БОЕиСЊЕїsparkШЮЮёВПЪ№ећИіСїГЬ
windowБОЕиСЌНгдЖГЬМЏШК,жДааsparkШЮЮё
НщЩм: ПДЭјЩЯЕФВЉПЭЖдгкБОЕиСЊЕїsparkШЮЮёећИіВПЪ№СїГЬЖМВЛЪЧКмШЋ, ЫљвдЕЅЖРаДСЫвЛИі,ЭЌЪБМгЩювЛаЉгАЯь,ЗНБуЯТДЮжБНгЪЙгУ
ЙІФм: windowЕчФдБОЕиСЌНгдЖГЬМЏШК, жДааsparkШЮЮёЕїЪдdemo
ЕквЛВН:demoДњТы
ашвЊаоИФЕФВЮЪ§:
- spark.sql.warehouse.dir ,ИУВЮЪ§жИЖЈСЫ Hive ЕФЪ§ОнДцДЂФПТМ;
- hive.metastore.uris;
- hive.exec.scratchdir,ИУВЮЪ§жИЖЈСЫ Hive ЕФЪ§ОнСйЪБЮФМўФПТМ,ФЌШЯЮЛжУЮЊ HDFS ЩЯУцЕФ /tmp/hive ТЗОЖЯТ;
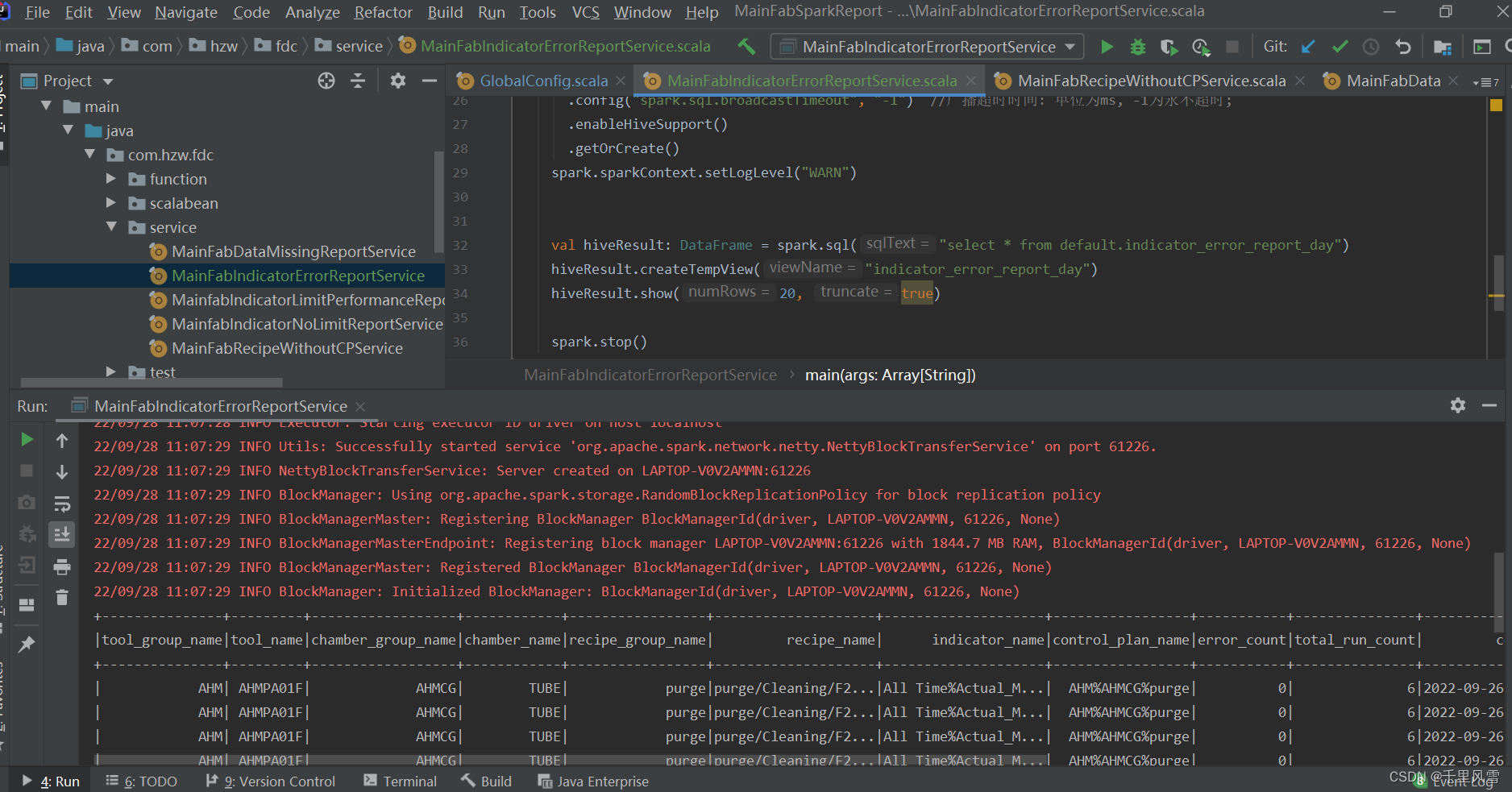
package com.hzw.fdc.service
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{DataFrame, SparkSession}
object MainFabIndicatorErrorReportService extends Logging{
def main(args: Array[String]): Unit = {
logWarning(s"----------НтЮі ГЬађШыВЮ args---------")
val warehouseLocation = "hdfs://116.63.158.113:8020/user/hive/warehouse"
//ЛёШЁSparkSession
val spark: SparkSession = SparkSession.builder()
.appName("MainFabIndicatorErrorReportService")
.master( "local[2]" )
.config("spark.sql.warehouse.dir",warehouseLocation)
.config("dfs.client.use.datanode.hostname", "true")
//.config("fs.defaultFS","hdfs://116.63.158.113/")
.config("hive.metastore.uris","thrift://139.9.228.88:9083")
.config("hive.exec.scratchdir", "hdfs://116.63.158.113:8020/user/hive/tmp")
.config("spark.sql.broadcastTimeout", "36000")
.config("spark.debug.maxToStringFields", "100")
.config("spark.sql.autoBroadcastJoinThreshold", "104857600") //ЙуВЅБэЕФЩЯЯо:ЕЅЮЛЮЊB,ЯжЩшжУзюДѓЙуВЅ300MЕФБэ;
.config("spark.sql.broadcastTimeout", "-1") //ЙуВЅГЌЪБЪБМф: ЕЅЮЛЮЊms, -1ЮЊгРВЛГЌЪБ;
.enableHiveSupport()
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val hiveResult: DataFrame = spark.sql("select * from default.indicator_error_report_day")
hiveResult.createTempView("indicator_error_report_day")
hiveResult.show(20, true)
spark.stop()
}
}
ЕкЖўВН: БОЕиwindow ЛЗОГХфжУ
window ЕчФдЩЯБОЕиСЊЕїsparkШЮЮё , ашвЊ Hadoop :https://github.com/cdarlint/winutils
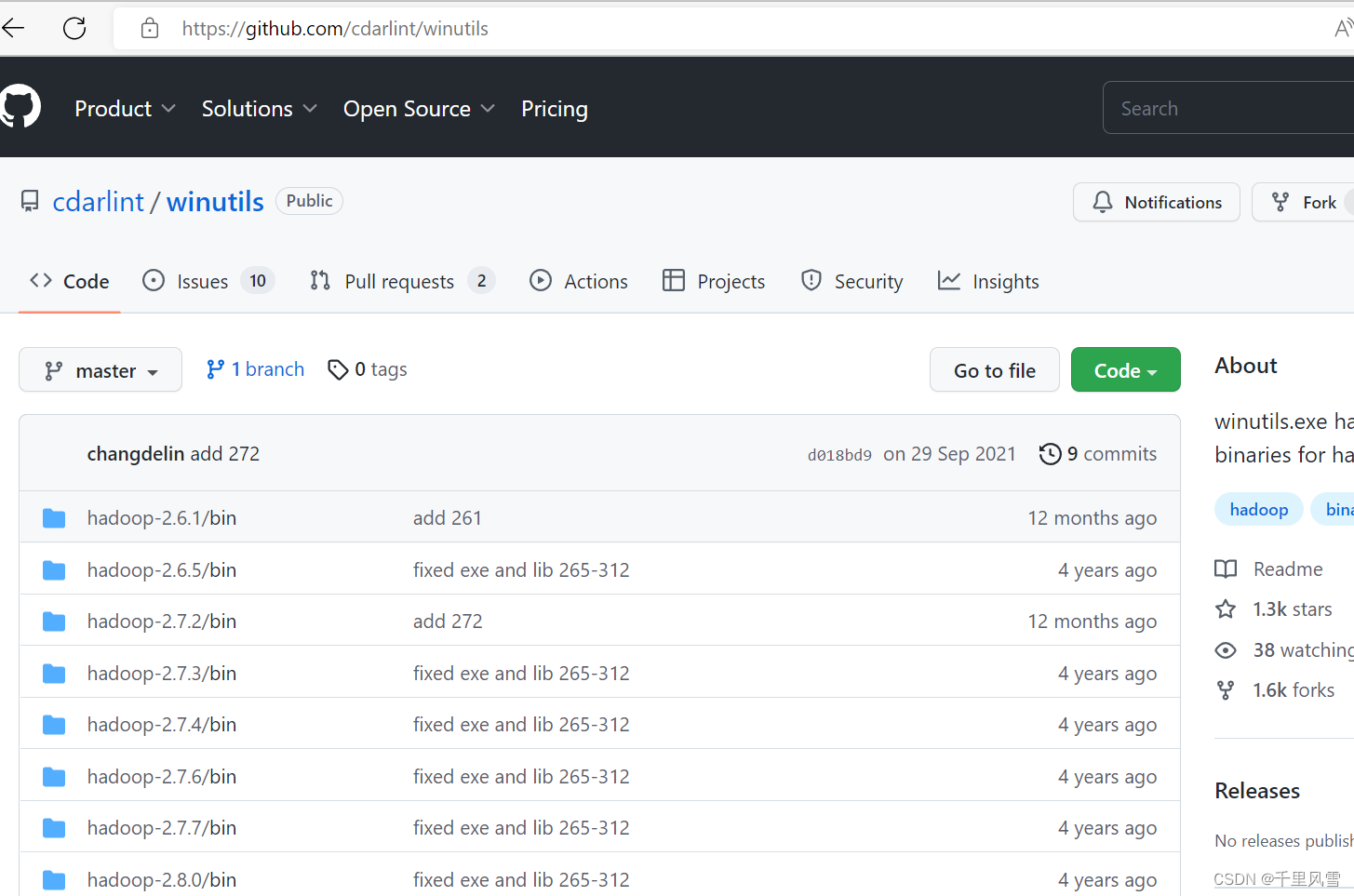
ЯТдиhadoopЮФМўЕНwindowЕчФд
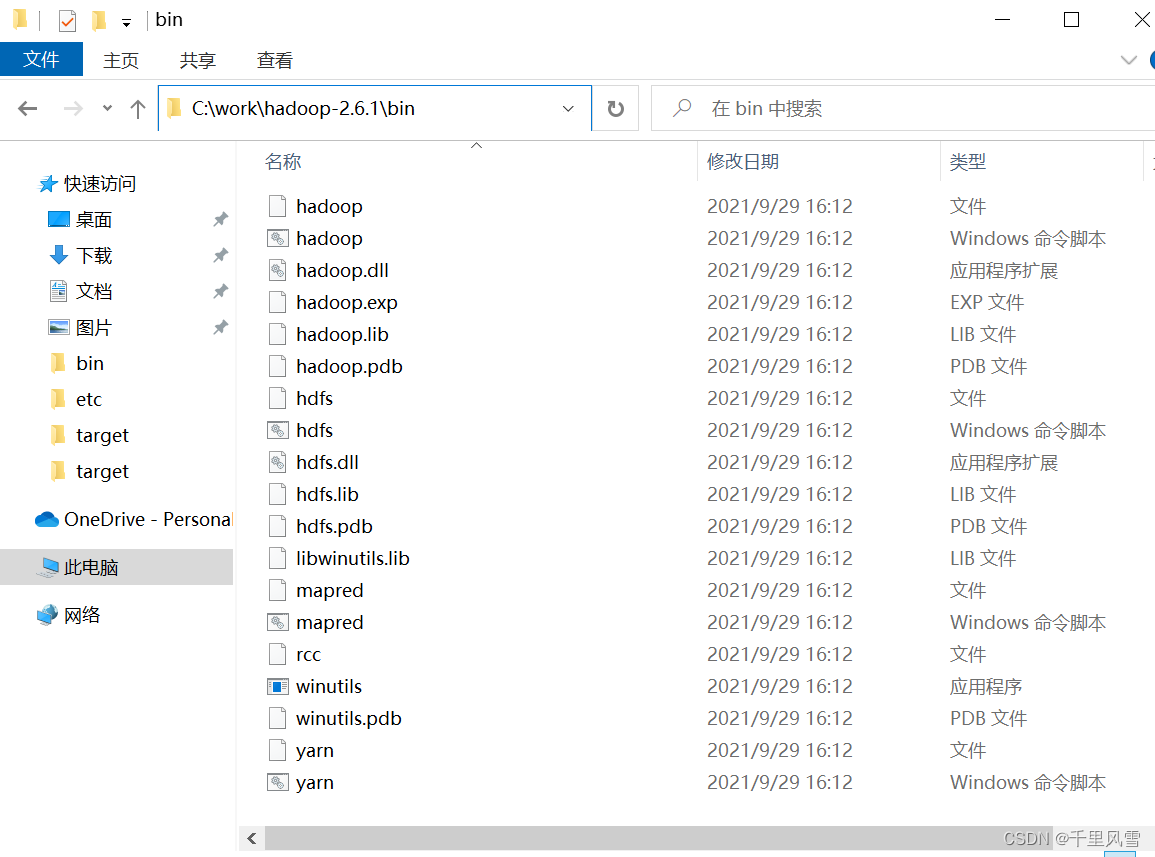
ХфжУБфСПЬэМг
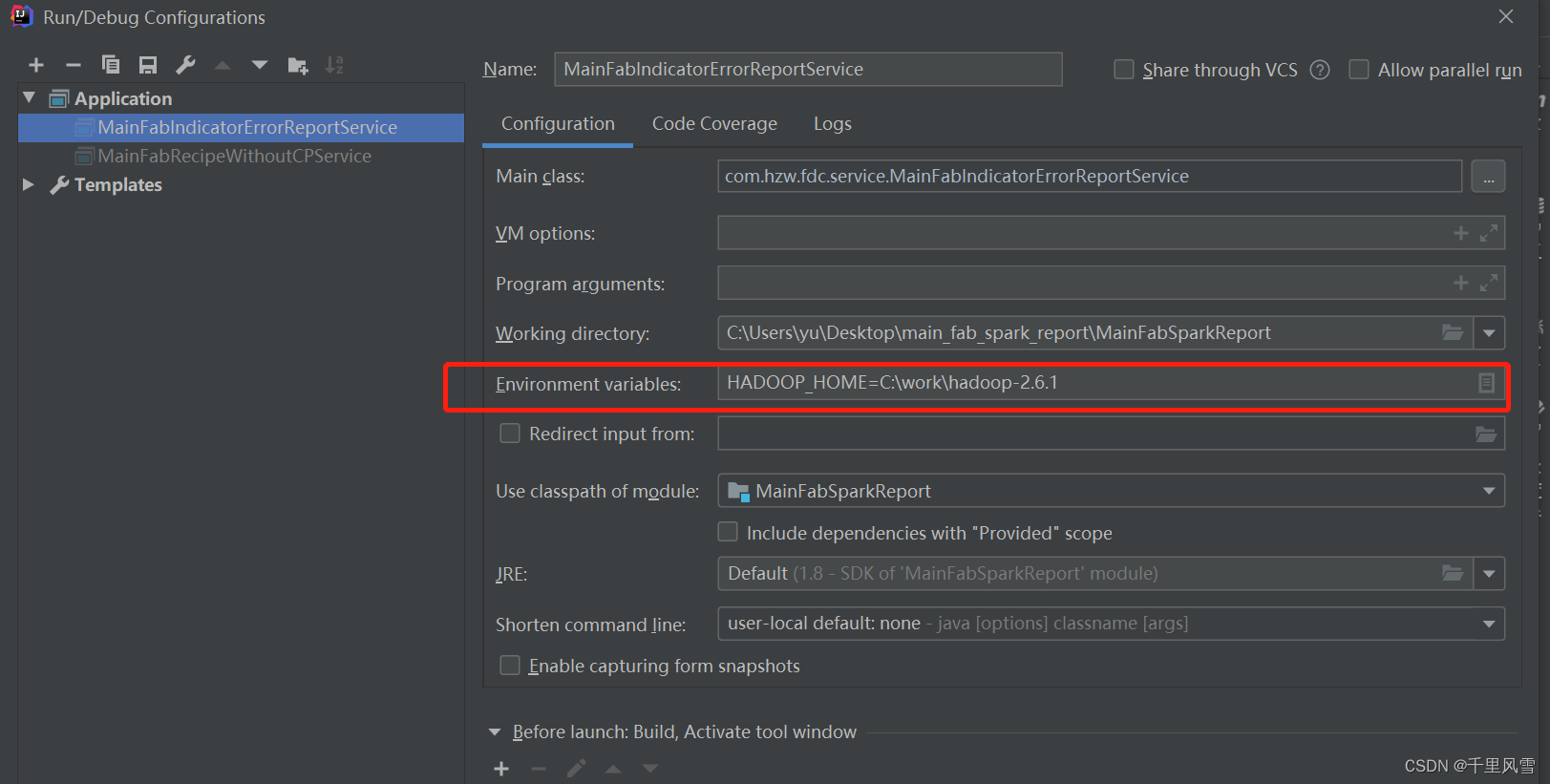
БОЕиЕчФдХфжУдЖГЬЕФhosts, ашвЊАбдЖГЬМЏШКЕФЗўЮёЦїhostnameдкБОЕиЬэМг
аоИФC:\Windows\System32\drivers\etc\hosts ЮФМў
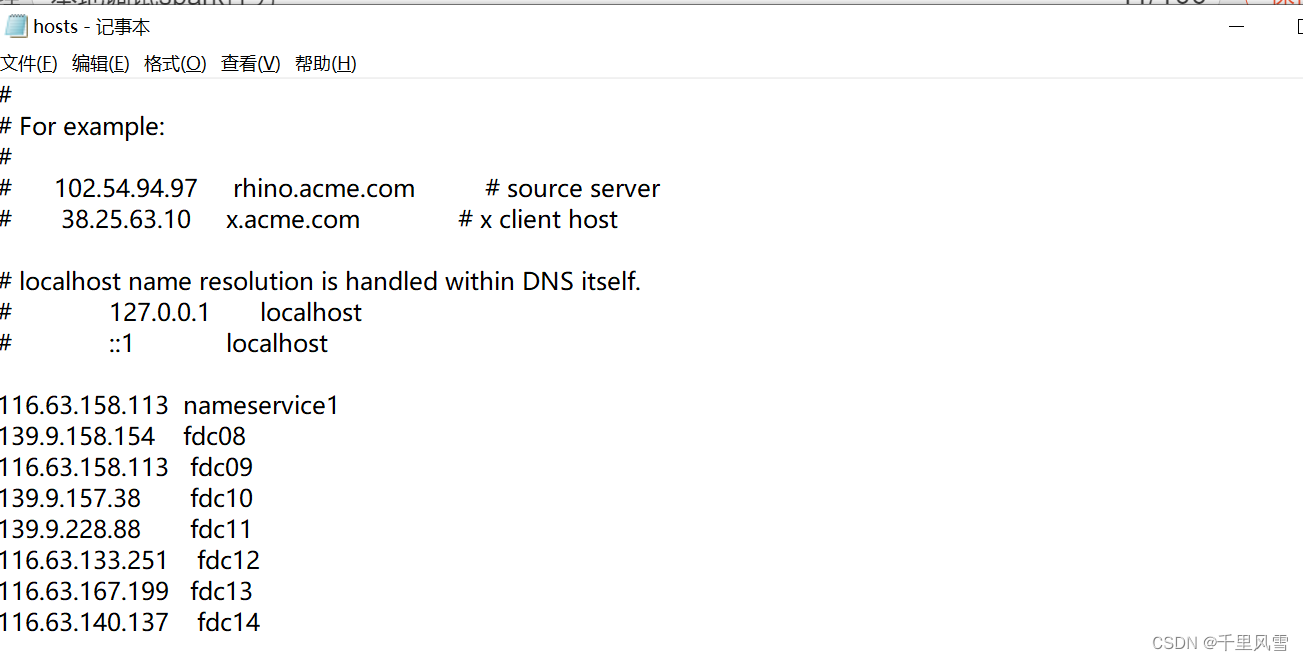
ашвЊЪЙгУЙмРэдБШЈЯожДаа
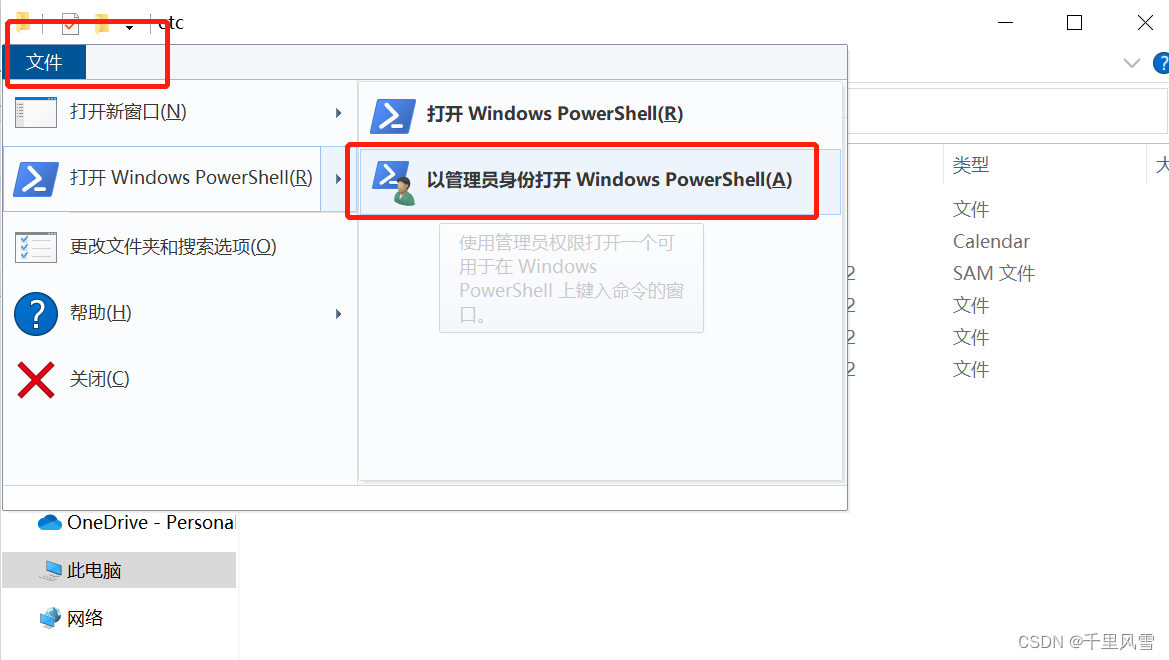
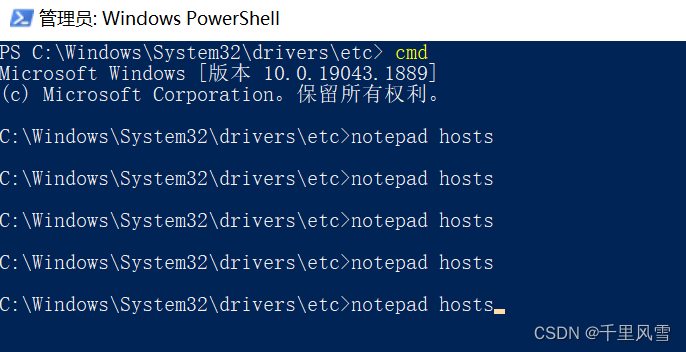
жДааnotepad hosts
ЕкШ§ВН:жДааsparkШЮЮёЕїЪд