条件查询
很多时候,我们使用数据库时并不是关心表里所有的数据,而是一部分满足条件的数据,这类条件要用WHERE子
句来实现数据的筛选。
SELECT …… FROM …… WHERE 条件 [ AND | OR ] 条件 …… ;
下面给出一个示例:
SELECT * FROM `t_emp` WHERE comm IS NOT NULL AND sal BETWEEN 1000 AND 20000
AND ename REGEXP "^[\\u4e00-\\u9fa5]{2,4}$";
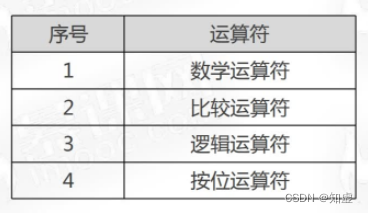
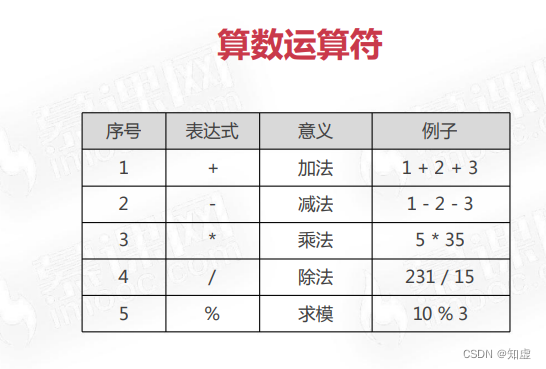
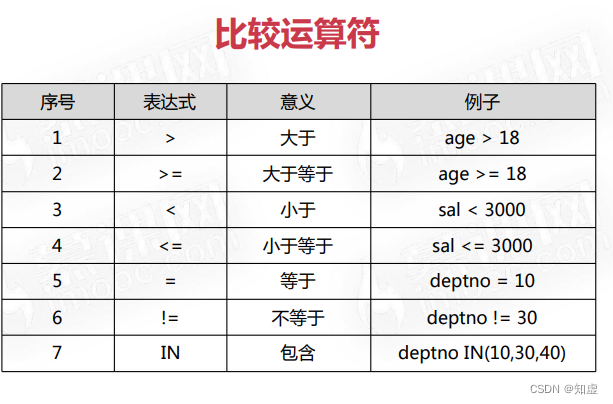
在sql中我们可能会用到以下四种运算符:
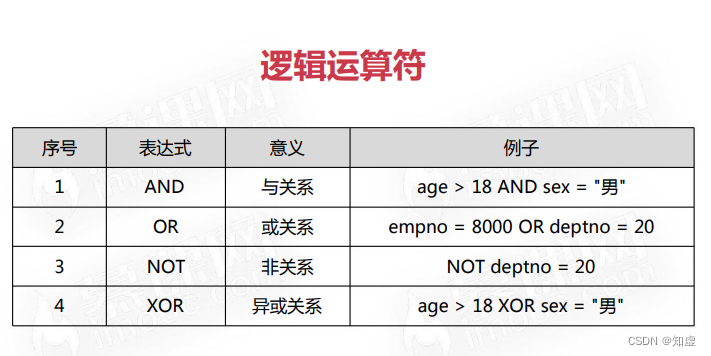
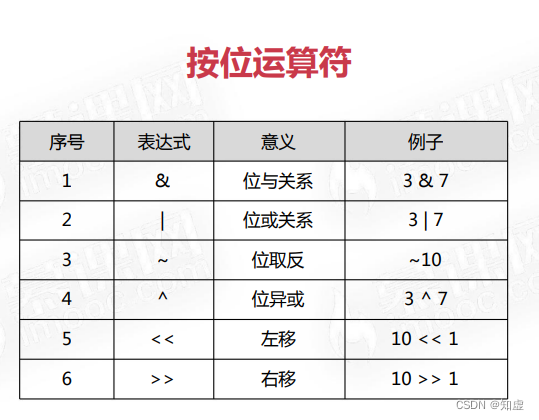
下面给出逻辑运算和按位运算的sql示例:
SELECT * FROM t_emp
WHERE NOT deptno IN (10,20)
XOR sal>2000;
SELECT 3&7,3|7,~10,3^7,10<<1,10>>1;
注意:这里提到了两个我基本没使用过的方法:
NOT 以及 XOR
WHERE 语句的使用注意事项
WHERE子句中,条件执行的顺序是从左到右的。所以我们应该把索引条件,或者筛选掉记录最多的条件写在最左侧
在sql中,如果出现了where ,它的执行顺序是什么样的呢?

数据库操作语言,聚合函数
什么是聚合函数
聚合函数在数据的查询分析中,应用十分广泛。聚合函数可以对数据求和、求最大值和最小值、求平均值等等。
- SUM 函数
SUM函数用于求和,只能用于数字类型,字符类型的统计结果为0,日期类型统计结果是毫秒数相加。
SUM函数会排除NULL值
SELECT SUM(sal) FROM t_emp WHERE deptno IN (10,20);
- MAX函数
MAX函数用于获得非空值的最大值。
SELECT MAX(sal + IFNULL(comm,0)) FROM t_emp WHERE deptno IN(10,20);
下面给出一个问题:查询员工最长的名字长度
SELECT MAX(LENGTH(ename)) FROM t_emp ;
-
MIN函数
MIN函数用于获得非空值的最小值。 -
AVG函数用于获取非空值的平均数,非数字数据统计为0
select AVG(sal + IFNULL(comm,0)) as avg FROM t_emp;
- COUNT函数
COUNT(*)用于获得包含空值的记录数,COUNT(列名)用于获得包含非空值的记录数。
SELECT COUNT(*) FROM t_emp; --15
SELECT COUNT(comm) FROM t_emp; --5
下面给出两个练习:
#练习 查询底薪大于2000,入职15年以上员工数量
SELECT COUNT(*) FROM t_emp WHERE sal > 2000 AND (DATEDIFF(NOW(),hiredate)>= 15*365 ) AND deptno IN (10,20);
#查询1985年后入职员工,底薪超过公司平均底薪的员工数量(下面是错误写法,因为在聚合函数的使用前提是必须有一个确定的数据集)
SELECT COUNT(*) FROM t_emp WHERE hiredate >='1985-01-01'
AND sal > AVG(sal);
分组查询
为什么需要分组?
- 默认条件下汇总函数是对全表氛围内的数据做统计
- GROUP BY语句的作用是通过一定的规则将一个数据集划分为若干个小的区域,然后对每个小区域的数据做汇总处理。
下面给出一个分组的示例:
#分组
SELECT deptno,ROUND(AVG(sal)) FROM t_emp GROUP BY deptno ORDER BY deptno;
逐级分组
- 数据库支持多列分组条件,执行的时候逐渐分组
例如,查询每个部门中,每种职位的人员数量和平均底薪
SELECT deptno,ROUND(AVG(sal)) FROM t_emp GROUP BY deptno ORDER BY deptno,job ORDER BY deptno;
对SELECT子句的要求
查询语句中如果含有GROUP BY子句,那么SELECT子句中的内容就必须要遵守规定:SELECT子句中可以包括聚合函数,或者GROUP BY子句的分组列,其余内容均不可以出现在SELECT子句中。
那么为什么会是这样呢,其实GROUP是对数据按照特定的情况进行了分组,分组后每组其实就是一行数据,其余内容未分组就是多数据,无法匹配。为了解决这种问题,我们就引入了GROUP_CONCAT函数。
GROUP_CONCAT函数可以把分组查询中的某个字段拼接成一个字符串
#查询每个部门内底薪超过2000的人数和员工姓名
SELECT deptno,COUNT(*),GROUP_CONCAT(ename) FROM t_emp where sal >2000 GROUP BY deptno ;
对数据结果集再做汇总计算
SELECT deptno,job,COUNT(*),AVG(SAL) FROM t_emp GROUP BY deptno,job WITH ROLLUP ORDER BY deptno;
效果如下:
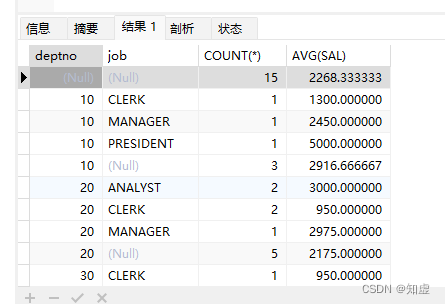
带分组语句的sql执行顺序

数据库操作语言――Having子句
分组查询遇到的困难?
像是之前所提到的想要查询1970年后入职员工,平均底薪超过2000的部门编号,我们按习惯会写成下面这个样子
SELECT deptno FROM t_emp WHERE hiredate >='1970-01-01'
AND AVG(sal)>2000 GROUP BY deptno;
显然这个语句执行会报错,原因是WHERE 语句执行比 GROUP BY 早,所以聚合函数执行时,还没有一个确定的结果集,所以会报错,这个时候怎么办呢,我们就需要引入HAVING 子句,sql如下:
SELECT deptno ,sal FROM t_emp WHERE hiredate >='1970-01-01'
GROUP BY deptno HAVING AVG(sal)>2000;
示例:
查询每个部门中,1982年以后入职的员工超过2个人的部门编号
SELECT deptno FROM t_emp WHERE hiredate>='1982-01-01' GROUP BY deptno HAVING count(*)>=2 ORDER BY deptno desc;
HAVING子句中如果聚合函数和具体字段比较就会出现语法错误, 例如
SELECT deptno FROM t_emp WHERE hiredate>='1982-01-01' GROUP BY deptno HAVING sal >AVG(sal) ORDER BY deptno desc;
HAVING子句的特殊用法
- 按照数字1分组,MYSQL会根据SELECT 子句中的列进行分组,HAVING子句也可以正常使用
#特殊用法
SELECT deptno,COUNT(*) FROM t_emp GROUP BY 1 HAVING deptno IN (10,20);
数据操作语言――表连接查询
从多张表中提取数据
- 从多张表中提取数据,必须指定关联的条件。如果不定义关联条件就会出现无条件连接,两张表的数据就会交叉连接,产生笛卡尔积,例如:
#产生笛卡尔积
SELECT e.empno,e.ename,d.dname FROM t_emp e JOIN t_dept d
- 当规定了取值条件时,就不会再出现笛卡尔积,例如:
SELECT e.empno,e.ename,e.dname FROM t_emp e JOIN t_dept d ON e.deptno =d.deptno;
表连接的分类
- 表连接分为两种:内连接和外连接
- 内连接是结果集中只保留符合连接条件的记录
- 外连接是不管符不符合连接条件,记录都要保留在结果集中
内连接的简介
内连接是一种最常见的连接,我们一般是用的都是标准内连接的变形版本

内连接有多种书写方式,例如:
SELECT …… FROM 表1 JOIN 表2 ON 连接条件 ;
SELECT …… FROM 表1 JOIN 表2 WHERE 连接条件 ;
# 最常见的书写方式
SELECT …… FROM 表1 , 表2 WHERE 连接条件 ;
下面给出一个练习题目:
查询每个员工的工号、姓名、部门名称、底薪、职位、工资等级:
SELECT e.empno,e.deptno,d.dname,e.sal,e.job,s.grade
FROM t_emp e INNER JOIN t_dept d ON e.deptno =d.deptno
INNER JOIN t_salgrade s ON (e.sal >=s.losal AND e.sal<=s.hisal);
- 内连接不一定字段相同,只有能建立关系就行
练习2:查询与SCOTT相同部门的员工都有谁?
#查询与SCOTT相同部门的员工都有谁
SELECT T1.ename FROM t_emp e INNER JOIN t_emp t1 ON e.deptno =t1.deptno where e.ename = 'SCOTT' and t1.ename !='SCOTT' ;
其实这个还有一种思路如下,但是因为他会多次执行子查询,所以效率远不如第一种高。
select T1.ename from t_emp t1 where t1.deptno = (select deptno FROM t_emp where ename ='SCOTT') AND T1.ename !='SCOTT';
下面给出几个关于多表连接的练习提巩固知识点:
#查询公司底薪超过公司平均底薪的员工信息
#错误写法
SELECT e.* FROM t_emp e INNER JOIN t_emp e2 ON e.sal>AVG(e2.sal);
#正确写法
SELECT e.* FROM t_emp e INNER JOIN (SELECT AVG(sal) AS avgSal FROM t_emp) t2
ON e.sal >t2.avgSal;
#查询RESEARCH 部门的人数,最高底薪,最低底薪,平均底薪,平均工龄
# FLOOR(X) 向下取整,CEIL(X)向下取整
SELECT COUNT(*), MAX(sal), MIN(sal), AVG(sal), FLOOR(AVG(DATEDIFF(NOW(),hiredate)/365))
FROM t_emp e
INNER JOIN t_dept d
ON e.deptno =d.deptno AND d.dname ='RESEARCH';
#查询每种职业的最高工资,最低工资,平均工资,最高工资等级和最低工资等级
SELECT
e.job,
MAX(
sal + IFNULL( comM, 0 )),
MIN(
sal + IFNULL( comM, 0 )),
AVG(
sal + IFNULL( comM, 0 )),
MAX( grade ),
MIN( grade )
FROM
t_emp e
INNER JOIN t_salgrade s ON s.losal <= sal + IFNULL( comM, 0 ) AND s.hisal > sal + IFNULL( comM, 0 )
GROUP BY
e.job
ORDER BY e.job ASC;
#查询每个底薪超过部门平均底薪的员工信息
SELECT e.*
FROM t_emp e
INNER JOIN (SELECT AVG(sal) AS avgSal,deptno FROM t_emp GROUP BY deptno ) t
ON e.sal>t.avgSal AND e.deptno =t.deptno;
外连接
为什么要使用外连接
假设现在有一名临时工作人员,他没有固定的工作部门,我们是用内连接时就会把他给过滤掉,而我们想要查询它的信息,此时就需要引入外连接。
外连接的简介
- 外连接与内连接的区别在于,除了符合条件的记录之外,结果集中还会保留不符合条件的记录。
- 例如,现在给出一个内连接和外连接的脚本结果示例
#内连接
SELECT e.ename,e.empno,e.ename,t.deptno
FROM t_emp e
INNER JOIN t_dept t
ON e.deptno =t.deptno;
#左连接
SELECT e.ename,e.empno,e.ename,t.deptno
FROM t_emp e
LEFT JOIN t_dept t
ON e.deptno =t.deptno;
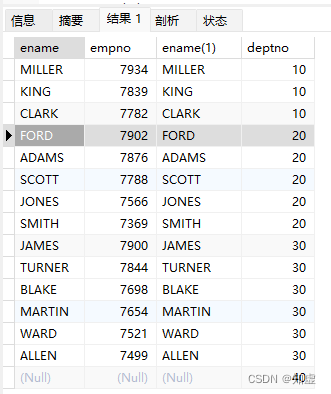
结果:
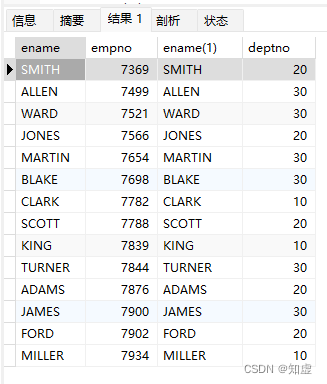
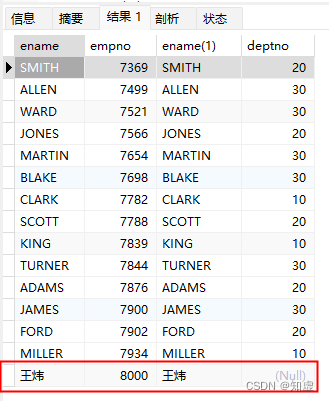
可以看出内外连接的区别在于最后一条数据是否被过滤掉。
左连接和右连接
左外连接就是保留左表所有的记录,与右表做连接。如果右表有符合条件的记录就与左表连接。如果右表没有符合条件的记录,就用NULL与左表连接。右外连接也是如此。
下面给出一个右连接的示例:
#右连接
SELECT e.ename,e.empno,e.ename,t.deptno
FROM t_emp e
RIGHT JOIN t_dept t
ON e.deptno =t.deptno;
结果:
下面给出一些有关于表外连接的练习题目:
#外连接练习
#查询每个部门的名称和部门的人数
SELECT d.dname,COUNT(e.deptno)
FROM t_dept d
LEFT JOIN t_emp e
ON d.deptno =e.deptno
GROUP BY d.deptno;
#查询每个部门的名称和部门的人数,如果没有部门的员工,部门名称用NULL替代
(SELECT d.dname,COUNT(e.deptno)
FROM t_dept d
LEFT JOIN t_emp e
ON d.deptno =e.deptno
GROUP BY d.deptno)
UNION(SELECT d.dname,COUNT(*)
FROM t_dept d
RIGHT JOIN t_emp e
ON d.deptno =e.deptno
GROUP BY d.deptno);
#练习:查询每名员工的编号,姓名,部门,月薪,工资等级,工龄,上司编号,上司姓名,上司部门
SELECT e.empno,e.ename,d.dname,e.sal+IFNULL(e.comm,0),s.grade,FLOOR(DATEDIFF(NOW(),e.hiredate)/365),t.empno,t.ename,t.dname
FROM t_emp e
LEFT JOIN t_dept d
ON e.deptno =d.deptno
LEFT JOIN t_salgrade s
ON e.sal BETWEEN s.losal AND s.hisal
LEFT JOIN(SELECT e1.empno,e1.ename,t1.dname FROM t_emp e1 LEFT JOIN t_dept t1 ON e1.deptno =t1.deptno) t ON e.mgr =t.empno;
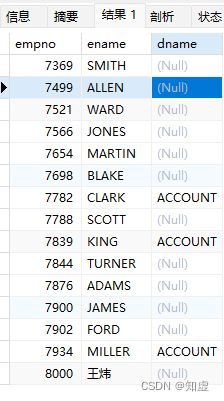
外连接的注意事项
与内连接ON 与WHERE 中的语句效果相同有区别的点在于,外连接的ON 因为会保留不满足条件的数据,而使用where会过滤掉数据,所以需要综合考虑实际使用哪一个语句,例如:
#WHERE
SELECT e.empno,e.ename,t.dname
FROM t_emp e
LEFT JOIN t_dept T
ON E.deptno = T.deptno
where e.deptno ='10';
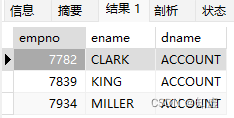
#ON
SELECT e.empno,e.ename,t.dname
FROM t_emp e
LEFT JOIN t_dept T
ON E.deptno = T.deptno
AND e.deptno ='10';
效果:(可见区别还是挺大的)
子查询
- 子查询就是在查询中嵌套查询的语句
- 查询底薪超过公司平均底薪的员工信息
#WHERE 子句的子查询
SELECT *
FROM t_emp E
WHERE E.sal >(SELECT AVG(sal) FROM t_emp e1)
子查询的分类
子查询可以写在三个地方:WHERE子句,FROM子句,SELECT子句,但是只有FROM子句是最可取得,因为其他两种都会执行多次。
- WHERE 子查询
这种子查询最简单,最容易理解,但是效率很低
在数据库中,被反复执行的子查询被称为相关子查询 - FROM 子查询
这种子查询只会执行一次
例如:
SELECT e.*
FROM t_emp e INNER JOIN
(SELECT AVG(sal) AS sal,deptno FROM t_emp e2 GROUP BY e2.deptno) t
ON e.deptno = t.deptno AND e.sal >=t.sal
ORDER BY empno;
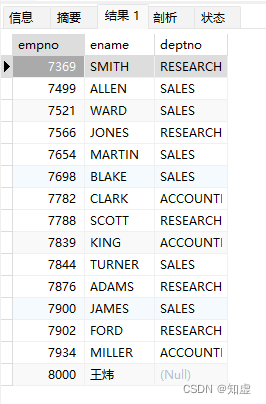
- 相关子查询
这种子查询每次输出一条数据时都会执行一次,效率很慢。
例如:
SELECT
e.empno,
e.ename,
(SELECT dname FROM t_dept WHERE e.deptno =deptno) as deptno
FROM t_emp e;
单行子查询和多行子查询
- 单行子查询的结果集只有一条记录,多行子查询的结果有多行记录。
- 多行子查询只能出现在WHERE子句和FROM子句中
- 如何用子查询查找FORD和MARTIN两个人的同事?
给出解决方案:
SELECT e1.*
FROM t_emp e1
INNER JOIN (SELECT deptno FROM t_emp e2 WHERE e2.ename IN ('FORD','MARTIN') ) t
ON e1.deptno =t.deptno
AND e1.ename NOT IN ('FORD','MARTIN');
WHERE 子句中的多行子查询
- WHERE子句中,可以使用IN、ALL、ANY、EXISTS关键字来处理多行表达式结果集的条件判断
例如:查询比FORD和MARTIN底薪都高的员工信息
SELECT e.*
FROM t_emp e
WHERE e.sal > ALL
(SELECT sal FROM t_emp e2 WHERE e2.ename IN ('FORD','MARTIN'));
例如:查询比FORD或者MARTIN底薪高的员工信息
SELECT e.*
FROM t_emp e
WHERE e.sal > ANY
(SELECT sal FROM t_emp e2 WHERE e2.ename IN ('FORD','MARTIN'));
EXISTS关键字
EXISTS关键字是把原来在子查询之外的条件判断,写到了子查询的里面。
例如:
#查询工资等级是三级或者四级的员工信息
SELECT e.*
FROM t_emp e
WHERE EXISTS (SELECT s.grade FROM t_salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal and s.grade in ('3','4'));