?完全分布式:
真正的分布式,由3个及以上的实体机或者虚拟机组成的机群。一个Hadoop集群环境中,NameNode,SecondaryName和DataNode是需要分配在不同的节点上,也就需要三台服务器
1.配置JAVA 环境
1.1检查系统是否有JDK环境
[root@master01?jdk1.8]# rpm -qa | grep jdk
1.2卸载之前的JDK环境
[root@master01?jdk1.8]#?rpm -e --nodeps
1.3新建文件夹、解压、配置环境变量
(1)cd /usr/local
?mkdir?java
(2)[root@master01?~]$?sudo tar -zxvf jdk-8u241-linux-x64.tar.gz -C /usr/local/java
(3)[root@master01 local]# sudo mv jdk1.8.0_241/ jdk1.8
vim ~/.bashrc
配置内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_241# 配置Java的安装目录
export PATH=$PATH:$JAVA_HOME/bin?#?在原PATH的基础上加入JDK的bin目录
使文件生效: source ~/.bashrc
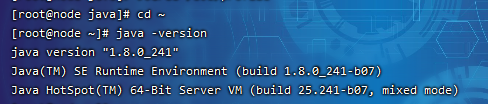
- 检测jdk是否正确安装:java -version
????
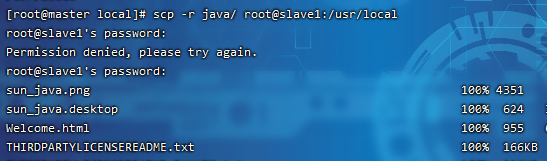
1.4 copy整个目录到其它机器(或者安装好jdk后克隆)
scp -r java/ root@slave1:/usr/local
2.配置ssh
2.1修改每台机器主机名(hostname)
hostnamectl?set-hostname?master???(立即生效)
hostnamectl set-hostname slave1???(立即生效)
hostnamectl set-hostname slave2???(立即生效)
2.2修改每台机器/etc/hosts文件
vi /etc/hosts

修改其中1台,然后scp到其它机器?
????scp?文件名 远程主机用户名@远程主机名或ip:存放路径
scp?hosts?root@slave1:/etc/
scp hosts root@slave2:/etc/
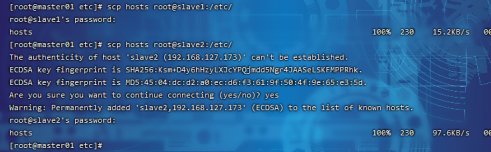
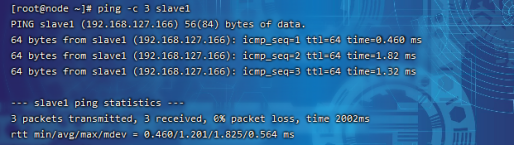
?修改完之后,互ping其它机器,能互ping则说明修改OK
ping?-c?3?slave1(※?3表示发送?3?个数据包)
2.3配置ssh,实现无密码登录
(无密码登录,效果也就是在master上,通过ssh slave1或者ssh slave2就可以登录?对方机器,而不用输入密码。)
(1)进入:cd /usr
(2)执行:ssh-keygen ## ?(一直回车即可)

(3)查看:cd ~/.ssh
ls -al
(4)在master上将公钥放到authorized_keys里
cat id_rsa.pub > authorized_keys
??(5)将master上的authorized_keys放到其它机器上
scp authorized_keys root@slave1:/root/.ssh
scp authorized_keys root@slave2:/root/.ssh

??(6)测试是否成功:ssh slave1(第一次要输密码)

3.Hadoop上传、配置
3.1创建、解压、环境变量
(1)创建目录
mkdir?/usr/hadoop
(2)解压
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/hadoop
(3)追加环境变量
vim ~/.bashrc(其它机器也要相应配置一次hadoop环境变量)
配置内容:
#HADOOP
??export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin ?
使环境变量生效:source?/.bashrc
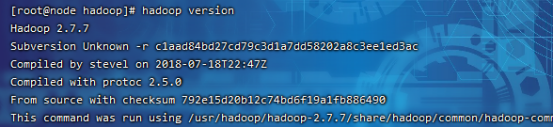
(4)确认环境变量配置:hadoop version
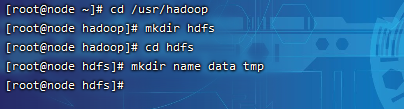
3.2创建HDFS存储目录
cd?/usr/hadoop
mkdir?hdfs
cd?hdfs
mkdir?name?data?tmp
/usr/hadoop/hdfs/name????--存储namenode文件
/usr/hadoop/hdfs/data??????--存储数据
/usr/hadoop/hdfs/tmp???????--存储临时文件
3.3配置文件
3.3.1 hadoop-env.sh
vim /usr/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
????
3.3.2 yarn-env.sh
??
3.3.3 core-site.xml
<configuration>
???<property>
??????<name>hadoop.tmp.dir</name>
??????<value>/usr/hadoop/hdfs/tmp</value>
???</property>
???<property>
??????<name>fs.default.name</name>
??????<value>hdfs://master01:9000</value>
???</property>
</configuration>
3.3.4 hdfs-site.xml
<configuration>
??<property>
????<name>dfs.replication</name>
????<value>3</value>
??</property>
??<property>
????<name>dfs.name.dir</name>
????<value>/usr/hadoop/hdfs/name</value>
??</property>
??<property>
????<name>dfs.data.dir</name>
????<value>/usr/hadoop/hdfs/data</value>
??</property>
??<property>
????<name>dfs.permissions</name>
????<value>false</value>
??</property>
</configuration>
3.3.5 mapred-site.xml
cd /usr/hadoop/hadoop2.7.7/etc/hadoop
cp?mapred-site.xml.template?mapred-site.xml
配置内容:
<configuration>
??<property>
????<name>mapreduce.framework.name?</name>
????<value>yarn</value>
??</property>
</configuration>
3.3.6 yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
3.3.7 slaves(删除其中localhost)
??????
3.3.8 copy整个/usr/hadoop/目录到其它机器
进入:cd?/usr/hadoop
scp -r hadoop/ root@slave1:/usr/hadoop/
scp -r hadoop/ root@slave2:/usr/hadoop/
3.4启动Hadoop?(master上)
(1)格式化:hadoop?namenode?-format
格式化成功后,可以看到在/usr/hadoop/hdfs/name目录下多了一个current目录,而且该目录下有一系列文件,如下:
????????
- 执行启动(namenode只能在master上启动,因为配置在master上;datanode每 ?个节点上都可以启动)
? ????start-all.sh?

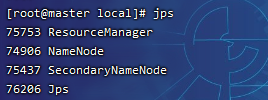
master上执行jps,会看到NameNode, SecondaryNameNode, ResourceManager
???
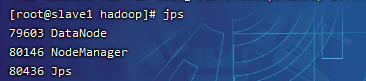
? ?其它节点上执行jps,会看到DataNode, NodeManager
??
?
(3)在wins上打开网页,查看HDFS管理页面?http://10.152.136.5:50070查看,提示无法访问
? ?在master上,执行以下命令关闭防火墙,即可访问(为了能够正常访问node节点,最好把
其它机器的防火墙也stop了)
? ? ? ? ? ? HDFS管理首页

? ?访问Yarn管理页:?http://10.152.136.5:8088
?