前言
#博学谷IT学习技术支持#
想要了解Hadoop相关框架,首先就是搭建Hadoop集群,然后再学习Hadoop相关知识,边学习边实操,可以大大提高学习的效率。
一、Hadoop概述
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
Hadoop的核心组件有:
(1) HDFS 分布式文件存储系统,解决海量数据存储
(2)YARN 作业调度和集群资源管理的框架,解决资源任务调度
(3)MapReduce分布式运算编程框架,解决海量数据计算
二、Hadoop特性优点
(1)扩容能力强,Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
(2)成本低,Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
(3)高效,通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
(4)可靠性强,能自动维护数据的多份复制,并且在任务失败后能自动地重新部署计算任务。
三、Hadoop集群搭建
(一)集群简介
Hadoop集群主要包含两个集群:HDFS集群和Yarn集群,两者逻辑上分离,但物理上常在一起。
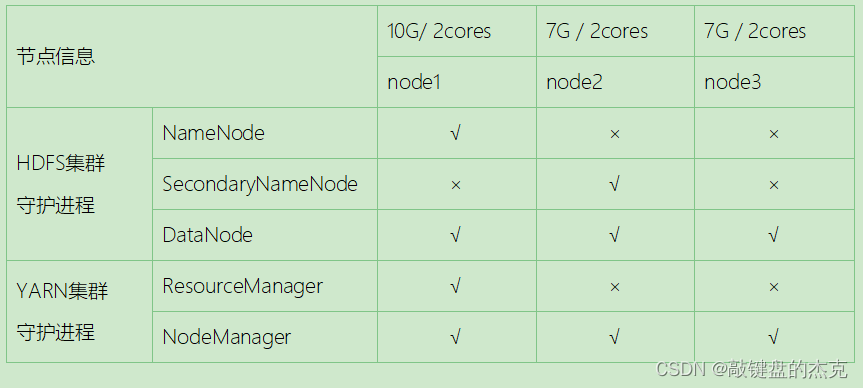
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
Yarn集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
Hadoop中的MapReduce其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到Yarn集群的资源调度管理。
(二)集群规划
本次主要搭建的是集群模式,集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问,我们在之前搭建好基础环境的三台虚拟机上进行Hadoop的搭建,以下是集群规划:
(三)解压Hadoop安装包
上传解压hadoop 3.1.4安装文件
cd /export/software
rz
--------------------------------
解压
tar -zxvf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /export/server/
# 在每个节点中创建用于存放数据的data目录
mkdir -p /export/server/hadoop-3.1.4/data
(四)编辑配置文件
- 配置NameNode(core-site.xml)
cd /export/server/hadoop-3.1.4/etc/hadoop
vim core-site.xml
--------------------------------
在第19行下添加以下内容:
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-3.1.4/data</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 配置HDFS路径(hdfs-site.xml)
vim hdfs-site.xml
在第20行下添加以下内容:
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
- 配置Yarn(yarn-site.xml)
vim yarn-site.xml
--------------------------------
在第18行下添加以下内容:
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
- 配置MapReduce(mapred-site.xml)
vim mapred-site.xml
----------------------------------
在第20行下添加以下内容:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property> <property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 修改workers文件
vim /export/server/hadoop-3.1.4/etc/hadoop/workers
----------------------------------
# 删除第一行localhost,然后添加以下三行
node1
node2
node3
- 修改hadoop.env环境变量
hadoop.env文件
vim /export/server/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
----------------------------------
修改第54行为:
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 配置环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
- 由于Hadoop集群中设置了三台主机,而以上只在一台主机上配置,所以需要将以上Hadoop安装文件和环境变量分发到其他两台主机上
在node1节点上执行:
cd /export/server/
scp -r hadoop-3.1.4 node2:$PWD
scp -r hadoop-3.1.4 node3:$PWD
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc
在每个节点上执行
source /etc/profile
- 格式化HDFS
首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。只需要在node1上进行格式化,只能格式化一次
cd /export/server/hadoop-3.1.4
bin/hdfs namenode -format
- 一键启动HDFS集群和Yarn集群
-- 一键启动HDFS、YARN
start-all.sh
-- 一键关闭HDFS、YARN
stop-all.sh
- 配置windows域名映射
(1)以管理员身份打开C:\Windows\System32\drivers\etc目录下的hosts文件
(2)在文件最后添加以下映射域名和ip映射关系,然后保存文件并退出
192.168.88.161 node1
192.168.88.162 node2
192.168.88.163 node3
- 访问WebUI
NameNode: http://node1:9870
Yarn: http://node1:8088
总结
本次Hadoop集群主要用到三台Linux的主机,并且按照以上流程搭建好Hadoop集群;使用Shell命令即可一键开启Hadoop集群,开启集群后便可在浏览器上输入相关地址访问对应集群。