kakfa安装及使用
1.下载安装包
在 https://kafka.apache.org/downloads下载最新的包,安装解压

解压后,我一般会在~/.bashrc配置文件中加入以下两行代码:
export KAFKA_HOME=/home/zyb/kafka/kafka_2.13-2.8.0
export PATH=$KAFKA_HOME/bin:$PATH
进入kafka_2.13-2.8.0解压目录,修改kafka-server 的配置文件
vim config/server.properties
修改配置文件中21、31、36和60行

2.功能验证
1、启动Zookeeper
? Zookeeper部署的是单点的。(以守护进程进行)
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2、启动Kafka服务
使用 kafka-server-start.sh 启动 kafka 服务
# 同样,加-daemon选项可实现后台运行守护进程
bin/kafka-server-start.sh config/server.properties
#挂后台
nohup bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
关闭kafka服务
bin/kafka-server-stop.sh config/server.properties
3、创建topic
首先创建一个名为test的topic,只使用单个分区和一个复本
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
# 或者
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
查看topic列表
bin/kafka-topics.sh --list --zookeeper localhost:2181
# 或者
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
4、产生消息,创建消息生产者
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
5、消费消息,创建消息消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
3.生产者消费者模型
基本概念:
“生产者消费者模型”: 某个模块(函数等)负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、协程、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者/消费者模型。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。
生产者: 发送数据端
消费者: 接收数据端
缓冲区:
1. 解耦 ( 降低生产者 和 消费者之间 耦合度 )
2. 并发 (生产者消费者数量不对等时,能保持正常通信)
3. 缓存 (生产者和消费者 数据处理速度不一致时, 暂存数据)
4.使用Go使用kafka实现生产者消费者模型
同步生产者
package test01import ( "fmt" "github.com/Shopify/sarama" "log" "os" "time")var Address = []string{"192.168.137.121:9092"} //虚拟机上的Kafka服务ip和端口func SyncProducer(address []string) { config := sarama.NewConfig() config.Producer.Return.Successes = true config.Producer.Timeout = 5 * time.Second //同步消费者 p, err := sarama.NewSyncProducer(address, config) if err != nil { log.Printf("sarama.NewSyncProducer err, message=%s \n", err) return } defer p.Close() topic := "test" srcValue := "sync, this is a message, index=%d" for i := 0; i < 10; i++ { value := fmt.Sprintf(srcValue, i) msg := &sarama.ProducerMessage{ Topic: topic, Value: sarama.ByteEncoder(value), } part, offset, err := p.SendMessage(msg) if err != nil { log.Printf("send messages(%s) err=%s \n", value, err) } else { _, _ = fmt.Fprintf(os.Stdout, value+" 发送成功, partition=%d, offset=%d\n", part, offset) } time.Sleep(2 * time.Second) }}
异步生产者
package test01import ( "fmt" "github.com/Shopify/sarama" "log" "os" "os/signal" "time")func Test01() { config := sarama.NewConfig() // 如果打开了Return.Successes配置,而又没有producer.Successes()提取,那么Successes()这个chan消息会被写满。 config.Producer.Return.Successes = true producer, err := sarama.NewAsyncProducer([]string{"192.168.137.121:9092"}, config) if err != nil { panic(err.Error()) } defer func() { if err := producer.Close(); err != nil { log.Fatal(err) } }() //Trap SIGINT to trigger a shutdown signals := make(chan os.Signal, 1) signal.Notify(signals, os.Interrupt) index := 0 var srcValue string var enqueued, produceErrors int ProducerLoop: for { select { case producer.Input() <- &sarama.ProducerMessage{ Topic: "test", Key: nil, Value: sarama.ByteEncoder(srcValue), }: enqueued++ index++ srcValue = fmt.Sprintf("test %d", index) case err := <- producer.Errors(): log.Printf("Failed to produce messages: %s, err: %v\n", srcValue, err) produceErrors++ case <- signals: break ProducerLoop } time.Sleep(2 * time.Second) } log.Printf("Enqueued: %d; errors: %d\n", enqueued, produceErrors)}
消费者
package mainimport ( "fmt" "github.com/Shopify/sarama")var Address = []string{"192.168.137.121:9092"}func main() { //配置 config := sarama.NewConfig() //接收失败通知 config.Consumer.Return.Errors = true //设置kafka版本号 config.Version = sarama.V2_8_0_0 //新建一个消费者 consumer, err := sarama.NewConsumer(Address, config) if err != nil { panic("create comsumer failed") } defer consumer.Close() //特定分区消费者,需要设置主题,分区和偏移量,sarama.OffsetNewest表示每次从最新的消息开始消费 partitionConsumer, err := consumer.ConsumePartition("test", 0, sarama.OffsetNewest) if err != nil { fmt.Println("error get partition sonsumer") } defer partitionConsumer.Close() for { select { case msg := <- partitionConsumer.Messages(): fmt.Println("msg offset: ", msg.Offset, " partition: ", msg.Partition, " timestrap: ", msg.Timestamp.Format("2006-01-02 15:04"), " value: ", string(msg.Value)) case err := <- partitionConsumer.Errors(): fmt.Println(err.Err) } }}
使用过程中遇到的问题
1.虚拟机的网络不通,虚拟机可以ping通主机,主机ping不通虚拟机
原因在于主机的VMware Network Adapter VMnet8网络适配器IP设置不对,与虚拟机IP没在同一个网段。所以需要去本机的网络与共享中心,点击更改适配器设置,点击VMware Network Adapter VMnet8,点击属性,点击Internet协议版本4(TCP/IPv4)修改属性,将ip改到和虚拟机的同一个网段即可,可能需要先禁用后重启生效。
2.启动kafka失败,报如下错误:

解决方法:需修改日志文件加夹下的meta.properties
其中内容如下: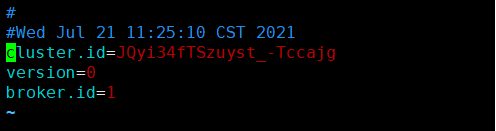
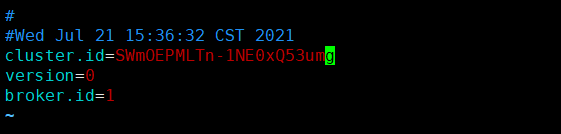
将cluster.id修改为SWmOEPMLTn-1NE0xQ53umg即可,如下图所示
3.运行生产者程序时报错kafka: client has run out of available brokers to talk to (Is your cluster reachable?)
解决方法:如果zookeeper和kafka服务正常启动,并且config/server.properties配置如下图所示,都没有问题的话,那就是可能是虚拟机的防火墙没有关闭,使得端口没有暴露出来,这时可以运行systemctl disable firewalld.service关闭防火墙,重新运行程序就没问题了。
