- 传统分布式文件系统中文件存储的缺点:
1.磁盘负载不均衡。
举例来说,在两台机器上的两个1TB的磁盘中,如果一个机器上存储了一个50MB的文件,另一个机器上存储了一个50GB的文件,就会导致这两台机器上的磁盘使用率有较大的差别,也即负载不均衡。
2.读取数据的速度受到限制。
举例来说,如果一个文件是1.3TB,那么该文件在存储时会被分割成1TB和0.3TB两个文件,而磁盘的大小为1TB,那么这两个拆分出来的文件就要被存储在两个机器上,当某个业务逻辑是需要读取这两个子文件进行计算时,就会出现0.3TB的这个子文件很快就被读完了,而1TB的这个文件要花较多的时间进行读取,使得读取0.3TB文件的这个程序要等待1TB文件的读取结果才能使整个业务逻辑进行下一步处理,这样就会造成资源的浪费。
- HDFS中的块
HDFS中的块相对于传统文件存储系统的块大小来说是较大的,并且是可以自定义的。块是HDFS中的最小存储单位,在hadoop2.x中默认大小是128MB,在hadoop1.x中默认是64MB,在hadoop3.x中默认大小是256MB。在HDFS中存储文件时,会将文件拆分成块,以块为单位进行存储,如果一个文件按照128MB(块大小)进行拆分,可能最后一个文件拆分出来的大小不足128MB,此时该子文件不会将整个块的128MB都占用;拆分出来的块会有它相应的副本,块与其副本会存在不同的DataNode上以实现副本机制。拆分出来的多个块也尽可能地存储在不同的DataNode上以实现负载均衡,但块与其他块的副本可以存储在同一个节点上,因为他们本身就是互不相干的数据。
- 为什么HDFS中的块大小远大于传统文件中的块大小?
1.因为在读取文件时寻址时间占用了较大的开销,也即想要读取某个文件时,花了较长的时间去寻找文件所在块的起始地址,找到起始位置后,读取文件时是顺序读取,用时开销较短。而近年来,随着硬盘的传输速度逐渐提高,块的大小也相应地增大了。
2.由于一个块的metedata大约在内存中占用150个字节,metadata的数据会存储在NameNode的内存中。无论这个块的大小是多少,它的metadata都是要占用150个字节,那么在大体量的数据存储集群中,将块的大小设置的相对大一些也是在提高数据的存储性能,能够存储更多的数据。
- 块大小的配置
块大小的配置在$HADDOP_HOME/etc/hadoop/hdfs-site.xml中:

- ?块的存储位置
在$HADDOP_HOME/etc/hadoop/core-site.xml中我们配置了一个目录,该目录下会存储NameNode和DataNode的数据。
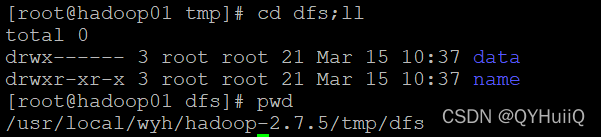
在data目录下存储的是DataNode的数据:
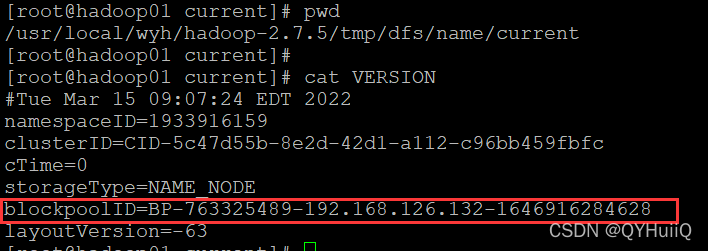
 ?这里面的BP-XXXXXXX是表示BlockPool(块池),后面的一串id是要和集群的id保持一致的。
?这里面的BP-XXXXXXX是表示BlockPool(块池),后面的一串id是要和集群的id保持一致的。
我们可以看到name目录下NameNode节点存储的集群id:
?再次进入到data目录下查看块池下面的内容,?这里可以看到很多blk(block)开头的文件,这就是块所存储的位置:

?参考视频:bilibili.com/video/BV18y4y1G7JA?p=9