1��mapreduceԭ��
1.1�����л��ͷ����л�
(1)���л�:���ڴ�Ķ���ת�����ֽ�����,���ڴ洢
(2)�����л�:���յ����ֽ����л�Ӳ�̵ij־û�����,ת�����ڴ档
1.2��inputformat��Ĭ�ϵ���(textinputformat)
1.3��Inputsplit���
�Cinputsplitֻ��¼�˷�Ƭ��Ԫ������Ϣ,������ʼλ�á����ȼ����ڽڵ��б��ȡ�
(1)�ҵ����������ļ��洢Ŀ¼;
(2)��������Ŀ¼�µ�ÿһ���ļ�
(3)������һ���ļ�ss.txt
�ٱ����ļ���С;
�ڼ�����Ƭ��С,Ĭ�������block��С;
�ۿ�ʼ��Ƭ,�γɵ�һ����Ƭss.txt-1:128M��
ÿ����Ƭ��Ҫ�ж�����ʣ�µIJ����Ƿ���ڿ��1.1��,������1.1���ͻ���Ϊһ����Ƭ��
�ܽ���Ƭ��Ϣд�뵽һ����Ƭ�滮�ļ��С�
���ύ��Ƭ�滮�ļ���yarn��,yarn�ϵ�MRAppmaster������Ƭ�滮�ļ����㿪��maptask�ĸ�����
- ע��:
block:��HDFS�� �����洢 ������;
��Ƭ:�Ƕ� �������� �Ļ��֡�
������Ƭֻ�������϶��������ݽ�����Ƭ,�������ڴ����Ͻ����зֳ�Ƭ���д洢��
2��Mapreduceִ������(�ص�)
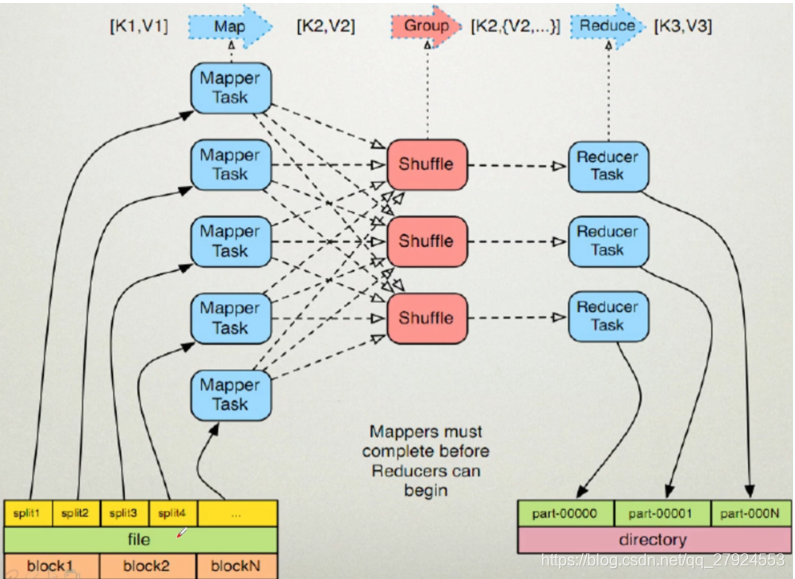
2.1��Mapper����������
1��������
:HDFS���������ļ�(200M),����block��Ӧ������Ƭ(split),��Ӧ����Maptask
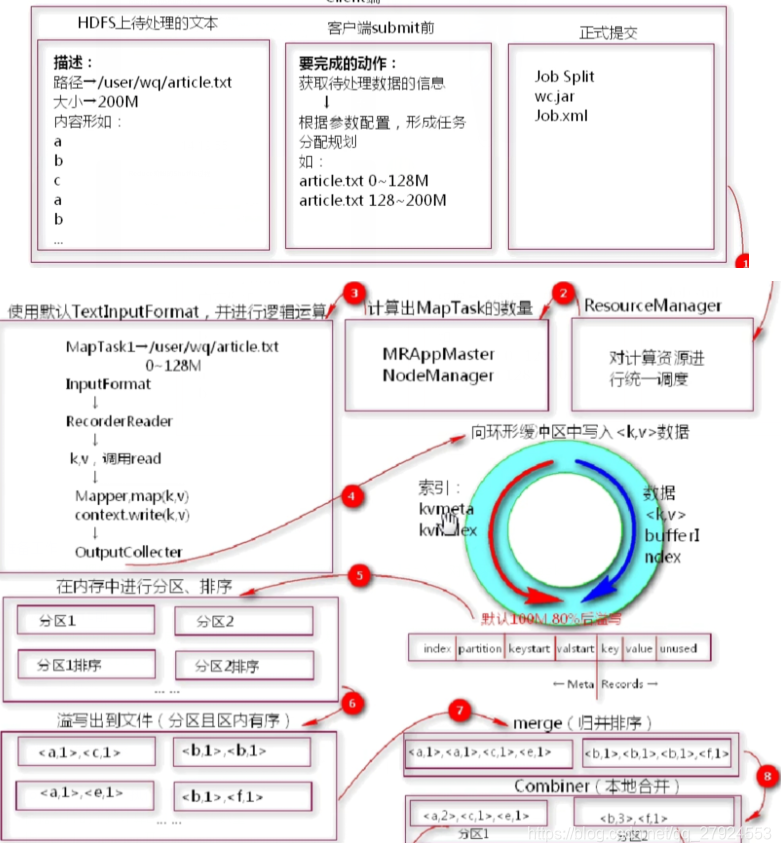
2���ͻ���submitǰ
:��ȡ����������Ϣ,���ݲ�������,�γ��������滮
:�� - txt1(0-128M),txt2(128-200M)
3���ͻ�����ʽ�ύ
:wc.jar,job.xml
4���ͻ�����RM��������
5��Resourcemanagerִ�е��������
:���ݷ�Ƭ�ĸ��������Maptask����
:ָ��nodemanager����APPmaster
6��ʹ��textinputformat��ȡ����,������������Ĭ��
:��InputFormat��ȡtxt1�ļ�
:�ײ�ʹ�ü�¼��ȡ��RecorderReader��ȡ�ڴ�
:����read��ȡk1,v1
:��������mapper����,����k2,v2
7��������Ϻ�����k2,v2д�뵽���λ�����
:Ԫ���� - ��������������������key�Ŀ�ʼ��,value�Ŀ�ʼ
:��¼ - ��¼��key,��¼��values,δʹ������
8�����ڴ���з�������
:�������� - ��ǰkey��hashֵ��reduce��������������
:������� - ����
9�����ڴ����ݳ�����ֵ,0.8��,����д���ݵ�����,�γ�С�ļ�
:�����ļ���������������
10�������е�С�ļ�����鲢����
:����������ͬ��С�ļ��ϲ���һ���ļ�
11��Combiner,���ո����������б��ؾۺ�
2.2��Reducer����������
- ���е�MapTask�������֮��,�������Ӧ������ReduceTask(�����շ���������)
- reduce������ָ��
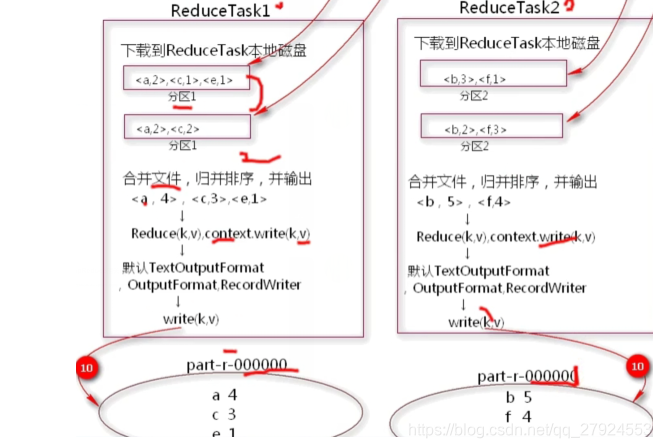
- reduce������ָ��
1�����շ�����ͨ��httpЭ���ڵ���ȡ��reducetask���ش���;
2������ȡ���Ķ��map���ļ����й鲢����,����һ���������ļ�
3�����ļ�װ�ص��ڴ�,���оۺϲ���
4�������������HDFS,�����ʽ��outputformat.recordwriter����
3��Shuffle����(�ص�)
3.1�����λ��������ݽṹ

Map������������collector������,ÿ��Map���ϵؽ���ֵ����������ڴ��й����һ���������ݽṹ�С�ʹ�û������ݽṹ��Ϊ�˸���Ч��ʹ���ڴ�ռ�,���ڴ��з��þ����ܶ�����ݡ�
:������ݽṹ��ʵ���Ǹ��ֽ�����byte[],��Kvbuffer,��������,���������治�����������,��������һЩ��������,�������������ݵ���������һ��Kvmeta�ı���,��Kvbuffer��һ�������ϴ���һ��IntBuffer(�ֽ�����õ���ƽ̨�������ֽ���)�����ס�
:�����������������������Kvbuffer�������ڲ��ص�����������,��һ���ֽ������������,�ֽ�㲻��ب�Ų����,����ÿ��Spill֮�����һ�Ρ���ʼ�ķֽ����0,���ݵĴ洢��������������,�������ݵĴ洢��������������.
ע��:�����ķֽ��Ϳ�������ͼ�еij����Ϣ
Kvbuffer�Ĵ��ָ��bufindex(�����ݵĴ洢����)��һֱ����ͷ����������,����bufindex��ʼֵΪ0,һ��Int�͵�keyд��֮��,bufindex����Ϊ4,һ��Int�͵�valueд��֮��,bufindex����Ϊ8�� (int�͵�����ռ��4���ֽ�)
�����Ƕ���kvbuffer�еļ�ֵ�Ե�����,�Ǹ���Ԫ��,����:value����ʼλ�á�key����ʼλ�á�partitionֵ��value�ij���,ռ���ĸ�Int����,Kvmeta�Ĵ��ָ��Kvindexÿ�ζ����������ĸ������ӡ�,Ȼ��������һ������һ�����ӵ������Ԫ������ݡ�����Kvindex��ʼλ����-4,����һ����ֵ��д��֮��,(Kvindex+0)��λ�ô��value����ʼλ�á�(Kvindex+1)��λ�ô��key����ʼλ�á�(Kvindex+2)��λ�ô��partition��ֵ��(Kvindex+3)��λ�ô��value�ij���,Ȼ��Kvindex����
-8λ��,�ȵڶ�����ֵ�Ժ�����д��֮��,Kvindex����-12λ�á�
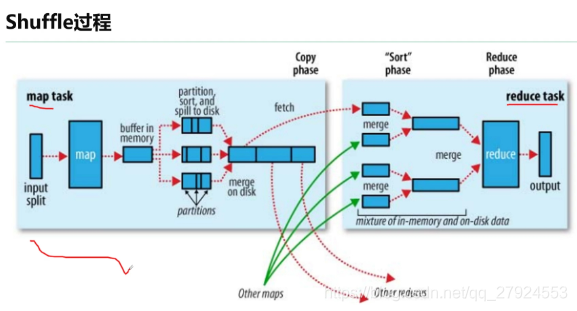
3.2��Map�ε�Shuffle����(�ص�)
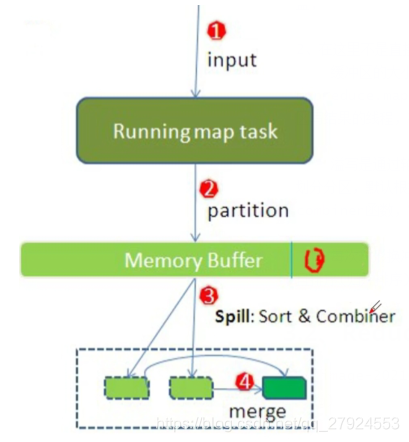
map��shuffle��������
1��ÿ��map��һ�������ڴ滺����,���ڴ洢map�������
:Ĭ�ϴ�СΪ100MB,һ���ﵽ��ֵ0.8,һ����̨�߳̾ͽ�����д�뵽���̵�ָ��Ŀ¼��һ���½��ļ���
2��д����ǰ,Ҫpartition(��ϣȡģ����,�������Ƿ������),sort��
:�����combiner,combiner��������
:commbiner:���ؾۺϿɻ���reducetask����ѹ��
:�ڴ��������㷨Ϊ����
3��������¼д��,�ϲ�ȫ���ļ�Ϊһ��������������ļ�
:С�ļ��ϲ������㷨Ϊ�鲢����
- ��������
1��������map֮ǰ,������ļ���Ƭ�Ĵ�С,Ȼ�����ݷ�Ƭ�Ĵ�С����map�ĸ���,
��ÿһ����Ƭ�������һ��map��ҵ,������һ���ļ�(С�ڷ�Ƭ��С*1.1)����һ��map��ҵ,Ȼ��ͨ���Զ���map���������Զ����������,������Ϻ��д�����ش���;
2�������ﲻ��ֱ��д�����,Ϊ�˱�֤IOЧ��,��������д���ڴ�Ļ��λ�����,����һ��Ԥ����(��������)��
�������Ĵ�СĬ��Ϊ100MB(��ͨ����������mpareduce.task.io.sort.mb������),��д���ڴ滺�����Ĵ�С����һ������ʱ,Ĭ��Ϊ80%(��ͨ��mapreduce.map.sort.spill.percent��������),������һ����д�߳̽��ڴ滺������������д������(spill to disk),�����д�߳��Ƕ�����,��Ӱ��map����д������߳�,����д�����̵Ĺ�����,map�������뵽������,����ڼ仺����������,��mapд�ᱻ��������д���̹�����ɡ�
��д��ͨ����ѯ�ķ�ʽ���������е��ڴ�д�뵽����mapreduce.cluster.local.dirĿ¼�¡�����д������֮ǰ,���ǻ�֪��reduce������,Ȼ������reduce���������ַ���,Ĭ�ϸ���hashpartition����д������д�뵽���Ӧ�ķ�����
��ÿ��������,��̨�̻߳����key��������,������д�����̵��ļ��Ƿ���������ġ������combiner����,�����������������,ʹ��map��������ա�����д�����̵����ݺʹ����reduce�����ݡ�
ÿ�λ��λ��������ڴ�ﵽ��ֵʱ,�ͻ���д��һ���µ��ļ�,��˵�һ��map��д��֮��,���ػ���ڶ��������������ļ�����map���֮ǰ�����Щ�ļ��ϲ���һ������������(�鲢����)���ļ�,����ͨ������mapreduce.task.io.sort.factor����ÿ�ο��Ժϲ����ٸ��ļ���
3.3��Reduce�ε�Shuffle����(�ص�)
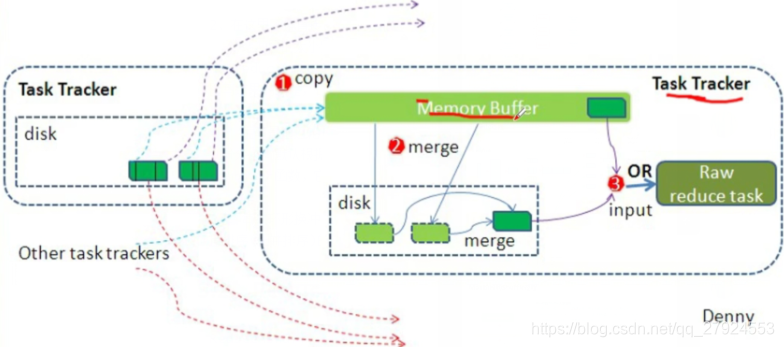
Reduce shuffle�������:
1��Reducerͨ��httpЭ��õ�����ļ����ض�����������
reducetask1:�������1�ͷ���3�����ݾۺ�,ͨ��httpЭ�齫��Ӧ����������ȡ����,��ȥ�ڴ���
:�ڴ���ֵ��0.8,����������
2��ȫ����ȡ������,��������ϲ�map���,Ȼ����reduce��
3��reduceִ�����֮��,д�뵽HDFS��
- ��������
map������ɺ�,�����ҵ״̬��application master��֪��map��ִ�����,������reduce����,application master����֪��map���������֮��Ķ�Ӧӳ���ϵ,reduce��ѯapplication master��֪��������Ҫ���Ƶ����ݡ�
һ��Map��������,���ܱ����Reduce����ץȡ��ÿ��Reduce���������Ҫ���Map����������Ϊ������������ļ�,��ÿ��Map��������ʱ����ܲ�ͬ,����һ��Map�������ʱ,Reduce����Ϳ�ʼ���С�Reduce������ݷ������ڶ��Map�����ץȡ(fetch)��Ӧ����������,�������Ҳ����Shuffle��copy���̡�
reduce�������ĸ����߳�,����ܹ����еĸ���map�����,Ĭ��Ϊ5���̡߳�����ͨ������mapreduce.reduce.shuffle.parallelcopies���ơ�
������ƹ��̺�mapд����̹�������,Ҳ�з�ֵ���ڴ��С,��ֵһ�������������ļ�������,���ڴ��С��ֱ��ʹ��reduce��tasktracker���ڴ��С,����ʱ��reduce���������������ͺϲ��ļ�������
���map�����С,��ᱻ���Ƶ�Reducer���ڽڵ���ڴ滺����,�������Ĵ�С����ͨ��mapred-site.xml�ļ��е�mapreduce.reduce.shuffle.input.buffer.percentָ����һ��Reducer���ڽڵ���ڴ滺�����ﵽ��ֵ,���������е��ļ����ﵽ��ֵ,��ϲ���д�����̡�
���map����ϴ�,��ֱ�ӱ����Ƶ�Reducer���ڽڵ�Ĵ����С�����Reducer���ڽڵ�Ĵ�������д�ļ�����,��̨�̻߳Ὣ���Ǻϲ�Ϊ������������ļ�������ɸ���map���,����sort�Ρ������ͨ���鲢���������map���С�ļ��ϲ��ɴ��ļ������ͨ���鲢�ϲ��ɵĴ��ļ���Ϊreduce�������
4��MapReduce������������
4.1��һ��job��map������reduce����
4.1.1��map����
? MapReduce��ܻ���������ļ������������ݷ�Ƭ(input split),ÿ�����ݷ�Ƭ���һ��map����,���ݷ�Ƭ�洢�IJ������ݱ���,����һ����Ƭ���Ⱥ�һ����¼���ݵ�λ�õ����顣
defalt = total_size/split_size
1����������ݷ�Ƭ��������,InputFormat��Ĭ������»����hadoop��Ⱥ��DFS���С���з�Ƭ,ÿһ����Ƭ����һ��map���������д�����
2��block��(���ݿ�,��������)
block:HDFS�еĻ����洢��λ,hadoop1.xĬ�ϴ�СΪ64M��hadoop2.xĬ�Ͽ��СΪ128M���ļ��ϴ���HDFS,��Ҫ�������ݳɿ�,����Ļ������������Ļ���(ʵ�ֻ���Ҳ��������һ��read����,ÿ����������128M�����ݺ����write����д�뵽hdfs),��Ĵ�С��ͨ�� dfs.block.size���á�block����������Ʊ�֤���ݵİ�ȫ:Ĭ��Ϊ3��,��ͨ��dfs.replication���á�
ע��:�����Ŀ��С�����ú�,���ϴ����ļ��Ŀ��СΪ�����õ�ֵ,��ǰ�ϴ����ļ��Ŀ��СΪ��ǰ������ֵ��
3��split��Ƭ(���ݷ�Ƭ,������)
split��Ƭ:�������ϵĻ���,Ŀ��ֻ��Ϊ����map task���õػ�ȡ���ݡ�split��ͨ��hadoop�е�InputFormat�ӿ��е�getSplits()�����õ��ġ�
4.1.2��reduce����
4.2��maptask��reducetask�Ĺ���ԭ��
4.2.1��maptask�Ĺ���ԭ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-v1IZL3cG-1627810650498)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Local/YNote/data/lhw18434365386@163.com/c3baff788a0a4ccf8d6a16764277dbbf/clipboard.png)]](https://img-blog.csdnimg.cn/13b116fe445e4eaf876a1d66fabedf32.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI3OTI0NTUz,size_16,color_FFFFFF,t_70)
(1) Read��:Map Taskͨ���û���д��RecordReader,������InputSplit�н�����һ����key/value��
(2) Map��:�ýڵ���Ҫ�ǽ���������key/value�����û���дmap()��������,������һϵ���µ�key/value��
(3) Collect�ռ���:���û���дmap()������,�����ݴ�����ɺ�,һ������OutputCollector.collect()���������ڸú����ڲ�,���Ὣ���ɵ�key/value����(����Partitioner),��д��һ�������ڴ滺�����С�
(4) Spill��:������д��,�����λ���������,MapReduce�Ὣ����д�����ش�����,����һ����ʱ�ļ�����Ҫע�����,������д�뱾�ش���֮ǰ,��Ҫ�����ݽ���һ�α�������,���ڱ�Ҫʱ�����ݽ��кϲ���ѹ���Ȳ�����
- �������:
����1:���ÿ��������㷨�Ի������ڵ����ݽ�������,����ʽ��,�Ȱ��շ������partition��������,Ȼ����key������������,���������,�����Է���Ϊ��λ�ۼ���һ��,��ͬһ�������������ݰ���key����
����2:���շ��������С�������ν�ÿ�������е�����д��������Ŀ¼�µ���ʱ�ļ�output/spillN.out(N��ʾ��ǰ��д����)�С�����û�������Combiner,��д���ļ�֮ǰ,��ÿ�������е����ݽ���һ�ξۼ�������
����3:���������ݵ�Ԫ��Ϣд���ڴ��������ݽṹSpillRecord��,����ÿ��������Ԫ��Ϣ��������ʱ�ļ��е�ƫ������ѹ��ǰ���ݴ�С��ѹ�������ݴ�С�������ǰ�ڴ�������С����1MB,���ڴ�����д���ļ�output/spillN.out.index�С�
(5) Combine��:���������ݴ�����ɺ�,MapTask��������ʱ�ļ�����һ�κϲ�,��ȷ������ֻ������һ�������ļ���
���������ݴ������,MapTask�Ὣ������ʱ�ļ��ϲ���һ�����ļ�,�����浽�ļ�output/file.out��,ͬʱ������Ӧ�������ļ�output/file.out.index��
�ڽ����ļ��ϲ�������,MapTask�Է���Ϊ��λ���кϲ�������ij������,�������ö��ֵݹ�ϲ��ķ�ʽ��ÿ�ֺϲ�io.sort.factor(Ĭ��100)���ļ�,�����������ļ����¼�����ϲ��б���,���ļ������,�ظ����Ϲ���,ֱ�����յõ�һ�����ļ���
��ÿ��MapTask����ֻ����һ�������ļ�,�ɱ���ͬʱ�����ļ���ͬʱ��ȡ����С�ļ������������ȡ�����Ŀ�����
4.2.2��reducetask�Ĺ���ԭ��
(1)copy�� - reducetask��ȡmap�ε����
��reduce��Ҫͨ���ڲ�ͨ�Ž�map��������������reduce��
����Ҫ�����е�map����������������ͬ��reduce��һ��reduce����һ������������map���������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-VN692lGj-1627810650500)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Local/YNote/data/lhw18434365386@163.com/174b1beb74e84bf795b380f4b1b99df8/clipboard.png)]](https://img-blog.csdnimg.cn/cf75b4f5fab142ba83c806e7707f5f0f.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI3OTI0NTUz,size_16,color_FFFFFF,t_70)
- ע��:
��map�����reduce����һ����ͬһ̨�����ϡ�
��map�����reduce������ֻ��һ���������ж��map����Ͷ��reduce����ͬʱִ�С�
(2)�ϲ��������
�ٽ�map���������reduce��,��Ҫ���ļ����кϲ�Ϊһ���ļ���
��֮��Ժϲ��Ժ���ļ����ݽ�������
��������Ժ�ĺϲ��ļ�����reduce����������ļ���
(3)reduce����������������
�������ļ����Ѿ��������ġ�
���ļ�������,����k.v����ʽ����ͬ��key,���ܻ��кܶ�IJ�ͬ��value��
������reduce������,����k,v�Ĺ�ϵʵ������һ��key->list��ϵ��
�۽�key��Ӧ�ļ������ݽ��б���,��ͼ��ϲ���
�ܺϲ��Ժ�Ľ��,�����k.v��һ��һ��ϵ��ʵ�ʾ���k����ͺ�����ݻ��ܵ�һ��һ��ϵ��
�ݽ����������
(4)reduce����ļ�����
���ļ�������/�����ʽ���д���,��ͬ���ļ�ʹ�ò�ͬ�ļ�����/�����ʽ��
Ĭ��TextInputformat/TextOutputformat.
�ڶ����ݵĶ���/д��ʹ��RecorderReader/RecoderWriter
4.3��Hive�ķ���������һ�������ļ����滻Ϊ���ɶ��ļ�,ʹ����Щ����ʱ�����Ӱ����?
������Ӱ��,�������������ļ�ȫ�������滻
��������ļ������滻,ֻ��Ӱ�쵱ǰ����
5��MapReduce����ʵս
5.0���ر��������ͽ���
- ʹ����Щ���Ͷ�������ݿ��Ա����л��������紫����ļ��洢,�Լ����д�С�Ƚϡ�
BooleanWritable:����������ֵ
ByteWritable:���ֽ���ֵ
DoubleWritable:˫�ֽ���
FloatWritable:������
IntWritable:������
LongWritable:��������
Text:ʹ��UTF8��ʽ�洢���ı�
NullWritable:��<key, value>�е�key��valueΪ��ʱʹ��
5.1��ʵʩ����
��һ��:��ʽʵʩ
�ڶ���:��������
������:ѡ����Ӧ�ı�̷�ʽʵ��
5.1.1������maven����
5.1.2����������
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>mapreduce-study</groupId>
<artifactId>mapreduce-study</artifactId>
<version>1.0-SNAPSHOT</version>
<name>mapreduce-study</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.hadoop.examples.ExampleDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
5.3�������д
5.3.0�������嵥
ͳ���ļ��еĵ��ʸ���:�ļ���С200M
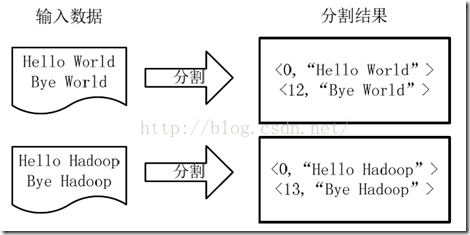
:���ļ���ֳ�splits,���ڲ����õ��ļ���С,����ÿ���ļ�Ϊһ��split,�����ļ����зָ��γ�<key, value>��,����ͼ��ʾ,��һ����MapReduce����Զ����,����ƫ����(��keyֵ)�����˻س���ռ���ַ���
- ����˼·
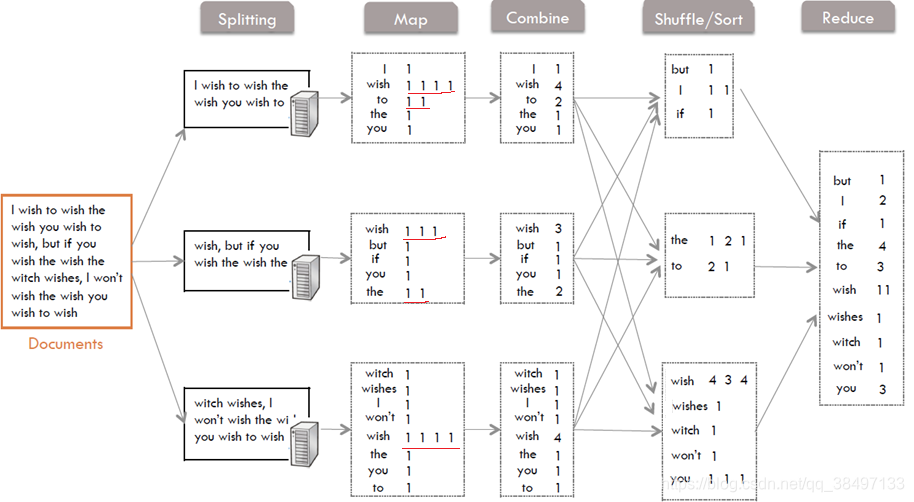
1.���ı���Ϣת�����ַ�������
2.��split�����Կո��ַ����ָ�浽������
3.��ÿһ��������Ϊmap��key,���ʳ��ֵĴ�����Ϊmap��value
4.Combine���Ż��IJ���,��mapper�ξͶ�value��ֵ���м���,ÿһ����Ƭֻ���ص������value,�������Ƕ���1��value
5.Suffle/sort���ǶԵ��ʽ��������Ҷ����з�Ƭ��valueֵ�����ٴ�ͳ��
6.reduce�ζ���һ�ε�valueֵ�����ļ���,������ʶ�Ӧ���ֵĴ�����
5.3.1���Զ���Mapper
1���и��ַ���
2�����ָ�õ�<key, value>�Խ����û������map�������д���,�����µ�<key, value>��
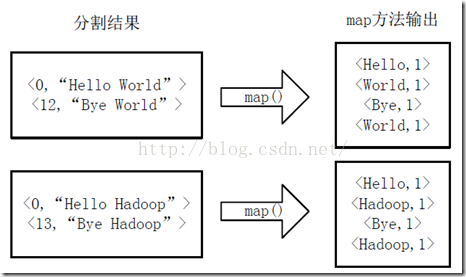
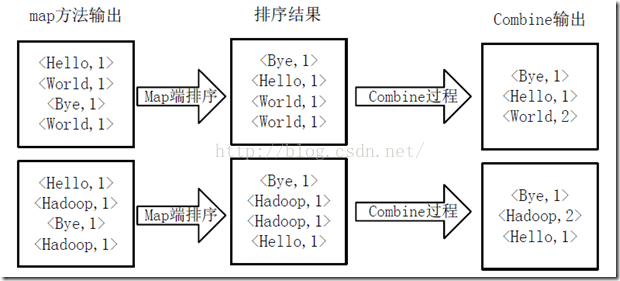
3���õ�map���������<key, value>֮��,Mapper�Ὣ���ǰ���keyֵ��������,��ִ��Combine����,��keyֵ��ͬ��valueֵ�ۼ�,�õ�Mapper������������
/*1���Զ�������̳�Mapper����
*2���������k1,v1,k2,v2
* KEYIN: key1,������hdfs�ϵ��ض���Դ�ļ������ݵ�ƫ����,���һ��ƫ����Ϊ0,�ڶ���ƫ����Ϊ19
* LongWrite:�Ƕ�long�ķ���,���ݹ������Բ���intwrite
* VALUEIN:values,������Դ�ļ��е�ǰ�ж�Ӧ������,��hello you
* KEYOUT:key1,map����ִ����Ϻ�,������������������shuffle��ʱkey������,���ǵ���,��:hello
* VALUEOUT:value2,map����ִ����Ϻ�,������������������shuffle��ʱvalue������,���ǵ��ʳ��ֵĴ���,��:1
*
* �ֱ���� �ļ�����ƫ����,�����ı�(Text),����ĵ���(�ı���ʽ),������ʵĴ���(IntWrite)
* Text��String�Ż�
*/
private final static class MyMapper extends<Longwrite,Text,Text,IntWrite>{
/*
*����map����:map���������n��,ÿ�η���������Դ�ļ��е�һ������,������map�����ͻ�ִ��һ��
* ����˵��:
* key:��key1,�洢����ƫ����,��0
* value:��value1,�洢���ǵ�ǰ�е�����
* context:������,��װ������Ϣ
* IOException:
* InterruptedException:
*/
@Override
protected void map(LongWrite key,Text value,Context context)throws IOException,InterruptedException{
//��һ������hadoop�����л����ͻ�ԭ��java����
//�ڶ���������ǰ�е������ҷָ��ַ���ת��Ϊһά����
//�������ʽ:s+��ո�,ȫ�ǿո�,tap������ƥ��,\\����ת��
String[]arr=value.toString().split("\\s+");
//��������ͨ��ѭ����������,ÿѭ��һ��,����ǰ�����еĵ����Լ����������shuffle��
for(String word:arr){
Text key2=new Text(word);
IntWritable value2=new IntWritable(1);
context.write(key,value2);
}
//���IJ��������ʱ,���뽫java��Ӧ�����л����ͷ�װ��hadoop��Ӧ�����л�����
}
}
5.3.2��shuffle��
- shuffle��:����,����
�õ�map���������<key, value>֮��,Mapper�Ὣ���ǰ���keyֵ��������,��ִ��Combine����,��keyֵ��ͬ��valueֵ�ۼ�,�õ�Mapper��������������
5.3.3���Զ���reducer
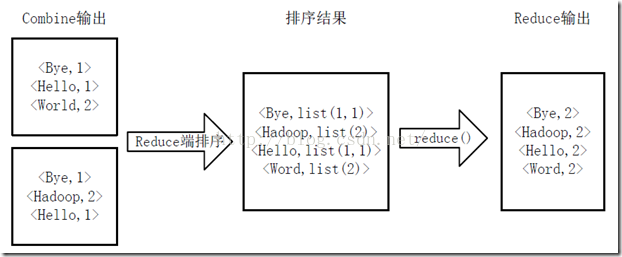
Reducer�ȶ�Mapper���յ����ݽ�������,�ٽ����û��Զ����reduce�������д���,�õ��µ�<key, value>��,����Ϊwordcount��������
private final static class MyReducer extends Reducer<>{
/**
* reduce��ִ��n��,����shuffle��,�ֳɼ�����(�м�����ͬ�ĵ���),ֱ��˵:�м�����ͬ�ĵ���,�����ķ����ͻ�ִ�м���
* ÿִ��һ��,Ҫ���㵱ǰ���ʳ��ֵ��ܴ���,������������hdfs��Ӧ�Ľ���ļ���
*
* key:key2,����,��ǰ�ĵ���,��:hello
* values:shuffle�δ�����ǰ���ʷ����ļ���,��:[1,1,1,1]
* context:������
* IOException:
* InterruptedException:
*/
@Override
protected void reduce(Text key,Iterable<IntWritable>,Context context) throws IOException,InterruptedException{
//����
//��һ��:�������������е�ֵ�ۻ�����
int totalCnt = 0;
for (IntWritable cnt:values){
int currentCnt = cnt.get();
totalCnt += currentCnt;
}
//�ڶ���������key3(��key2ֵ��ͬ,���ǵ���)��value3->��װ�˲���һ�ۼƵĵ�ǰ���ʳ��ֵ��ܴ���
Text key3 = key;
InterWritable value3 = new IntWritable(totalCnt);
//�������������ǰ�����Լ�������hdfs�Ϲ̻�����
context.write(key3,value3)
}
5.3.4�����طǷ�����
- ���Ҫ�������ز����ͽ������ز���
/**
* ǰ��:���طǷ��IJ���(Ҫ��̬)
* Ҫ��̬������������:����1->�������Ŀ¼;����2->�������ص�Ŀ¼
*/
if(args == null || args.length != 2){
System.out.println("�봫�����!ʹ��:yarn jar xx.jar Sample01WordCountMapReduce<input><output>");
System.exit(-1);
5.3.5��װ��job���ύ
- װ��job,����Job�ύ��Hadoop��Ⱥ��ȥ����
- �ٹ���Jobʵ��
- �ڽ��Զ����Mapperװ�䵽job��
- �۽��Զ����Reducerװ�䵽job��
- �ܽ�Job�ύ��Hadoop��Ⱥ��ȥ����
//2����ȡԴ�ļ�·����Ŀ���ļ�·��,���ݴ������
Path inputPath = new Path(args[0].trim());
Path ouputPath = new Path(args[1].trim());
try {
//3��װ��JOB,����Job�ύ��hadoop�ֲ�ʽ��Ⱥ
/**��һ��:����JOBʵ��,һ��job�а���һ������mapreduce
* ����JOB,��ͨ����̬��������ʵ��
* Configration:��ҵ�������
* Jobname:��ҵ����
*/
Class cls = Sample01WordCountMapReduce.class;
Configuration configuration = new Configuration();
String jobName = cls.getSimpleName(); //�����ļ�д,��������
Job job = Job.getInstance();
//�ڶ��������õ�ǰJob�����,������Ҳ�����ڵ�main����
job.setJarByClass(Sample01WordCountMapReduce.class);
//�����������Զ����Mapperװ�䵽Job��,�ײ�ʹ���˷���
//3.1��ָ��Mapper
job.setMapperClass(MyMapper.class);
//3.2������Mapper�������key2������
job.setMapOutputKeyClass(Text.class)
//3.3������Mapper�������value2������
job.setMapOutputValueClass(Text.class)
//3.4�����ô������Դ·��
FileInputFormat.setInputPaths(job,inputPath);
//3.5����ȡhdfs�ϵ�Դ���ڴ���ʱͨ���Ǹ�api��Դ���и�ʽ��
job.setInputFormatClass(TextInputFormat.class);
//���IJ������Զ����Reducerװ�䵽Job��
//4.1��ָ��Reducer
job.setReducerClass(MyReducer.class);
//4.2������Reducer�������key3������
job.setOutputKeyClass(Text.class);
//4.3������Reducer�������value3������
job.setOutputValueClass(Text.class);
//4.4�����ü������ص�hdfs�ϵ�Ŀ�ĵ�·��
FileOutputFormat.setOutputPaths(job,outputPath);
//4.5�����ڴ��еĽ��ͨ��ָ����ʵ�����������hdfs�ض����ļ��й̻�
job.setOutputFormatClass(TextOutputFormat.class);
//5����Job�ύ��hadoop�ֲ�ʽ��Ⱥ��ȥ����
job.waitForCompletion(True);
}catch(IOException | InterruptedException | ClassCastException e){
e.printStackTrace();
}
5.4�������
Դ�ļ�Ŀ¼:�������
Ŀ��Ŀ¼:���Զ�����Ŀ¼,���벻����,����ᱨ��,Ŀ¼�Ѵ���
- �������:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-PU9AzTqi-1627810650502)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210625120542375.png)]](https://img-blog.csdnimg.cn/90a481c1fba2475ca54e78747a0cf073.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI3OTI0NTUz,size_16,color_FFFFFF,t_70)
- �����ļ�

- ������
Ant_Man 1
Avengers 2
Black_Panther 1
Black_Widow 1
Captain_America 1
DC 2
Doctor_Strange 1
Gamora 1
Groot 1
Hawkeye 1
Hulk 1
Iron_Man 1
Loki 1
Mavel 2
Rocket_Raccoon 1
Scarlet_Witch 1
Spider_Man 1
Star_Lord 1
Thor 1
Vision 1
Winter_Soldier 1