前言
#博学谷IT学习技术支持#
上篇文章主要介绍了MapReduce的输入和输出以及流程介绍,MapReduce的整个流程大致分为Map阶段、Shuffle阶段和Reduce阶段,本次主要对Shuffle阶段做进一步的梳理。
一、Shuffle介绍
shuffle阶段是MapReduce中的一个重要环节,称为数据洗牌节点,MapReduce先经过Map数据拆分阶段,然后再经过shuffle数据清洗阶段,最后再由Redeuce阶段将清洗后的数据进行汇总,Shuffle阶段主要包括分区、排序、Combiner规约和分组。
二、Shuffle中各流程介绍
(一)自定义分区
-
概述
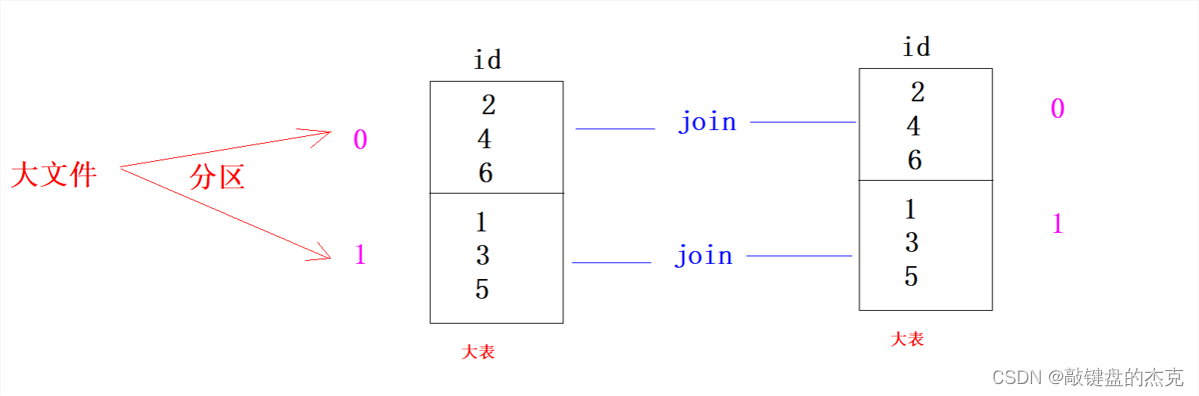
1、分区就是将一份数据根据一定的规则分到不同的文件中;
2、分区的实现的方式为:在Map阶段对K2打标记,标记相同的数据分到同一个区;
3、如果设置了分区则会有多个文件输出,一个Reduce输出一份文件,相同标记的K2会被同一个Reduce读取,输出到同一份文件中,多个Reduce则会生成多份文件;
4、Partition分区就是在Map结束之后,根据Key值不同,给每个Key打上标签,每个Reduce再分别处理不同标签的Key值
(二)自定义排序
-
概述
1、MapReduce中只能根据K2进行排序
2、如果想按照某个字段排序,则应该把这个字段包含在K2中
3、可以自定义Java类进行排序 -
注意要点
1、如果在MapReduce中自定义Java类,则MapReduce对该类有以下要求
1)自定义类必须能够被序列化 ,即需要实现Writable接口
2) 如果该类作为K2,则要求该类必须指定排序规则,即需要实现WritableComparable接口
(三)Combiner规约
- 概述
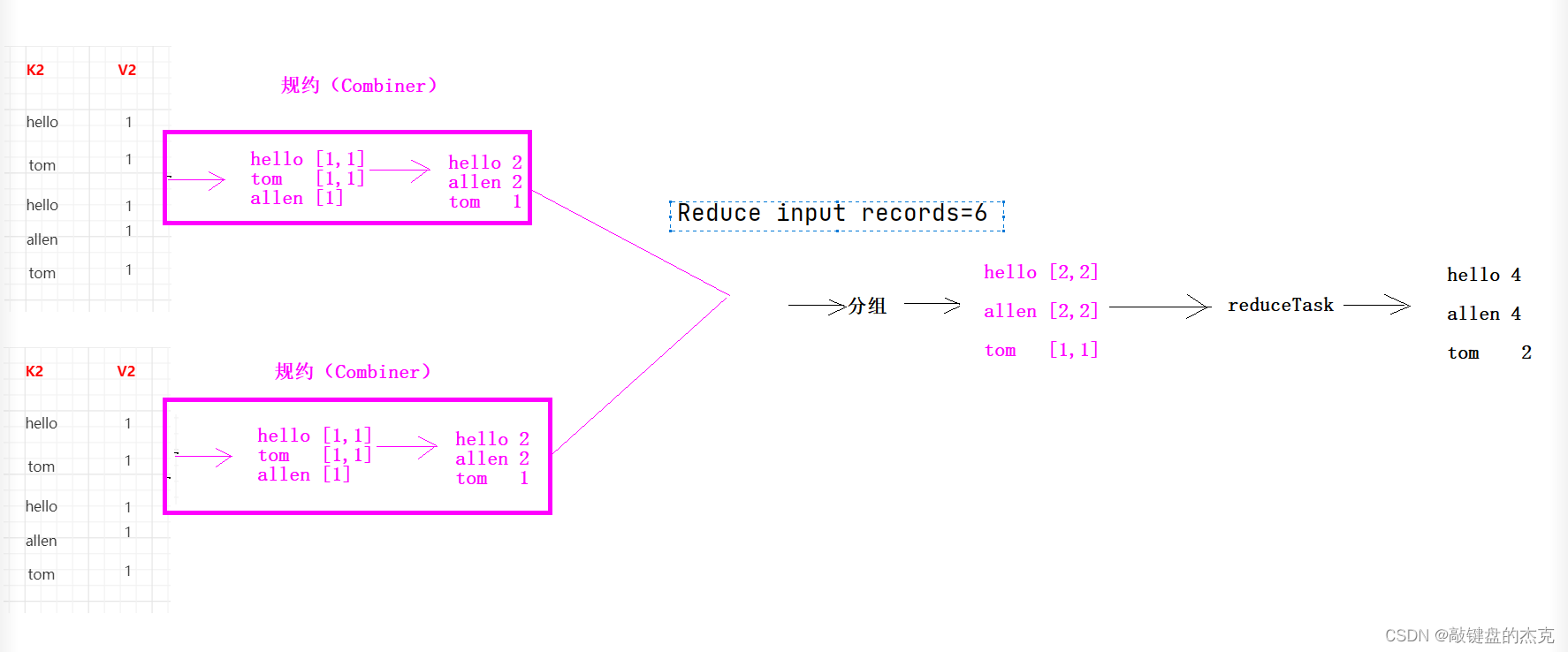
1、Combiner规约是MapReduce中的优化手段,将每一个Map阶段的数据进行提前聚合,减少Map端和Reduce端网络传输的数据量
2、规约相当于为将Reduce的逻辑在Map端先执行一遍
3、Reduce是对所有的Map后的数据进行汇总,而规约是对每一个Map的数据进行汇总
4、Combiner规约只是一种优化手段,不能改变最终的执行结果
(四)自定义分组
- 概述
1、分组的作用就是将K2进行去重,然后相同K2的V2存入集合
2、MapReduce默认的分组是根据K2来决定的,相同K2的数据会被分到同一组
3、当默认的分组,不满足我们的需求时,我们可以使用自定义分组
4、当我们没有指定分组规则时,系统默认调用K2类中的compareTo方法,如果我们自定义了规则,则按照我们的方式来实现分组
总结
MapRedeuce最主要的流程是Map阶段和Reduce阶段,shuffle阶段都有默认执行逻辑,倘若shuffle阶段的默认逻辑无法满足当前需求,则可以对shuffle阶段的分区、排序、combiner规约和分组进行自定义设定,从而达到效果。