每遇到一个问题,在经过努力研究明白之后,总想写点东西记录。怎奈又没这个好习惯,过了一两天这个激情就没了,想写也写不出来了。这个问题耗费了我两个早上,今天必须趁热打铁,记录一波
最近研究了一段时间Flink-CDC,感觉使用还是比较简单,准备产品化的开发。
在研究测试时,开始新建一张MySQL表:products
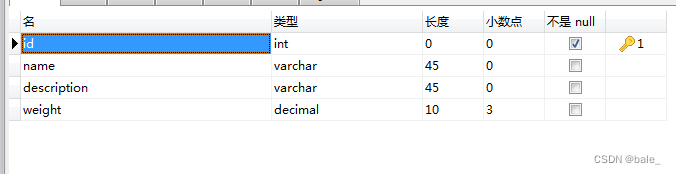
插入一些数据:

?搬过来官网的示例代码
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("...")
.port(...)
.databaseList("...") // set captured database
.tableList("products") // set captured table
.username("...")
.password("...")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}?Run as 看打印结果,嗯? 怎么weight字段的值变这样了

?开始上网查资料,各种搜索,居然找不到,这也是为什么想写篇文章记录一下的原因。
没办法,只能看源码,查了一下资料,各种自定义解码器的文章倒是挺多,但是看了一下官方提供的json解码器JsonDebeziumDeserializationSchema,那些自定义的都是一坨屎,明明有个很牛逼的不知道用好,还有人要重新自定义JSON解码器,然而又写的稀巴烂,还各种抄来抄去。
从JsonDebeziumDeserializationSchema类进去,经过多层方法调用最终看到将Object转成JSON的方法叫convertToJson
/**
* Convert this object, in the org.apache.kafka.connect.data format, into a JSON object, returning both the schema
* and the converted object.
*/
private JsonNode convertToJson(Schema schema, Object value) {
//源码略
}断点调试到这个方法中,可以看到有个LogicalTypeConverter不为空
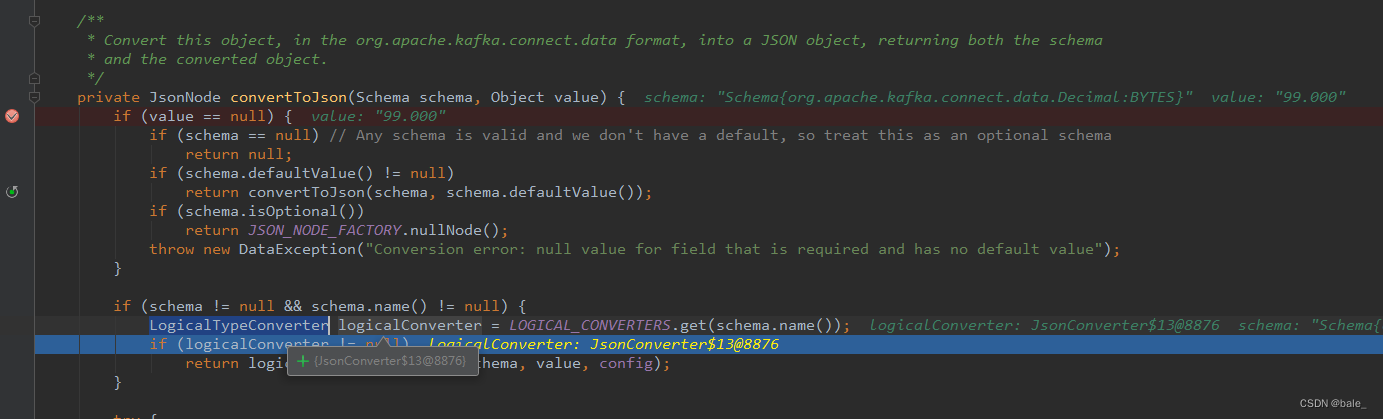
于是再进这个LOGICAL_CONVERTERS看一下 ,这里面单独定义了Decimal、Date、Time等类型的处理逻辑,其他简单类型的处理放在了TO_CONNECT_CONVERTERS中。继续断点调试可以看到Dicimal类型直接就进了BASE64的case
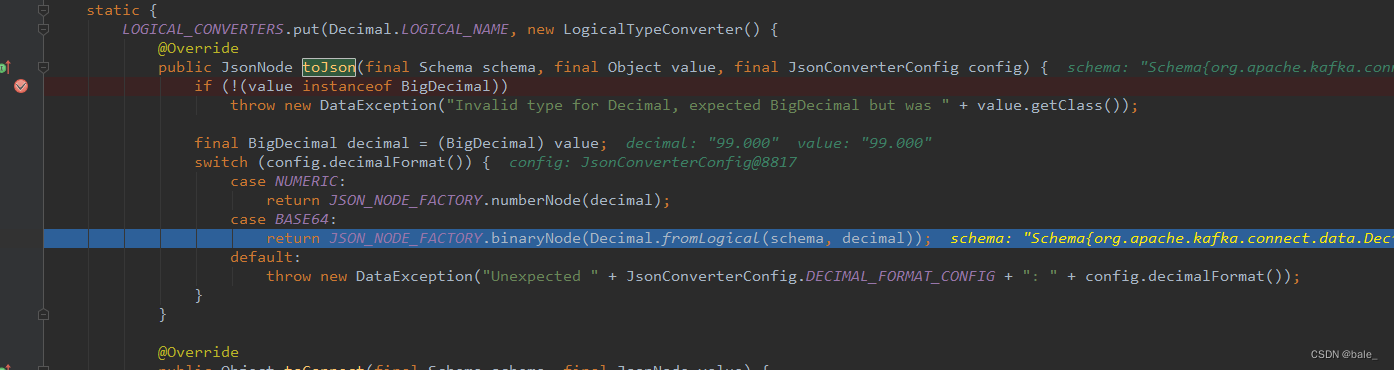
而这个类型是通过参数JsonConverterConfig传进来的,往上推,可以看到这个参数是解码器初始化的时候被实例化的,而且还接受了自定义参数customConverterConfigs
/** Initialize {@link JsonConverter} with given configs. */
private void initializeJsonConverter() {
jsonConverter = new JsonConverter();
final HashMap<String, Object> configs = new HashMap<>(2);
configs.put(ConverterConfig.TYPE_CONFIG, ConverterType.VALUE.getName());
configs.put(JsonConverterConfig.SCHEMAS_ENABLE_CONFIG, includeSchema);
if (customConverterConfigs != null) {
configs.putAll(customConverterConfigs);
}
jsonConverter.configure(configs);
}?那么问题就好办了,指定Decimal的格式为NUMERIC不就可以了,于是自定义一个customConverterConfigs
public static void main(String[] args) throws Exception {
Map config = new HashMap();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
JsonDebeziumDeserializationSchema jdd = new JsonDebeziumDeserializationSchema(false, config);
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("...")
.port(...)
.databaseList("...") // set captured database
.tableList("products") // set captured table
.username("...")
.password("...")
.deserializer(jdd)
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}?在Run as 看打印结果,这下Happy了

?可以看到已经变成想要的结果了。
后来进入产品化开发,打包到flink集群测试执行,采集oracle的时候总是同步不成功,同步成功了,也有一些字段的值变成空了,继续看了一下原表字段类型,才明白还是数值类型的问题,主键是number类型,同步之后类型还是被编码成BASE64,数仓的表是数字类型,不能插入。于是还得再测试验证一下,创建一张有各种number类型字段的表
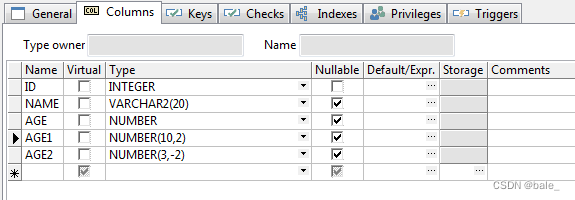
简单插入两条数据

读取方法?
public static void main(String[] args) throws Exception {
Map config = new HashMap();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
JsonDebeziumDeserializationSchema jdd = new JsonDebeziumDeserializationSchema(false, config);
SourceFunction<String> sourceFunction = OracleSource.<String>builder()
.hostname("...")
.port(...)
.database("...") // monitor XE database
.schemaList("...") // monitor inventory schema
.tableList("...") // monitor products table
.username("...")
.password("...")
.deserializer(jdd) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(sourceFunction)
.print()
.setParallelism(1)
; // use parallelism 1 for sink to keep message ordering
env.execute();
}?看执行输出

更奇怪了,又去对JsonDebeziumDeserializationSchema一通研究,发现number类型,没设置p、s时,Flink-CDC读取的记录中就已经变成了Struct类型,通过解码器解决不了问题了。但是看到解码器可以通过设置includeSchema=true返回Schema,那是不是可以根据返回的Schema 的type判断是数值类型在取出value来Base64解码.....! 但是,类似这样想法的代码写法,在项目中实在是太多了,我不想也沦为这种垃圾代码的制造者。
继续查一下吧,是这个提问(请教大佬们,oracle cdc的NUMBER类型,打印出来为什么变成字符串了呢,怎么转换回去?-问答-阿里云开发者社区-阿里云)启发了我,虽然回答中那个参数试了一下无效,但是我找到了正确答案,后来还再次回答了这个问题
于是到Flink-CDC官网(Oracle CDC Connector ― CDC Connectors for Apache Flink? documentation)看看有没有什么参数可以控制这个类型的转换
可以看到,Flink-CDC提供的参数都比较简单,于是再去debezium看看
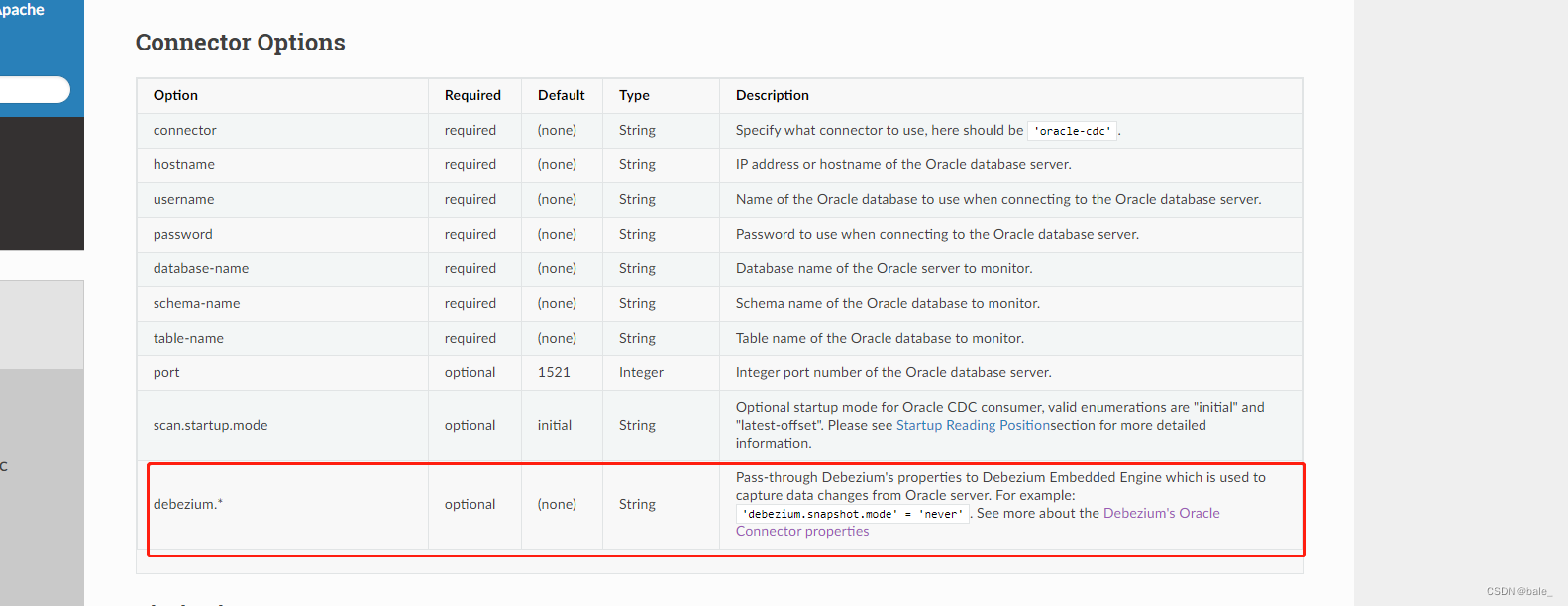
到debezium网站找啊找啊找,找到了一个神奇的和我想像中一样的参数,它叫decimal.handling.mode
?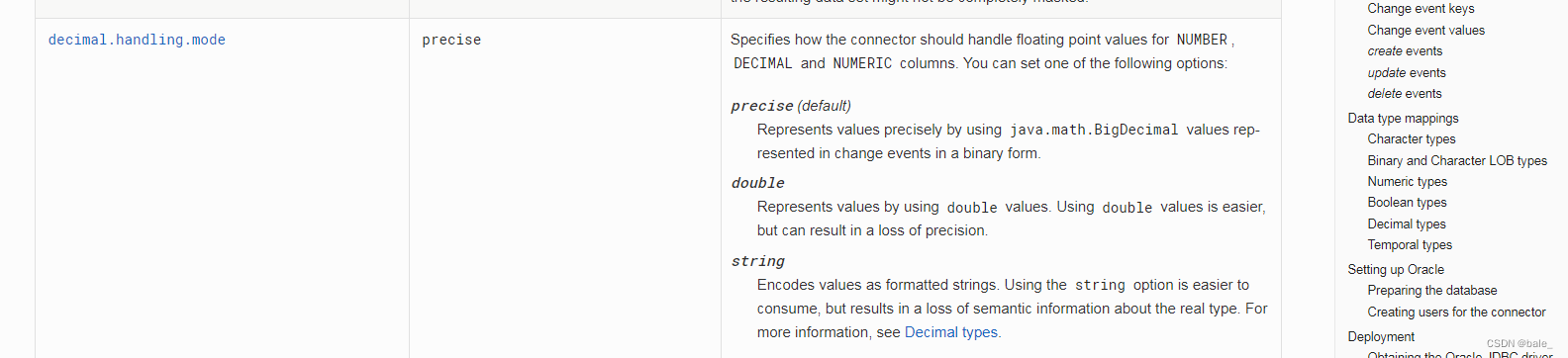
可以看到这个参数默认值 是precise,还有其他两个可选值double和string
看看说明,简单理解一下
precise 以java中的精确类型来表示值
double 使用比较容易,但是会造成精度损失
string? 也比较容易使用,但是会造成字段语意信息丢失
那么我直接整个string不就完美了,转成json就只有值了,我管你什么语意
果断试一下
public static void main(String[] args) throws Exception {
Properties prop = new Properties();
prop.put("decimal.handling.mode", "string");
SourceFunction<String> sourceFunction = OracleSource.<String>builder()
.hostname("...")
.port(...)
.database("...") // monitor XE database
.schemaList("...") // monitor inventory schema
.tableList("...") // monitor products table
.username("...")
.password("...")
.debeziumProperties(prop)
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(sourceFunction)
.print()
.setParallelism(1)
; // use parallelism 1 for sink to keep message ordering
env.execute();
}看到结果,瞬间通透了

?还看了一下debezium的其他参数,非常多,还需要持续的学习
结论不重要,学习的过程很重要