前言
在之前的一篇文章中,我介绍了spark集群搭建的第一步,hadoop集群的搭建,在这篇文章中,我会继续讲解Spark集群的搭建过程。
OK,假设我们现在已经成功安装并且配置好了hadoop,接下来,我们开始正式进入Spark的安装过程。
1.Spark安装
首先我们需要在master节点上进行Spark的安装。我选择了2.0.2的版本,这里是下载链接。当然你也可以选择其他的版本,但是需要注意的是,如果你选择的Spark版本过高,可能导致无法与你的hadoop版本适配。
OK,完成下载后,进行如下的命令行操作,和hadoop安装时十分类似。
$ sudo tar -zxf ~/下载/spark-2.0.2-bin-without-hadoop.tgz -C /usr/local/ #解压到指定路径
$ cd /usr/local
$ sudo mv ./spark-2.0.2-bin-without-hadoop/ ./spark #重命名
$ sudo chown -R frank ./spark #修改权限2.环境变量配置
同样在master机器上,打开bashrc文件进行环境变量配置。
$ vim ~/.bashrc在文件中添加如下内容
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin并使其生效。
$ source ~/.bashrc
3.Spark集群配置
进入到/usr/local/spark的conf路径下,进行以下文件的配置。
a)slaves文件
但是由于其开始并没有这个文件,而只有slaves.template文件,所以我们需要先拷贝重命名一下。
$ cd /usr/local/spark/conf/
$ cp ./slaves.template ./slaves然后打开这个slaves文件,并将默认的localhos替换为slave(工作节点的主机名),因为我只有一台名为slave的工作机器,因此如下。
slaveb)spark-env.sh文件
同样的,我们需要先将template文件拷贝重命名。
$ cp ./spark-env.sh.template ./spark-env.sh然后在文件中添加如下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.56.9 #主节点的ip
4.复制到各个从节点
在master机器上进行如下操作。
$ cd /usr/local/
$ tar -zcf ~/spark.master.tar.gz ./spark
$ cd ~
$ scp ./spark.master.tar.gz slave:/home/frank #将frank 替换为你的用户名然后进入slave节点中,在终端输入如下指令,安装spark。
$ sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
$ sudo chown -R frank /usr/local/spark5.运行Spark
因为我们的Spark是基于hadoop来运行的,因此我们首先需要将hadoop启动起来。
在master机器上运行如下指令启动hadoop
$ cd /usr/local/hadoop/
$ sbin/start-all.sh然后我们再再master机器上启动Spark的master进程。
$ cd /usr/local/spark/
$ sbin/start-master.sh使用jps命令查看master机器上的进程情况,结果如下。
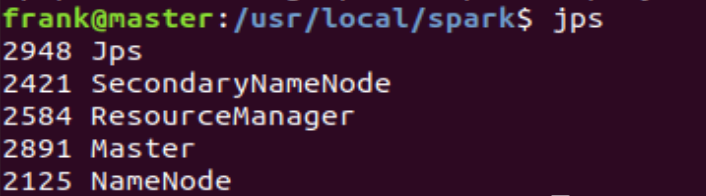
我们发现,除了hadoop的相关进程之外,还多了一个Master进程,证明master节点已经成功启动。
然后我们同样在master机器上再启动worker进程。
$ sbin/start-slaves.sh然后我们进入我们的slave机器,通过查看jps,结果如下。
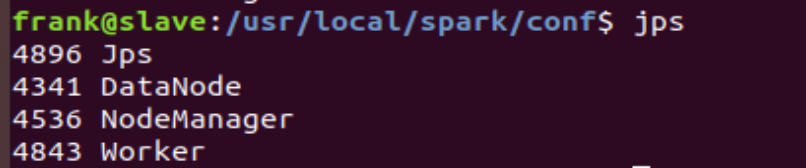
?我们发现,同样的除了hadoop的相关进程,多出来一个Worker进程,证明worker节点也已经成功启动。
OKK,到此为止,关于spark集群的整个搭建过程就差不多结束了,感谢大家的阅读。
参考: