一、准备工作
1、本次任务需要三台虚拟机,主机名分别为Master、Slave01、Slave02先在Master上安装好jdk和Hadoop(安装教程可以参考这两篇文章)然后为了简便我们直接克隆两台Master来配置成为Slave01、Slave02;
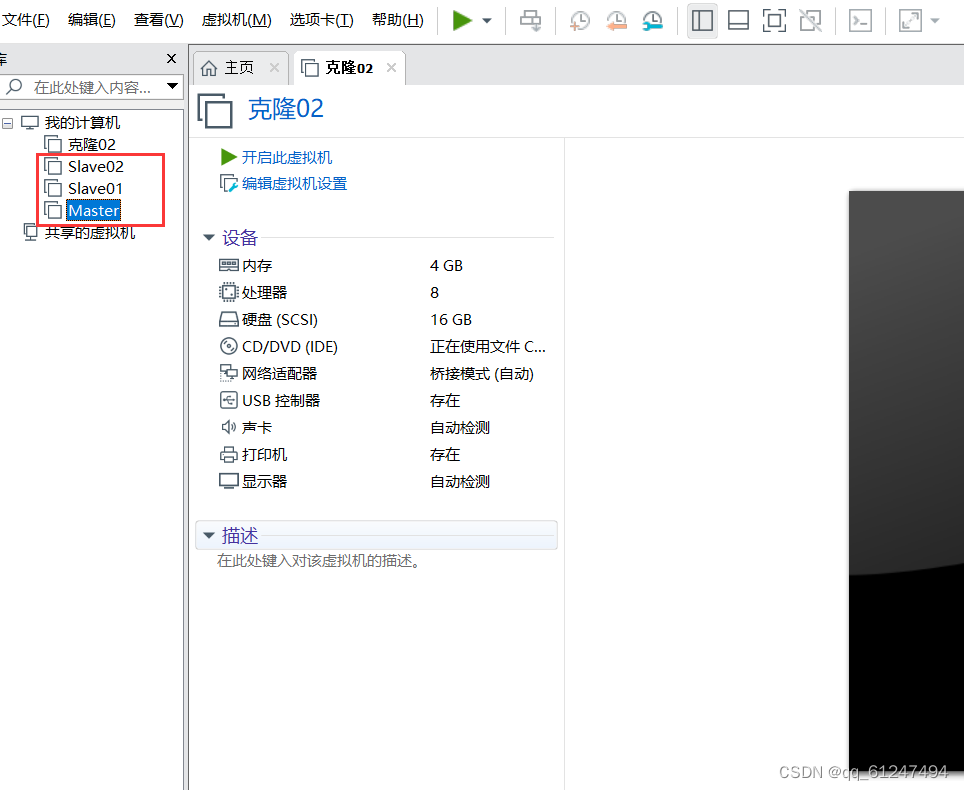
2、把克隆的虚拟机名字改为?Slave01、Slave02
二、配置IP与密钥?
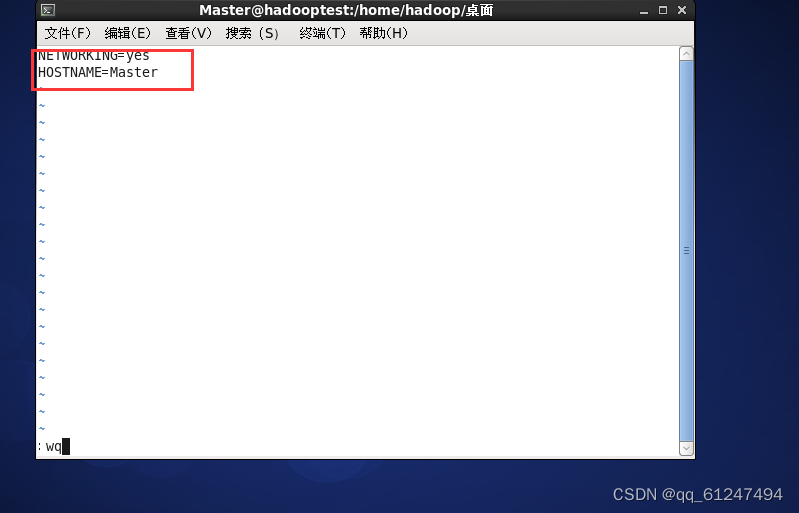
? 1、分别在三台虚拟机上的root下输入命令vi /etc/sysconfig/network编辑为如下内容(另外两台为Slave01、Slave02)
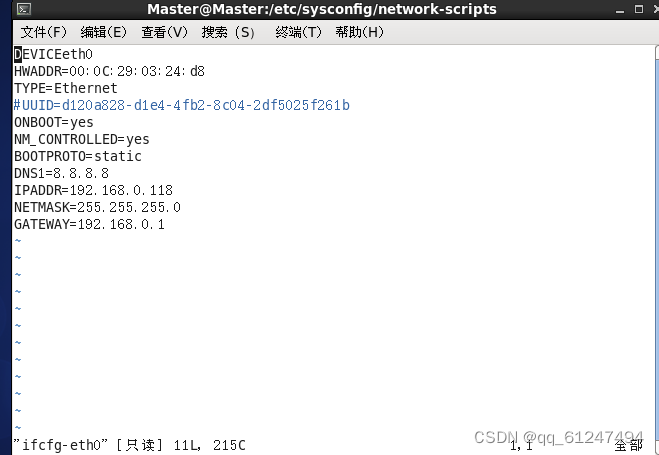
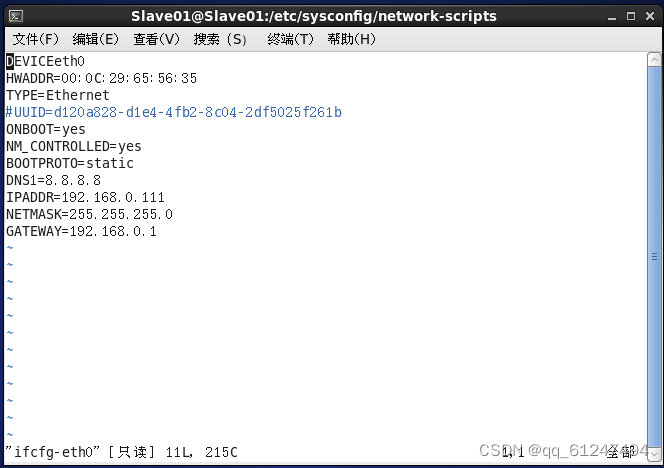
 ?2、在三台虚拟机上分别输入命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0配置IP地址(如图为Master的IP配置,配置完记得重启网络service network restart)
?2、在三台虚拟机上分别输入命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0配置IP地址(如图为Master的IP配置,配置完记得重启网络service network restart)
(如图为Slave01的IP配置)?
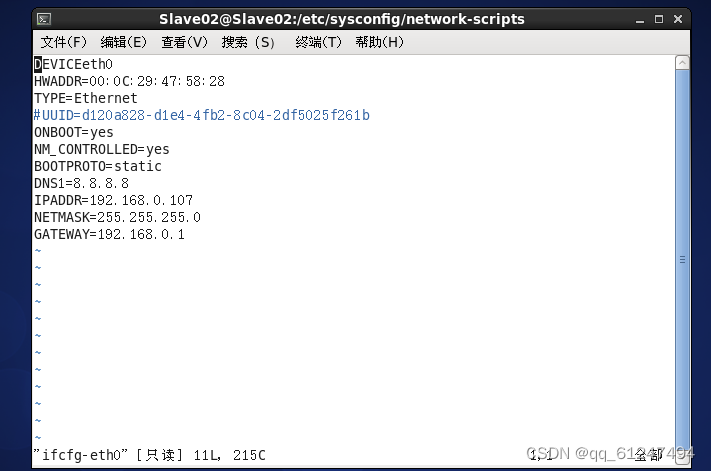
(如图为Slave02的IP配置)?
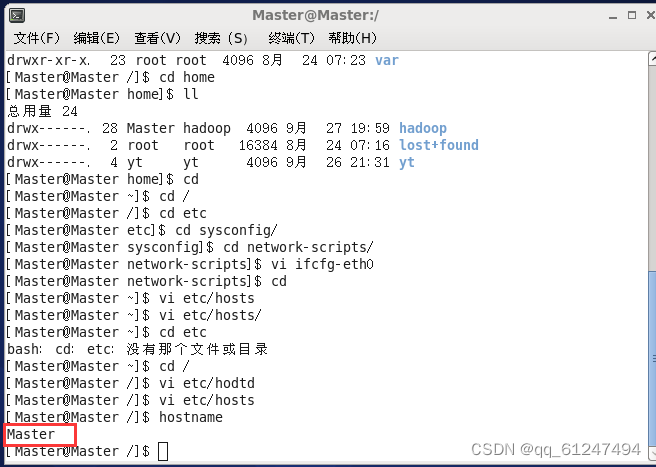
3、输入命令:hostname +主机名更改三台虚拟机的主机名?,第一台为Master?
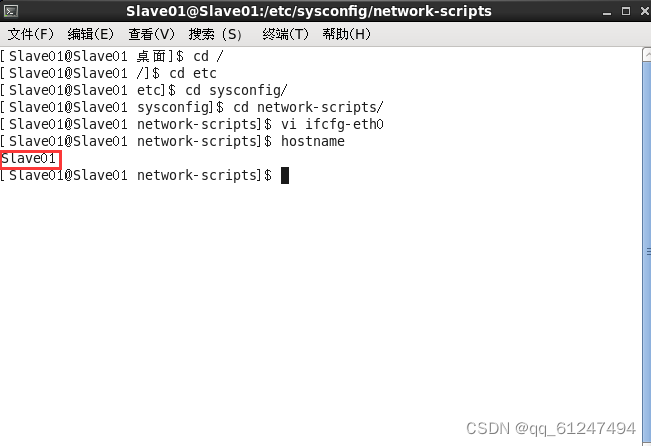
第二台主机名为Slave01?
?第三台主机名为Slave02
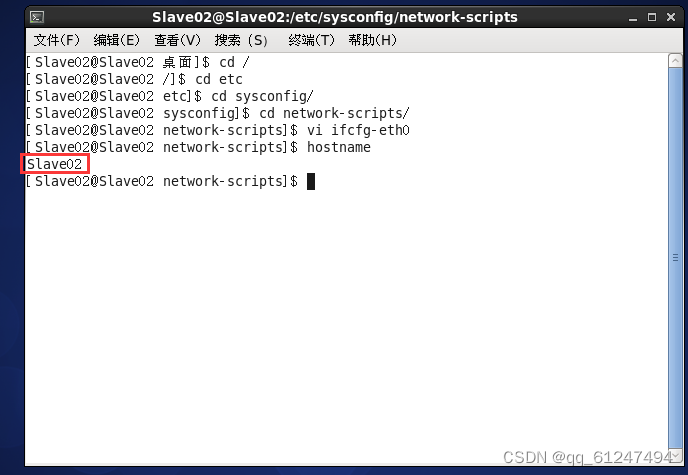
4、分别在三台虚拟机的root上输入命令:vi? /etc/hosts输入三台虚拟机的主机名与对应的IP地址(如图为Master)
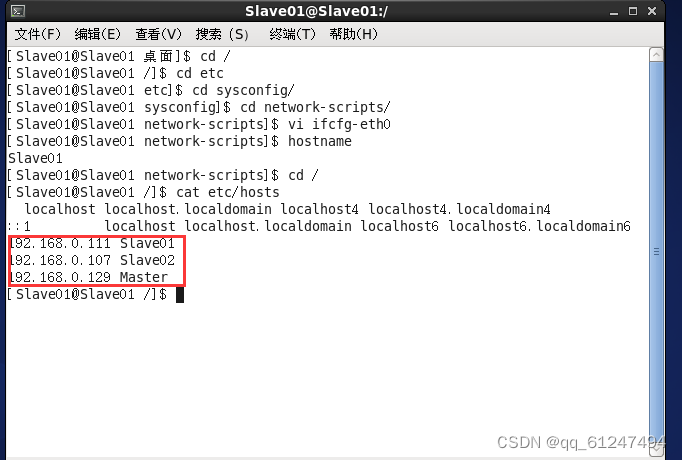
如图为Slave01节点
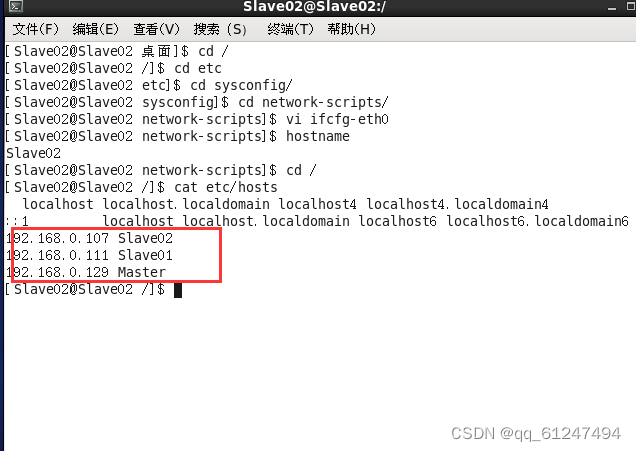
如图为Slave02节点?
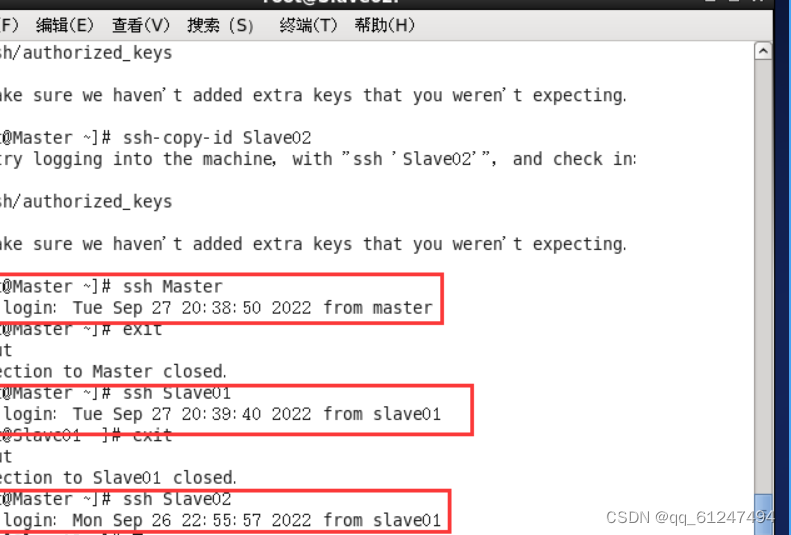
5、在?Master节点上输入配置密钥的命令: ssh-keygen -t rsa 回车之后进入到./ssh目录下输入命令scp authorized_ keys hadoop(当前用户名)@192.168.0.111(Slave01、Slave02的IP地址): /home/ hadoop/.ssh/(Slave01、Slave01的?.ssh文件的路径)。免密成功后如图所示?
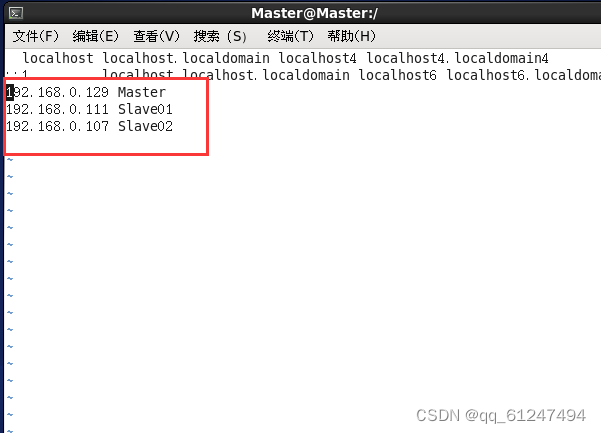
?三、配置文件变量?
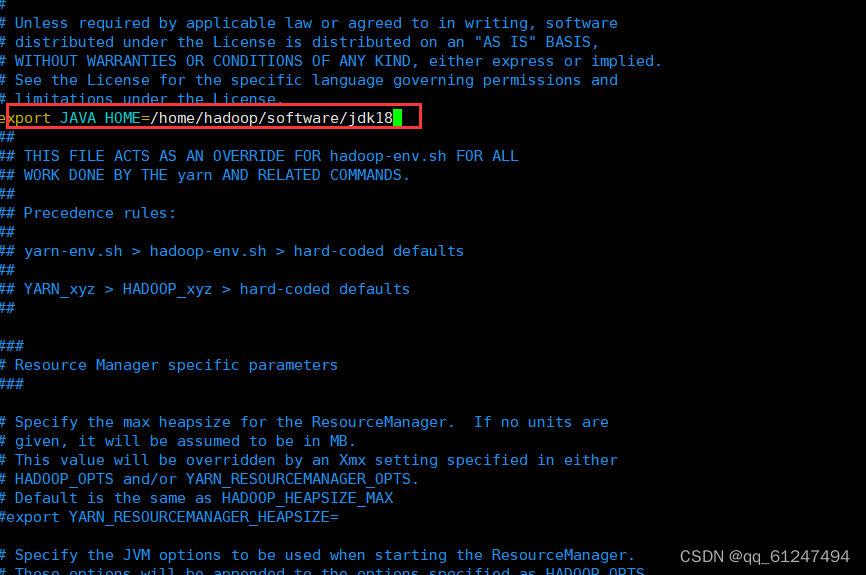
1、分别在三台虚拟机下进入到hadoop文件下输入命令:vi hadoop-env.sh加入 export JAVA_HOME=/home/hadoop/software/jdk18(这里为自己的jdk安装路径)(黑色背景为xshell 远程连接虚拟机后的终端,直接在虚拟机终端输入也可以但是使用xshell连接后便于配置文件内容较多时可以直接复制粘贴)不会使用xshell可以参考这篇文章
 ??
??
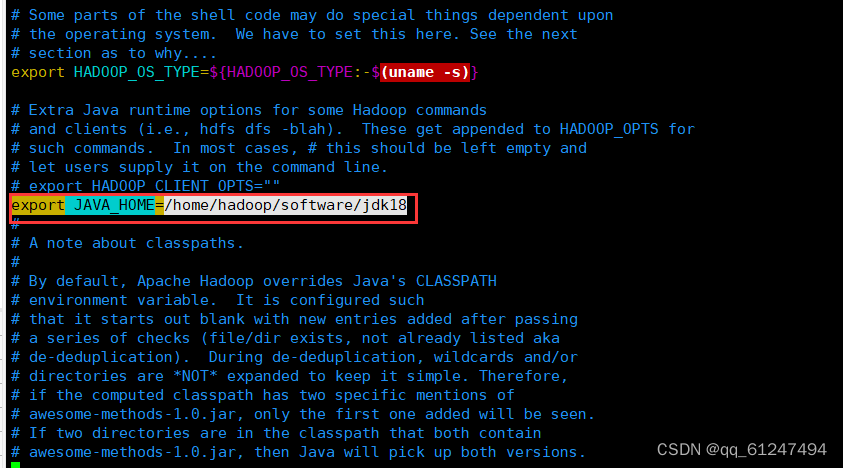
2、输入命令:vi yarn-env.sh也输入自己的jdk安装路径?
 ??
??
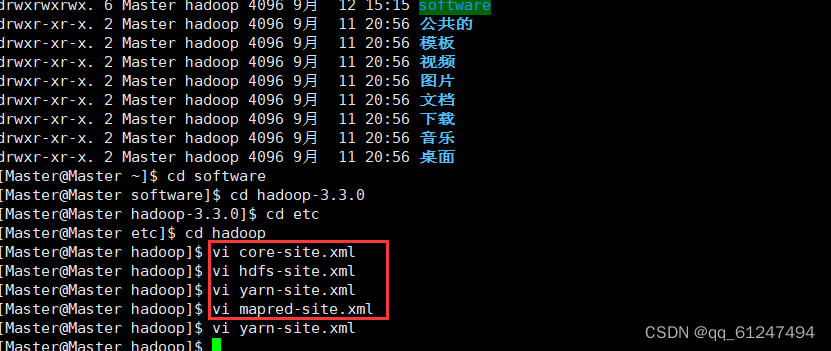
5、接下来需要在三台虚拟机上配置如图四个文件?
 ??
??
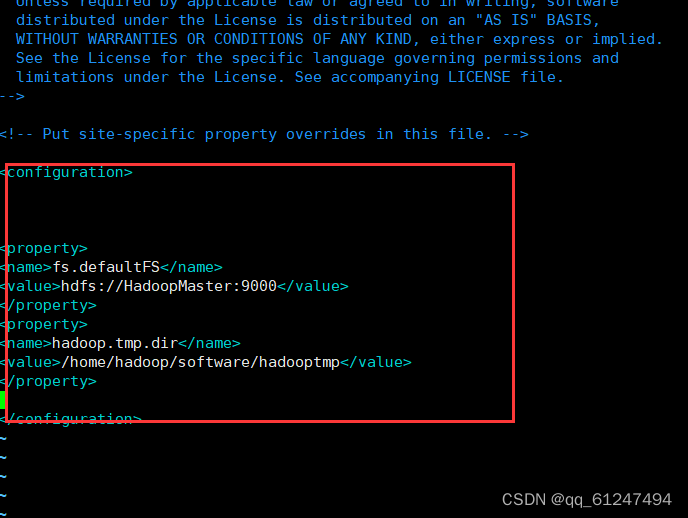
输入命令:vi core-site.xml输入以下内容?
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://HadoopMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadooptmp</value>
</property>
</configuration>
 ??
??
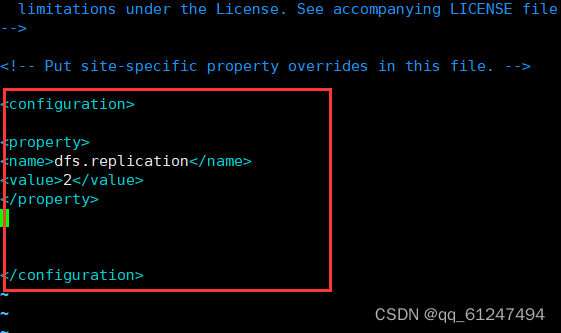
输入命令:vi hdfs-site.xml输入以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
 ??
??
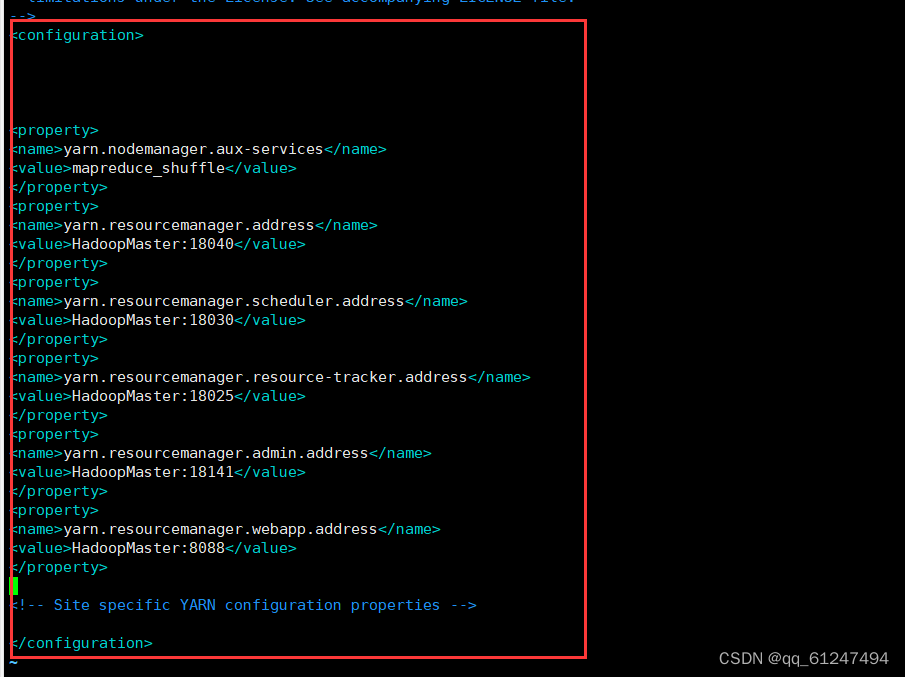
输入命令:vi yarn-site.xml输入以下内容?
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>HadoopMaster:18040</value>
</property>
<property> <name>yarn.resourcemanager.scheduler.address</name>
<value>HadoopMaster:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>HadoopMaster:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>HadoopMaster:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>HadoopMaster:8088</value>
</property>
</configuration>
 ??
??
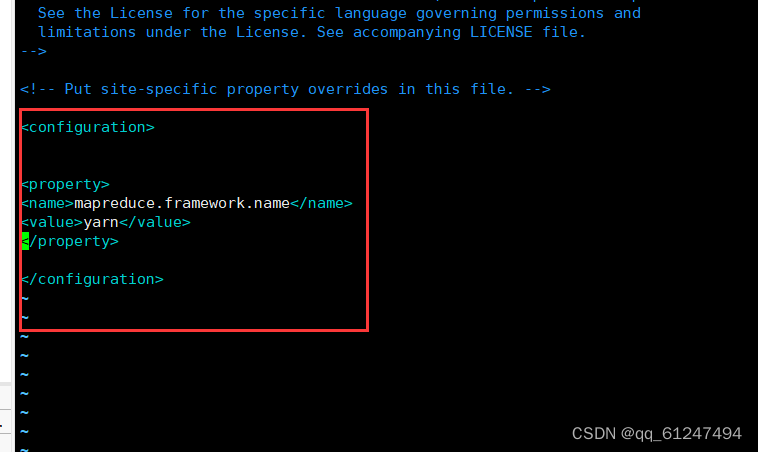
?输入命令:vi mapred-site.xml输入以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
 ??
??
6、在Master节点的hadoop目录下输入命令:vi workers?
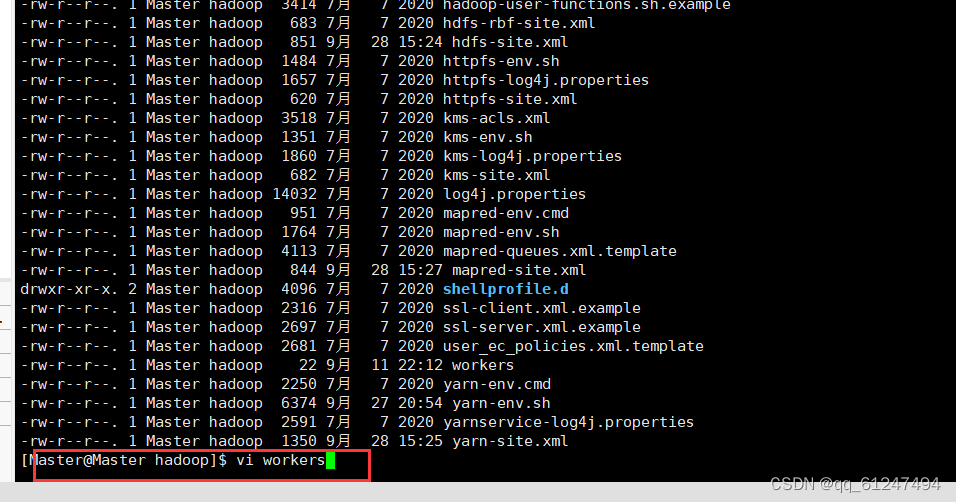 ??
??
编辑内容如下加入Slave01 、Slave02节点
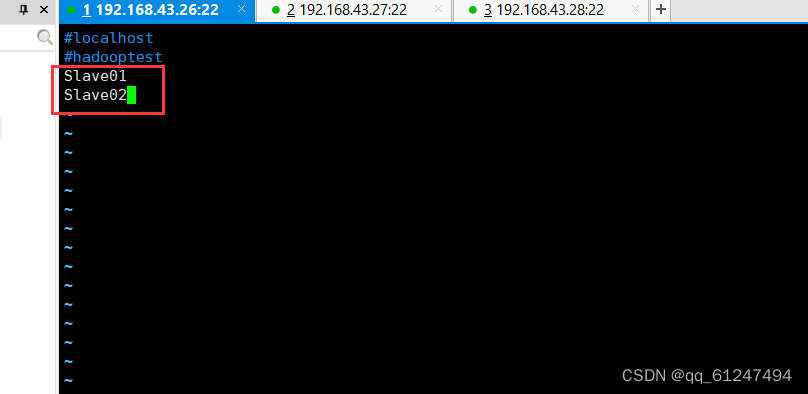 ??
??
四、启动Hadoop全分布式集群
1、输入命令hdfs namenode -format 格式化?
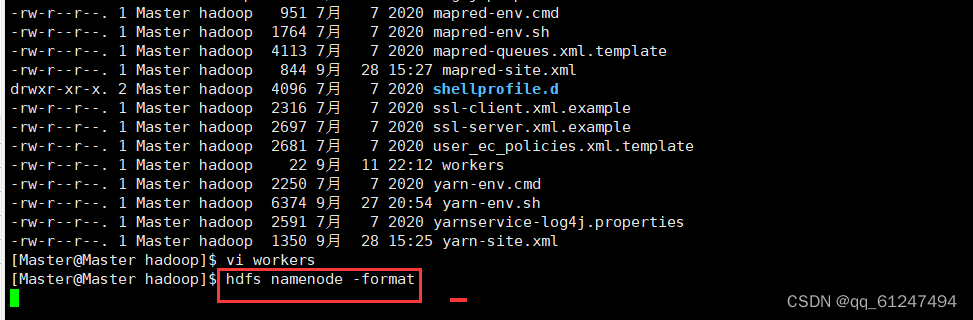 ??
??
2、输入命令:start-all.sh启动Hadoop?
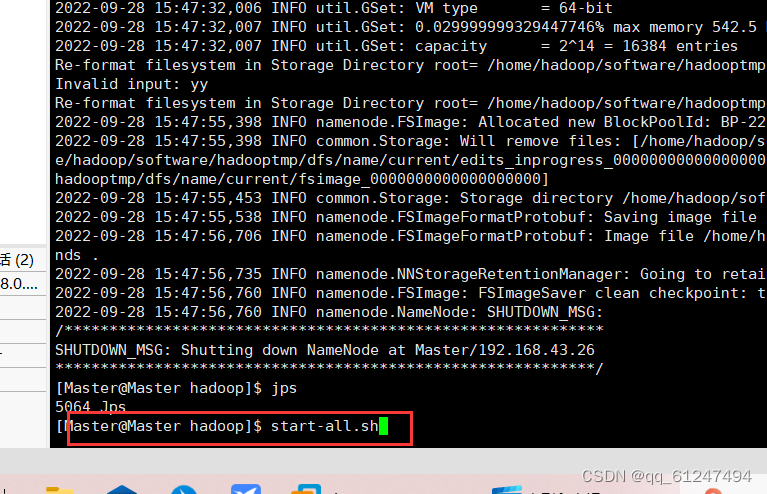 ??
??
3、输入命令:jps查看启动的进程,除JPS外有三个教程即为启动成功??
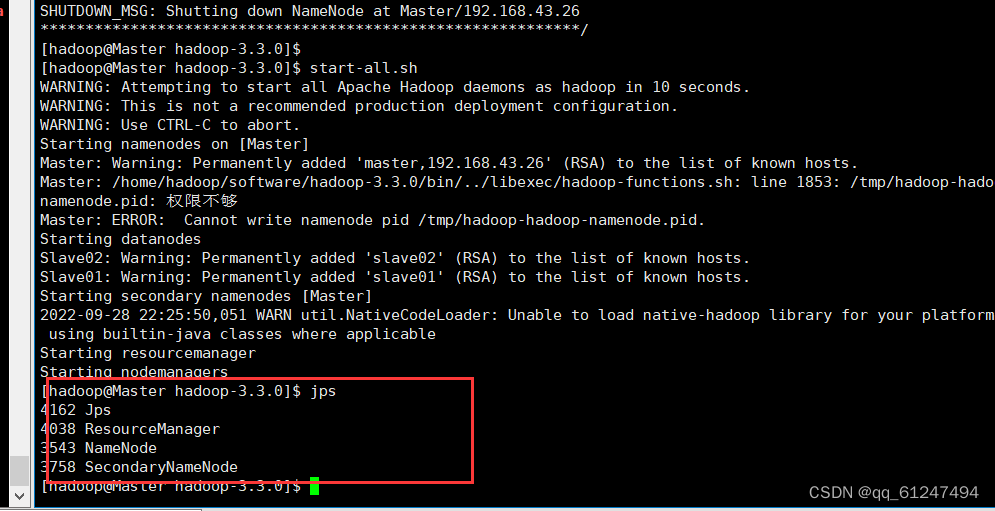 ??
??
4、此时分别在Slave01与Slave02节点上输入命令jps都可以看见有除JPS外的两个进程启动成功?
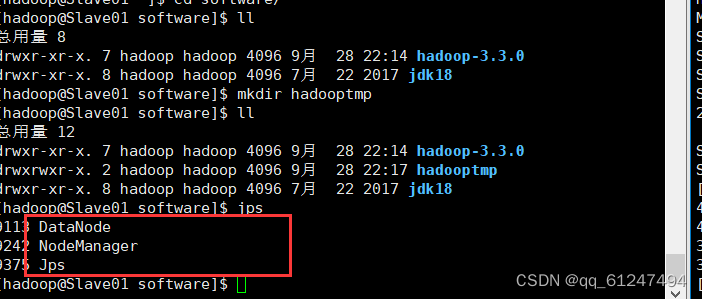 ??
??
五、检验是否完成
1、打开自己的浏览器在网址输入栏输入192.168.0.107:9807进行访问(192.168.0.107为自己虚拟机Master配置的IP地址)?
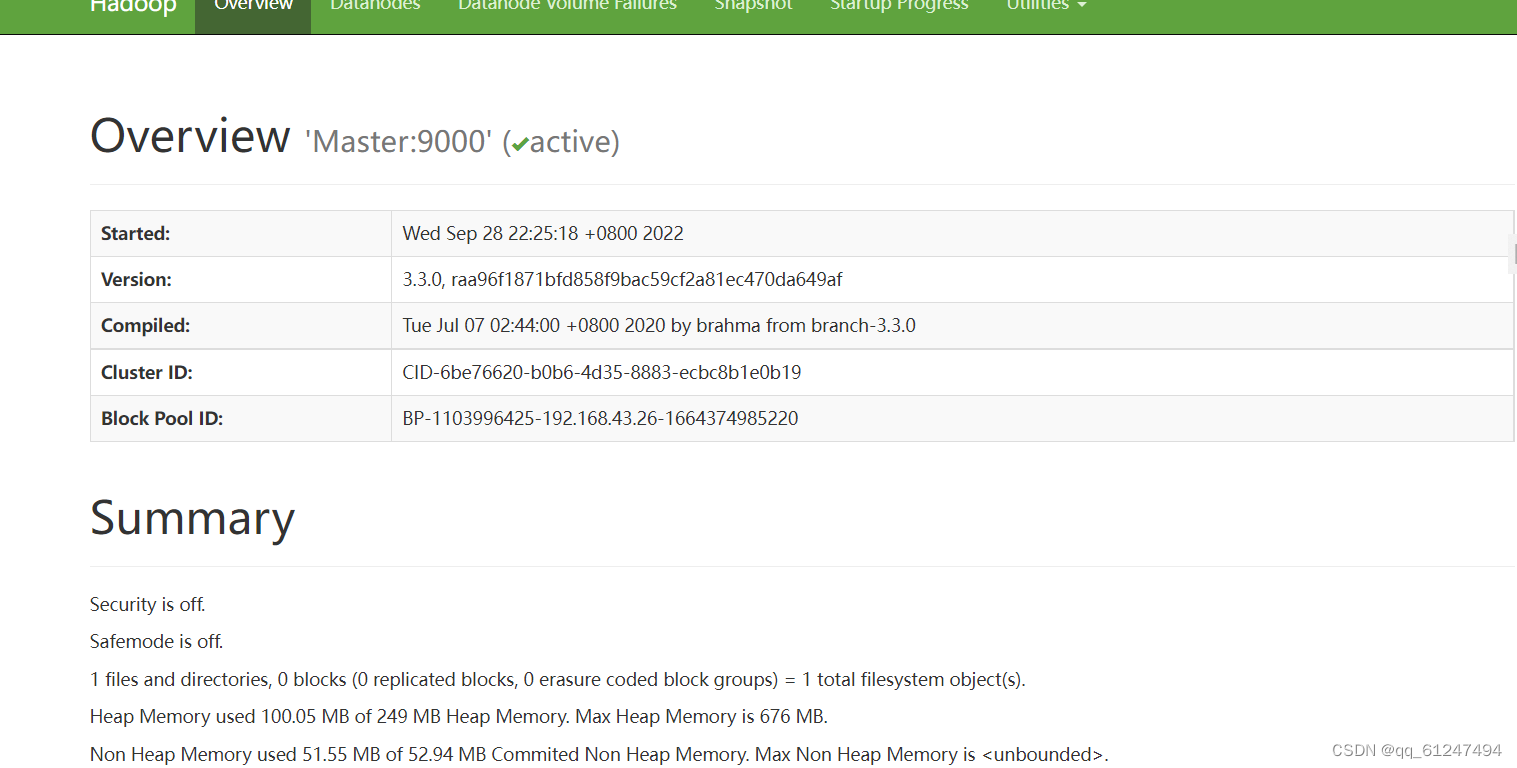 ??
??
?再把9807改为8088就会出现访问如图所示网页?
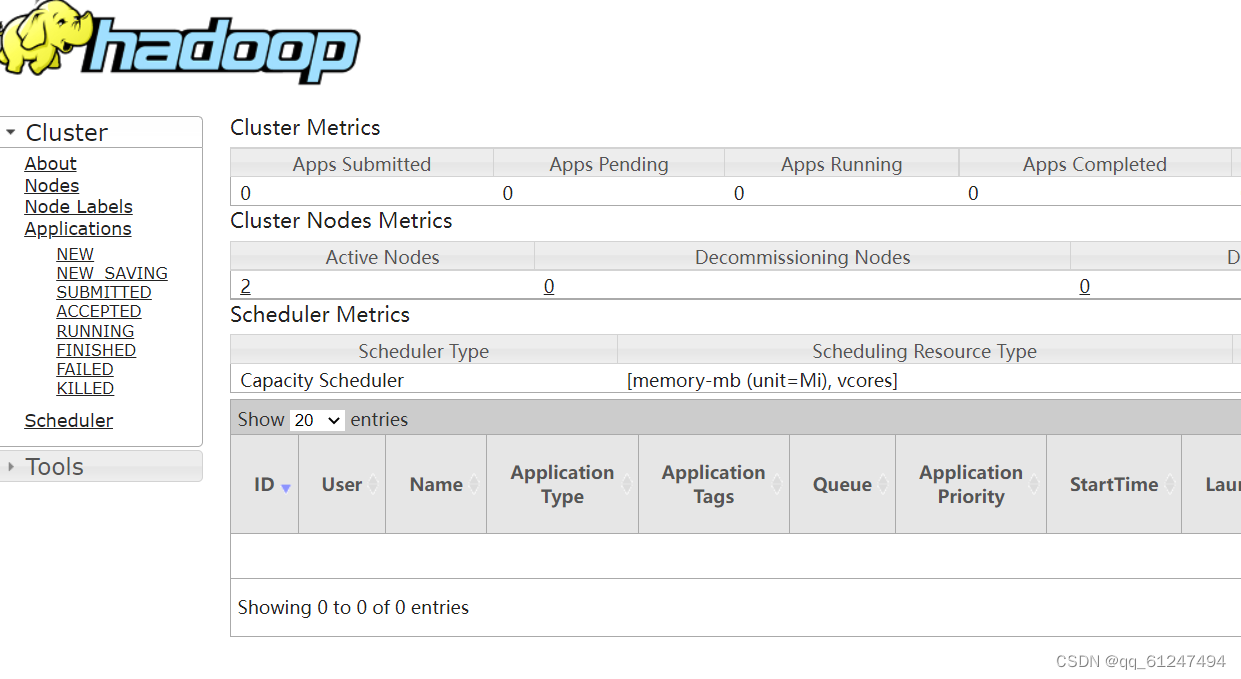 ??
??
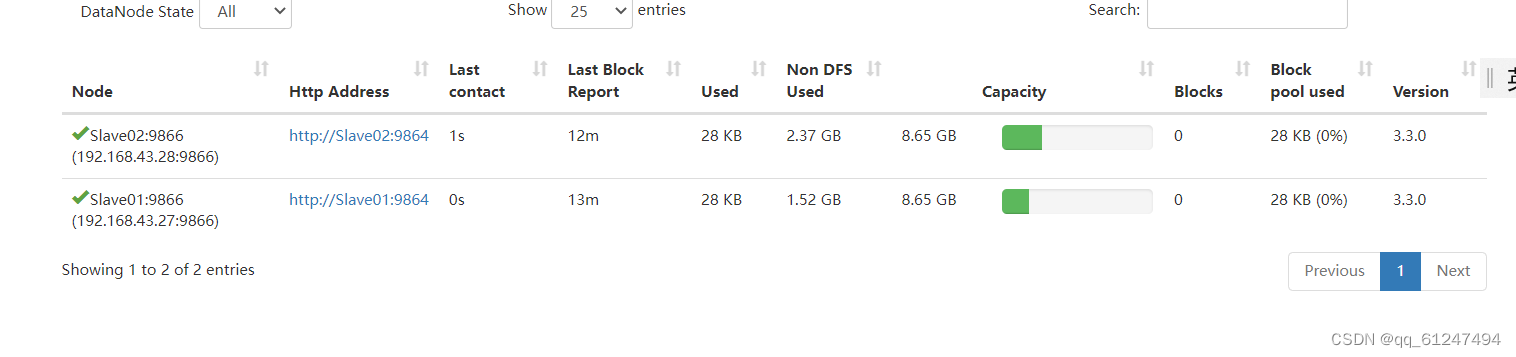 ???这样Hadoop部署全布式集群就部署完成了!!!?
???这样Hadoop部署全布式集群就部署完成了!!!?