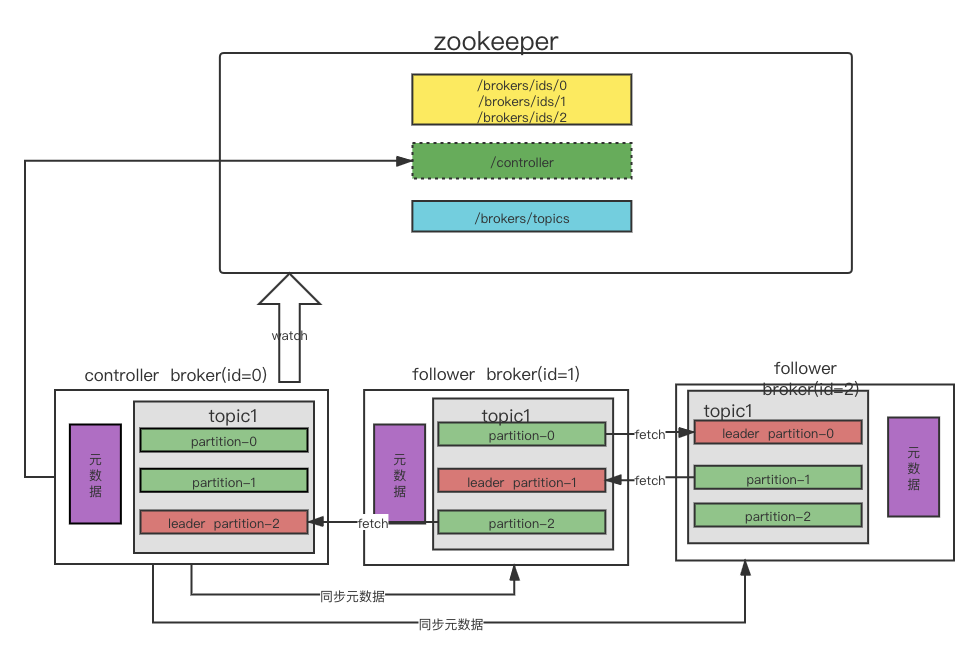
Broker:服务代理节点。对于Kafka而言,Broker可以简单地看作一个独立的Kafka服务节点或Kafka服务实例。大多数情况下也可以将Broker看作一台Kafka服务器,前提是这台服务器上只部署了一个Kafka实例。一个或多个Broker组成了一个Kafka集群。一般而言,我们更习惯使用首字母小写的broker来表示服务代理节点
-
Controller:是Broker的管理节点,在Broker启动的时候会试着在zookeeper上创建controller临时节点,创建成功的Broker就有了Controller的身份。随后会读取zookeeper上的节点信息缓存到本地,并监听一些zookeeper上的brokers、topics、partitions等节点,当监听到相应的变化后会更新本地缓存并发送到其他的follower节点
-
Topic:Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
-
Partition:一个分区只属于单个主题,很多时候也会把分区称为主题分区。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序
-
Replica:kafka通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用
-
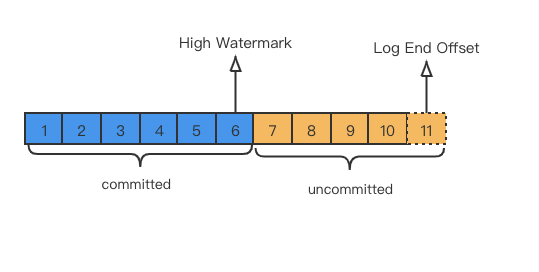
LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=11,那么表示该副本保存了11条消息,位移值范围是[0, 10]
-
HW:即上面提到的水位值。对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所有消息都被认为是“已备份”的(replicated),下图中的hw=6,表示消费者只能消费到6以前的消息
-
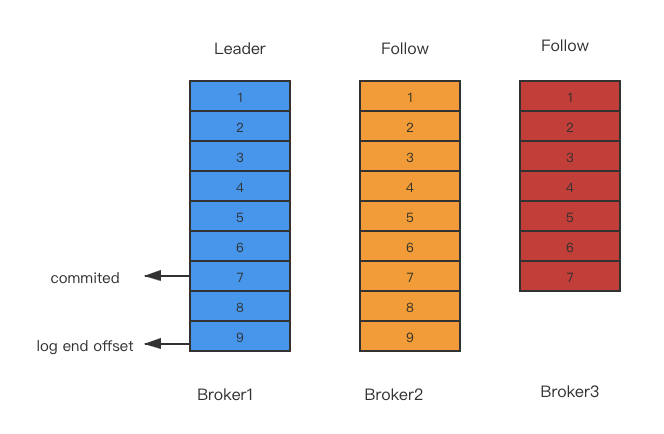
ISR:partition的leader会追踪和维护ISR中所有follower的滞后状态。如果滞后太多(数量滞后和时间滞后两个维度,replica.lag.time.max.ms和replica.lag.max.message可配置),leader会把该replica从ISR中移除。被移除ISR的replica一直在追赶leader。如上图,leader写入数据后并不会commit,只有ISR列表中的所有folower同步之后才会commit,把滞后的follower移除ISR主要是避免写消息延迟。设置ISR主要是为了broker宕掉之后,重新选举partition的leader从ISR列表中选择
ReplicaManage的介绍
ReplicaManager 可以说是 Server 端重要的组成部分,Server 端的多种类型的请求都是调用ReplicaManager 来处理:
- LeaderAndIsr 请求;
- StopReplica 请求;
- UpdateMetadata 请求;
- Produce 请求;
- Fetch 请求;
- ListOffset 请求;
我们将详解这些请求流程
LeaderAndIsr 请求
对于Broker而已,它管理的分区和副本的主要方式是保存哪些是leader副本,哪些是follower副本,但是这些信息不可能一层不变的(当某个broker重启或宕机的时候,该broker下的分区将会重新选举新的分区leader),而这些变更则是通过Controller发送LeaderAndIsr请求到Broker完成的
LeaderAndIsr请求数据:
public class LeaderAndIsrRequestData implements ApiMessage {
int controllerId;
int controllerEpoch;
long brokerEpoch;
byte type;
List<LeaderAndIsrPartitionState> ungroupedPartitionStates;
List<LeaderAndIsrTopicState> topicStates;
List<LeaderAndIsrLiveLeader> liveLeaders;
...
}
public static class LeaderAndIsrPartitionState implements Message {
String topicName;
int partitionIndex;
int controllerEpoch;
int leader;
int leaderEpoch;
List<Integer> isr;
int zkVersion;
List<Integer> replicas;
List<Integer> addingReplicas;
List<Integer> removingReplicas;
}
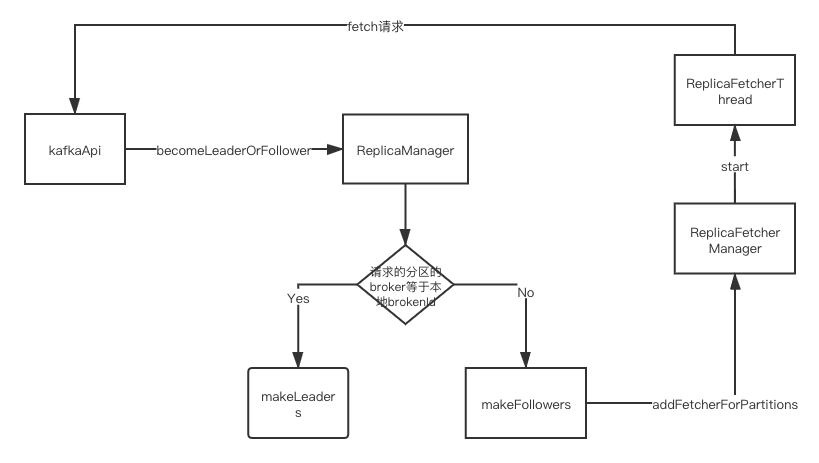
- KafkaApi接受到请求,将做一些校验,校验通过后会调用ReplicaManage的becomeLeaderOrFollower方法
- 在becomeLeaderOrFollower方法里,先做校验请求的controllerEpoch和本地的controllerEpoch大小,如果请求携带的controllerEpoch小于本地的controllerEpoch则拒绝请求(解决脑裂是数据一致性问题)。否则进行过滤在该broker下的leader分区和follower分区(判断的依据LeaderAndIsrPartitionState的leader和localBrokerId是否相等:相等判定为leader否则为follower)
- 分别调用makeLeaders方法对leader的分区处理:停止该分区的fetch线程(因为已经是主分区了),创建相应的日志目录等等操作
- 分别调用makeFollowers方法对follower的分区处理:主要对一些数据的初始化工作和创建同步副本线程ReplicaFetcherThread,ReplicaFetcherThread线程将一直发Fetch请求拉取最新的副本消息,ReplicaFetcherThread的实现细节后面介绍Fetch请求的时候做更详细的介绍
StopReplica 请求
def stopReplicas(correlationId: Int,
controllerId: Int,
controllerEpoch: Int,
brokerEpoch: Long,
partitionStates: Map[TopicPartition, StopReplicaPartitionState]
): (mutable.Map[TopicPartition, Errors], Errors) = {
replicaStateChangeLock synchronized {
val responseMap = new collection.mutable.HashMap[TopicPartition, Errors]
if (controllerEpoch < this.controllerEpoch) {
stateChangeLogger.warn(s"Ignoring StopReplica request from " +
s"controller $controllerId with correlation id $correlationId " +
s"since its controller epoch $controllerEpoch is old. " +
s"Latest known controller epoch is ${this.controllerEpoch}")
(responseMap, Errors.STALE_CONTROLLER_EPOCH)
} else {
this.controllerEpoch = controllerEpoch
...
stopPartitions(stoppedPartitions).foreach { case (topicPartition, e) =>
if (e.isInstanceOf[KafkaStorageException]) {
stateChangeLogger.error(s"Ignoring StopReplica request (delete=true) from " +
s"controller $controllerId with correlation id $correlationId " +
s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +
"partition is in an offline log directory")
} else {
stateChangeLogger.error(s"Ignoring StopReplica request (delete=true) from " +
s"controller $controllerId with correlation id $correlationId " +
s"epoch $controllerEpoch for partition $topicPartition due to an unexpected " +
s"${e.getClass.getName} exception: ${e.getMessage}")
responseMap.put(topicPartition, Errors.forException(e))
}
responseMap.put(topicPartition, Errors.forException(e))
}
(responseMap, Errors.NONE)
}
}
}
protected def stopPartitions(partitionsToStop: Map[TopicPartition, Boolean]): Map[TopicPartition, Throwable] = {
// First stop fetchers for all partitions.
val partitions = partitionsToStop.keySet
replicaFetcherManager.removeFetcherForPartitions(partitions)
replicaAlterLogDirsManager.removeFetcherForPartitions(partitions)
// Second remove deleted partitions from the partition map. Fetchers rely on the
// ReplicaManager to get Partition's information so they must be stopped first.
val partitionsToDelete = mutable.Set.empty[TopicPartition]
partitionsToStop.forKeyValue { (topicPartition, shouldDelete) =>
if (shouldDelete) {
getPartition(topicPartition) match {
case hostedPartition: NonOffline =>
if (allPartitions.remove(topicPartition, hostedPartition)) {
maybeRemoveTopicMetrics(topicPartition.topic)
// Logs are not deleted here. They are deleted in a single batch later on.
// This is done to avoid having to checkpoint for every deletions.
hostedPartition.partition.delete()
}
}
partitionsToDelete += topicPartition
}
completeDelayedFetchOrProduceRequests(topicPartition)
}
// Third delete the logs and checkpoint.
val errorMap = new mutable.HashMap[TopicPartition, Throwable]()
if (partitionsToDelete.nonEmpty) {
// Delete the logs and checkpoint.
logManager.asyncDelete(partitionsToDelete, (tp, e) => errorMap.put(tp, e))
}
errorMap
}
- KafkaApi接受到请求,将做一些校验,校验通过后会调用ReplicaManage的stopReplicas方法
- 同LeaderAndIsr请求的第二步一样
- 过滤掉需要真正暂停副本同步的分区(有可能该broker已经没有进行同步工作了)
- 移除该分区的fetch线程
- 如果该分区需要删除,则异步删除日志等
UpdateMetadata 请求
UpdateMetadata 请求主要controller监听到元数据变化了,通知其他非controller的broker更新数据,使集群的broker的元数据保持一致
Produce 请求
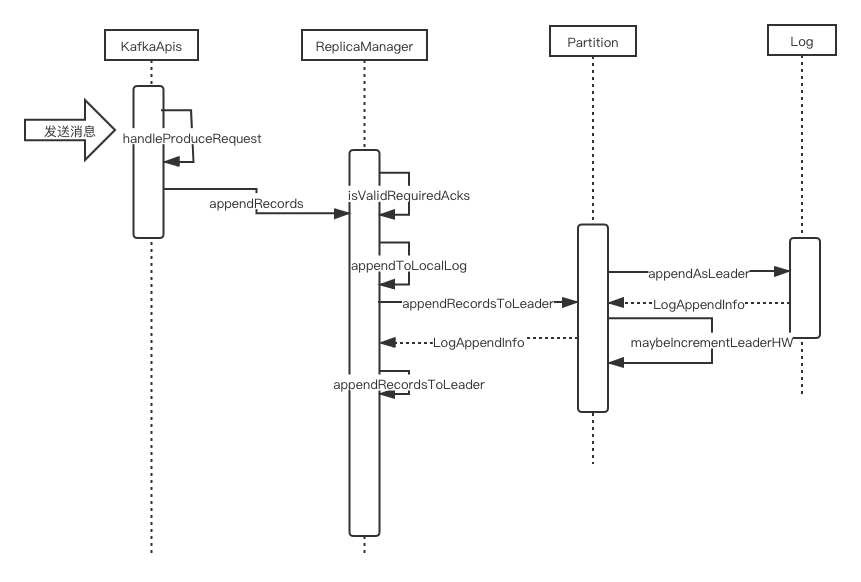
- KafkaAp接受到producer请求,并调用ReplicaManager的appendRecords处理
- appendRecords方法首先调用isValidRequiredAcks校验ack的方式是否正确,目前kafka只支持0,1,-1三个值。0:表示不需要producer不等待broker同步完成的确认,继续发送下一条(批)信息,1:表示需要等待leader成功收到数据并得到确认,才发送下一条(批)消息,-1:表示需要所有的副本接受到消息确认后才发送下一条(批)消息。当appendToLocalLog方法正确返回并且ack=-1的时候,ack=-1表示所有副本都要复制该消息才能回复给生产者。kafka这块的处理方式是构建DelayedProduce延迟生产的对象,并把该对象加到时间轮里,所有副本都拉取到该消息或时间到期后才会触发回复生产者。
def appendRecords(timeout: Long,
requiredAcks: Short,
internalTopicsAllowed: Boolean,
origin: AppendOrigin,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
responseCallback: Map[TopicPartition, PartitionResponse] => Unit,
delayedProduceLock: Option[Lock] = None,
recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()): Unit = {
if (isValidRequiredAcks(requiredAcks)) {
val sTime = time.milliseconds
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, entriesPerPartition, requiredAcks)
debug("Produce to local log in %d ms".format(time.milliseconds - sTime))
...
if (delayedProduceRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)) {
// create delayed produce operation
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
val producerRequestKeys = entriesPerPartition.keys.map(TopicPartitionOperationKey(_)).toSeq
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
} else {
// we can respond immediately
val produceResponseStatus = produceStatus.map { case (k, status) => k -> status.responseStatus }
responseCallback(produceResponseStatus)
}
...
}
private def isValidRequiredAcks(requiredAcks: Short): Boolean = {
requiredAcks == -1 || requiredAcks == 1 || requiredAcks == 0
}
def tryCompleteElseWatch(operation: T, watchKeys: Seq[Any]): Boolean = {
if (operation.safeTryCompleteOrElse {
watchKeys.foreach(key => watchForOperation(key, operation))
if (watchKeys.nonEmpty) estimatedTotalOperations.incrementAndGet()
}) return true
// if it cannot be completed by now and hence is watched, add to the expire queue also
if (!operation.isCompleted) {
if (timerEnabled)
timeoutTimer.add(operation)//加入到时间轮
if (operation.isCompleted) {
// cancel the timer task
operation.cancel()
}
}
false
}
-
appendToLocalLog方法主要是根据发送的主题分区的信息找到相应的partition,并调用partition的appendRecordsToLeader方法
-
appendRecordsToLeader方法中,当ack是-1的时候并且当前isr的集合大小小于要求最小同步副本数的时候,则会抛出异常NotEnoughReplicasException。否则则调用日志类的appendAsLeader把日志追加到xxx.log里面,如果成功写入文件返回LogAppendInfo
def appendRecordsToLeader(records: MemoryRecords, origin: AppendOrigin, requiredAcks: Int): LogAppendInfo = {
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderLogIfLocal match {
case Some(leaderLog) =>
val minIsr = leaderLog.config.minInSyncReplicas
val inSyncSize = isrState.isr.size
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException(s"The size of the current ISR ${isrState.isr} " +
s"is insufficient to satisfy the min.isr requirement of $minIsr for partition $topicPartition")
}
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion)
(info, maybeIncrementLeaderHW(leaderLog))
case None =>
throw new NotLeaderOrFollowerException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}
info.copy(leaderHwChange = if (leaderHWIncremented) LeaderHwChange.Increased else LeaderHwChange.Same)
}
- 当消息成功写入log文件后,会调用partition的maybeIncrementLeaderHW方法,maybeIncrementLeaderHW大体上是遍历所有的副本找到最小的log end offset(LEO)如果该最小LEO比当前的HighWatermark大则更新Leader的HighWatermark
private def maybeIncrementLeaderHW(leaderLog: Log, curTime: Long = time.milliseconds): Boolean = {
// maybeIncrementLeaderHW is in the hot path, the following code is written to
// avoid unnecessary collection generation
var newHighWatermark = leaderLog.logEndOffsetMetadata
remoteReplicasMap.values.foreach { replica =>
// Note here we are using the "maximal", see explanation above
if (replica.logEndOffsetMetadata.messageOffset < newHighWatermark.messageOffset &&
(curTime - replica.lastCaughtUpTimeMs <= replicaLagTimeMaxMs || isrState.maximalIsr.contains(replica.brokerId))) {
newHighWatermark = replica.logEndOffsetMetadata
}
}
leaderLog.maybeIncrementHighWatermark(newHighWatermark) match {
case Some(oldHighWatermark) =>
debug(s"High watermark updated from $oldHighWatermark to $newHighWatermark")
true
case None =>
def logEndOffsetString: ((Int, LogOffsetMetadata)) => String = {
case (brokerId, logEndOffsetMetadata) => s"replica $brokerId: $logEndOffsetMetadata"
}
if (isTraceEnabled) {
val replicaInfo = remoteReplicas.map(replica => (replica.brokerId, replica.logEndOffsetMetadata)).toSet
val localLogInfo = (localBrokerId, localLogOrException.logEndOffsetMetadata)
trace(s"Skipping update high watermark since new hw $newHighWatermark is not larger than old value. " +
s"All current LEOs are ${(replicaInfo + localLogInfo).map(logEndOffsetString)}")
}
false
}
}
Fetch 请求
在上面LeaderAndIsr 请求的时候提到,ReplicaManager接受到请求后,如果分区的leader的brokerId和本地的不一样,则改broker就是这个分区的follow副本,则会启动ReplicaFetcherThread线程不断发送fetch请求同步leader副本的数据。
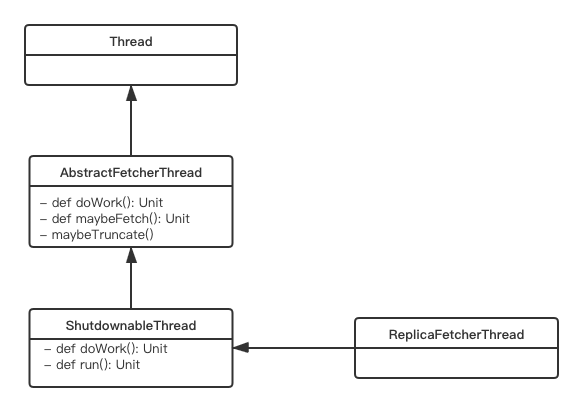
上面是ReplicaFetchThread的继承图,ReplicaFetcherThread继承了ShutdownableThread,ShutdownableThread继承了AbstractFetcherThread类,其中AbstractFetcherThread实现了Thread的run方法
----------ShutdownableThread----------------------------------
def doWork(): Unit
override def run(): Unit = {
isStarted = true
info("Starting")
try {
while (isRunning)
doWork()//一直循环执行doWork,其中doWork是抽象方法,其实现在AbstractFetcherThread
} catch {
case e: FatalExitError =>
shutdownInitiated.countDown()
shutdownComplete.countDown()
info("Stopped")
Exit.exit(e.statusCode())
case e: Throwable =>
if (isRunning)
error("Error due to", e)
} finally {
shutdownComplete.countDown()
}
info("Stopped")
}
-----------AbstractFetcherThread--------------------------
override def doWork(): Unit = {
maybeTruncate()//截取日志
maybeFetch() //向远程的leader分区拉取日志
}
可以理解ReplicaFetcherThread就一直处理截断日志和拉取远程leader的分区日志数据的过程
截断日志
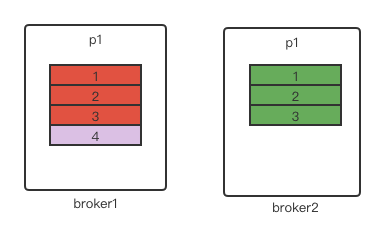
为了保证副本之间数据的一致性,kafka会进行日志截断操作,例如下图中的场景broker1是p1的leader,broker2是p1的follower:其中消息1、2、3这个消息都被成功写入并被broker2复制成功,此时生产者发送消息4过来,broker1刚写入到日志文件来没有等到broker2同步完就宕机了,随后broker2重新被选举为p1的leader。当broker1重启成为p1的follower时,消息4在broker1上存在但是在broker2上不存在这样就导致副本的数据不一致。所以kafka就在拉取日志的时候会先做截断日志的处理来保证副本的数据一致。
private def maybeTruncate(): Unit = {
val (partitionsWithEpochs, partitionsWithoutEpochs) = fetchTruncatingPartitions()
if (partitionsWithEpochs.nonEmpty) {
truncateToEpochEndOffsets(partitionsWithEpochs)
}
if (partitionsWithoutEpochs.nonEmpty) {
truncateToHighWatermark(partitionsWithoutEpochs)
}
}
private def truncateToEpochEndOffsets(latestEpochsForPartitions: Map[TopicPartition, EpochData]): Unit = {
val endOffsets = fetchEpochEndOffsets(latestEpochsForPartitions)//向远程leader partition 拉取罪行的endOffsets
//Ensure we hold a lock during truncation.
inLock(partitionMapLock) {
//Check no leadership and no leader epoch changes happened whilst we were unlocked, fetching epochs
val epochEndOffsets = endOffsets.filter { case (tp, _) =>
val curPartitionState = partitionStates.stateValue(tp)
val partitionEpochRequest = latestEpochsForPartitions.getOrElse(tp, {
throw new IllegalStateException(
s"Leader replied with partition $tp not requested in OffsetsForLeaderEpoch request")
})
val leaderEpochInRequest = partitionEpochRequest.currentLeaderEpoch
curPartitionState != null && leaderEpochInRequest == curPartitionState.currentLeaderEpoch
}
val ResultWithPartitions(fetchOffsets, partitionsWithError) = maybeTruncateToEpochEndOffsets(epochEndOffsets, latestEpochsForPartitions)
handlePartitionsWithErrors(partitionsWithError, "truncateToEpochEndOffsets")
updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)
}
}
- 一:对分区进行是否有epoch进行分组为partitionsWithEpochs、partitionsWithoutEpochs
- 二:对有epoch的分区进行处理:
- 1:向远程的leader partition拉取endoffset
- 2:根据leader的endOffset和本地的endOffset进行对比,取出最小的endOffset
- 3: 对本地的日志文件进行截断操作(截断到步骤2比较出的min的endOffset),这些包括了日志文件,offsetIndex文件,timeIndex文件,txnIndex文件等文件做相应的截断
- 三:对无epoch的分区进行处理,如果本地没有该分区的状态记录的话,则不做任何处理,否则对未提交的日志做全部截断操作(即截断到highWatermark)
Fetch主分区的日志
同步主分区的日志数据我们分客户端的处理(即follower分区的处理)和服务端处理(即leader分区的处理)
客户端处理
public FetchRequest build(short version) {
if (version < 3) {
maxBytes = DEFAULT_RESPONSE_MAX_BYTES;
}
FetchRequestData fetchRequestData = new FetchRequestData();
fetchRequestData.setReplicaId(replicaId);
fetchRequestData.setMaxWaitMs(maxWait);//最多等待的时候,如果leader没有数据会等待一段时间在拉取数据
fetchRequestData.setMinBytes(minBytes);//为了保证拉取的性能,这里会做赞批处理
fetchRequestData.setMaxBytes(maxBytes);//如果延迟的消息过多,则会分多长拉取同步消息
......
FetchRequestData.FetchPartition fetchPartition = new FetchRequestData.FetchPartition()
.setPartition(topicPartition.partition())
.setCurrentLeaderEpoch(partitionData.currentLeaderEpoch.orElse(RecordBatch.NO_PARTITION_LEADER_EPOCH))//当前的leaderEpoch
.setLastFetchedEpoch(partitionData.lastFetchedEpoch.orElse(RecordBatch.NO_PARTITION_LEADER_EPOCH))
.setFetchOffset(partitionData.fetchOffset)//拉取的offset
.setLogStartOffset(partitionData.logStartOffset)//lso
.setPartitionMaxBytes(partitionData.maxBytes);
fetchTopic.partitions().add(fetchPartition);
}
.....
return new FetchRequest(fetchRequestData, version);
}
- 1:构建拉取副本数据请求体,从上面部分代码可以看到请求体有maxWait(最大等到时间),minBytes(最小字节树),maxBytes(最大字节树),fetchOffset(该副本已经同步消息的位置),leaderEpoch等重要参数
- 2:发送请求
- 3: 如果有同步的消息数据,则进行写消息处理(处理逻辑基本上和主分区处理生产者发送消息一致ReplicaFetcherThread->Partition->Log->LogSegment)
--------------processFetchRequest------------------------------------
if (responseData.nonEmpty) {
// process fetched data
inLock(partitionMapLock) {
responseData.forKeyValue { (topicPartition, partitionData) =>
Option(partitionStates.stateValue(topicPartition)).foreach { currentFetchState =>
// It's possible that a partition is removed and re-added or truncated when there is a pending fetch request.
// In this case, we only want to process the fetch response if the partition state is ready for fetch and
// the current offset is the same as the offset requested.
val fetchPartitionData = sessionPartitions.get(topicPartition)
if (fetchPartitionData != null && fetchPartitionData.fetchOffset == currentFetchState.fetchOffset && currentFetchState.isReadyForFetch) {
partitionData.error match {
case Errors.NONE =>
try {
// Once we hand off the partition data to the subclass, we can't mess with it any more in this thread
val logAppendInfoOpt = processPartitionData(topicPartition, currentFetchState.fetchOffset,
partitionData)//如果有同步的消息数据,则进行写消息处理
logAppendInfoOpt.foreach { logAppendInfo =>
val validBytes = logAppendInfo.validBytes
val nextOffset = if (validBytes > 0) logAppendInfo.lastOffset + 1 else currentFetchState.fetchOffset
val lag = Math.max(0L, partitionData.highWatermark - nextOffset)
fetcherLagStats.getAndMaybePut(topicPartition).lag = lag
服务端处理
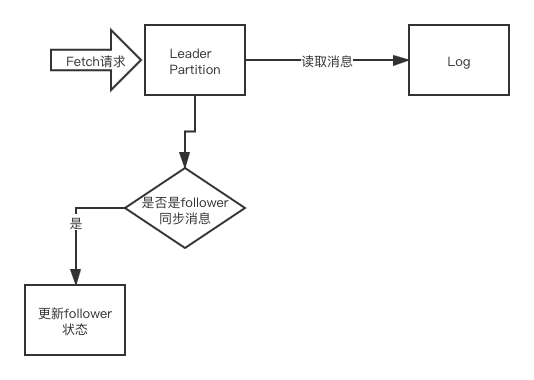
- 1:主分区接受到fetch请求以后,则更加请求的参数找到相应的分区
- 2:根据请求参数maxWait(最大等到时间),minBytes(最小字节数),maxBytes(最大字节数),fetchOffset(该副本已经同步消息的位置),leaderEpoch等,进行读取消息日志。
- 如果没有消息可以拉取,则进入定时任务等待有数据或者maxWait在响应客户端
- 如果消息大小小于minBytes长度,也加入到定时任务等待足够的消息在响应客户端
- 如果消息太多(刚加入的的副本等情况),会取长度不大于maxBytes的消息树
- 3:读取到相应的的消息日志以后,如果是follower拉取消息则会做updateFollowerFetchState操作
- 1、更新相应副本 followerFetchOffsetMetadata、leaderEndOffset、 followerFetchTimeMs元数据
- 2、maybeExpandIsr检查是否需要isr扩容,如果该副本的不在isr集合中,并且该副本的endOffset大于主分区的水位线highWatermark,则会进行扩容,把该副本brokerId添加到isr集合中,并把相应的元数据写到zookeeper上
- 3、maybeIncrementLeaderHW判断是否需要跟新highWatermark的值,遍历所有的副本取出在isr集合中并且最小的LEO值(为什么是最小的?最小的LEO表明之前的消息在其他isr副本中已经同步完成)并且大于主分区的highWatermark则进行跟新水位线
def updateFollowerFetchState(followerId: Int,
followerFetchOffsetMetadata: LogOffsetMetadata,
followerStartOffset: Long,
followerFetchTimeMs: Long,
leaderEndOffset: Long): Boolean = {
getReplica(followerId) match {
case Some(followerReplica) =>
val oldLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L
val prevFollowerEndOffset = followerReplica.logEndOffset
followerReplica.updateFetchState(
followerFetchOffsetMetadata,
followerStartOffset,
followerFetchTimeMs,
leaderEndOffset)
val newLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L
val leaderLWIncremented = newLeaderLW > oldLeaderLW
maybeExpandIsr(followerReplica, followerFetchTimeMs)
val leaderHWIncremented = if (prevFollowerEndOffset != followerReplica.logEndOffset) {
inReadLock(leaderIsrUpdateLock) {
leaderLogIfLocal.exists(leaderLog => maybeIncrementLeaderHW(leaderLog, followerFetchTimeMs))
}
} else {
false
}
if (leaderLWIncremented || leaderHWIncremented)
tryCompleteDelayedRequests()
true
case None =>
false
}
}
private def maybeIncrementLeaderHW(leaderLog: Log, curTime: Long = time.milliseconds): Boolean = {
// maybeIncrementLeaderHW is in the hot path, the following code is written to
// avoid unnecessary collection generation
var newHighWatermark = leaderLog.logEndOffsetMetadata
remoteReplicasMap.values.foreach { replica =>
// Note here we are using the "maximal", see explanation above
if (replica.logEndOffsetMetadata.messageOffset < newHighWatermark.messageOffset &&
(curTime - replica.lastCaughtUpTimeMs <= replicaLagTimeMaxMs || isrState.maximalIsr.contains(replica.brokerId))) {
newHighWatermark = replica.logEndOffsetMetadata
}
}
leaderLog.maybeIncrementHighWatermark(newHighWatermark) match {
case Some(oldHighWatermark) =>
debug(s"High watermark updated from $oldHighWatermark to $newHighWatermark")
true
case None =>
def logEndOffsetString: ((Int, LogOffsetMetadata)) => String = {
case (brokerId, logEndOffsetMetadata) => s"replica $brokerId: $logEndOffsetMetadata"
}
if (isTraceEnabled) {
val replicaInfo = remoteReplicas.map(replica => (replica.brokerId, replica.logEndOffsetMetadata)).toSet
val localLogInfo = (localBrokerId, localLogOrException.logEndOffsetMetadata)
trace(s"Skipping update high watermark since new hw $newHighWatermark is not larger than old value. " +
s"All current LEOs are ${(replicaInfo + localLogInfo).map(logEndOffsetString)}")
}
false
}
}
参考:深入理解Kafka:核心设计和实践原理