举例 查询语句
{
"query": {
"bool": {
"must": [
{
"term": { // 未删除
"isdeleted": "0"
}
},
{
"term": { // 未下架
"updown": "1"
}
},
{
"term": { // 未成交
"cjflag": "0"
}
}
],
"must_not": [
{
"term": { // 核验编码不为空
"government_code.keyword": ""
}
},
{
"term": { // 核验编码图 不为空
"government_qr.keyword": ""
}
}
]
}
},
"sort": {
"istop": {
"order": "desc"
},
"flag3d": {
"order": "desc"
},
"hasimg": {
"order": "desc"
},
"housesexchangescore": {
"order": "desc"
},
"housesid": {
"order": "desc"
},
"firstuptime": {
"order": "desc"
}
},
"_source": [ // 指定返回两个字段
"government_code",
"government_qr"
],
"from": 0,
"size": 30
}
结果结构题
took:表示整个搜索请求花费了多少毫秒
hits.total:本次搜索,返回了几条结果
hits.max_score:本次搜索的所有结果中,最大的相关度分数是多少。每一条document对于search的相关度,越相关,_score分数越大,排位越靠前
hits.hits:默认查询出前10条数据,完整数据,_score降序排序
shards:shard fail的条件,不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
timeout:默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制
GET /_search
{
"took": 19, //took:表示整个搜索请求花费了多少毫秒
"timed_out": false, //timeout:默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制
"_shards": { //shards:shard fail的条件,不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
"total": 21,
"successful": 21,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 32538, //hits.total:本次搜索,返回了几条结果
"max_score": 1, //hits.max_score:本次搜索的所有结果中,最大的相关度分数是多少。每一条document对于search的相关度,越相关,_score分数越大,排位越靠前
"hits": [ // 默认查询出前10条数据,完整数据,_score降序排序
{
"_index": ".kibana",
"_type": "doc",
"_id": "config:6.4.0",
"_score": 1,
"_source": {
"type": "config",
"updated_at": "2018-09-12T16:02:30.105Z",
"config": {
"buildNum": 17929,
"telemetry:optIn": true
}
}
}
.......
搜索模式
/_search:所有索引,所有type下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有type的数据
/index1,index2/_search:同时搜索两个index下的数据
/*1,*2/_search:按照通配符去匹配多个索引
/index1/type1/_search:搜索一个index下指定的type的数据
/index1/type1,type2/_search:可以搜索一个index下多个type的数据
/index1,index2/type1,type2/_search:搜索多个index下的多个type的数据
/_all/type1,type2/_search:_all,可以代表搜索所有index下的指定type的数据
语法
Search timeout
1、 设置:默认没有timeout,如果设置了timeout,那么会执行timeout机制。
2、Timeout机制:假设用户查询结果有1W条数据,但是需要10s才能查询完毕
用户设置了1s″的timeout
那么不管当前一共查询到了多少数据,都会在1s″后ES讲停止查询,并返回当前数据。
3、用法:GET /_search?timeout=1s /ms /m(单位)
Query DSL
1、 match_all:可以查询到所有文档,是没有查询条件下的默认语句
此查询常用于合并过滤条件。 比如说你需要检索所有的邮箱,所有的文档相关性都是相同的,所以得到的_score 为 1.
GET /product/_search
{
"query":{
"match_all": {}
}
}
2、 match:name中包含“nfc”
查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符:
GET /product/_search
{
"query": {
"match": {
"name": "nfc"
}
}
}
如果用match下指定了一个确切值,在遇到数字,日期,布尔值或者not_analyzed 的字符串时,它将为你搜索你给定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
提示: 做精确匹配搜索时,你最好用过滤语句,因为过滤语句可以缓存数据。
match查询只能就指定某个确切字段某个确切的值进行搜索,而你要做的就是为它指定正确的字段名以避免语法错误。
3、multi_match:根据多个字段查询一个关键词,name和desc中包含“nfc”的doc
multi_match查询允许你做match查询的基础上同时搜索多个字段,在多个字段中同时查一个
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
4、 sort:按照价格倒序排序
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
5、_source 元数据:想要查询多个字段,例子中为只查询“name”和“price”字段。
GET /product/_search
{
"query":{
"match": {
"name": "nfc"
}
},
"_source": ["name","price"]
}
6、分页(deep-paging):查询第一页(每页两条数据)
GET /product/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 2
}
Full-text queries
1、query-term:不会被分词
(name:nfc phone)中nfc phone不会被分词,但是doc会被分词,所以在es中查找时结果为0
term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型):
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text"}}
terms 过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
GET /product/_search
{
"query": {
"term": {
"name": "nfc phone"
}
}
}
--------------
GET /product/_search
{
"query": {
"terms": {
"name":["nfc","phone"]
}
}
}
2、match和term的区别:
GET /product/_search
{
"query": {
"term": {
"name": "nfc phone" 这里因为没有分词,所以查询没有结果
}
}
}
3、全文检索
GET /product/_search
{
"query": {
"match": {
"name": "xiaomi nfc zhineng phone"
}
}
}
----------
# 验证分词
GET /_analyze
{
"analyzer": "standard",
"text":"xiaomi nfc zhineng phone"
}
短语搜索
就像用于全文搜索的的match查询一样,当你希望寻找邻近的单词时,match_phrase查询可以帮你达到目的。
GET /product/_search
{
"query": {
"match_phrase": {
"name": "nfc phone"
}
}
}
查询和过滤
1、bool 查询
可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
①must:查询指定文档一定要被包含
子句(查询)必须出现在匹配的文档中,并将有助于得分。
②filter:过滤器,不计算相关度分数
子句(查询)必须出现在匹配的文档中。但是不像 must查询的分数将被忽略。
Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句被考虑用于缓存。
③should:查询指定文档,有则可以为文档相关性加分
子句(查询)应出现在匹配的文档中。
④must_not:必须不满足 不计算相关度分数,查询指定文档一定不要被包含
子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略
并且子句被视为用于缓存。由于忽略计分,0 因此将返回所有文档的分数。
-- 实际使用 貌似不能 传多个值或多个值性能很差
⑤minimum_should_match:should 配合使用,满足几个should条件
⑥range过滤:lt大于,gt小于
- gt :: 大于
- gte:: 大于等于
- lt :: 小于
- lte:: 小于等于
#首先筛选name包含“xiaomi phone”并且价格大于1999的数据(不排序),
#然后搜索name包含“xiaomi”and desc 包含“shouji”
GET /product/_search
{
"query": {
"bool":{
"must": [
{"match": { "name": "xiaomi"}},
{"match": {"desc": "shouji"}}
],
"filter": [
{"match_phrase":{"name":"xiaomi phone"}},
{"range": {
"price": {
"gt": 1999
}
}}
]
}
}
}
以下查询将会找到 title 字段中包含 “how to make millions”,并且 “tag” 字段没有被标为 spam。 如果有标识为 “starred” 或者发布日期为2014年之前,那么这些匹配的文档将比同类网站等级高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
提示: 如果bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有must子句,那么没有should子句也可以进行查询。
2、bool多条件(过滤)
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
- must :: 多个查询条件的完全匹配,相当于 and。
- must_not :: 多个查询条件的相反匹配,相当于 not。
- should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组
name 包含xiaomi 不包含 erji 描述里包不包含nfc都可以,价钱要大于等于4999
GET /product/_search
{
"query": {
"bool":{
#name中必须包含“xiaomi”
"must": [
{"match": { "name": "xiaomi"}}
],
#name中必须不能包含“erji”
"must_not": [
{"match": { "name": "erji"}}
],
#should中至少满足0个条件,参见下面的 minimum_should_match 的解释
"should": [
{"match": {
"desc": "nfc"
}}
],
#筛选价格大于4999的doc
"filter": [
{"range": {
"price": {
"gt": 4999
}
}}
]
}
}
}
------------------
参考二
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}
3、嵌套查询
minimum_should_match:参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或 filter子句,则默认值为1。否则,默认值为0
GET /product/_search
{
"query": {
"bool": {
"filter": {
"bool": {
"should": [
{ "range": {"price": {"gt": 1999}}},
{ "range": {"price": {"gt": 3999}}}
],
"must": [
{ "match": {"name": "nfc"}}
]
}
}
}
}
}
4、组合查询
搜索一台xiaomi nfc phone或者一台满足 是一台手机 并且 价格小于等于2999
GET /product/_search
{
"query": {
"constant_score": {
"filter": {
"bool":{
"should":[
{
"match_phrase":{
"name":"xiaomi nfc phone"
}
},
{
"bool":{
"must":[
{"term":{"name":"phone"}},
{
"range":{
"price":{
"lte":"2999"
}
}
}
]
}
}
]
}
}
}
}
}
5、高亮
GET /product/_search
{
"query" : {
"match_phrase" : {
"name" : "nfc phone"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
6、exists 和 missing 过滤
exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件.
{ "exists": { "field": "title" } }
这两个过滤只是针对已经查出一批数据来,但是想区分出某个字段是否存在的时候使用。
7、wildcards 查询
使用标准的shell通配符查询 官方文档
# 以下查询能够匹配包含W1F 7HW和W2F 8HW的文档
GET /my_index/address/_search
{
"query": {
"wildcard": {
"postcode": "W?F*HW"
}
}
}
-----------------------
# 又比如下面查询 hostname 匹配下面shell通配符的:
{
"query": {
"wildcard": {
"hostname": "wxopen*"
}
}
}
7、regexp 查询 参考: ES官网点击直达
假设您只想匹配以W开头,紧跟着数字的邮政编码。使用regexp查询能够让你写下更复杂的模式
GET /my_index/address/_search
{
"query": {
"regexp": {
"postcode": "W[0-9].+"
}
}
}
# 这个正则表达式的规定了词条需要以W开头,紧跟着一个0到9的数字,然后是一个或者多个其它字符。
# 例子是所有以 wxopen 开头的正则
{
"query": {
"regexp": {
"hostname": "wxopen.*"
}
}
}
8、prefix 查询, 参考: ES官网点击直达
以什么字符开头的,可以更简单地用 prefix,如下面的例子:
{
"query": {
"prefix": {
"hostname": "wxopen"
}
}
}
更多命令 ,ES官网点击直达
Deep paging问题
使用场景:当你的数据超过1W时,不要使用,返回不要超过1000个
解决办法:尽量避免深查询,使用Scroll search
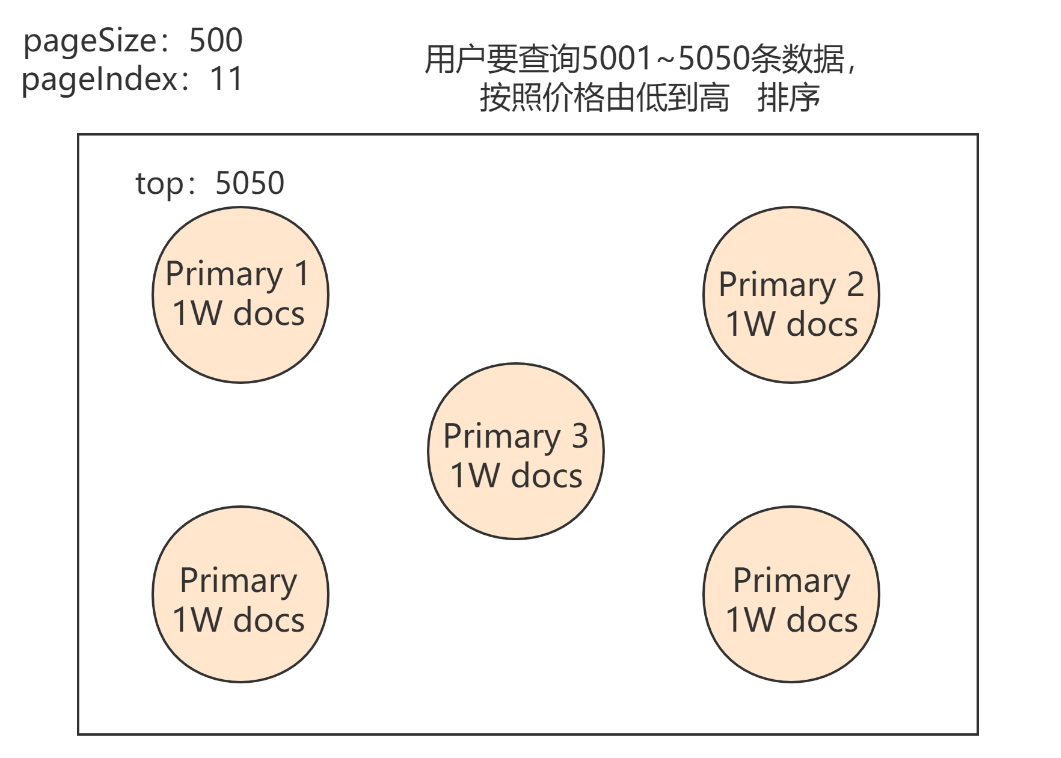
如上图所示:
用户要查询5001~5050条数据。一个集群有5个PShard分片构成完整数据,每个PShard中有1W数据,这时ES会在每个分片中将前5050条数据取出,这时一共会取出25250条数据,十分耗性能
?