0. 引言
之前我们讲解了通过canal来实现mysql数据同步到elasticsearch。我们实际生产中,往往更加常见的应用是mysql之间的数据同步,比如主从同步,异地机房数据同步等等。
我们之前也讲过了通过MTS来实现mysql主从同步,所以本期我们来讲讲通过canal实现异地机房mysql数据同步
1. canal简介
canal是阿里开源的数据同步工具,基于bin log可以将数据库同步到其他各类数据库中,目标数据库支持mysql,postgresql,oracle,redis,MQ,ES等
2. 安装
2.1 安装jdk
canal是基于java环境的,因此运行前需要先安装jdk,这里我安装的是jdk1.8。详细步骤就不再累述了。
canal1.1.5使用jdk1.8即可,但是以下我示例的是canal1.1.6。该版本需要使用jdk11+,否则会报错NoSuchMethodError,详细报错信息如下:
java.lang.NoSuchMethodError: java.nio.ByteBuffer.clear()Ljava/nio/ByteBuffer;
at com.alibaba.otter.canal.client.impl.SimpleCanalConnector.readNextPacket(SimpleCanalConnector.java:412) ~[na:na]
at com.alibaba.otter.canal.client.impl.SimpleCanalConnector.readNextPacket(SimpleCanalConnector.java:397) ~[na:na]
at com.alibaba.otter.canal.client.impl.SimpleCanalConnector.doConnect(SimpleCanalConnector.java:155) ~[na:na]
at com.alibaba.otter.canal.client.impl.SimpleCanalConnector.connect(SimpleCanalConnector.java:116) ~[na:na]
at com.alibaba.otter.canal.connector.tcp.consumer.CanalTCPConsumer.connect(CanalTCPConsumer.java:63) ~[na:na]
at com.alibaba.otter.canal.adapter.launcher.loader.AdapterProcessor.process(AdapterProcessor.java:185) ~[client-adapter.launcher-1.1.6.jar:na]
2.2 安装canal
1、截止本文,canal的稳定版已更新到1.1.6了, 所以本文也以这个版本为例。
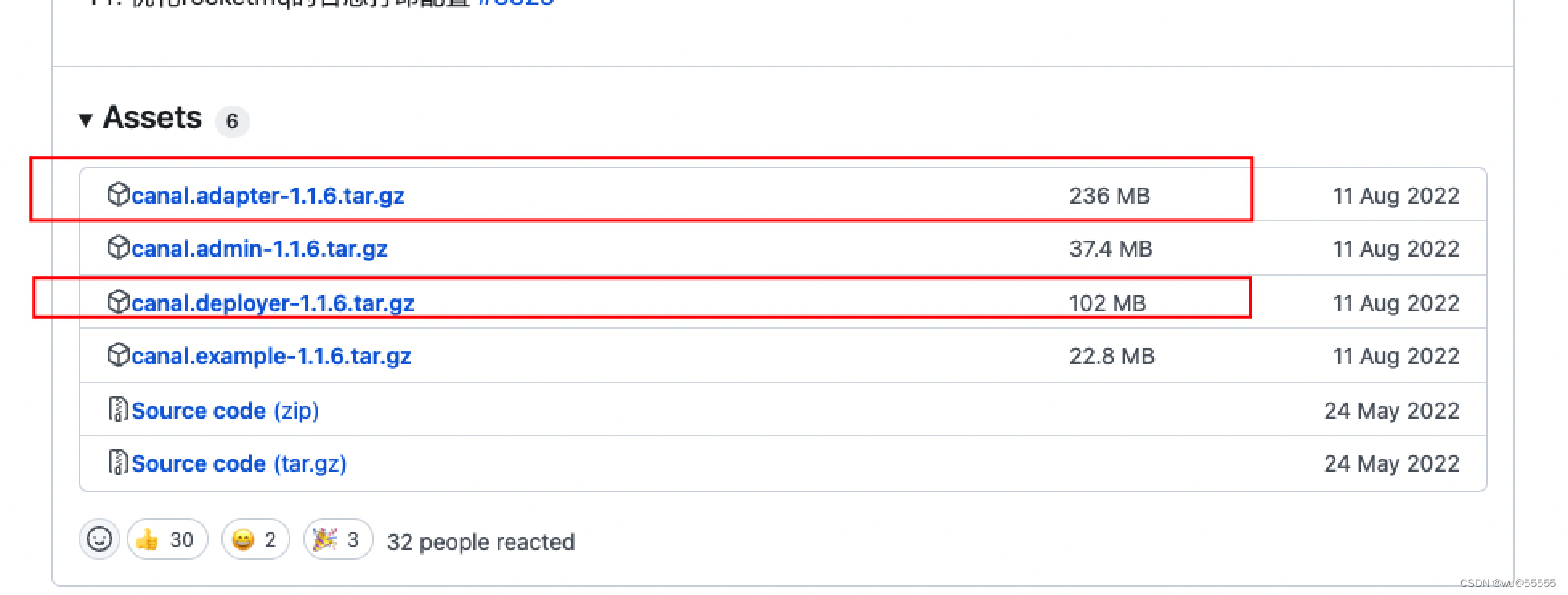
当然也可以通过wget指令直接下载到服务器
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.adapter-1.1.6.tar.gz
详细的安装步骤不再累述了,还不清楚的同学可以参考上一篇文章
通过canal来实现mysql数据同步到elasticsearch
3. 实现同步
3.1 mysql操作步骤
1、因为同步是基于binlog实现的,所以要现在mysql中开启binlog,注意要在需要同步的两个数据库中都开启
修改mysql配置文件
vim /etc/my.cnf
修改内容
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
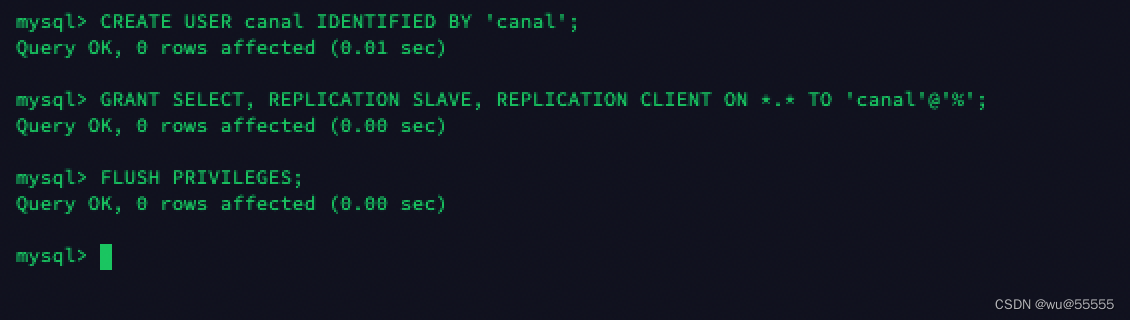
2、源数据库创建一个canal账号,并且设置slave,dump权限
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
3、因为mysql8.0.3后身份检验方式为caching_sha2_password,但canal使用的是mysql_native_password,因此需要设置检验方式(如果该版本之前的可跳过),否则会报错IOException: caching_sha2_password Auth failed
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal';
select host,user,plugin from mysql.user ;
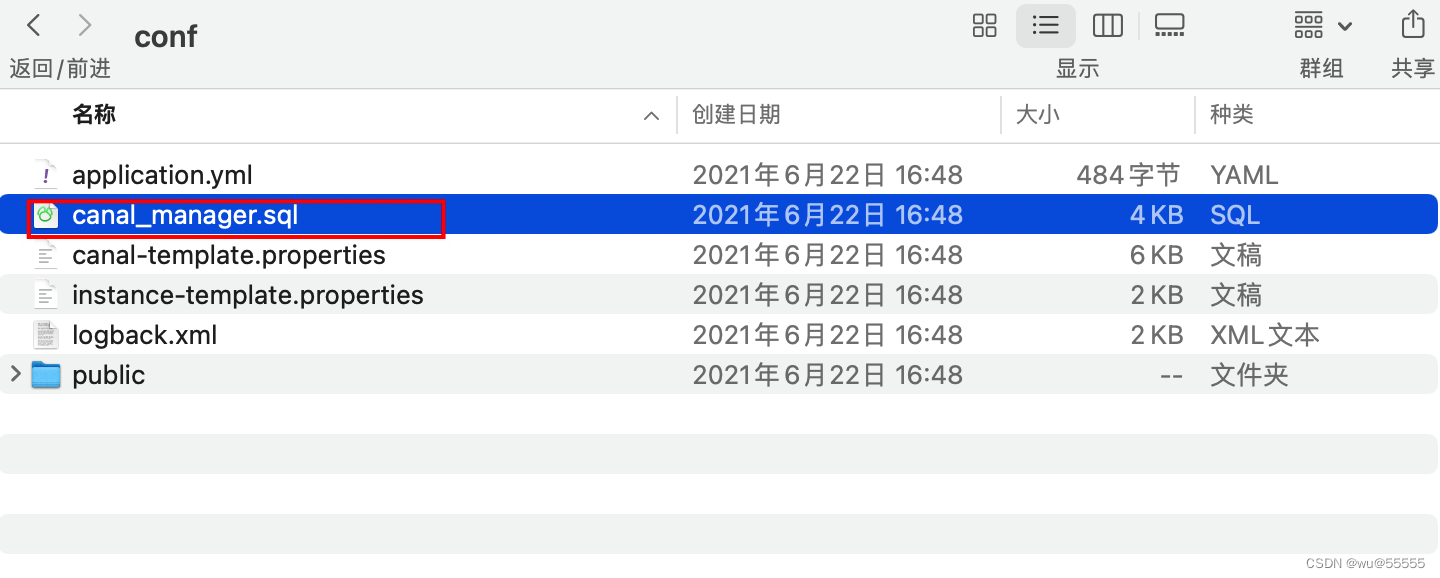
4、创建一个canal_manager数据库,编码格式utf8mb4
该数据库用于远程统一配置管理
导入脚本canal_manager.sql,初始化数据库结构数据
该脚本文件在canal.admin下的conf目录中
3.2 服务端deployer操作
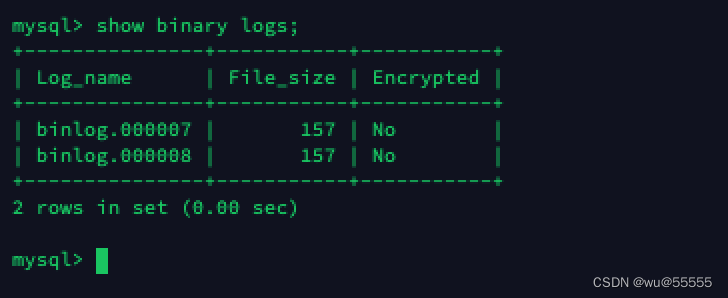
1、查询源mysql服务器的binlog位置
# 源mysql服务器中登陆mysql执行
show binary logs;
2、进入deployer安装目录
cd deployer
3、我们新建一个实例wu专门用于本次演示
cd conf
# 复制example实例配置
cp -R example wu
4、修改实例wu配置文件instance.properties
cd wu
vim instance.properties
修改内容
# position info
# 源数据库地址及端口
canal.instance.master.address=192.168.244.17:3306
# 开始同步的binlog日志文件,注意这里的binlog文件名以你自己查出来的为准
canal.instance.master.journal.name=binlog.000007
# 开始同步的binlog文件位置
canal.instance.master.position=0
# 开始同步时间点 时间戳形式
canal.instance.master.timestamp=1546272000000
# 数据库账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 配置不同步mysql库
canal.instance.filter.black.regex=mysql\..*
mysql数据同步起点说明:
- canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
- canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
- 不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
5、启动服务端
./bin/start.sh
6、查看示例日志,无报错则说明启动成功
cat logs/wu/wu.log

针对服务端的详细配置项解释,可以参考官方文档:
3.3 客户端adapter操作
1、进入adapter安装目录
cd adapter
2、修改配置文件application.yml
vim conf/application.yml
修改内容如下,需要修改的地方已用【】标识出
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
# deployer服务端地址
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
# 源数据库地址,可配置多个 【1】
canalDs: # 命名自定义
url: jdbc:mysql://192.168.244.17:3306/canal_test?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: wu # 服务端配置的实例名称【2】
groups:
- groupId: g1
outerAdapters:
# 开启日志打印
- name: logger
# 配置目标数据库【3】
- name: rdb
key: mysql_target
properties:
jdbc.driverClassName: com.mysql.cj.jdbc.Driver
jdbc.url: jdbc:mysql://目标数据库IP:3306/canal_test?useUnicode=true
# 注意这里的账号需要具有DDL DML的权限
jdbc.username: root
jdbc.password: 123456
druid.stat.enable: false
druid.stat.slowSqlMillis: 1000
客户端配置项的详细解释可以查看官网
3、同步模式分成两种,一种是指定数据表同步,一种是全部数据表同步。我们分别讲解:
4、第一种指定数据表同步:
(1)创建需要同步的数据库表配置文件,一张表一个配置文件
(2)我这里示范同步一张表,创建表bs_ecif配置文件
vim conf/rdb/bs_ecif.yml
配置文件内容
# 源数据库key,对应application.yml中设置的srcDataSources
dataSourceKey: canalDs
# 服务端配置的实例名称
destination: wu
groupId: g1
# 目标数据库key,对应application.yml中设置的outerAdapters
outerAdapterKey: mysql_target
concurrent: true
dbMapping:
database: canal_test
table: bs_ecif
targetTable: bs_ecif
# 配置主键
targetPk:
seq_no: seq_no
# 全表同步,则开启,否则开启targetColumns
mapAll: true
# targetColumns:
# id:
# name:
# role_id:
# c_time:
# test1:
# etlCondition: "where c_time>={}"
# commitBatch: 3000 # 批量提交的大小
5、第二种是同步全部表,也就是所谓的镜像模式。这也要求源库和目标库的结构要一致
(1)conf/rdb文件夹中只留存一个配置文件
vim conf/rdb/all.yml
文件内容:
# 源数据库key,对应application.yml中设置的srcDataSources
dataSourceKey: canalDs
# 服务端配置的实例名称
destination: wu
# 目标数据库key,对应application.yml中设置的outerAdapters
outerAdapterKey: mysql_target
concurrent: true
dbMapping:
mirrorDb: true
database: canal_test
6、启动客户端
./bin/start.sh
7、查看日志
tail -n 100 logs/adapter/adapter.log
无报错,出现同步的记录则表示配置成功
如果出现报错Target column: id not matched,说明是主键设置的不对,检查下conf/rdb下的配置文件的主键配置targetPk
如果出现UPDATE command denied to user 'canal'@'ip' for table 'bs_ecif',说明账号canal的权限不足,如果是在目标数据库中配置的该账号,就需要赋予DDL,DML的权限。如果是在源数据库配置的该账号就需要赋予slave,dump权限
3.4 测试
1、我们修改源库中的一条数据
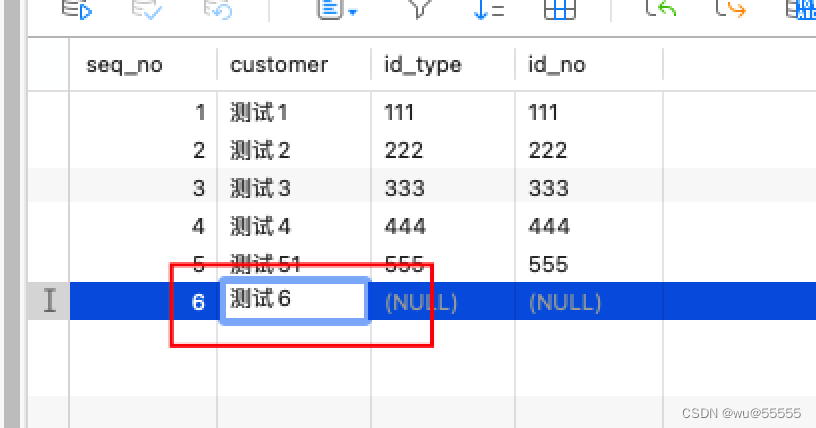
2、这是目标库的原数据
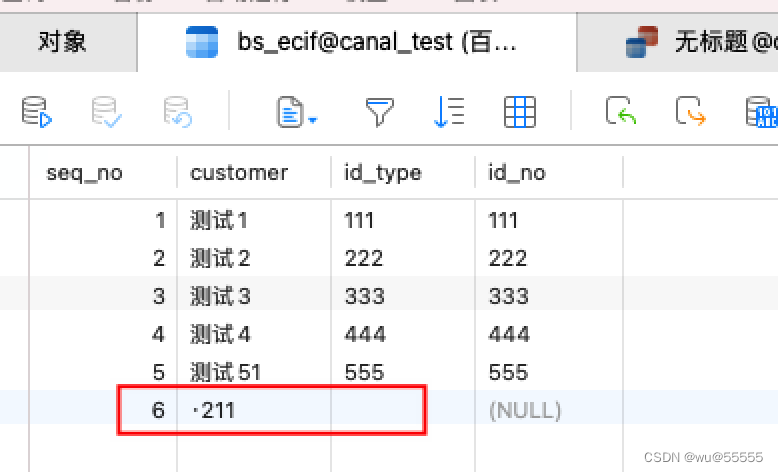
刷新一下,看到新数据更新了
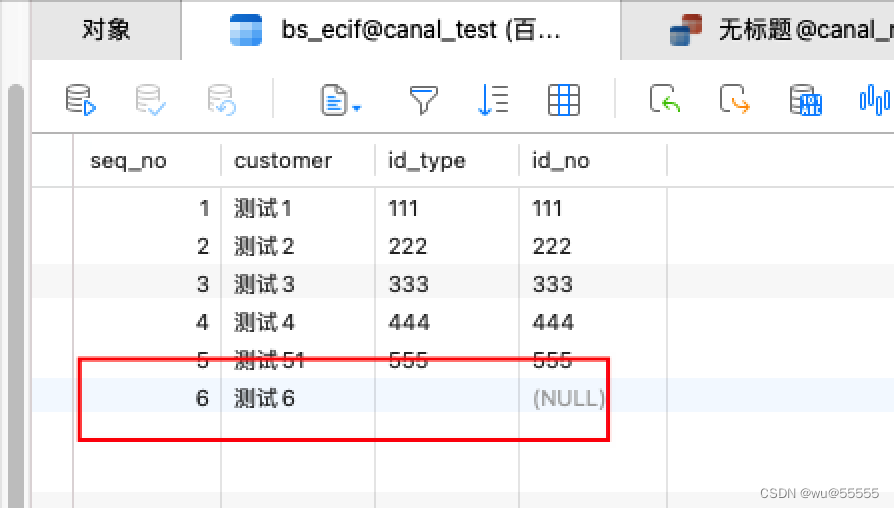
同步成功!
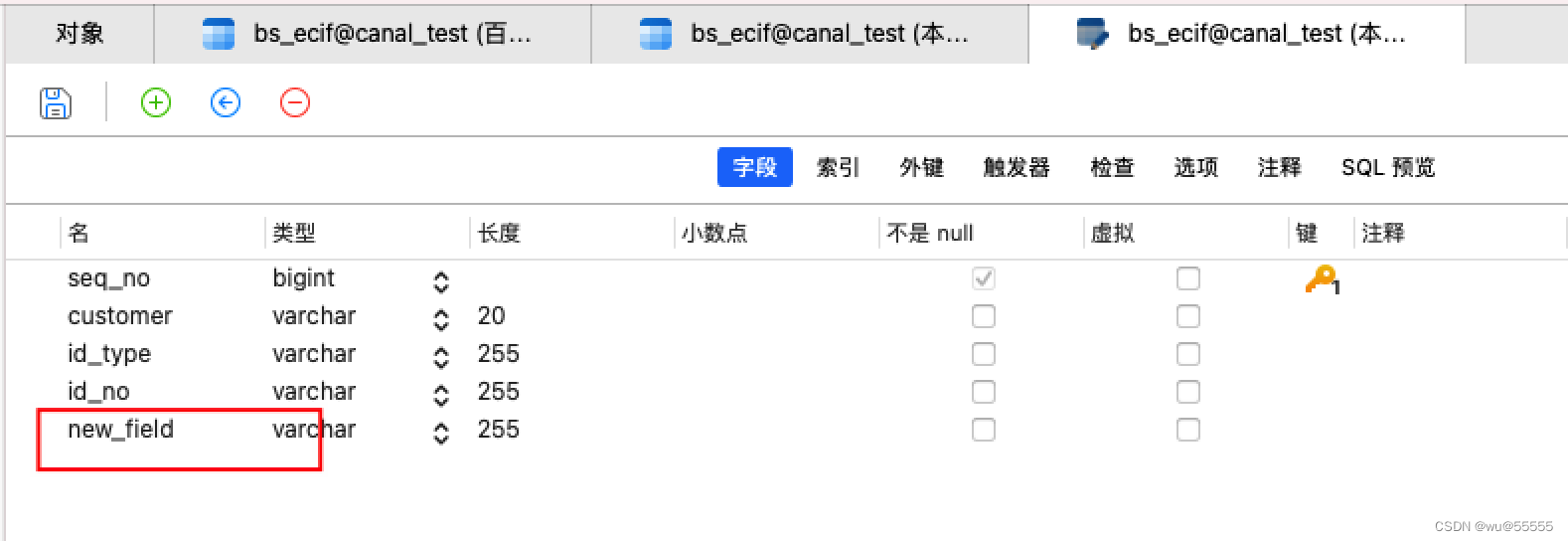
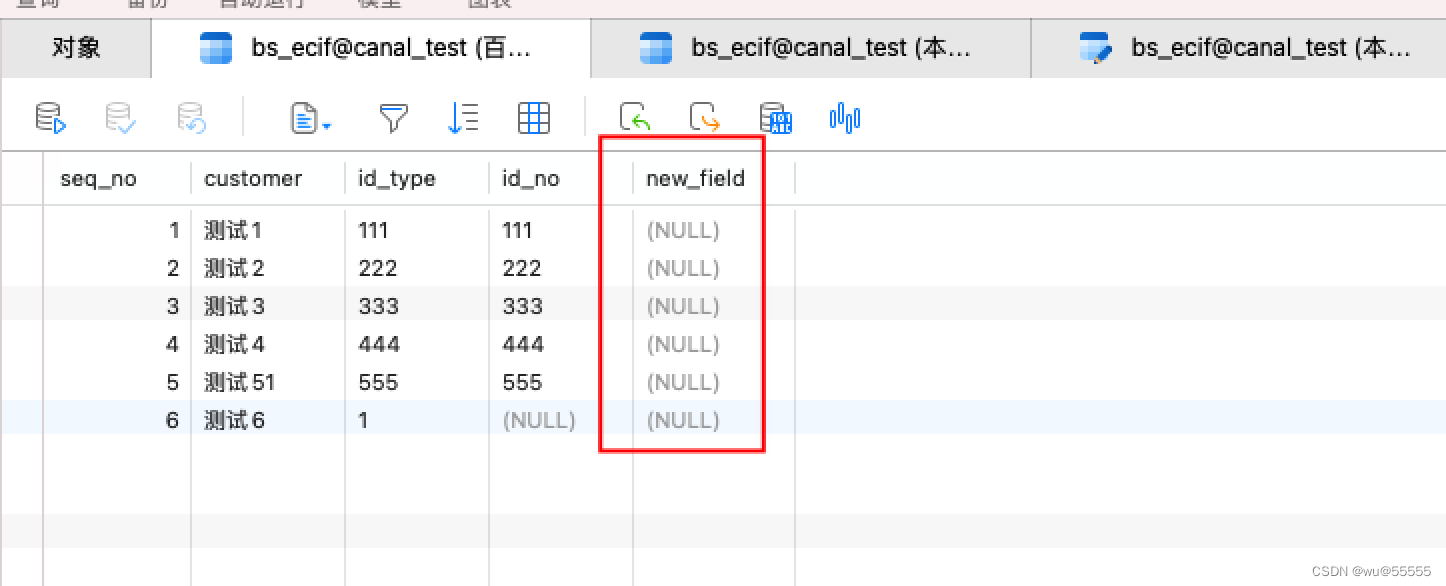
其次我们如果设置的是镜像模式(如果是指定表的形式是不会同步表结构的),那么我们再来测试下更改数据库结构,看看是否会同步
查看目标数据库,发现字段也已经同步成功了!
演示代码下载
本次演示配置,可在如下地址下载,供大家参考:
网盘地址
提取码: a5dw
总结
自此我们针对数据以及数据结构的同步都配置成功了,并且本次演示中使用的目标数据库部署在百度服务器上,源数据库部署在本地虚拟机中,两者异地,演示了异地机房同步。
大家需要注意的是,配置镜像模式同步时,一定要确保初始的数据库结构是一致的,否则也无法达到“镜像”的效果。
我正在申请认证,如果本文对你有帮助的话,希望点个赞支持一下