����Ŀ¼
- һ��Redis��Linux�����µİ�װ������
- �����־û�
- (һ)����
- (��)RDB
- 1���������ݵ�����(˭,ʲôʱ��,��ʲô����)
- 2��RDB�־û������� saveָ��
- 3��saveָ���������(���� .conf�ļ�)
- 4��saveָ���ԭ��
- 5������������,���߳�ִ�з�ʽ���Ч�ʹ�����δ���?
- 6��RDB������ʽ ���� bgsaveָ��
- 7��bgsaveָ���ԭ��
- 8��bgsaveָ���������
- 9������ִ�б���ָ��,��������ô��?��֪�����ݲ����˶��ٱ仯,��ʱ����?
- 10��RDB������ʽ ����save����
- 11��RDB������ʽ ����save����ԭ��
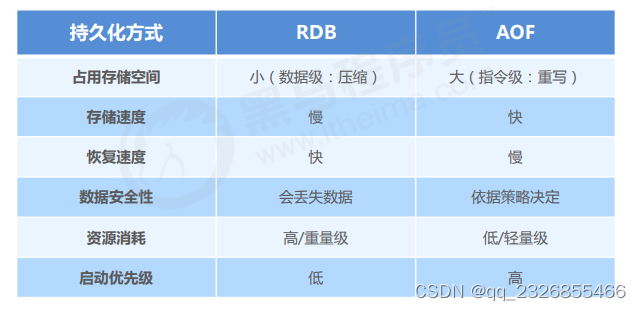
- 12��RDB����������ʽ�Ա�
- 13��rdb����������ʽ
- 14��RDB����ȱ��
- ����AOF
- 1��RDB�洢�ı�
- 2��AOF����
- 3��AOFд���ݹ���
- 4��AOFд���ݵ����ֲ���(appendfsync)
- 5��AOF���ܿ���(����xxx.conf�ļ�)
- 6��AOF�������������
- 7��AOF��д
- 8��AOF�����
- 9��AOF�����
- 10��AOF��д��ʽ
- 11��AOF�ֶ���д ���� bgrewriteaofָ���ԭ��
- 12��AOF�Զ���д��ʽ
- 13��AOF��������
- 14��AOF�����
- 15��RDB��AOF����
- 16��RDB��AOF��ѡ��֮��
- 17���־û�Ӧ�ó���
- �ġ�����
- ����ָ��
һ��Redis��Linux�����µİ�װ������
(һ)����Center OS7��װRedis
? ���ذ�װ��
wget http://download.redis.io/releases/redis-?.?.?.tar.gz
? ��ѹ
tar �Cxvf �ļ���.tar.gz
? ����
make
? ��װ
make install [destdir=/Ŀ¼]
(��)Redis������������
? ����������:
ln -s ԭʼĿ¼�� ���ٷ���Ŀ¼��
? ���������ļ�����Ŀ¼
mkdir conf
mkdir config
? ���������ļ�����Ŀ¼
mkdir data
(��)Redis��������
? Ĭ����������
redis-server
redis-server �C-port 6379
redis-server �C-port 6380 ����
? ָ�������ļ�����
redis-server redis.conf
redis-server redis-6379.conf
redis-server redis-6380.conf ����
redis-server conf/redis-6379.conf
redis-server config/redis-6380.conf ����
(��)Redis�ͻ�������
1��Ĭ������
redis-cli
2�� ����ָ��������
redis-cli -h 127.0.0.1
redis-cli �Cport 6379
redis-cli -h 127.0.0.1 �Cport 6379
(��)Redis���������
? ��������
1��daemonize yes:���ػ����̷�ʽ����,ʹ�ñ�������ʽ,redis���Է������ʽ����,��־�����ٴ�ӡ���������
2��port 6***:�趨��ǰ���������˿ں�
3��dir ��/�Զ���Ŀ¼/redis/data��:�趨��ǰ�����ļ�����λ��,������־�ļ����־û��ļ�(������ϸ����)��
4��logfile "6*.log��**:�趨��־�ļ���,���ڲ���
�����־û�
(һ)����
ʲô�dz־û�
���������Դ洢����(Ӳ��)�����ݽ��б���,���ض���ʱ�佫��������ݽ��лָ��Ĺ������Ƴ�Ϊ�־û���
ΪʲôҪ���г־û�
��ֹ���ݵ����ⶪʧ,ȷ�����ݰ�ȫ��
�־û����̱���ʲô
Redis�д洢�����ݸ�ʽ�Ƕ���������
��:

���淽��һ(����)Ҳ��RDB
? ����ǰ����״̬���б���,�Կ�����ʽ,�洢���ݽ��,�洢��ʽ��,��ע��������
���淽ʽ��(�������)Ҳ��AOF
? �����ݵIJ������̽��б���,��־��ʽ,�洢��������,�洢��ʽ����,��ע�������ݵIJ�������

(��)RDB
1���������ݵ�����(˭,ʲôʱ��,��ʲô����)
����ִ��
? ˭:redis������(�û�)
? ʲôʱ��:��ʱ(��ʱ����)
? ��ʲô����:��������
2��RDB�־û������� saveָ��
����:save
����:�ֶ�ִ��һ�α������
(ÿ����һ��,����ȥ����һ��.rdb���ļ�,�������浱ǰ�Ŀ�����Ϣ)
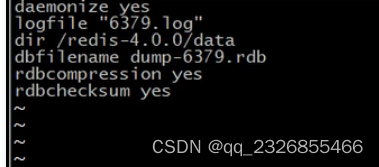
3��saveָ���������(���� .conf�ļ�)
? dbfilename dump.rdb
˵��:���ñ������ݿ��ļ���,Ĭ��ֵΪ dump.rdb
����:ͨ������Ϊdump-�˿ں�.rdb
? dir
˵��:���ô洢.rdb�ļ���·��
����:ͨ�����óɴ洢�ռ�ϴ��Ŀ¼��,Ŀ¼����data
? rdbcompression yes
˵��:���ô洢���������ݿ�ʱ�Ƿ�ѹ������,Ĭ��Ϊ yes,���� LZF ѹ��
����:ͨ��Ĭ��Ϊ����״̬,�������Ϊno,���Խ�ʡ CPU ����ʱ��,����ʹ�洢���ļ����(��)
? rdbchecksum yes
˵��:�����Ƿ����RDB�ļ���ʽУ��,��У�������д�ļ��Ͷ��ļ����̾�����
����:ͨ��Ĭ��Ϊ����״̬,�������Ϊno,���Խ�Լ��д�Թ���Լ10%ʱ������,���Ǵ洢һ������������
������
4��saveָ���ԭ��
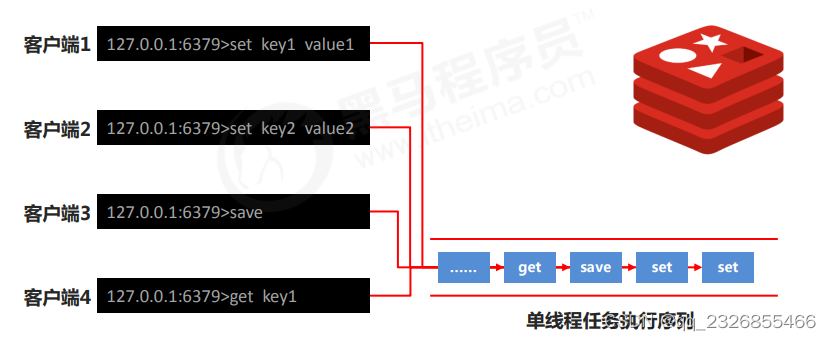
ע��:saveָ���ִ�л�������ǰRedis������,ֱ����ǰRDB�������Ϊֹ,�п��ܻ���ɳ�ʱ������,���ϻ���������ʹ�á�
5������������,���߳�ִ�з�ʽ���Ч�ʹ�����δ���?
��ִ̨��
? ˭:redis������(�û�)����ָ��;redis����������ָ��ִ��
? ʲôʱ��:��ʱ(����);������ʱ��(ִ��)
? ��ʲô����:��������
6��RDB������ʽ ���� bgsaveָ��
? ����:bgsave
? ����:�ֶ�������̨�������,����������ִ��
7��bgsaveָ���ԭ��
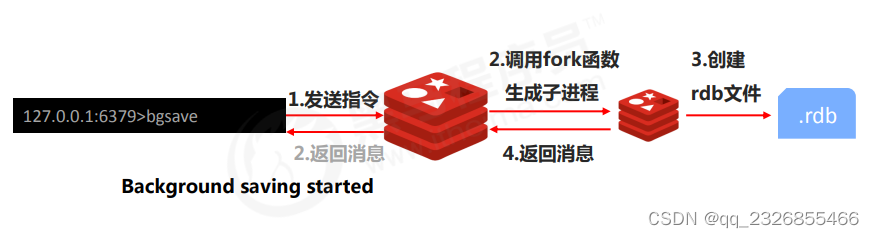
ע��: bgsave���������save�������������Ż���Redis�ڲ������漰��RDB����������bgsave�ķ�ʽ,save������Է���ʹ�á�
8��bgsaveָ���������
? dbfilename dump.rdb
˵��:���ñ������ݿ��ļ���,Ĭ��ֵΪ dump.rdb
����:ͨ������Ϊdump-�˿ں�.rdb
? dir
˵��:���ô洢.rdb�ļ���·��
����:ͨ�����óɴ洢�ռ�ϴ��Ŀ¼��,Ŀ¼����data
? rdbcompression yes
˵��:���ô洢���������ݿ�ʱ�Ƿ�ѹ������,Ĭ��Ϊ yes,���� LZF ѹ��
����:ͨ��Ĭ��Ϊ����״̬,�������Ϊno,���Խ�ʡ CPU ����ʱ��,����ʹ�洢���ļ����(��)
? rdbchecksum yes
˵��:�����Ƿ����RDB�ļ���ʽУ��,��У�������д�ļ��Ͷ��ļ����̾�����
����:ͨ��Ĭ��Ϊ����״̬,�������Ϊno,���Խ�Լ��д�Թ���Լ10%ʱ������,���Ǵ洢һ������������
? stop-writes-on-bgsave-error yes
˵��:��̨�洢������������ִ�������,�Ƿ�ֹͣ�������
����:ͨ��Ĭ��Ϊ����״̬
9������ִ�б���ָ��,��������ô��?��֪�����ݲ����˶��ٱ仯,��ʱ����?
�Զ�ִ��
? ˭:redis����������ָ��(��������)
? ʲôʱ��:��������
? ��ʲô����:��������
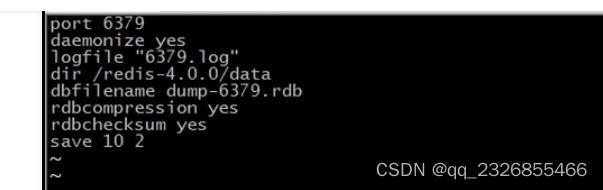
10��RDB������ʽ ����save����
? ����
save second changes
? ����
������ʱ�䷶Χ��key�ı仯�����ﵽָ�����������г־û�
? ����
second:���ʱ�䷶Χ
changes:���key�ı仯��
? �
��conf�ļ��н�������
? ����
save 900 1
save 300 10
save 60 10000
conf������:
11��RDB������ʽ ����save����ԭ��
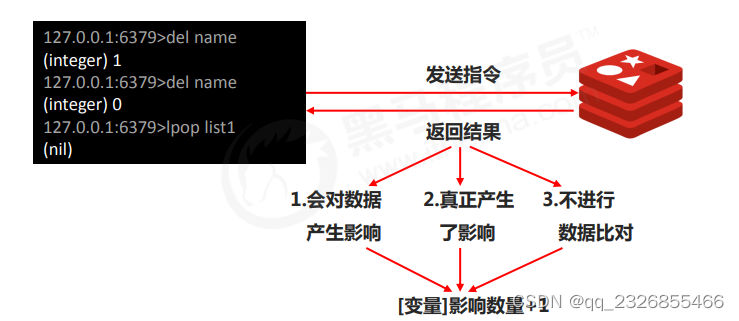
ע��:
save����Ҫ����ʵ��ҵ�������������,Ƶ�ȹ�����Ͷ��������������,��������������Ե�
save�����ж���second��changes����ͨ�����л�����Ӧ��ϵ(һ��һС),������Ҫ���óɰ����Թ�ϵ
save����������ִ�е���bgsave����
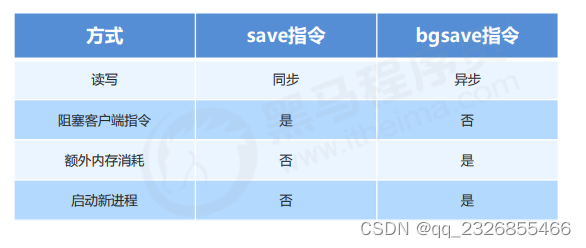
12��RDB����������ʽ�Ա�
13��rdb����������ʽ
? ȫ������
�����Ӹ�������ϸ����
? �����������������:debug reload
? �رշ�����ʱָ����������:shutdown save
Ĭ�������ִ��shutdown����ʱ,�Զ�ִ��
bgsave(���û�п���AOF�־û�����)
14��RDB����ȱ��
RDB�ŵ�:
? RDB��һ������ѹ���Ķ������ļ�,�洢Ч�ʽϸ�
? RDB�ڲ��洢����redis��ij��ʱ�������ݿ���,�dz��ʺ��������ݱ���,ȫ�����Ƶȳ���
? RDB�ָ����ݵ��ٶ�Ҫ��AOF��ܶ�
? Ӧ��:��������ÿXСʱִ��bgsave����,����RDB�ļ�������Զ�̻�����,�������ѻָ�
Rdbȱ��:
? RDB��ʽ������ִ��ָ�����������,������ʵʱ�־û�,���нϴ�Ŀ����Զ�ʧ����
? bgsaveָ��ÿ������Ҫִ��fork���������ӽ���,Ҫ������һЩ����
? Redis���ڶ�汾��δ����RDB�ļ���ʽ�İ汾ͳһ,�п��ܳ��ָ��汾����֮�����ݸ�ʽ����������
����AOF
1��RDB�洢�ı�
? �洢�������ϴ�,Ч�ʽϵ�
���ڿ���˼��,ÿ�ζ�д����ȫ������,����������ʱ,Ч�ʷdz���
? ���������µ�IO���ܽϵ�
? ����fork�����ӽ���,�ڴ������������
? 崻����������ݶ�ʧ����
���˼·
? ��дȫ����,����¼��������
? �������������Ƿ�ı���Ѷ�,�ļ�¼����Ϊ��¼��������
? �����в��������м�¼,�ų���ʧ���ݵķ���
2��AOF����
? AOF(append only file)�־û�:�Զ�����־�ķ�ʽ��¼ÿ��д����,����ʱ������ִ��AOF�ļ�������
�ﵽ�ָ����ݵ�Ŀ�ġ���RDB��ȿ���������Ϊ�ļ�¼����Ϊ��¼���ݲ����Ĺ���
? AOF����Ҫ�����ǽ�������ݳ־û���ʵʱ��,Ŀǰ�Ѿ���Redis�־û���������ʽ
3��AOFд���ݹ���
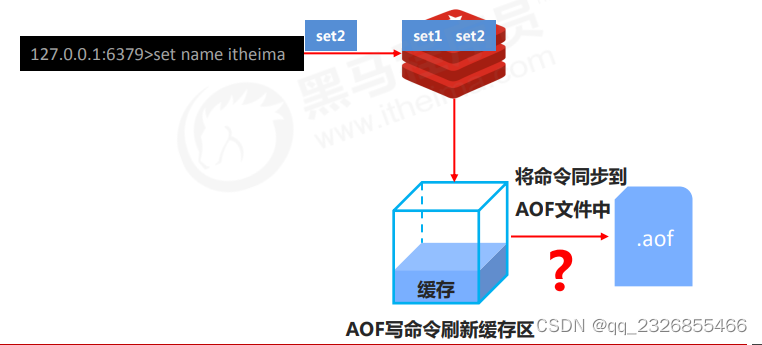
���ͻ��˷��ͳ�һ��ָ�������ʱ,���������յ�����ָ��,��������û�����ϼ�¼�����Ƿŵ���һ����ʱ����(AOFд����Ļ�����),����һ���κ�,������ͬ����aof�ļ���
4��AOFд���ݵ����ֲ���(appendfsync)
? always(ÿ��:��һ��ָ���һ��)
ÿ��д�������ͬ����AOF�ļ���,���������,���ܽϵ�������ʹ�á�
? everysec(ÿ��:ÿһ��ȥ��һ��)
ÿ�뽫�������е�ָ��ͬ����AOF�ļ���,����ȷ�Խϸ�,���ܽϸ� ��ϵͳͻȻ崻�������¶�ʧ1���ڵ�����,����ʹ��,Ҳ��Ĭ������
? no(ϵͳ����)
�ɲ���ϵͳ����ÿ��ͬ����AOF�ļ�������,����������ɿ�
5��AOF���ܿ���(����xxx.conf�ļ�)
? ����:appendonly yes|no Ĭ��Ϊno
? ����:�Ƿ���AOF�־û�����,Ĭ��Ϊ������״̬
? ����:appendfsync always|everysec|no Ĭ��Ϊalways
? ����:AOFд���ݲ���
AOF����������
? ����:appendfilename filename
? ����AOF�־û��ļ���,Ĭ���ļ���δappendonly.aof,��������Ϊappendonly-�˿ں�.aof
? ����:dir
? ����:AOF�־û��ļ�����·��,��RDB�־û��ļ�����һ�¼���
������
6��AOF�������������
�������ִ������ָ�����δ���:
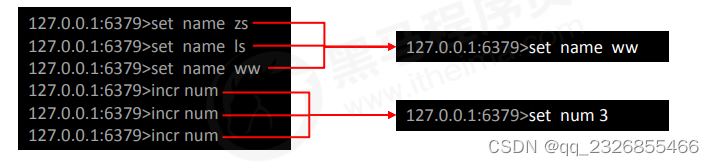
�������ִ������ָ��,����Խ�set�ϲ�Ϊ���һ��,��incr�ϲ�Ϊ3,��Ϊsetֻ�����һ����Ч��,ִ������incr�൱��ִ����һ��set num 3,����AOP���ṩ�������Ĺ��ܡ���д
7��AOF��д
���������д��AOF,�ļ���Խ��Խ��,Ϊ�˽���������,Redis������AOF��д����ѹ���ļ������AOF�ļ���д�ǽ�Redis�����ڵ�����ת��Ϊд����ͬ������AOF�ļ��Ĺ�������˵���ǽ���ͬһ�����ݵ����ɸ�������ִ�н�
��ת�������ս�����ݶ�Ӧ��ָ����м�¼��
8��AOF�����
? ���ʹ���ռ����,��ߴ���������
? ��߳־û�Ч��,���ͳ־û�дʱ��,���IO����
? �������ݻָ���ʱ,������ݻָ�Ч��
9��AOF�����
? �������ѳ�ʱ�����ݲ���д���ļ�
? ������Чָ��,��дʱʹ�ý���������ֱ������,�����µ�AOF�ļ�ֻ�����������ݵ�д������
��del key1�� hdel key2��srem key3��set key4 111��set key4 222��
? ��ͬһ���ݵĶ���д����ϲ�Ϊһ������
��lpush list1 a��lpush list1 b�� lpush list1 c ����ת��Ϊ:lpush list1 a b c��
Ϊ��ֹ������������ɿͻ��˻��������,��list��set��hash��zset������,ÿ��ָ�����д��64��Ԫ��
10��AOF��д��ʽ
? �ֶ���д:bgrewriteaof ��set������bgrewriteaof��д
11��AOF�ֶ���д ���� bgrewriteaofָ���ԭ��
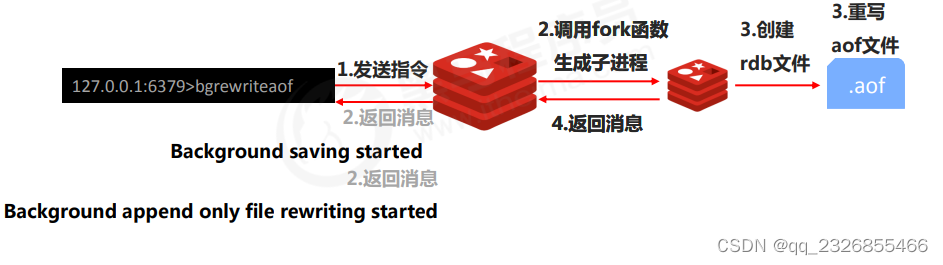
background saving started��bgsave���ص���Ϣ
Background append only file rewriting started ��bgrewriteaof���ص���Ϣ
12��AOF�Զ���д��ʽ
AOF�Զ���д��ʽ:
auto-aof-rewrite-min-size size �Զ�aop�Զ���д�Ĵ�С����
auto-aof-rewrite-percentage percent �Զ���д�İٷֱ� ����
? �Զ���д�����ȶԲ���( ����ָ��info Persistence��ȡ������Ϣ )
aof_current_size ��ʶaof�������Ѿ��еĴ�С
aof_base_size ������С

����1:aof_current_size>auto-aof-rewrite-min-size:��ʶ��ǰ�Ĵ�С�����õ��Զ���д�Ĵ�Сʱ��д
����2:���еĴ�С��ȥ������СȻ����Ի�����С�İٷֱȴ��ڻ�������õ��Զ���д�İٷֱ�����д
�鿴redis��������������ֵ��ָ��:info
13��AOF��������
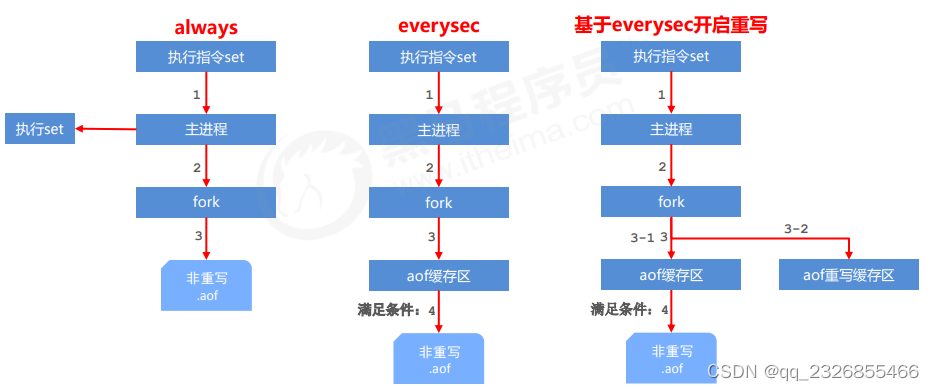
always:ָ����������������,Ȼ��ִ��set��ͬʱ����fork,�ٽ���Ϣд�뵽aof�ļ���
everysec:ָ����������������,��ִ��set��ͬʱ����fork,�ٽ���Ϣװ�뵽aof�Ļ�������,�ȵ��ﵽʱ���д��aof�ļ���
14��AOF�����
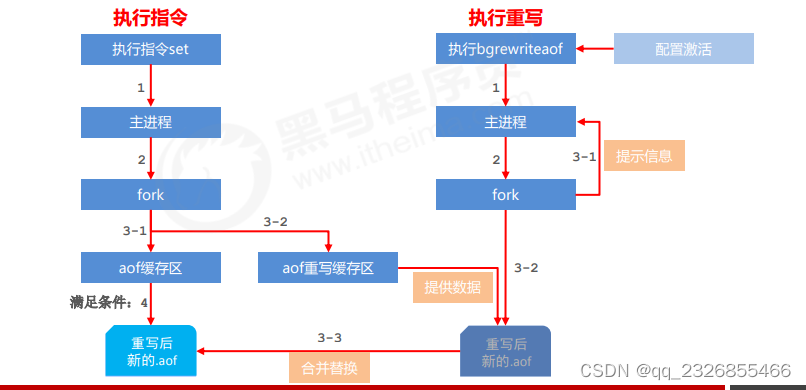
15��RDB��AOF����
16��RDB��AOF��ѡ��֮��
�����ݷdz�����,����ʹ��Ĭ�ϵ�AOF�־û�����
? AOF�־û�����ʹ��everysecond,ÿ����fsyncһ�Ρ��ò���redis�Կ��Ա��ֺܺõĴ�������,����������ʱ,��ඪʧ0-1���ڵ����ݡ�
? ע��:����AOF�ļ��洢����ϴ�,�һָ��ٶȽ���
���ݳ��ֽ���Ч��,����ʹ��RDB�־û�����
? ���ݿ������õ�����������ʧ(�ý��ǿ�������ά��Ա�ֹ�ά����),�һָ��ٶȽϿ�,�ε����ݻָ�ͨ������RDB����
? ע��:����RDBʵ�ֽ��յ����ݳ־û���ʹRedis���ĺܵ�,�����ܽ�:
�ۺϱȶ�
? RDB��AOF��ѡ��ʵ����������һ��Ȩ��,ÿ�ֶ������б�
? �粻�ܳ������������ڵ����ݶ�ʧ,��ҵ�����ݷdz�����,ѡ��AOF
? ���ܳ������������ڵ����ݶ�ʧ,��������ݼ��Ļָ��ٶ�,ѡ��RDB
? ���ѻָ�ѡ��RDB
? ˫���ղ���,ͬʱ���� RDB �� AOF,������,Redis����ʹ�� AOF ���ָ�����,���Ͷ�ʧ���ݵ���
17���־û�Ӧ�ó���
? Tips 1:redis���ڿ������ݿ������id,Ϊ���ݿ�������ṩ���ɲ���,�������ݿ��������Ψһ�� ��Ϊ:��redis�л�ȡ���ܻ����,���ִ���
? Tips 3:redisӦ���ڸ��ֽṹ�ͺͷǽṹ���ȶ����ݷ��ʼ��� ��Ϊ:�������л�ȡ�ʹ�Redis�л�ȡû����
? Tips 4:redis Ӧ���ڹ��ﳵ���ݴ洢��� ��Ϊ:redis�е����ݺ����ݿ��е�һ��
? Tips 5:redis Ӧ��������,���ࡢ���������Żݾ����������ҵ������ݴ洢��� ��Ϊ:���ܳ��ֶϵ������,����Щ ���ٴ洢������ʧ��������
? Tips 6:redis Ӧ���ھ��в����Ⱥ�˳������ݿ��� ��Ϊ:��Щ���ݿ��������ݿ���û�д洢��
? Tips 7:redis Ӧ����������Ϣչʾ
? Tips 9:redis Ӧ����ͬ����Ϣ�Ĺ�������,���ȹ�������,��ȹ�������
? Tips 12:redis Ӧ���ڻ��ں�������������趨�ķ������ �������������ʱ�ԵľͿ��Կ�����
? Tips 13:redis Ӧ���ڼ�������������ܶ�Ӧ������
? Tips 15:redis Ӧ���ڼ�ʱ����/��Ϣ����ִ�й��� �и��õĽ������
? Tips 16:redis Ӧ���ڰ��ν���ķ������
�ġ�����
(һ)ʲô������
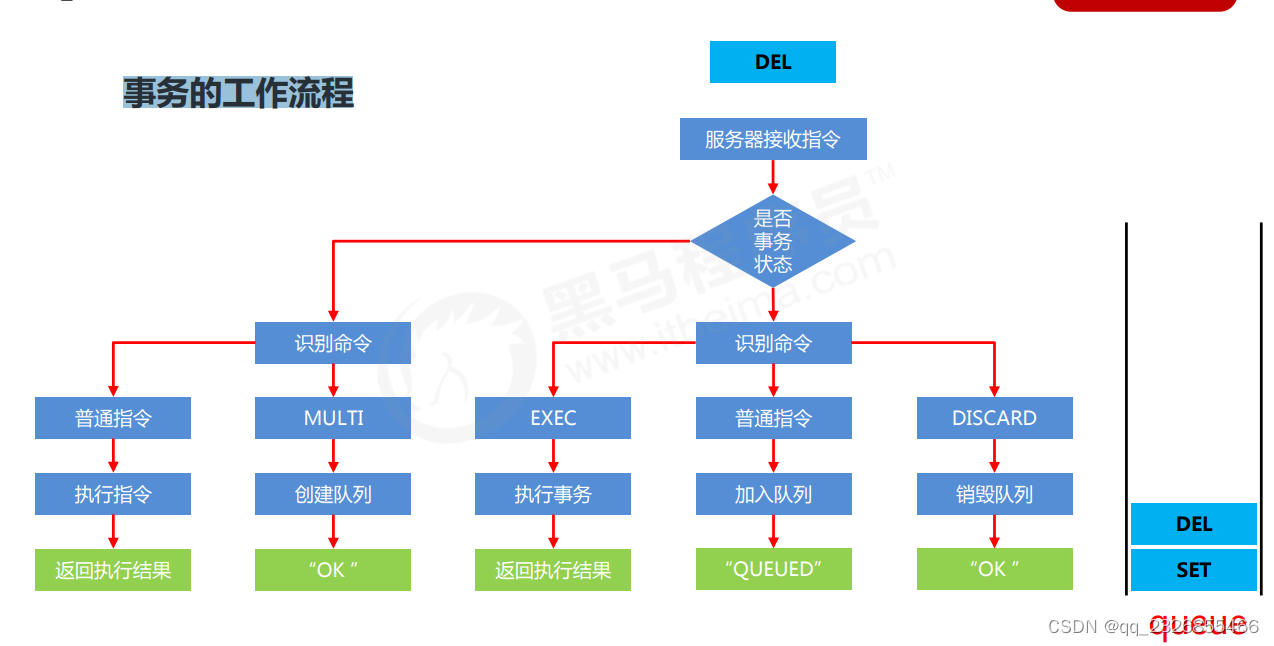
Redisִ��ָ�������,��������ִ�е�ָ�����,���,���?
redis�������һ������ִ�еĶ���,��һϵ��Ԥ���������װ��һ������(һ������)����ִ��ʱ,һ����,��������˳������ִ��,�м䲻�ᱻ��ϻ��߸��š�
һ��������,һ���ԡ�˳���ԡ������Ե�ִ��һϵ������
(��)����Ļ�������
? ��������:multi
? ����:�趨����Ŀ���λ��,��ָ��ִ�к�,����������ָ������뵽������
? ִ������:exec
? ����:�趨����Ľ���λ��,ͬʱִ��������multi�ɶԳ���,�ɶ�ʹ��
? ȡ������:discard
? ����:��ֹ��ǰ����Ķ���,������multi֮��,exec֮ǰ (������������з��ֳ�������ʱ��)
ע��:���������������ʱ���뵽���������,��û������ִ��,ֻ��ִ��exec����ſ�ʼִ��
(��)�����������
(��)�����ע������
1����������Ĺ�����,�����ʽ���������ô��
? �����:ָ������д��ʽ����
? �������:����������������������������������,�����������������������ִ�С�������Щ���ȷ�����
2����������Ĺ�����,����ִ�г��ִ�����ô��?
? ���д���:ָ�����ʽ��ȷ,��������ȷ��ִ�С������list����incr����
? �������:�ܹ���ȷ���е������ִ��,���д��������ᱻִ��
ע��:�Ѿ�ִ����ϵ������Ӧ�����ݲ����Զ��ع�,��Ҫ����Ա�Լ��ڴ�����ʵ�ֻع���
(��)�ֶ���������ع�
? ��¼ ���������б�Ӱ�������֮ǰ��״̬
������:string
������:hash��list��set��zset
? ����ָ��ָ����еı��ĵ���
������:ֱ��set(ע���ܱ�����,����ʱЧ)
������:�Ķ�Ӧֵ�������¡����
(��)�����ض�����������ִ�С���
ҵ��1
��è˫11����������,���Ѿ������Ļ����Ӳ���,4��ҵ��Ա����Ȩ���в����������IJ���������һϵ�еIJ���,ǣ���������������,��α��ϲ����ظ�����?
ҵ�����
? ����ͻ����п���ͬʱ����ͬһ������,���Ҹ�����һ���������ĺ�,���������ڼ�������
? �ڲ���֮ǰ����Ҫ����������,һ�������仯,��ֹ��ǰ����
�������
? �� key ���Ӽ�����,��ִ��execǰ���key�����˱仯,��ֹ����ִ��:watch key1 [key2����]
? ȡ�������� key �ļ���:unwatch
Tips 18:
? redis Ӧ�û���״̬���Ƶ���������ִ��
(��)�����ض�����������ִ�С��ֲ�ʽ��
ҵ��
��è˫11����������,���Ѿ������Ļ����Ӳ���,�Ҳ�����ɡ��ͻ������������,3���ڽ�������Ʒ������ϡ����β����Ѿ������ȫ�����,��α������һ����Ʒ��������ͬʱ����?���������⡿
ҵ�����
? ʹ��watch���һ��key��û�иı��Ѿ����ܽ������,�˴�Ҫ��ص��Ǿ�������
? ��Ȼredis�ǵ��̵߳�,���Ƕ���ͻ��˶�ͬһ����ͬʱ���в���ʱ,��α��ⲻ��ͬʱ��?
�������
? ʹ�� setnx ����һ��������:setnx lock-key value
��:���keyΪname ������Ϊsetnx lock-name 1/-1/true valueֵ�����������
����setnx����ķ���ֵ����,��ֵ������ʧ��,��ֵ�����óɹ�
? ���ڷ������óɹ���,ӵ�п���Ȩ,������һ���ľ���ҵ�����
? ���ڷ�������ʧ�ܵ�,�����п���Ȩ,�Ŷӻ�ȴ�
�������ͨ��del�����ͷ���,���˲��ܷ���
ע��:�������������һ����Ƹ���,�����淶����,���з�����
Tips 19:
? redis Ӧ�û��ڷֲ�ʽ����Ӧ�ij�������
(��)�����ض�����������ִ�С����ֲ�ʽ������
ҵ��
�����ֲ�ʽ���Ļ���,ij���û�����ʱ��Ӧ�ͻ���崻�,�Ҵ�ʱ�Ѿ���ȡ��������ν��?
ҵ�����
? �������������û����Ƽ�������,�ض�����ڼ�����δ�����ķ���
? ��Ҫ�����������ܽ������û�����,ϵͳ����Ҫ������Ӧ�ı��״�������
�������
? ʹ�� expire Ϊ��key����ʱ����,��ʱ���ͷ�,������
expire lock-key second
pexpire lock-key milliseconds
���ڲ���ͨ�����������뼶,��˸�����ʱ�䲻�����ù�����ʱ����Ҫҵ����Ժ�ȷ�ϡ�
? ����:�������IJ����ִ��ʱ��127ms,���ִ��ʱ��7ms��
? ��������ִ��ʱ���Ӧ���������ʱ,������������ӳ�ƽ����ʱ
? ��ʱ���趨�Ƽ�:����ʱ120%+ƽ�������ӳ�110%
? ���ҵ������ʱ<<����ƽ���ӳ�,ͨ��Ϊ2��������,ȡ���е�����ʱ�ϳ�����
����ָ��
�鿴redis����:ps -ef | grep redis-
ɱ������:kill -s 9 �˿ں�
����redis����:redis-server conf/redisxxxx.conf
ɾ���ļ�:rm -rf �ļ���
�鿴�ļ�����:cat �ļ���
�鿴redis��������������ֵ:info