目录
spark有4种模式,单节点(没人用)
集群模式:
standalone,仅仅使用spark,不依赖其他的组件
yarn模式,使用yarn资源调度
memos模式,国内资料很少,一般不用。
? ? ??
YARN模式
搭建spark,spark资源管理需要yarn,yarn是在hadoop上的,hadoop需要java,所以
需要安装,java(很简单,不赘述)
hdfs搭建
配置单节点hadoop 边搭边写(含hadoop集群搭建)_我要用代码向我喜欢的女孩表白的博客-CSDN博客
zookeeper搭建
zookeeper搭建_我要用代码向我喜欢的女孩表白的博客-CSDN博客
spark搭建
Spark集群搭建超详细教程_笑看风云路的博客-CSDN博客_spark集群搭建步骤
STANDALONE模式
以前没有装过spark3.0,现在采用standalone模式安装一下
下载
https://dlcdn.apache.org/spark/spark-3.2.2/spark-3.2.2-bin-hadoop3.2-scala2.13.tgz
安装spark
创建存放spark的目录
mkdir -p /bigdata/server
1.解压
tar -zxvf spark-3.2.2-bin-hadoop3.2-scala2.13.tgz -C /bigdata/server/
改名并且修改目录
mv /bigdata/server/spark-3.2.2-bin-hadoop3.2-scala2.13/ /bigdata/server/spark3-standalone
2.配置spark的work节点
cd /bigdata/server/spark3-standalone/conf
cp workers.template workers
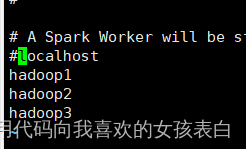
vi workers(注释localhost,用主机名作为从节点名称)
??? 
3.配置spark-env.sh
cd /bigdata/server/spark3-standalone/conf
所有节点都创建data目录
mkdir -p /bigdata/server/data
copy环境变量
cp spark-env.sh.template spark-env.sh
设定主节点
vi spark-env.sh
新增内容如下?
export SPARK_MASTER_HOST=hadoop1
export SPARK_LOCAL_DIRS= /bigdata/server/data
4.配置spark-defaults.conf
cd /bigdata/server/spark3-standalone/conf
cp spark-defaults.conf.template spark-defaults.conf
分发到其他节点
scp -r /bigdata/server/spark3-standalone/ root@hadoop2:/bigdata/server/spark3-standalone/
scp -r /bigdata/server/spark3-standalone/ root@hadoop3:/bigdata/server/spark3-standalone/
5.测试
启动主节点
cd?/bigdata/server/spark3-standalone/sbin
cat /software/spark2/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop1.out
发现拒绝连接zookeeper:2181
(注意:Standalone模式的单点故障是借助zookeeper实现的,所以要先启动zookeeper集群。)
启动work节点(所有配置中的节点都要执行)
cd /bigdata/server/spark3-standalone/sbin
./start-worker.sh spark://hadoop1:7077
查看日志正常启动
tail -f /software/spark2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop1.out
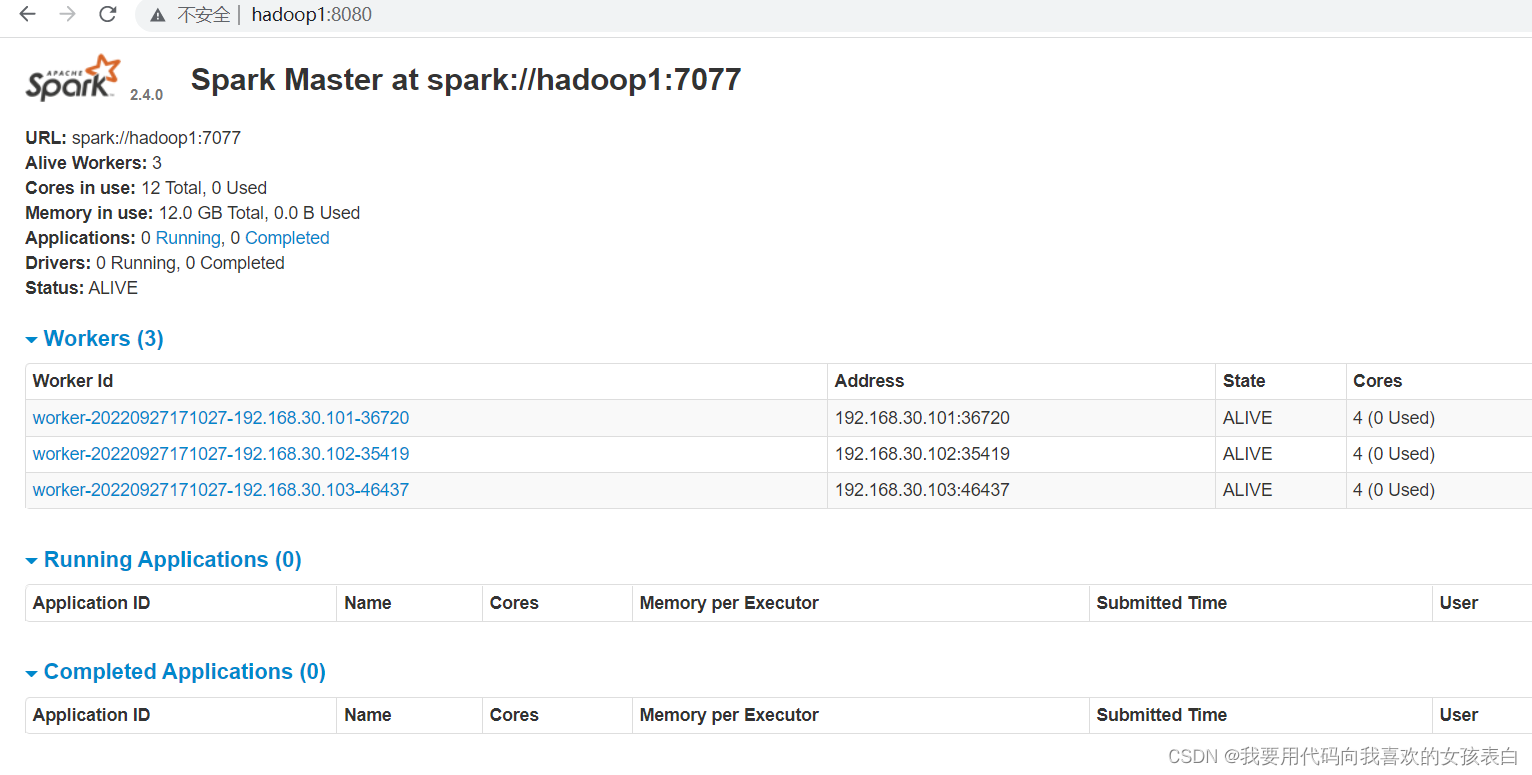
主节点,他默认的是8080端口,从节点默认的是7077端口
Spark Master at spark://hadoop1:7077
我刚启动的三台:
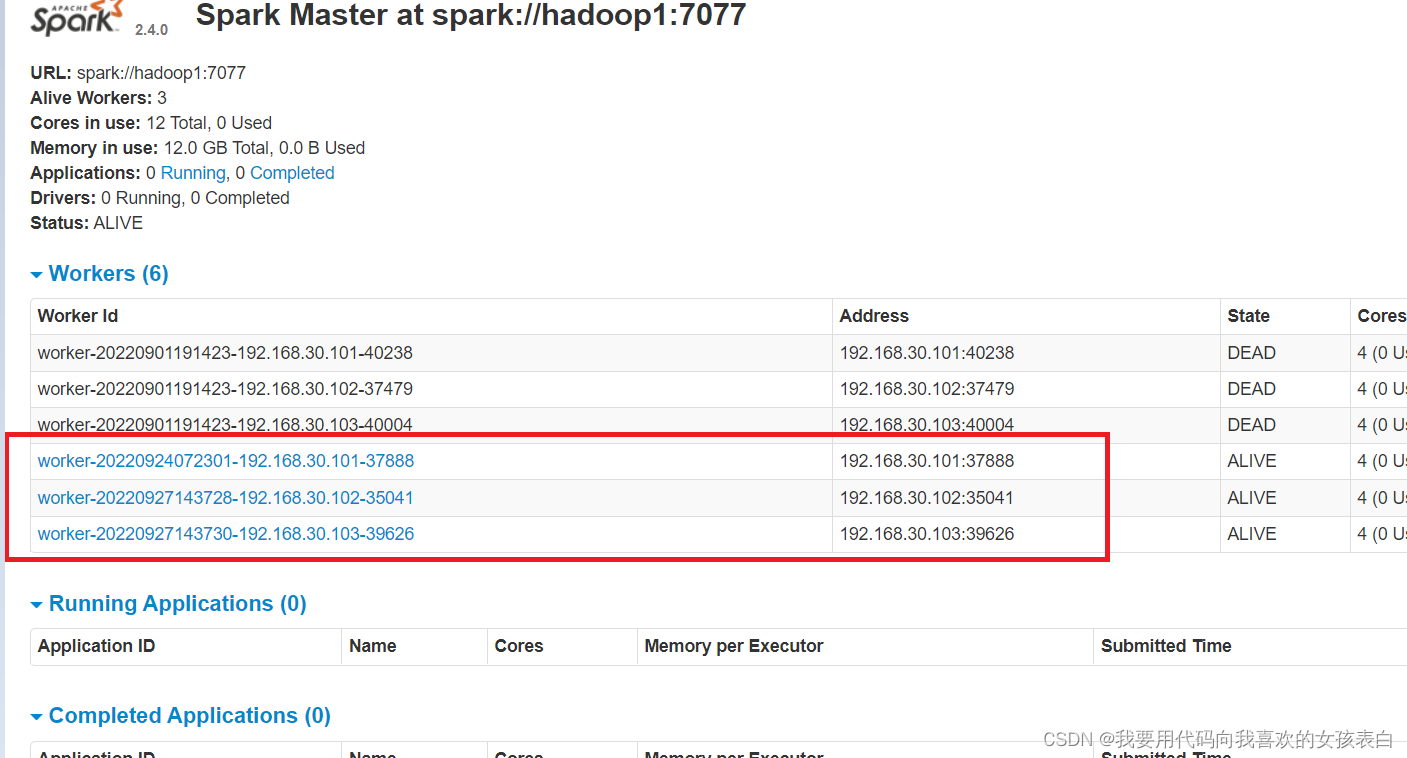
2.3版本的spark,standalone
standalone模式,独立于hadoop,仅仅需要spark
spark下载地址: ??? https://dlcdn.apache.org/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz(注意spark3.2以上需要scala2.13,spark3.0以上需要scala2.12)
创建存放spark的目录
mkdir -p /bigdata/server
1.解压
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /bigdata/server/
改名并且修改目录
mv /bigdata/server/spark-2.3.0-bin-hadoop2.7/ /bigdata/server/spark2-3
2.配置spark的主节点
cd /bigdata/server/spark2-3/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
新增
export SPARK_MASTER_HOST=192.168.30.101
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export SPARK_MASTER_PORT=7077
3.配置work节点
cp slaves.template slaves
vi slaves(把localhost改为集群的ip或者hostname)
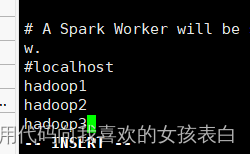
copy配置好的内容到其他节点
scp -r /bigdata/server/spark2-3/ root@hadoop2:/bigdata/server/spark2-3/
scp -r /bigdata/server/spark2-3/ root@hadoop3:/bigdata/server/spark2-3/
启动集群
cd /bigdata/server/spark2-3/sbin
主节点
./start-all.sh
访问matser节点
http://hadoop1:8080
我刚启动的三台
?