文章目录
Hadoop系列文章
Hadoop系列 (一):在CentOS中搭建hadoop环境(伪分布式)
Hadoop系列 (二):完全分布式搭建(腾讯云服务器+阿里云服务器)
ZooKeeper简介
概述
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等等。
从设计模式角度来说,是基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper中的角色主要有以下三类:

特点
-
Zookeeper:一个领导者(leader),多个跟随着(Follower)组成的集群。
-
可靠性:集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。如果消息被推送到一台服务器接收,那么它将被所有的服务器接收。
-
全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
-
顺序性:更新请求顺序进行,来自一个Client的更新请求按其发送的顺序依次执行。包括全局有序和偏序两种,全局有序是指如果在一台服务器上消息a在消息b之前发布,则所有的Server上消息a都将消息b之前发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
-
原子性:数据更新原子性,一次数据更新要么成功,要么失败。
-
实时性:在一定范围内,Client能读到最新数据。zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息,但由于网络延时等原因,zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync接口。
-
等待无关:慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
数据模型结构
Zookeeper数据模型的结构与Unix文件系统很类似,整体上可以看做是一棵树,每个节点称作一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
ZNode类型:
Zookeeper中znode的节点创建时候是可以指定类型的,主要有下面几种类型。
| ZNode类型 | 描述 |
|---|---|
| PERSISTENT | 持久化znode节点,一旦创建这个znode点存储的数据不会主动消失,除非是客户端主动的delete。 |
| SEQUENCE | 顺序增加编号znode节点,任意Client来创建这个znode都会得到一个比当前zookeeper命名空间最大znode编号+1的znode,也就说任意一个Client去创建znode都是保证得到的znode是递增的,而且是唯一的。 |
| EPHEMERAL | 临时znode节点,Client连接到zk service的时候会建立一个session,之后用这个zk连接实例创建该类型的znode,一旦Client关闭了zk的连接,服务器就会清除session,然后这个session建立的znode节点都会从命名空间消失。也就是说,这个类型的znode的生命周期是和Client建立的连接一样的。 |
| PERSISTENT|SEQUENTIAL | 顺序自动编号的znode节点,这种znoe节点会根据当前已近存在的znode节点编号自动加 1,而且不会随session断开而消失。 |
| EPHEMERAL|SEQUENTIAL | 临时自动编号节点,znode节点编号会自动增加,但是会随session消失而消失。 |
工作原理
Zookeeper 的核心是广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
-
恢复模式(选主):当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后, 恢复模式就结束了。
-
广播模式(同步):状态同步保证了leader和Server具有相同的系统状态。为了保证事务的顺序一致性,zookeeper采用了递增的事务id号 (zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用 来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数 。
每个Server在工作过程中有三种状态:
LOOKING: 当前Server不知道leader是谁,正在搜寻。
LEADING: 当前Server即为选举出来的leader。
FOLLOWING: leader已经选举出来,当前Server与之同步。
选主流程
当 leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的 Server都恢复到一个正确的状态。
Zookeeper的选举算法有两种:
一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。
系统默认的选举算法为fast paxos。
basic paxos
流程如下:

- 选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
- 选举线程首先向所有Server发起一次询问(包括自己);
- 选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
- 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
- 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
fast paxos
在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。

规则:
集群中的每台机器发出自己的投票后,也会接受来自集群中其他机器的投票。每台机器都会根据一定的规则,来处理收到的其他机器的投票,以此来决定是否需要变更自己的投票:
-
初始阶段,都会给自己投票。
-
当接收到来自其他服务器的投票时,都需要将别人的投票和自己的投票进行pk,规则如下:
优先检查zxid。zxid比较大的服务器优先作为leader。
如果zxid相同的话,就比较sid,sid比较大的服务器作为leader。
举个列子:
假设当前集群中有5台机器组成。sid分别为1,2,3,4,5。zxid分别为8,8,8,7,6,并且此时sid为2的机器是leader。某一时刻,1和2的服务器挂掉了,集群开始进行选主。
-
在第一次投票中,由于无法检测到集群中其他机器的状态信息,因此每台机器都将自己作为被推举的对象来进行投票。于是sid为3,4,5的机器,投票情况分别为(3,8),(4,7),(5,6)
-
每台机器把投票发出后,同时也会接收到来自另外两台机器的投票。
-
对于server3来说,接收到(4,7),(5,6)的投票,对比后,由于自己的zxid要大于收到的另外两个投票,因此不需要做任何变更。
-
对于server4来说,接收到(3,8),(5,6)的投票,对比后由于(3,8)这个投票的zxid大于自己,因此需要变更投票为(3,8),然后继续将这个投票发送给另外两台机器。
-
对于server5来说,接收到(3,8),(4,7)的投票,对比后由于(3,8)这个投票的zxid大于自己,因此需要变更投票为(3,8),然后继续将这个投票发送给另外两台机器。
-
经过第二轮投票后,集群中的每台机器都会再次受到其他机器的投票,然后开始统计投票。判断是否有过半的机器收到相同的投票信息,如果有,那么该投票的sid会成为新的leader。
-
机器总数为5台,server3,4,5都收到投票(3,8)。因此server3成为leader。
同步流程
选完leader以后,zookeeper就进入状态同步过程:
- Leader等待Server连接
- Follower连接Leader,将最大的zxid发送给Leader
- Leader根据Follower的zxid确定同步点
- 完成同步后,通知Follower已经成为up-to-date状态
- Follower收到up-to-ate消息后,又可以重新接收Client的请求服务
工作流程
Leader工作流程
- 恢复数据。
- 维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型。
Learner的消息类型:
| Learner的消息类型 | 描述 |
|---|---|
| PING消息 | Learner的心跳信息 |
| REQUEST消息 | Follower发送的提议信息,包括写请求及同步请求 |
| ACK消息 | Follower的对提议 的回复,超过半数的Follower通过,则commit该提议 |
| REVALIDATE消息 | 用来延长SESSION有效时间 |
Leader会根据不同的消息类型,进行不同的处理。
Follower工作流程
-
向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
-
接收Leader消息并进行处理;
-
接收Client的请求,如果为写请求,发送给Leader进行投票;
-
返回Client结果。
Follower会循环处理来自Leader的消息:
| 消息类型 | 描述 |
|---|---|
| PING消息 | 心跳消息 |
| PROPOSAL消息 | Leader发起的提案,要求Follower投票 |
| COMMIT消息 | 服务器端最新一次提案的信息 |
| UPTODATE消息 | 表明同步完成 |
| REVALIDATE消息 | 根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息 |
| SYNC消息 | 返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新 |
应用场景
Zookeeper提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务

统一配置管理
分布式环境下,会频繁进行配置文件同步。一般一个集群中,所有节点的配置信息是要求一致的,对配置文件修改后,希望能够快速同步到各个节点上。此时,配置管理可交由Zookeeper实现:
- 可将配置信息写入ZK上的一个Znode
- 各个客户端服务器监听这个Znode
- 一旦Znode中的数据被修改,ZK将通知各个客户端的服务器

统一集群管理

负载均衡

ZooKeeper搭建
Zookeeper运行模式分 单点模式 和 集群模式。
文件下载:
[hadoop@master ~]$ wget -P /home/hadoop/software https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
版本选择见:https://archive.apache.org/dist/zookeeper/
解压到目录/opt/zookeeper
[hadoop@master software]$ sudo tar zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /opt/zookeeper --strip-components 1
注意:apache-zookeeper-3.7.0-bin.tar.gz 而不是apache-zookeeper-3.7.0.tar.gz,否则启动时会报错Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain
修改/opt/zookeeper文件夹权限为hadoop
[hadoop@master opt]$ sudo chown -R hadoop:hadoop zookeeper/
单点模式
创建配置文件
根据conf目录下的zoo_sample.cfg 创建配置文件zoo.cfg,
启动时默认就是按照zoo.cfg这个配置文件的信息来启动。
[hadoop@master conf]$ pwd
/opt/zookeeper/conf
[hadoop@master conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@master conf]$ ll
total 16
-rw-r--r-- 1 hadoop hadoop 535 Mar 17 2021 configuration.xsl
-rw-r--r-- 1 hadoop hadoop 3435 Mar 17 2021 log4j.properties
-rw-r--r-- 1 hadoop hadoop 1148 Oct 18 10:43 zoo.cfg
-rw-r--r-- 1 hadoop hadoop 1148 Mar 17 2021 zoo_sample.cfg
修改文件zoo.cfg

zookeeper主要会在内存里面维护znode的数据结构,让你高性能地去读写。但同时也会把数据往磁盘里面存。所以必须配置磁盘数据/日志所存放的目录: dataDir/dataLogDir。
面向客户端开放的端口号:clientPort=2181。
修改环境变量
在.bash_profile文件末尾添加如下内容:
#set zookeeper env
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使.bash_profile生效
[hadoop@master ~]$ source .bash_profile
[hadoop@master ~]$ echo $ZOOKEEPER_HOME
/usr/local/zookeeper
服务启动
[hadoop@master conf]$ cd ../bin
[hadoop@master bin]$ sh zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# 查看zk进程
[hadoop@master bin]$ jps
23056 Jps
23015 QuorumPeerMain
# 查看当前zookeeper状态
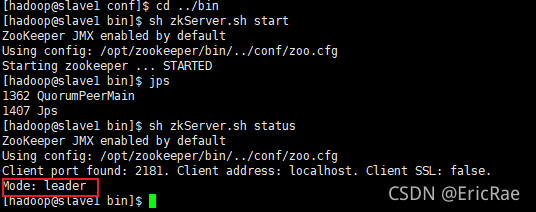
[hadoop@master bin]$ sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
#使用zkCli.sh连接zk的本地server
[hadoop@master bin]$ sh zkCli.sh
Connecting to localhost:2181
...
2021-10-18 16:10:20,424 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1438] - Session establishment complete on server localhost/127.0.0.1:2181, session id = 0x10000878f890000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls
ls [-s] [-w] [-R] path
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 2]
停止服务
[hadoop@master bin]$ sh zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
集群模式
集群模式的搭建和单点模式的差别不大,如果按照官方的最低要求,就是三台服务器,在这三台服务器上面分别执行一下上述单点模式的步骤,同一集群下的每台服务器的配置文件类似。
基于上述单点模式搭建,集群模式的搭建,修改zoo.cfg文件,在文件末尾添加集群信息:
# 集群信息,我的slave2服务器过期了,没续费,就两台凑合着吧
server.1=master:2888:3888
server.2=slave1:2888:3888
# server.3=slave2:2888:3888
在每个Zookeeper服务器对应的dataDir目录下需要创建一个名为myid的文件,这个文件中仅含有一行的内容,指定的是自身的 id 值,就是server.id=host:port1:port2中的id值。这个 id 值必须是集群中唯一的:
[hadoop@master data]$ echo 1 > myid
[hadoop@master data]$
文件分发,将zookeeper分发到另外两台服务器slave1,slave2上:
[hadoop@master opt]$ scp -r zookeeper hadoop@slave1:/opt/
# 如果权限问题,无法直接放到slave1的/opt/目录下,可以先放到其他目录,然后move
#修改myid
[hadoop@slave1 data]$ echo 2 > myid
[hadoop@slave1 data]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 2 Oct 18 16:22 myid
drwxrwxr-x 2 hadoop hadoop 24 Oct 18 16:19 version-2
# 编辑slave1的.bash_profile,添加环境变量
#set zookeeper env
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#slave2进行同样操作
确认每台服务器上的zoo.cfg和myid文件修改创建之后,在三个节点上分别执行命令sh zkServer.sh start,启动zookeeper server