1. NN 和 2NN
思考:NameNode 中的元数据是存储在哪里的?【元数据:描述数据的数据,比如文件的属性等等】
- 存在磁盘:因为读写文件都会经过NameNode同意,所以会导致效率低。
- 存在内存:断电数据就会丢失,不可靠。
所以,最终采用的是
磁盘 + 内存。 那么问题又来了,对于计算结果,如:a = 0; a = a +10;是如何存储在磁盘?
- 直接将计算结果20写入磁盘。
- 将计算过程写入磁盘。后面可以复现计算过程。
由于HDFS的追加操作比覆盖写入更快,所以采用的后者。
- 使用
fsimage_xxx文件存储初始数据a = 0;- 使用
edits_xxx文件存储计算过程a = a + 10,- 每隔一段时间
SecondaryNameNode更新fsimage_xxx文件、edits_xxx文件。更新之后fsimage_xxx文件为a = 20,edits_xxx文件内容为空。
文件解释:
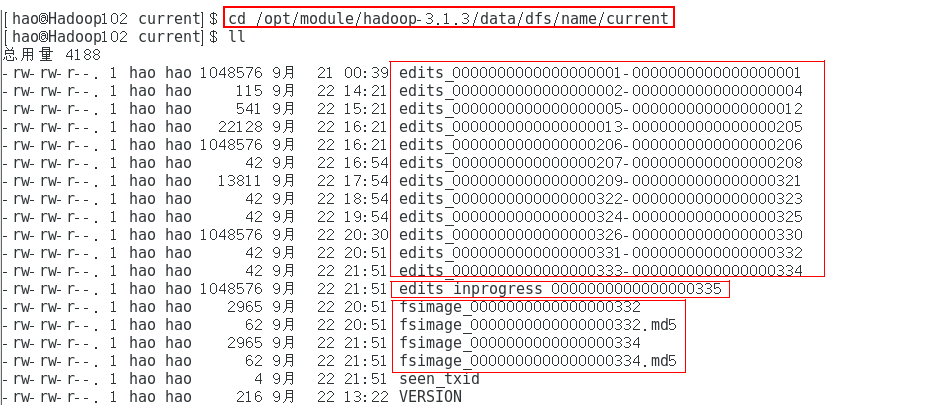
fsimages_xxx文件存放元数据。即 所有目录和文件inode的序列化信息。edits_inprogress_xxx用于临时存储上一次CheckPoint到下一次CheckPoint之间对元数据的改变向量。edits_xxx文件用于存储之前对元数据的改变向量。seen_txid:保存的是一个数字。就是记录当前edits_inprogress_xxx文件的末尾数字xxxVERSION:记录了NameNode的命令空间编号namespaceID,还有集群编号clusterID等信息。
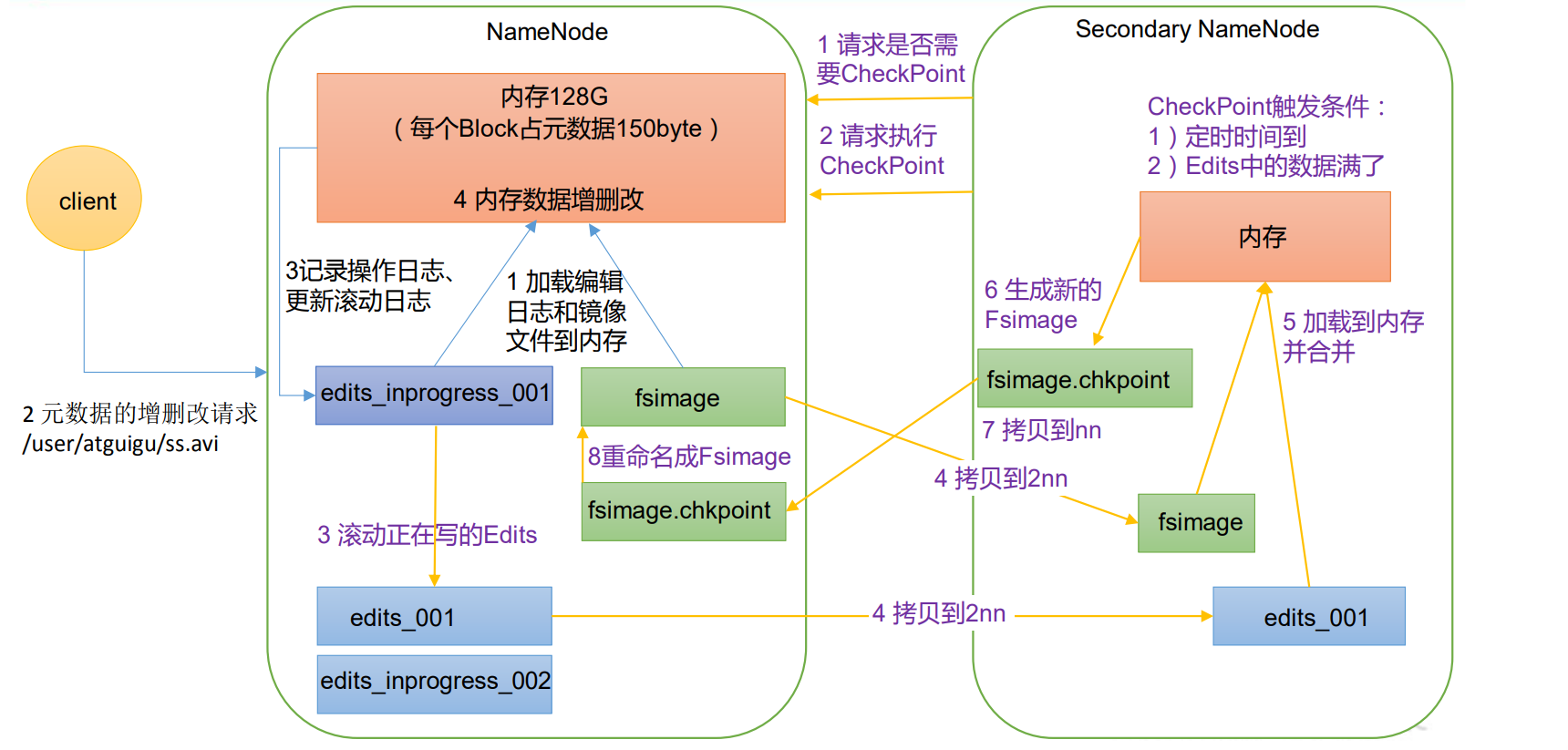
1.1 nn 和 2nn 工作机制
整体的工作流程为:
-
NameNode工作流程:
- 系统启动,将
fsimage_001和edits_inprogress_001从磁盘加载到内存中 - 客户端发出CRUD元数据的请求给NameNode
- NameNode 将修改数据的改变向量写入磁盘的
edits_inprogress_001中,然后同步修改掉内存中的数据
- 系统启动,将
-
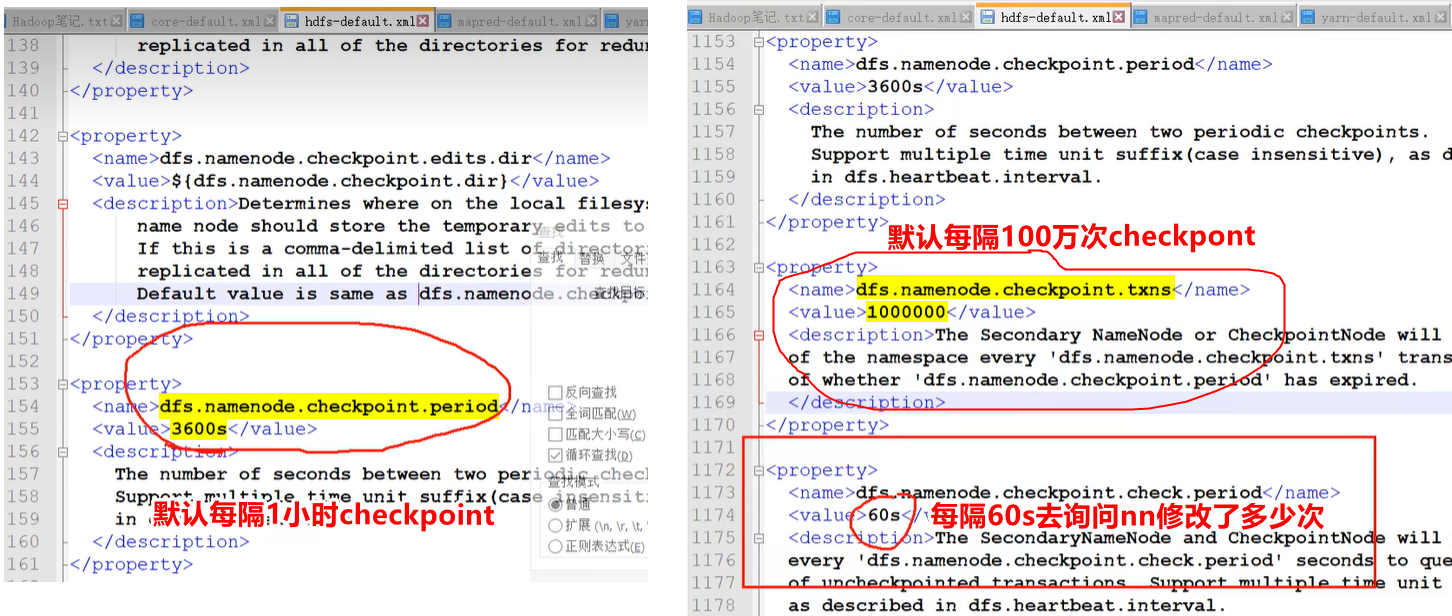
SecondaryNameNode向NameNode发出CheckPoint。而CheckPoint触发条件:
- 定时到了 (默认间隔1小时)
edits_inprogress_xxx文件修改次数过多(默认修改次数达到100万次)
-
当下一次CheckPoint到来时,即 SecondaryNameNode工作流程:
① 创建edits_inprogress_002用于存放新的操作向量。
② 将edit_inprogress_001存储的操作向量滚动写入edits_001-002、edits_002-003【edits_xxx-xxx文件大小是一个块,而edit_inprogress_001可能是多个块大小,所以一个edit_inprogress_001可能产生多个edits_xxx-xxx文件】
③ 将fsimages_001、edits_001-002、edits_002-003复制到SecondaryNameNode所在服务器并加载到内存进行计算,然后在2nn磁盘中创建fsimages_003.chkpoint文件并将计算结果写入其中。【因为最后一个是edits_002-003,所以fsimages后缀为003】
④ 将2nn的fsimages_003.chkpoint拷贝到nn,并重命名为fsimages_003,最后将其加载到内存。
故:2nn里面是没有对元数据最新的操作向量,即没有
edit_inprogress_xxx文件。
1.2 查看 fsImage_xxx 和 edits_xxx 文件
对于seen_txid、VERSION文件可以直接用cat命令打开。但是fsImage_xxx、edits_xxx 文件被加密处理过,用cat命令打开会有部分乱码,故需要专门的命令打开。
-
使用
hdfs oiv命令查看FSImage文件:hdfs oiv -p <文件类型> -d <FSImage文件> -o <转换后要输出的文件> # eg: hdfs oiv -p XML -i /opt/module/hadoop-3.1.3/data/dfs/name/current/fsimage_0000000000000000423 -o /home/hao/temp/fs.xml① 可以用
cat打开fs.xml。
② 也可以将fs.xml远程传输到window系统上,用Nodepad++等高级软件打开:sx /home/hao/temp/fs.xml # 回车后,window系统上会出现下载界面。选择下载路径即可将文件下载到window系统上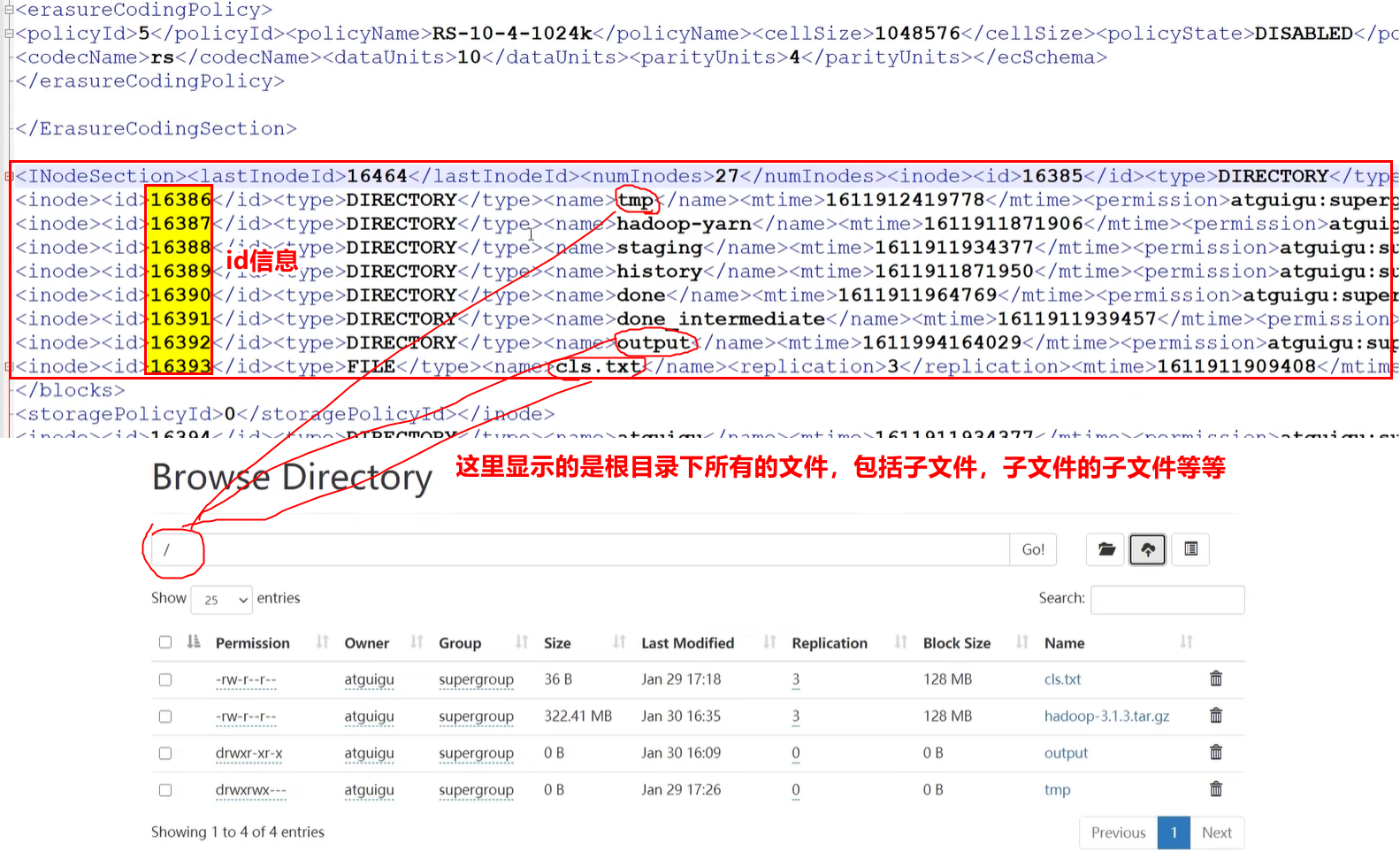

问:为什么 fsimage 中没有记录块所对应 DataNode?
答:在集群启动后,要求 DataNode 向nn上报数据块信息,并间隔一段时间后再次上报。 -
类似的使用
hdfs oev命令查看edits_xxx 、edits_inprogress_xxx 文件:hdfs oev -p <文件类型> -d <FSImage文件> -o <转换后要输出的文件> # eg: hdfs oiv -p XML -i /opt/module/hadoop-3.1.3/data/dfs/name/current/edits_0000000000000000424-0000000000000000425 -o /home/hao/temp/edits.xml其余步骤类似。
2. DN
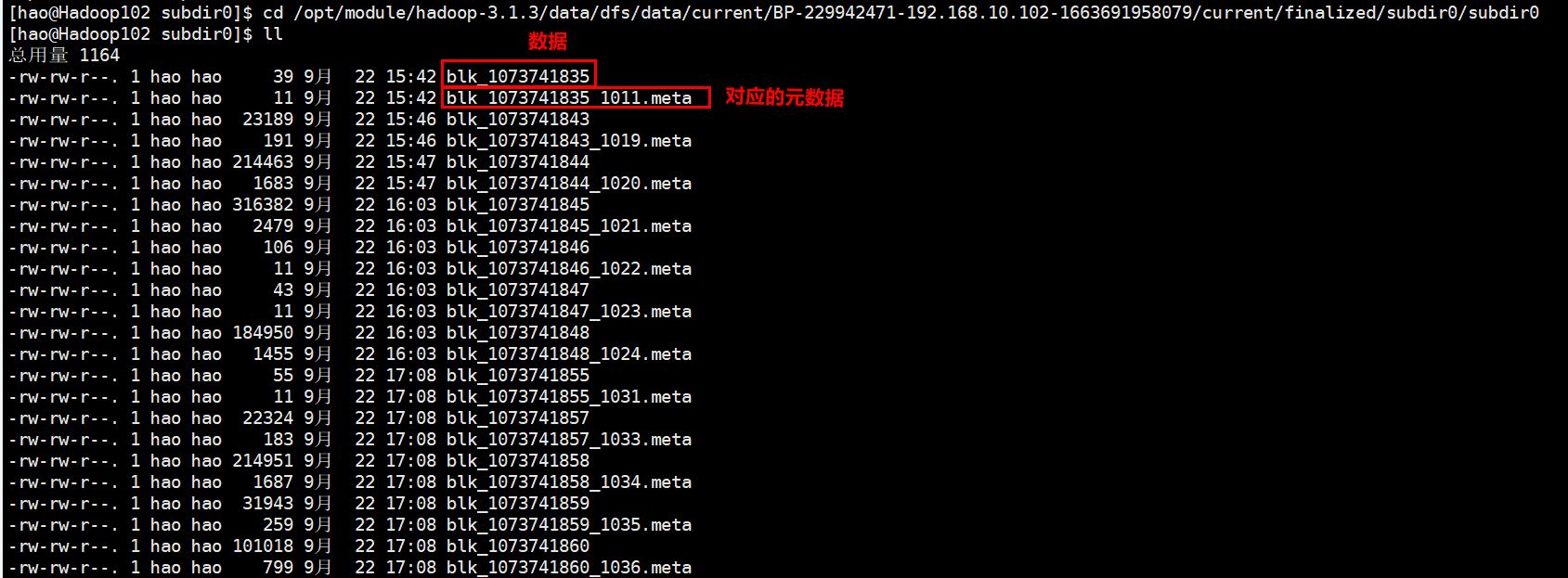
- 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件:一个是数据本身,一个是元数据(包括数据块的长度、块数据的校验和,以及时间戳)。
- 查看
DataNode存放在哪:/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-229942471-192.168.10.102-1663691958079/current/finalized/subdir0/subdir0
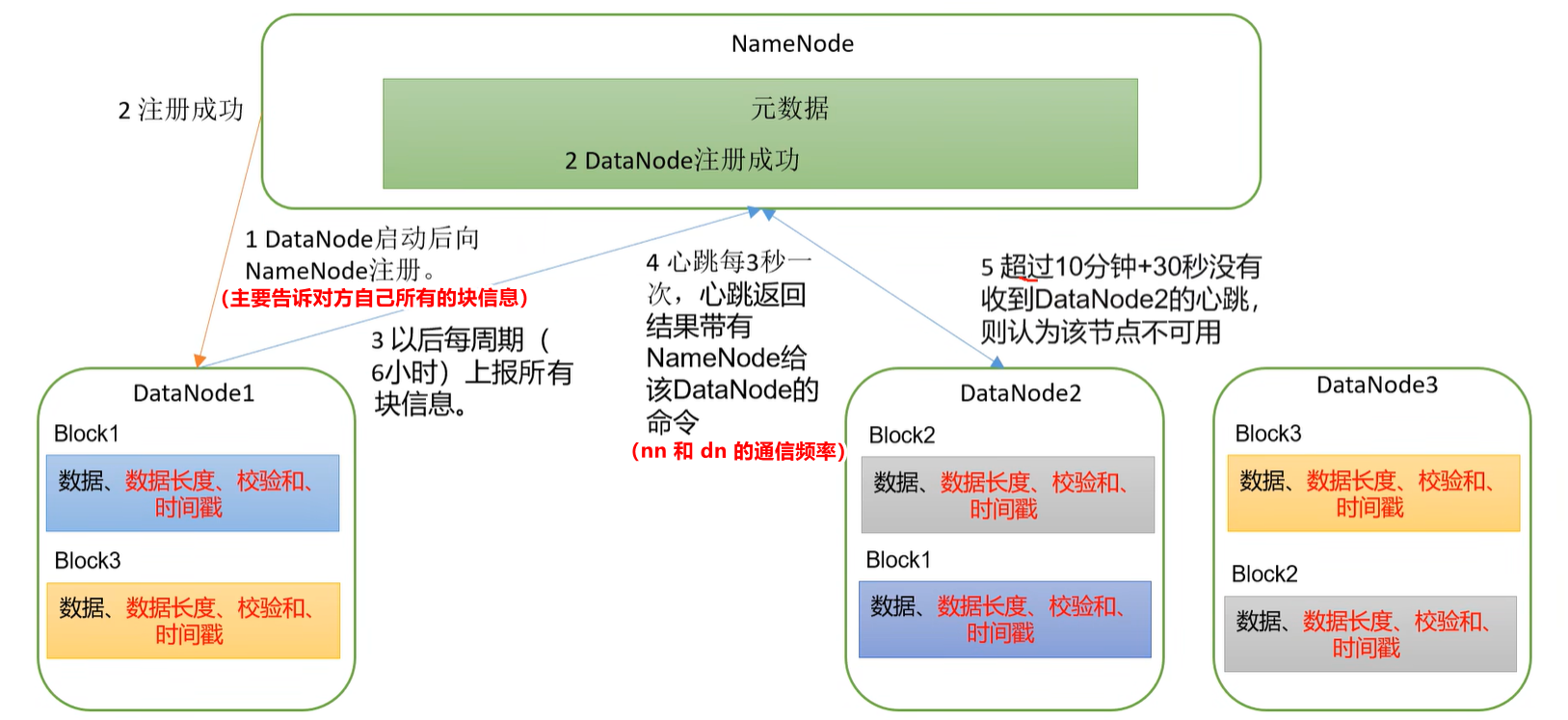
2.1 dn工作机制
工作流程:
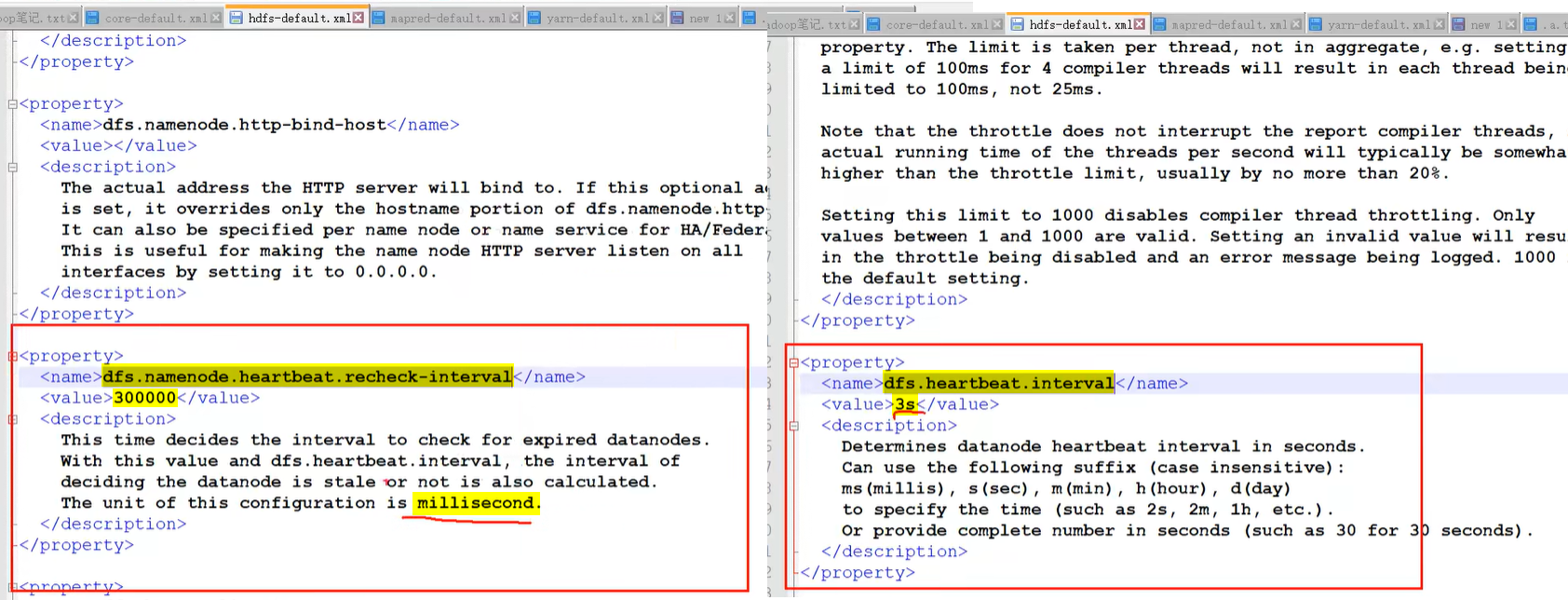
DataNode启动后向NameNode注册(主要是告诉nn自己所有的块信息),通过后,周期性(默认6小时)的向NameNode上报所有的块信息。- 心跳是每3秒一次(即nn 与 dn 的通信频率),心跳返回结果带有NameNode给该DataNode的命令。【如果超过10分钟 + 30秒(超过10分钟,再给10次机会)还没有收到某个DataNode的心跳,就认为该节点不可用,认为该节点宕机了,不会再向该节点传输信息。】
修改设置:
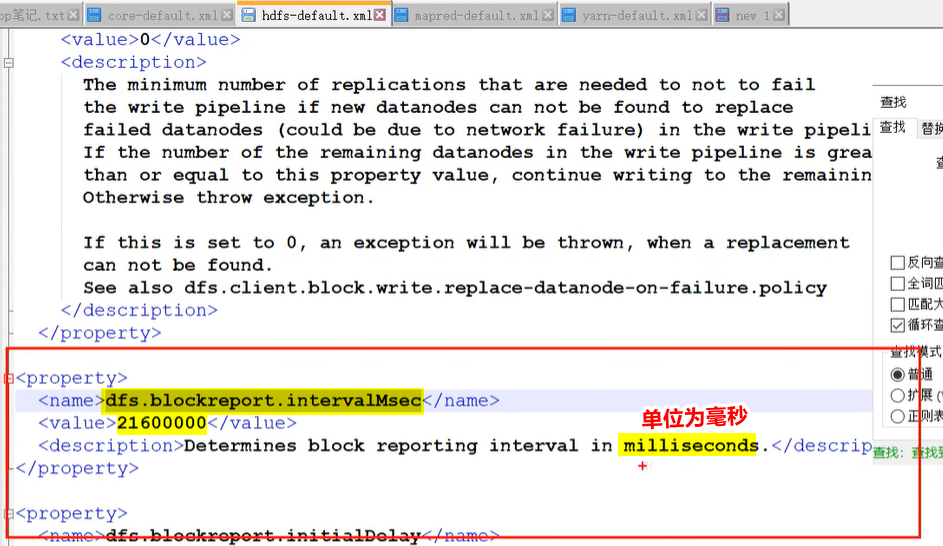
- dn 向 nn 周期性汇报的时间间隔设置:
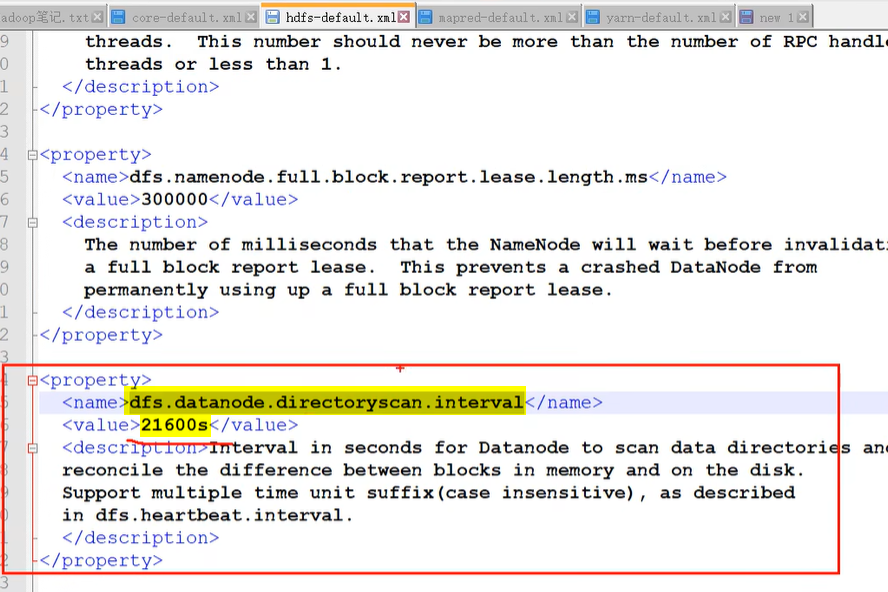
- dn 扫描自己块信息列表的时间间隔:
- 结点不可用的时间设置:

2.2 数据完整性
dn传输数据时使用校验码,常见的校验算法有:crc(32)、md5(128)、sha1(160)。