�ġ�HQL(hive SQL)
(��)DML���ݲ�������
1.���ݵ���:
(1)ֱ���ϴ�����
--��ʱ��
û�б��ļ�Ŀ¼,���ϴ�
--�ڲ���
hadoop fs -put emp.txt /user/hive/warehouse/ningxw.db/managed_emp01/aaa.txt
--��ѯ��������
select * from managed_emp01;
--�ⲿ��
hadoop fs -put emp.txt /user/hive/warehouse/ningxw.db/external_emp01
select * from external_emp01;
--������
--��������
hadoop fs -put emp.txt /user/hive/warehouse/ningxw.db/partition_emp/age=20/
select * from partition_emp;
--�༶����
hadoop fs -put emp.txt /user/hive/warehouse/ningxw.db/partition_emp2/month=5/day=20
select * from partition_emp2;
ע��:����������������,�ֶ����������ֶ�Ŀ¼(mkdir),���ϴ����ݺ�,
��Ҫ�����ſ�����
msck repair table tabName; --���������
--��Ͱ��
hadoop fs -put emp.txt /user/hive/warehouse/ningxw.db/buck_emp
select * from buck_emp;
������HDFS�ϵ��ļ�Ŀ¼��,��û�зֳɶ���ļ�,Ҳ���Dz�û�а���
ָ���ֶν��з�Ͱ
(2)�����װ������(Load)
�:load data [local] inpath 'path/target.log' [overwrite] into table tab [partition (partcol1=val1,��)];
˵��:
load data:��ʾ��������
local:��ʾ��(����������Ľڵ�)���ؼ������ݵ�hive��;�����HDFS�������ݵ�hive��
inpath:��ʾ�������ݵ�·��
overwrite:��ʾ���DZ�����������,�����ʾ��
into table:��ʾ���ص����ű�
tab:��ʾ����ı���
partition:��ʾ�ϴ���ָ������
ʾ��:
--Ϊ��ʱ����������
load data local inpath "/home/ningxw/tmp/emp.txt" into table temporary_emp;
select * from temporary_emp;
--Ϊ�ڲ�����������
load data local inpath "/home/ningxw/tmp/emp.txt" into table managed_emp01;
load data local inpath "/home/ningxw/tmp/emp.txt" overwrite into table managed_emp01;
select * from managed_emp01;
--Ϊ�ⲿ����������
load data local inpath "/home/ningxw/tmp/emp.txt" into table external_emp01;
select * from external_emp01;
--��������������(������)
load data local inpath "/home/ningxw/tmp/emp.txt" into table partition_emp
partition(age=18);
select * from partition_emp;
--Ϊ��������������(�༶����)
load data local inpath "/home/ningxw/tmp/emp.txt" into table partition_emp2 partition(month="05",day="20");
--Ϊ��Ͱ����������
load data local inpath "/home/ningxw/tmp/emp.txt" into table buck_emp;
hadoop fs -put emp.txt /test/
load data inpath "/test/emp.txt" into table buck_emp;
select * from buck_emp;
(3)ͨ����ѯ�������в�������(Insert)
(3.1)insert values
�:
insert into table tab [partition (partcol1[=val1], partcol2[=val2] ...)] values (value [, value ...])
ʾ��:
--��ʱ��
insert into table temporary_emp(id,name) values(1,"hadoop");
select * from temporary_emp;
--�ڲ���
insert into table managed_emp01(id,name) values(1,"hadoop");
select * from managed_emp01;
--�ⲿ��
insert into table external_emp01(id,name) values(1,"hadoop");
select * from external_emp01;
--������
insert into table partition_emp(id,name,age) values(1,"hadoop",18);
select * from partition_emp;
insert into table partition_emp2(id,name,month,day) values(1,"hadoop",5,20);
select * from partition_emp2;
insert into table partition_emp partition(age=20) values(2,"saprk"); --��������
insert into table partition_emp2 partition(month=7,day=13) values(2,"spark",5); --�༶����
--��Ͱ��
insert into table buck_emp(id,name) values(1,"hadoop");
select * from buck_emp;
(3.2)insert select
�:
insert overwrite table tablename [partition (partcol1=val1, partcol2=val2 ...)] select_statement1 from from_statement;
insert into table tablename [partition (partcol1=val1, partcol2=val2 ...)] select_statement1 from from_statement;
ʾ��:
--��ʱ��
insert overwrite table temporary_emp select * from emp02;
select * from temporary_emp;
--�ڲ���
insert into table managed_emp01 select * from emp02;
select * from managed_emp01;
--�ⲿ��
insert into table external_emp01 select * from emp02;
select * from external_emp01;
--������
insert into table partition_emp partition(age=45) select * from emp02;
select * from partition_emp;
insert into table partition_emp2 partition(month="3",day="18")
select * from emp02; --�ᱨ��
[X �жԲ���]
insert into table partition_emp2 partition(month="3",day="18")
select * from partition_emp; --��ʱ���ᱨ��
select * from partition_emp2; --�����鿴����
--��Ͱ��
Hive3.x֮ǰ�汾,��Ҫ�������²���:
set hive.enforce.bucketing=true;--������Ͱ����
set hive.enforce.sorting=true;--�����������
insert into table buck_emp select * from partition_emp;
select * from buck_emp;
(3.3)���ز���
�:
from from_statement
insert overwrite table tab [partition (partcol1=val1, partcol2=val2 ...)]
select_statement1
[insert overwrite table tab2 [partition ...] select_statement2]
[insert into table tab2 [partition ...] select_statement2];
˵��:��������Ҫ��һ�ű��еIJ������ݷֱ������ű�ʱ,�Ϳ���ʹ�ö��ز���
ʾ��:
��partition_emp���еIJ������ݷֱ��滻�����뵽managed_emp01��external_emp01����:
from partition_emp
insert overwrite table managed_emp01
select id,name
insert into table external_emp01
select id,name;
(3.4)��̬����
�:
insert overwrite table tablename partition (partcol1[=val1], partcol2[=val2] ...)
select_statement from from_statement;
insert into table tablename partition (partcol1[=val1], partcol2[=val2] ...)
select_statement from from_statement;
˵��:
��hive�������в�������ʱ,�����Ҫ�����ķ����ܶ�,�����Ա���ij���ֶ�
���з����洢,����Ҫ����ճ���ĺܶ�sqlȥִ��,Ч�ʵ͡�
��Ϊhive��������ϵͳ,����hive�ṩ��һ����̬��������
ʾ��:
--���÷��ϸ�ģʽ
set hive.exec.dynamic.partition.mode=nonstrict;
--������̬������
create table dynamic_emp(
id int)
partitioned by (name string)
row format delimited fields terminated by '\t';
--��̬��������
insert overwrite table dynamic_emp partition(name)
select id,name from managed_emp01;
--�鿴ȫ������
show partitions dynamic_emp;
(3.5)CTE����ʽ
�:
CTE(Common Table Expression) ���ñ�����ʽ,�����ڵ�������ִ�з�Χ��
�������ʱ�����,ֻ�ڲ�ѯ�ڼ���Ч,������������,Ҳ����ͬһ��ѯ�ж������,
ʵ���˴���ε��ظ�����.
CTE���ĺô�������SQL�Ŀɶ���,���Ը������ż��ķ�ʽʵ�ֵݹ�ȸ��ӵIJ�ѯ
�÷�ʾ��:
--ѡ������е�CTE
with t1 as (select name from emp01 where emp01.id=2)
select * from t1;
-- from���
with t1 as (select name from emp01 where emp01.id=2)
from t1 select *;
-- ����ʽ
with t1 as ( select * from emp01 where emp01.id=2),
t2 as ( select name from t1)
select * from (select name from t2) haha;
-- union����
with t1 as (select * from emp01 where emp01.id=2),
t2 as (select * from emp01 where emp01.id=3)
select * from t1 union all select * from t2;
-- ��������
create table emp03 like emp01;
with t1 as ( select * from emp01 where emp01.id=2)
from t1
insert overwrite table emp03 --�Ա�emp03���в�������
select *;
select * from emp03; --��ѯ�²������ݵı�
-- ������
create table emp05 as
with t1 as ( select * from emp01 where emp01.id=2)
select * from t1;
select * from emp05; --�鿴�����ı�emp05����û������
(4)������ʱͨ��Locationָ����������·��
create table if not exists emp4(
id int, name string
)
row format delimited fields terminated by '\t'
location '/test';
(5)Import���ݵ�ָ��Hive����
create table if not exists emp5(
id int, name string
)row format delimited fields terminated by '\t';
import table emp5 from '/test/';
ע��:�Ƚ����ݵ���,�ٽ��е���
2�����ݵ���
(1)Insert����
(1.1)����ѯ�Ľ������������
insert overwrite local directory '/home/ningxw/tmp/export/emp'
select * from managed_emp01;
(1.2)����ѯ�Ľ����ʽ������������
insert overwrite local directory '/home/offcn/tmp/export/emp2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from managed_emp01;
(1.3)����ѯ�Ľ��������HDFS��(û��local)
insert overwrite directory '/test/export/emp'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from managed_emp01;
(2)Hadoop�����������
dfs -get /user/hive/warehouse/offcn.db/emp02/emp.txt
/home/offcn/tmp/export/emp2/emp.txt;
(3)Hive Shell �����
hive -e 'select * from offcn.emp02;' > /home/offcn/tmp/export/emp.txt;
(4)Export������HDFS��
export table offcn.emp02 to
'/tmp/export/emp';
export��import��Ҫ��������Hadoopƽ̨��Ⱥ֮��Hive��Ǩ�ơ�
(��)DQL���ݲ�ѯ����
������:
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
load data local inpath '/home/offcn/tmp/dept.txt' into table dept;
load data local inpath '/home/offcn/tmp/emp.txt' into table emp;
dept.txt �ļ�
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 null
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
1��������ѯ(Select��From)
ȫ����ѯ
select * from emp;
ѡ���ض��в�ѯ
2��������ѯ
��ѯ��нˮ����1000������Ա��
select * from emp where sal >1000;
��ϵ�����:
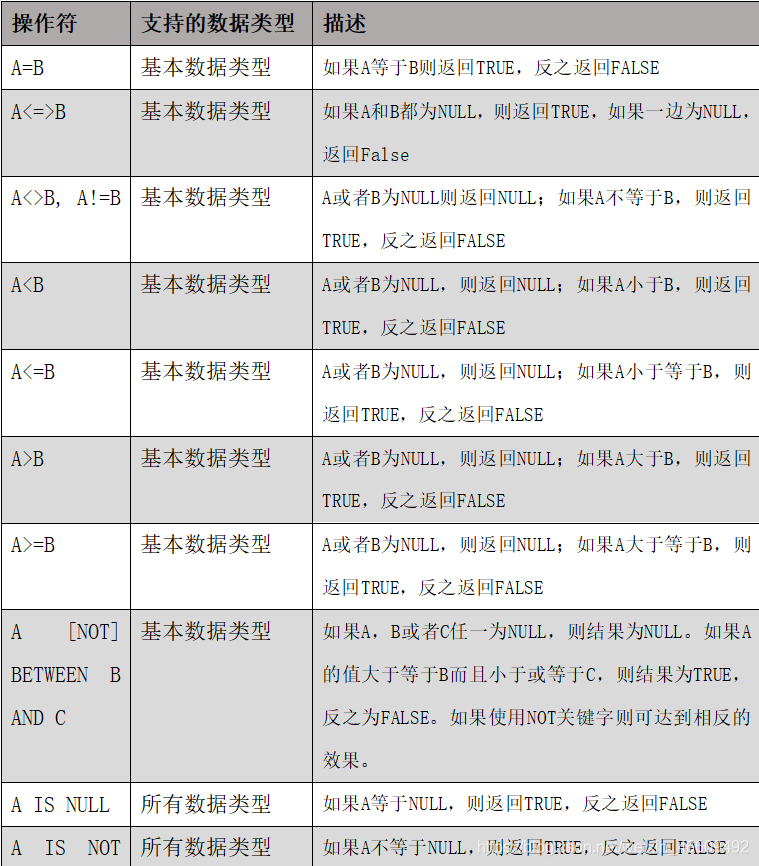


(2.1)Between��IN��is null
ѯ��нˮ����5000������Ա��
select * from emp where sal =5000;
��ѯ������500��1000��Ա����Ϣ
select * from emp where sal between 500 and 1000;
��ѯcommΪ�յ�����Ա����Ϣ
select * from emp where comm is null;
��ѯ������1500��5000��Ա����Ϣ
select * from emp where sal IN (1500, 5000);
(2.2)Like��RLike
ѡ�������������ַ�������:
% ������������ַ�(������ַ�)��
_ ����һ���ַ���
RLIKE�Ӿ�:
RLIKE�Ӿ���Hive��������ܵ�һ����չ,�����ͨ��Java���������ʽ
�����ǿ���������ָ��ƥ������
�����ԡ�S����ͷ��Ա����Ϣ
select * from emp where ename LIKE 'S%';
���ҵڶ�����ֵΪ��S����нˮ��Ա����Ϣ
select * from emp where ename LIKE '_S%';
���������к��С�I����Ա����Ϣ
select * from emp where ename RLIKE '[I]';
(2.3)�������(And/Or/Not)
������ ����
AND ����
OR ����
NOT ����
��ѯнˮ����1000,������30
select * from emp where sal>1000 and deptno=30;
��ѯнˮ����1000,���߲�����30
select * from emp where sal>1000 or deptno=30;
��ѯ����20���ź�30���������Ա����Ϣ
select * from emp where deptno not IN(30, 20);
(2.4)limit���
LIMIT�Ӿ��������Ʒ��ص�������ͬ��mysql����,limit��ֻ�ܸ�һ������
select * from emp limit 5;
3�������ѯ
(3.1)Group By���
GROUP BY���ͨ����;ۺϺ���һ��ʹ��,����һ�����߶���жӽ�����з���,
Ȼ���ÿ����ִ�оۺϲ�����
ע��:���������,select����ֶ�ֻ���Ƿ����ֶλ��߾ۺϺ���!
����emp��ÿ�����ŵ�ƽ������
select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
����empÿ��������ÿ����λ�����нˮ
select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
(3.2)Having���
having��where��ͬ��
where���治��д���麯��,��having�������ʹ�÷��麯����
havingֻ����group by����ͳ�����
����:
��ÿ�����ŵ�ƽ��нˮ����2000�IJ���
��һ��:
��ÿ�����ŵ�ƽ������
select deptno, avg(sal) from emp group by deptno;
�ڶ���:
��ÿ�����ŵ�ƽ��нˮ����2000�IJ���
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
4�����Ӳ�ѯ
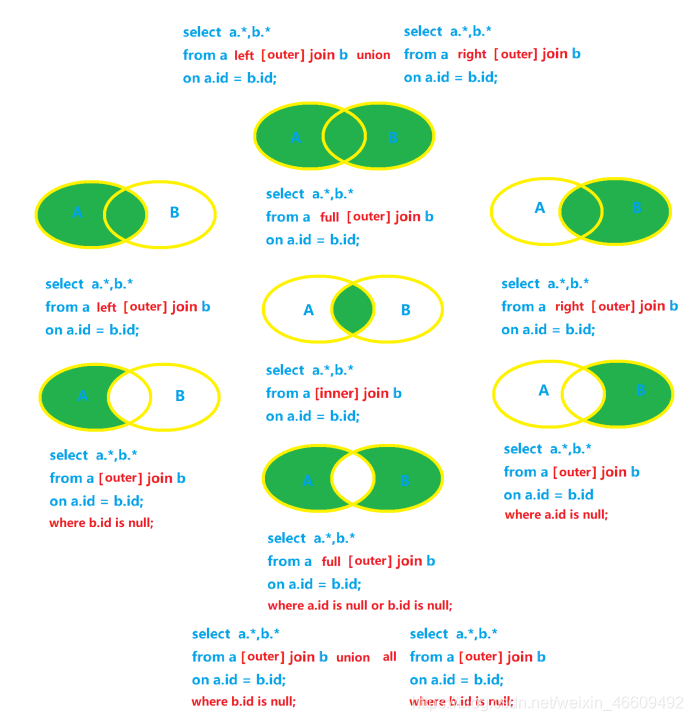
(4.1)������
select e.*,d.*
from emp e inner join dept d
on e.deptno=d.deptno;
���ý��淽ʽʵ��:
select e.*,d.*
from emp e left outer join dept d
on e.deptno=d.deptno
intersect
select e.*,d.*
from emp e right outer join dept d
on e.deptno=d.deptno;
(4.2)������
4.2.1.������
--������
select e.*,d.*
from emp e left outer join dept d
on e.deptno=d.deptno;
4.2.2������
--������
select e.*,d.*
from emp e right outer join dept d
on e.deptno=d.deptno;
4.2.3�����
--�����
select e.*,d.*
from emp e left outer join dept d
on e.deptno=d.deptno
where d.deptno is null;
4.2.4�Ҷ���
--�Ҷ���
select e.*,d.*
from emp e right outer join dept d
on e.deptno=d.deptno
where e.deptno is null;
4.2.5ȫ����
--ȫ����
select e.*,d.*
from emp e full outer join dept d
on e.deptno=d.deptno;
--��unionʵ��ȫ����
select e.*,d.*
from emp e left outer join dept d
on e.deptno=d.deptno
union
select e.*,d.*
from emp e right outer join dept d
on e.deptno=d.deptno;
4.2.6���Ҷ���
--���Ҷ���
select e.*,d.*
from emp e full outer join dept d
on e.deptno=d.deptno
where e.deptno is null or d.deptno is null;
--��union allʵ�����Ҷ���
select e.*,d.dname,d.loc
from emp e left outer join dept d
on e.deptno=d.deptno
where d.deptno is null
union all
select e.empno ,e.ename ,e.job,e.mgr,e.hiredate,e.sal,e.comm,d.*
from emp e right outer join dept d
on e.deptno=d.deptno
where e.deptno is null;
--except/minus:�ʵ��
select e.*,d.*
from emp e full outer join dept d
on e.deptno=d.deptno
except/minus
select e.*,d.*
from emp e inner join dept d
on e.deptno=d.deptno;
(4.3)��������
��������:�õ��ѿ�����,����ʽ����ʽ����д��
����on����,�൱��������
--��ʽд��
select e.*,d.*
from emp e,dept d;
����on����,�൱��������
select e.*,d.*
from emp e,dept d
where e.deptno=d.deptno;
--��ʾд��
select e.*,d.*
from emp e cross join dept d;
����on����,�൱��������
select e.*,d.*
from emp e cross join dept d
on e.deptno=d.deptno;
(4.4)��뿪����(left semi-join)
����߱���һ������,���ұ߱��д���ʱ,Hive��ֹͣɨ��,���Ч�ʱ�join��
������뿪���ӵ�select��where�ؼ��ֺ���ֻ�ܳ�����߱����ֶ�
���ܳ����ұ߱����ֶΡ�Hive��֧���Ұ뿪����
select *
from dept d left semi join emp e
on d.deptno=e.deptno;
select d.*
from dept d left semi join emp e
on d.deptno=e.deptno;
ִ���������,���������������in��������exists����
select * from user left semi join job on user.id=job.user_id;
������൱���������
select * from user where id in (select user_id from job);
����!!! hive��֧��in�Ӿ䡣����ֻ�ܱ�ͨ,ʹ��left semi�Ӿ䡣
(4.5)������
��ͨ������ѯ:
SELECT * FROM AREA
WHERE parent_code=(SELECT area_code
FROM AREA
WHERE area_name="���ɹ�������");
�����Ӳ�ѯ:
SELECT a.*,b.area_name
FROM AREA a JOIN AREA b
ON a.parent_code=b.area_code
WHERE b.area_name="���ɹ�������";
(6)�������
SELECT e.ename, d.dname, l.loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
Hive���ÿ��JOIN���Ӷ�������һ��MapReduce�������л�����
����һ�� MapReduce job�Ա�e�ͱ�d�������Ӳ���,Ȼ�����
����һ��MapReduce job����һ��MapReduce job������ͱ�l;�������Ӳ���
�Ż�:����3�����߸��������join����ʱ,���ÿ��on�Ӿ䶼ʹ��
��ͬ�����Ӽ��Ļ�,��ôֻ�����һ��MapReduce job
(7)hiveJoin��ע������
(7.1)����ʹ�ø��ӵ����ӱ���ʽ,֧�ַǵ�ֵ����
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
(7.2)ͬһ��ѯ�п�������2�����ϵı�
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
(7.3)���ÿ�����������Ӿ���ʹ����ͬ����,
��Hive��������ϵ�����ת��Ϊ����MR��ҵ
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--���������н��漰b��key1��,��˱�ת��Ϊ1��MR��ҵ��ִ��
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--��ת��Ϊ����MR��ҵ,��Ϊ�ڵ�һ������������ʹ����b�е�key1��,���ڵڶ�������������ʹ����b�е�key2�С�
(7.4)joinʱ�����һ������ͨ��reducer��ʽ����,�������л���֮ǰ��������,���,�������������������ڼ���reducer�λ�����������Ҫ���ڴ�
(7.5)��join��ʱ��,����ͨ���STREAMTABLE��ʾָ��Ҫ��ʽ����ı�
���ʡ��STREAMTABLE��ʾ,��Hive����ʽ�������ұߵı�
(7.6)join��WHERE����֮ǰ����
(7.7)�����һ��Ҫ���ӵı�֮������б�����С,����Խ�����Ϊ��map��ҵִ��(mapjoin)
5.����
(5.1)ȫ������(Order By)
Order By:ȫ������,ֻ��һ��Reducer
ʹ�� ORDER BY �Ӿ�����
ASC(ascend): ����(Ĭ��)
DESC(descend): ����
ORDER BY �Ӿ���SELECT���Ľ�β
--��ѯԱ����Ϣ��������������
select * from emp order by sal;
--��ѯԱ����Ϣ�����ʽ�������
select * from emp order by sal desc;
(5.2)ÿ��MapReduce�ڲ�����(Sort By)
���ڴ��ģ�����ݼ�order by��Ч�ʷdz���,�ںܶ������,������Ҫȫ������,
��ʱ����ʹ��sort by
Sort byΪÿ��reducer����һ�������ļ�,ÿ��Reducer�ڲ���������,��ȫ�ֽ������˵��������
--����reduce����
set mapreduce.job.reduces=3;
--�鿴����reduce����
set mapred.reduce.tasks;
--���ݲ��ű�Ž���鿴Ա����Ϣ
select * from emp sort by deptno desc;
--����ѯ������뵽�ļ���(���ղ��ű�Ž�������)
insert overwrite local directory '/home/offcn/tmp/sortby-result'
select * from emp sort by deptno desc;
(5.3)��������(Distribute By)
����Щ�����,������Ҫ����ij���ض���Ӧ�õ��ĸ�reducer,ͨ����Ϊ�˽��к����ľۼ�����
distribute by �Ӿ�����������
distribute by����MR��partition(�Զ������),���з���,���sort byʹ��
����distribute by���в���,һ��Ҫ�����reduce���д���,
����������distribute by����
--�Ȱ��ղ��ű�ŷ���,�ٰ���Ա����Ž�������
set mapreduce.job.reduces=3;
insert overwrite local directory '/home/offcn/tmp/distribute-result'
select * from emp
distribute by deptno sort by empno desc;
ע��:
distribute by�ķ��������Ǹ��ݷ����ֶε�hash����reduce�ĸ�������ģ����,
������ͬ�ķֵ�һ����
HiveҪ��DISTRIBUTE BY���Ҫд��SORT BY���֮ǰ
(5.4)Cluster By
��distribute by��sort by�ֶ���ͬʱ,����ʹ��cluster by��ʽ
cluster by���˾���distribute by�Ĺ�������sort by�Ĺ���
��������ֻ������������,����ָ���������ΪASC����DESC
�C��������д���ȼ�
1.select * from emp cluster by deptno;
2.select * from emp distribute by deptno sort by deptno;