下载地址
- Hadoop的下载:http://mirrors.cnnic.cn/apache/hadoop/common
本次是基于2.8.1版本
安装步骤
1.创建用户
- 用户名为hadoop,使用/bin/bash作为shell
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
su - hadoop
- 给hadoop分片ssh权限
编辑/etc/ssh/sshd_config文件
vim /etc/ssh/sshd_config
添加配置项
AllowUsers: hadoop
重启ssh
service sshd restart
如果出现ssh连接失败,可检查下面的日志
tail -100f /var/log/secure
2.设置JAVA_HOME
3.安装hadoop
>sudo tar -zxf ~/下载/hadoop-2.7.7.tar.gz -C /usr/local # 解压到/usr/local中
>cd /usr/local/
>sudo mv ./hadoop-2.7.7/ ./hadoop # 将文件夹名改为hadoop
>sudo chown -R hadoop ./hadoop # 修改文件权限
验证
>cd /usr/local/hadoop
>./bin/hadoop version
4.配置
4.1 Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
4.2 Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
- 修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
- 配置完成后,执行 NameNode 的格式化:
./bin/hdfs namenode -format
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。若JAVA_HOME设置正确,则修改./etc/hadoop/hadoop-env.sh添加环境变量expect JAVA_HOME=JDK安装路径
- 接着开启 NameNode 和 DataNode 守护进程。
./sbin/start-dfs.sh
启动 Hadoop 时提示 Could not resolve hostname
如果启动 Hadoop 时遇到输出非常多“ssh: Could not resolve hostname xxx”的异常情况
这个并不是 ssh 的问题,可通过设置 Hadoop 环境变量来解决。首先按键盘的 ctrl + c 中断启动,然后在 ~/.bashrc 中,增加如下两行内容(设置过程与 JAVA_HOME 变量一样,其中 HADOOP_HOME 为 Hadoop 的安装目录):
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
保存后,务必执行 source ~/.bashrc 使变量设置生效,然后再次执行 ./sbin/start-dfs.sh 启动 Hadoop。
- 验证启动成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MYmI24th-1628234664449)(evernotecid://8C4A8129-FDA9-4EC4-8DCC-EF481E5C8EE9/appyinxiangcom/10436148/ENResource/p522)]
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件
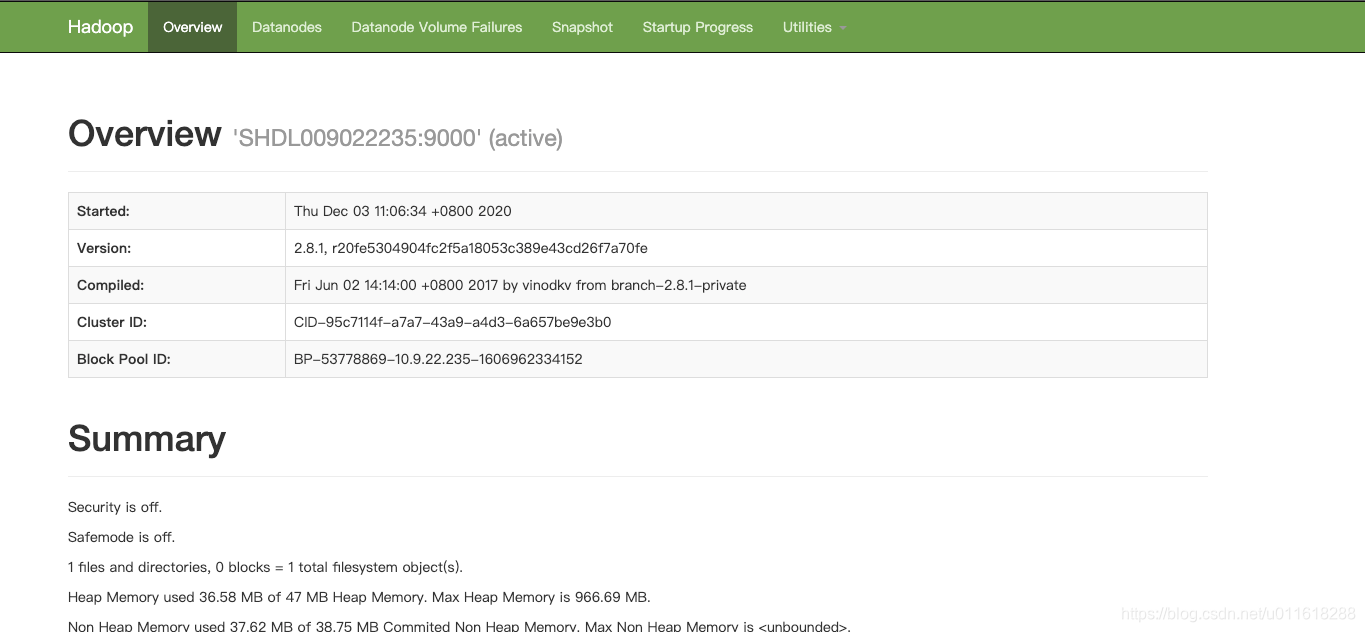
- 关闭Hadoop :
./sbin/stop-dfs.sh
Q&A
在上传文件报错
Caused by: org.apache.hadoop.ipc.RemoteException: Permission denied: user=flink, access=WRITE, inode="/":hadoop:supergroup:drwxr-xr-x
解决:
- 切换到hadoop用户 到hadoop master节点
- 创建文件目录
hadoop fs -mkdir /flink
- 将文件所有者改为上传用户
hdfs dfs -chown -R flink /flink