1.����
1.1��ͳ����
- Kafka��һ���ֲ�ʽ�Ļ��ڷ�������ģʽ����Ϣ����,��ҪӦ���ڴ����ݵ�ʵʱ��������
- ��������:��Ϣ�����߲���ֱ�ӽ���Ϣ����������,���ǽ���������Ϣ��Ϊ��ͬ�����,������ֻ���ո���Ȥ����Ϣ
1.2���¶���
- Kafka��һ����Դ�ķֲ�ʽ��ƽ̨,����ǧ�ҹ�˾���ڸ��������ݹܵ��������������ݼ��ɡ��ؼ�����Ӧ��
2.��Ϣ����
2.1������Ϣ����
- Kafka
- ActiveMQ
- RabbitMQ
- RocketMQ
2.2Ӧ�ó���
- Kafka����Ӧ���ڴ����ݳ���
- ActiveMQ��RabbitMQ��RocketMQ��Ӧ����web��������������
2.3����
- ����
- ��������
- ����
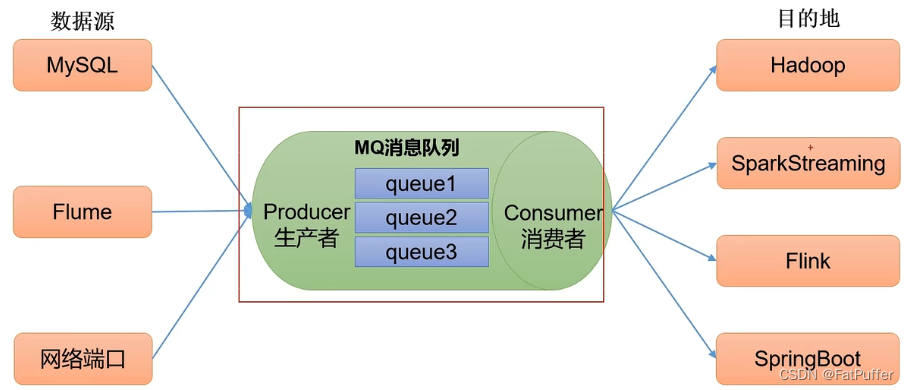
- �첽ͨ��
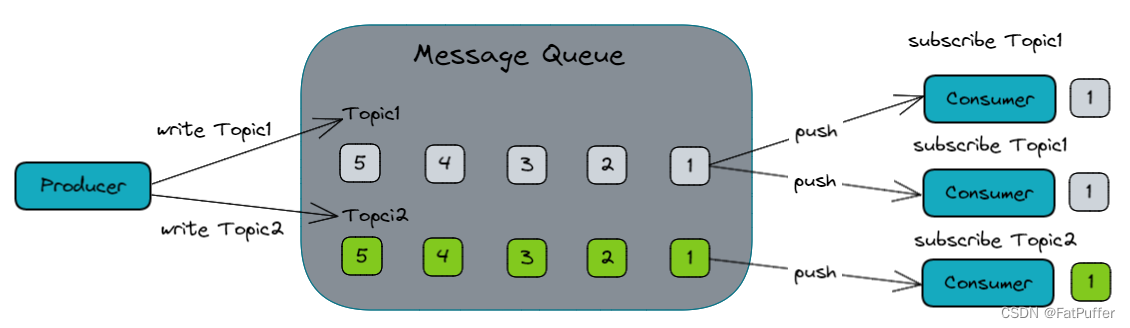
3.Kafkaģʽ
3.1ģʽͼ��
-
��Ե�ģʽ
- ������
������ȡ����,�����յ����������

- ������
-
����/����ģʽ
- ������Topic����
- �������������ݺ�,��ɾ������
- ÿ������������������������ѵ�����
3.2����ģʽ������ȱ��
3.2.1��ģʽ
- �ŵ�
- 1.��Ϣʵʱ�Ը�, Broker ��������Ϣ֮������������� Consumer��
- 2.����������ʹ����˵����,ֻ��Ҫ����,��������Ϣ���˾ͻ��ƹ�����
- ȱ��
- 1.
��������������Ӧ��������,��ģʽ��Ŀ������������ٶ�������Ϣ,
���������� Broker ������Ϣ�����ʴ���������������Ϣ������ʱ,
����ʱ��������������DZ߿��ܾ͡����֡���,��Ϊ�������Ѳ���������
���������ʹ������ DDos ����һ�������߾�ɵ�ˡ� - 2.����
��ͬ�������ߵ��������ʻ���һ��,��Ϊ Broker ����ƽ��ÿ��������
����������,���Ҫʵ������Ӧ�����������Ǿ���Ҫ�����͵�ʱ�������߸���
Broker ,�Ҳ��������������,Ȼ�� Broker ��Ҫά��ÿ�������ߵ�״̬����
�������ʵı��������ʵ�������� Broker �����ĸ��Ӷȡ�
- 1.
- ����
��������Ϣ��������������ǿҪ��ʵʱ�Ըߵ������
3.2.2��ģʽ
-
�ŵ�
- 1.
�����߿��Ը��������������������ȡ��Ϣ�����������赱ǰ�����߾����Լ����Ѳ�������,�����Ը���һ���IJ���ֹͣ��ȡ,�������ȡ���С� - 2.��ģʽ��
Broker �����������,��ֻ�ܴ������߷�������Ϣ,�������ѵ�ʱ����Ȼ����������������,��һ�����������Ϣ��,���Ŀ�ʼ����Ϣ,�ö��������߶�������,������һ��û�и���Ĺ�����,������Ҫ��û��ȡҲ���������¡�
- 1.
-
ȱ��
- 1.
��Ϣ�ӳ�,�Ͼ���������ȥ��ȡ��Ϣ,������������ô֪����Ϣ������?������ֻ�ܲ��ϵ���ȡ,�����ֲ��ܺ�Ƶ��������,̫Ƶ���˾ͱ���������ڹ��� Broker �ˡ������Ҫ���������Ƶ��,������� 2 ������һ��,�㿴����Ϣ�ͺ��п����ӳ� 2 ���ˡ� - 2.
��Ϣæ����,æ������DZ�����Ϣ���˼���Сʱ����,��ô�ڼ���Сʱ֮�������ߵ���������Ч��,�������ù��� - 3.
�����ѹ�����,��ʱ�������ٶȸ����������ٶ�,�ͻ�ʹ��Broker�洢����ϢԽ��Խ��,��������¿��ܵ��·������ڴ汬��
- 1.
-
����
- ��ģʽ����
�����ʵĽ�����Ϣ����������,������ģʽ������һ����Ϣ������,Ҳ���Ի���һЩ��Ϣ֮��������,�������͵�ʱ����ʵ��֪�������ߵ����ܲ���һ���Դ�����ô����Ϣ������ģʽ���Ӻ���,�����Բο��������������Ϣ���������������Ϣ֮���������͡�
- ��ģʽ����
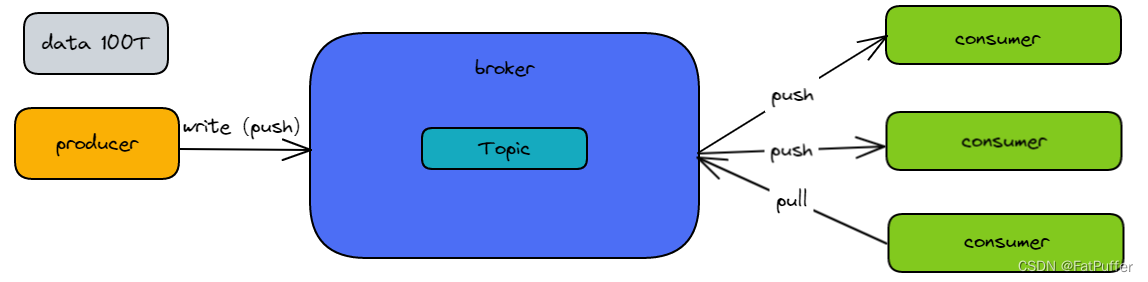
4.�ܹ�
4.1�����ܹ�
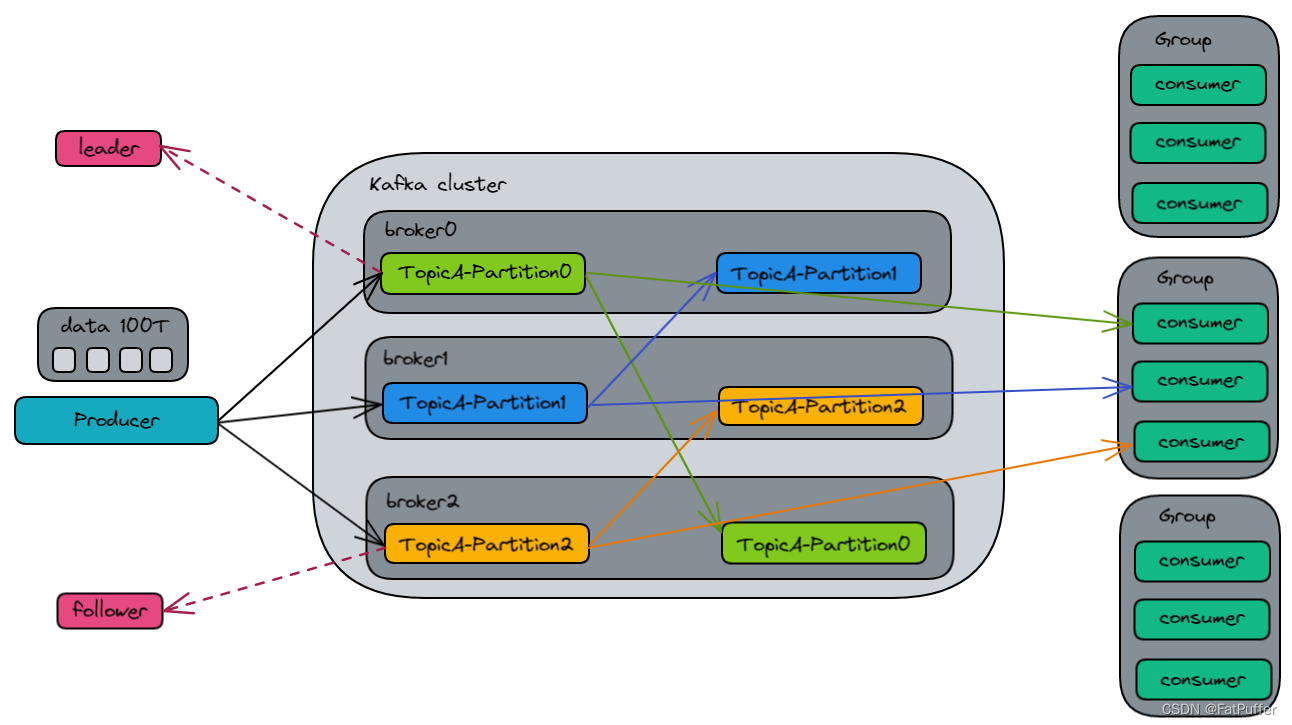
4.2�����ܹ�
- Ϊ������չ,���������,һ��topic��Ϊ���partition
- ��Ϸ������,�����������ĸ���,����ÿ�������߲�������
һ������������,ֻ�������������ڵ�һ������������,�����ظ������������û�ж������߷���,��ôһ�����������ݿ��Ա��������������
- Ϊ��߿�����,Ϊÿ��partition�������ɸ���,����NameNode HA
������ֻ�ܴ���partition��������,����partition�ҵ���,��partition�ɳ�Ϊ��partition
- Zookeeper(Kafka2.8.0֮ǰ����ʹ��Zookeeper,2.8.0֮���ѡkarft)
- ��¼��Ⱥ����Щbroker������������
- ��¼�ĸ�partition����
5.���ذ�װ
5.1����
-
������ַ:https://kafka.apache.org/downloads
wget https://archive.apache.org/dist/kafka/3.0.0/kafka_2.12-3.0.0.tgz -P /opt/software -
��ѹ
tar -zxvf /opt/software/kafka_2.12-3.0.0.tgz -C /opt/moudle -
������
mv /opt/moudle/kafka_2.12-3.0.0 /opt/moudle/kafka
5.2������
- ��
server.properties
# ��Ⱥ��ÿ��broker�����ݱ�ʶ,������Ⱥ�в��ܴ����ظ���id
broker.id=0
# ���ݴ洢Ŀ¼,���鲻Ҫʹ��/tmp��ʱ·��
# log.dirs=/tmp/kafka-logs
log.dirs=/opt/moudle/kafka/datas
# ���ӵ�zookeeper��Ⱥ
# /kafkaΪ�˷����������
# zookeeper.connect=localhost:2181
zookeeper.connect=first-node:2181,second-node:2181,third-node:2181/kafka
5.3��Ⱥ�ַ�
-
�ַ�kafka������
xsync /opt/moudle/kafka -
�ļ�Ⱥ�����������ļ���
broker.idssh second-node "sed -i.bak s/broker.id=0/broker.id=1/ /opt/moudle/kafka/config/server.properties" ssh third-node "sed -i.bak s/broker.id=0/broker.id=2/ /opt/moudle/kafka/config/server.properties" -
����kafka��������:
sudo vim /etc/profile.d/my_env.sh# KAFKA_HOME export KAFKA_HOME=/opt/moudle/kafka export PATH=$PATH:$KAFKA_HOME/bin -
���¼��ػ�������
source /etc/profile -
�������������ļ��ַ�
- ���
root�û�δ����ssh���ܵ�¼,�˴���Ҫ��������
sudo /home/fatpuffer/bin/xsync /etc/profile.d/my_env.sh - ���
-
��¼��Ⱥ���������ڵ����¼��ػ�������
source /etc/profile
5.4����kafka
5.4.1������Ҫ����ZK��Ⱥ
zk.sh start
5.4.2����Kafka
kafka-server-start.sh -daemon /opt/moudle/kafka/config/server.properties
5.4.3ֹͣKafka
kafka-server-stop.sh
6.Kafka��Ⱥ
6.1����ֹͣ�ű�
-
1.�û�binĿ¼�´���kfk.sh�ļ�:
vim /home/fatpuffer/bin/kfk.sh#! /bin/bash case $1 in "start"){ for node in first-node second-node third-node do echo ----------------------kafka $node start-------------------- ssh $node "kafka-server-start.sh -daemon /opt/moudle/kafka/config/server.properties" done };; "stop"){ for node in first-node second-node third-node do echo ----------------------kafka $node stop-------------------- ssh $node "kafka-server-stop.sh" done };; esac -
2.�Ľű�Ȩ��
comod +x kfk.sh -
3.�ű�ʹ��
kfk.sh start kfk.sh stop
6.2ע������
- ����Kafkaǰһ��Ҫȷ��ZK��Ⱥ�Ѿ������ɹ�
- ����ȴ�Kafka��ȫֹͣ,�ſ���ֹͣZoopeeper,����ᵼ��Kafka��ֹͣ
6.3Kafka��ZK��Ⱥ�еĽڵ�
-
�鿴�ڵ�
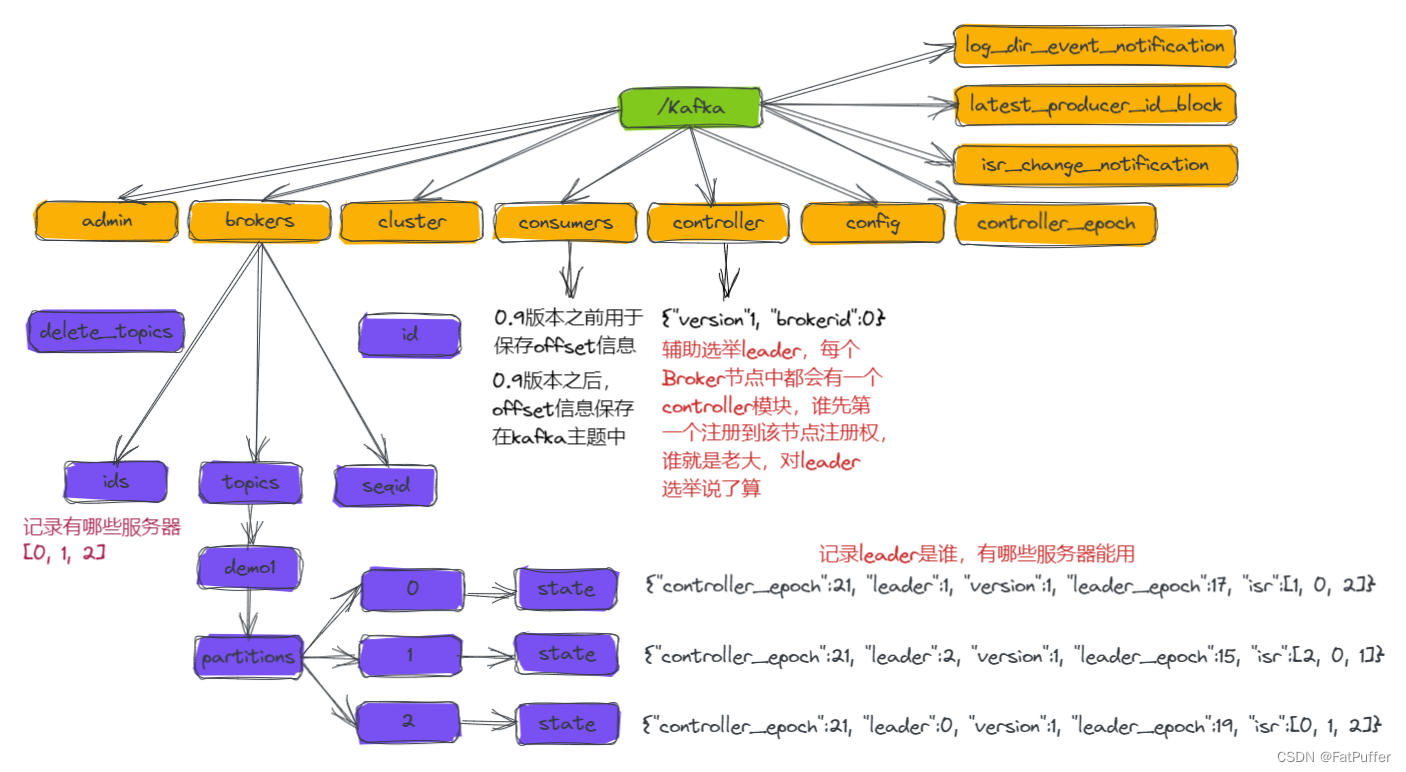
/kafka��Ϣ[zk: localhost:2181(CONNECTED) 1] ls /kafka [admin, brokers, cluster, config, consumers, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification] -
�鿴�ڵ�
/kafka/brokers[zk: localhost:2181(CONNECTED) 16] ls /kafka/brokers [ids, seqid, topics] -
�鿴�ڵ�
/kafka/brokers/ids[zk: localhost:2181(CONNECTED) 11] ls /kafka/brokers/ids [0, 1, 2] -
�鿴�ڵ�
/kafka/brokers/topics[zk: localhost:2181(CONNECTED) 17] ls /kafka/brokers/topics [] -
��ȡ
/kafka/brokers/ids/0������[zk: localhost:2181(CONNECTED) 13] get /kafka/brokers/ids/0 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://first-node:9092"],"jmx_port":-1,"features":{},"host":"first-node","timestamp":"1670480025960","port":9092,"version":5} [zk: localhost:2181(CONNECTED) 14] get /kafka/brokers/ids/1 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://second-node:9092"],"jmx_port":-1,"features":{},"host":"second-node","timestamp":"1670480032519","port":9092,"version":5} [zk: localhost:2181(CONNECTED) 15] get /kafka/brokers/ids/2 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://third-node:9092"],"jmx_port":-1,"features":{},"host":"third-node","timestamp":"1670480038549","port":9092,"version":5}
7.Kafka�����������
7.1�ű�ͼ��

7.2�����������
-
�������
���� ���� �Cbootstrap-server <String: server connect to> ���ӵ� Kafka Broker�������ƺͶ˿� �Ctopic <String: topic> ������Topic���� �Ccreate �������� �Cdelete ɾ������ �Calter ������ �Clist �鿴�������� �Cdescribe �鿴������ϸ���� �Cpartitions <Integer: # of partitions> ���÷����� �Creplication-factor <Integer: replication factor> ���÷������� �Cconfig <String: name=value> ����ϵͳĬ�ϵ����� �Cproducer-property ���Զ������Դ��ݸ��������Ļ���,����:key=value �Cproducer.config ���������������ļ� [�Cproducer-property] �����ڴ����� �Cproperty �Զ�����Ϣ��ȡ��:parse.key=true|false
key.separator=<key.separator>
ignore.error=true�Crequest-required-acks �����������ȷ�Ϸ�ʽ:0��1(Ĭ��ֵ)��all �Csync ͬ��������Ϣ -
�鿴��ǰ�������е�����topic
kafka-topics.sh --bootstrap-server first-node:9092 --list # ���Ӷ���ڵ� # kafka-topics.sh --bootstrap-server first-node:9092,second-node:9092,third-node:9092 --list -
����һ����Ϊ
demo1������,���÷�����Ϊ1,��������Ϊ3kafka-topics.sh --bootstrap-server first-node:9092 --topic demo1 --create --partitions 1 --replication-factor 3[zk: localhost:2181(CONNECTED) 22] ls /kafka/brokers/topics [demo1] [zk: localhost:2181(CONNECTED) 23] ls /kafka/brokers/topics/demo1 [partitions] [zk: localhost:2181(CONNECTED) 24] ls /kafka/brokers/topics/demo1/partitions [0] [zk: localhost:2181(CONNECTED) 25] ls /kafka/brokers/topics/demo1/partitions/0 [state] [zk: localhost:2181(CONNECTED) 26] ls /kafka/brokers/topics/demo1/partitions/0/state [] [zk: localhost:2181(CONNECTED) 27] get /kafka/brokers/topics/demo1 {"removing_replicas":{},"partitions":{"0":[2,1,0]},"topic_id":"D6Lse1d5TduQCu0mh-idwQ","adding_replicas":{},"version":3} [zk: localhost:2181(CONNECTED) 28] get /kafka/brokers/topics/demo1/partitions/0/state {"controller_epoch":5,"leader":2,"version":1,"leader_epoch":0,"isr":[2,1,0]} -
�鿴
demo1��������kafka-topics.sh --bootstrap-server first-node:9092 --describe demo1 # ������ # ���������� # ������С Topic: demo1 TopicId: D6Lse1d5TduQCu0mh-idwQ PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824 # ������ʼλ�� # �����е�leader��Ӧ��broker # ����������Ӧ��broker(�����������ֱ�洢��broker.id=2��broker.id=1��broker.id=0) Topic: demo1 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0- �����ߺ�������ֻ�����leader�ڵ���в���
-
������
demo1������Ϊ3kafka-topics.sh --bootstrap-server first-node:9092 --topic demo1 --alter --partitions 3- ע��:������ֻ������,���ܼ���
[zk: localhost:2181(CONNECTED) 34] ls /kafka/brokers/topics [demo1] [zk: localhost:2181(CONNECTED) 35] ls /kafka/brokers/topics/demo1 [partitions] [zk: localhost:2181(CONNECTED) 36] ls /kafka/brokers/topics/demo1/partitions [0, 1, 2] [zk: localhost:2181(CONNECTED) 37] ls /kafka/brokers/topics/demo1/partitions/1 [state] [zk: localhost:2181(CONNECTED) 38] ls /kafka/brokers/topics/demo1/partitions/1/state [] [zk: localhost:2181(CONNECTED) 39] get /kafka/brokers/topics/demo1 {"removing_replicas":{},"partitions":{"2":[1,2,0],"1":[0,1,2],"0":[2,1,0]},"topic_id":"D6Lse1d5TduQCu0mh-idwQ","adding_replicas":{},"version":3} [zk: localhost:2181(CONNECTED) 40] get /kafka/brokers/topics/demo1/partitions/0/state # 0�ŷ���leaderΪbroker2 {"controller_epoch":5,"leader":2,"version":1,"leader_epoch":0,"isr":[2,1,0]} [zk: localhost:2181(CONNECTED) 41] get /kafka/brokers/topics/demo1/partitions/1/state # 1�ŷ���leaderΪbroker0 {"controller_epoch":5,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1,2]} [zk: localhost:2181(CONNECTED) 55] get /kafka/brokers/topics/demo1/partitions/2/state # 2�ŷ���leaderΪbroker1 {"controller_epoch":5,"leader":1,"version":1,"leader_epoch":0,"isr":[1,2,0]}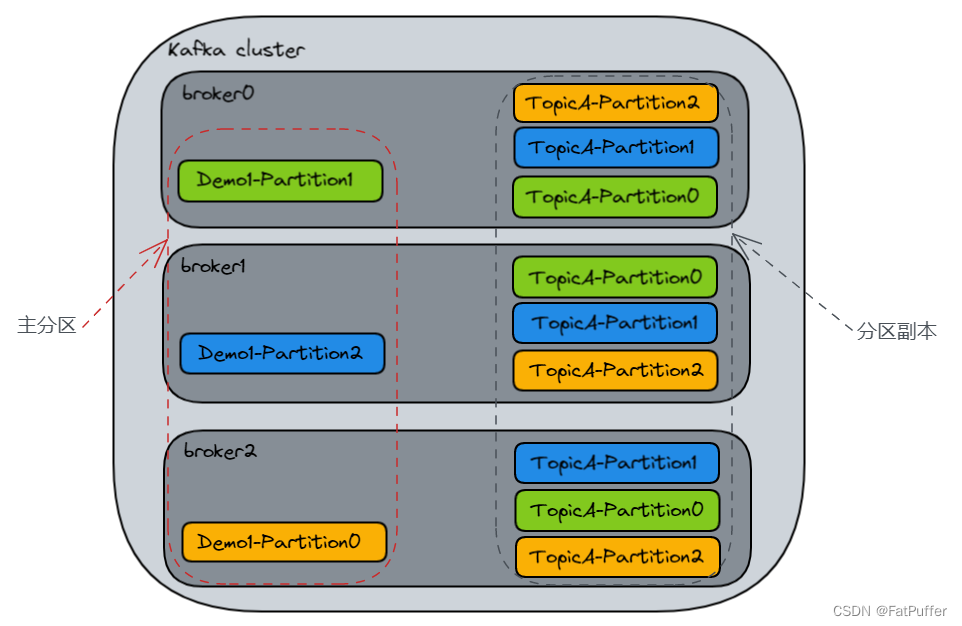
[fatpuffer@first-node ~]$ kafka-topics.sh --bootstrap-server first-node:9092 --describe demo1 Topic: demo1 TopicId: D6Lse1d5TduQCu0mh-idwQ PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: demo1 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 Topic: demo1 Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: demo1 Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 -
��������broker�е�
demo1���ⷢ��һ����Ϣkafka-console-producer.sh --bootstrap-server first-node:9092 --topic demo1 -
����������broker,���Ҽ���
deno1����,broker��ص�demo1����������Ϣ����,����Ϣ��������demo1����ļ�����kafka-console-consumer.sh --bootstrap-server first-node:9092 --topic demo1 # --from-beginning���Ի�ȡ��ʷ���� kafka-console-consumer.sh --bootstrap-server first-node:9092 --topic demo1 --from-beginning
-
���ʹ�
key����Ϣkafka-console-producer.sh --bootstrap-server first-node:9092 --topic demo1 --producer-property parse.key=true- ��ֵ֮��ʹ��
tab���ָ�
- ��ֵ֮��ʹ��
8.������(producer)
8.1����ԭ��
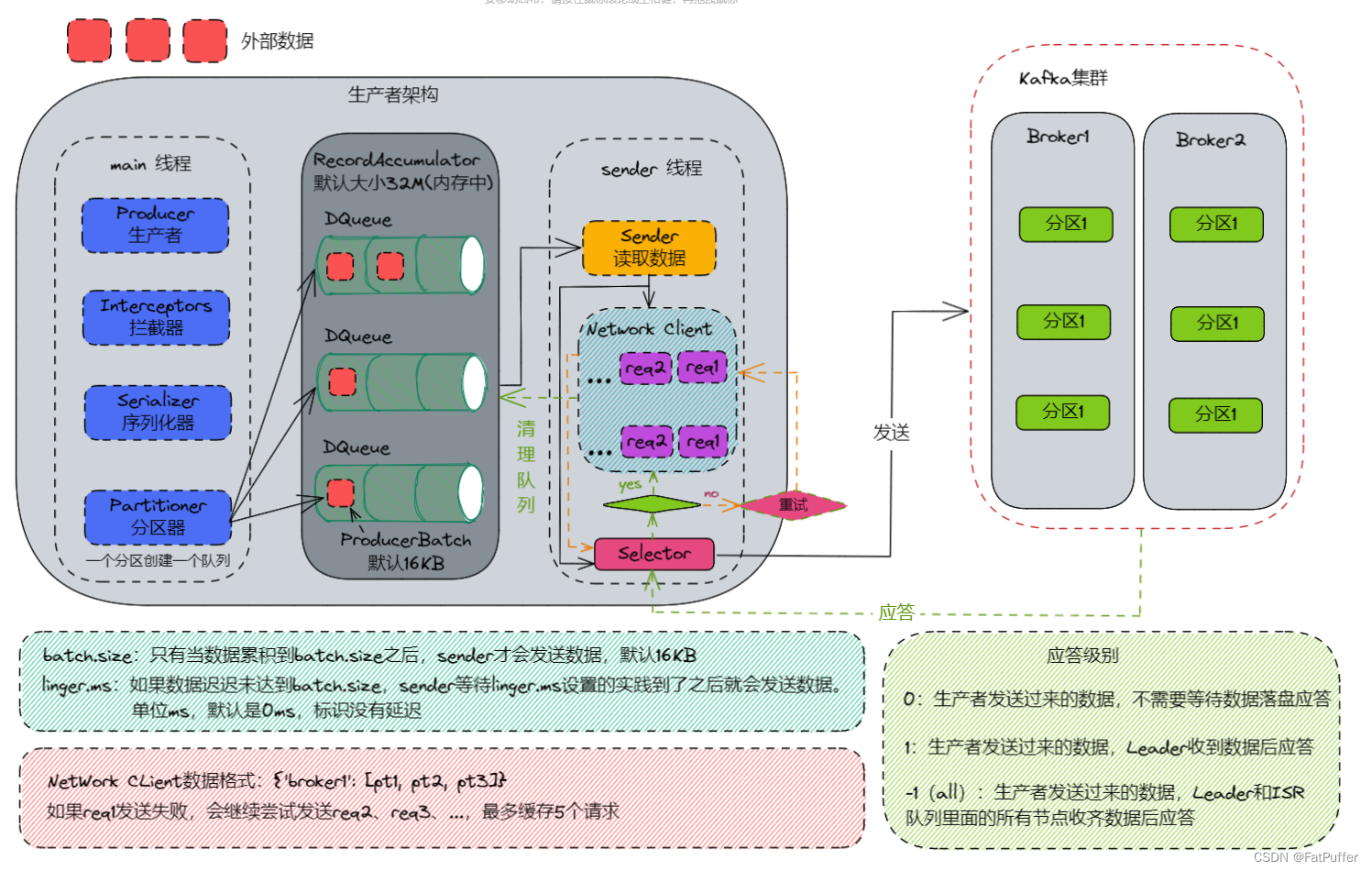
����Ϣ��������,�漰���������߳�,main�߳���sender�̡߳���main�߳��д�����һ��˫�˶���:RecordAccumulator��main�߳̽���Ϣ����:RecordAccumulator,sender�̲߳��ϴ�:RecordAccumulator����ȡ��Ϣ���͵�:Kafka Broker
8.2API��������
-
�������ö���
-
�����ö���д��kafka��Ⱥ������Ϣ
-
�����ö���д�����л���Ϣ
-
�������ö���,���������߶���
-
ʹ�������߶���������
-
�ر������߶���
kafka-python:https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
8.3�����߷���
8.3.1�����ô�
���ں���ʹ�ô洢��Դ,ÿ��Partion��һ��Broker�ϴ洢,���Ѻ��������ݰ��շ����и��һ��һ�����ݴ洢�ڶ�̨Broker�ϡ��������Ʒ���������,����ʵ�����ؾ�����Ч������߲��ж�,�����߿����Է���Ϊ��λ��������;�����߿����Է���Ϊ��λ������������
8.3.2�����߷�����Ϣ�ķ�������
- �ڷ�����Ϣʱ
ָ���˷���,��������Ϣ���͵��÷��� - �ڷ�����Ϣʱ
δָ������,��ָ����key- ��key��hashֵ��topic��partition������ȡ��õ�partitionֵ
- ����:key1��hashֵΪ5,key2��hashֵΪ6,topic��partition��Ϊ2,��ôkey1��Ӧ��value1��д��1�ŷ���,key2��Ӧ��value2д��0�ŷ���
- ��key��hashֵ��topic��partition������ȡ��õ�partitionֵ
- �ڷ�����Ϣʱ
δָ������,Ҳδָ��keyKafka����Sticky Partition(��Է�����),�����ѡ��һ������,��������һֱʹ�ø÷���,�ȴ��÷�����batch.size�����������,Kafka�����һ����������ʹ��(����һ�εķ�����ͬ)- ����:��һ�����ѡ��0�ŷ���,��0�ŷ�����ǰ����(batch.size)�Ѿ�����(Ĭ��16k),����
linger.ms���õ�ʱ�䵽��,Kafka�����ѡ��һ����������ʹ��(�����0,����������) - Java:
hashcode------------------------->Python:ord("a")
- ����:��һ�����ѡ��0�ŷ���,��0�ŷ�����ǰ����(batch.size)�Ѿ�����(Ĭ��16k),����
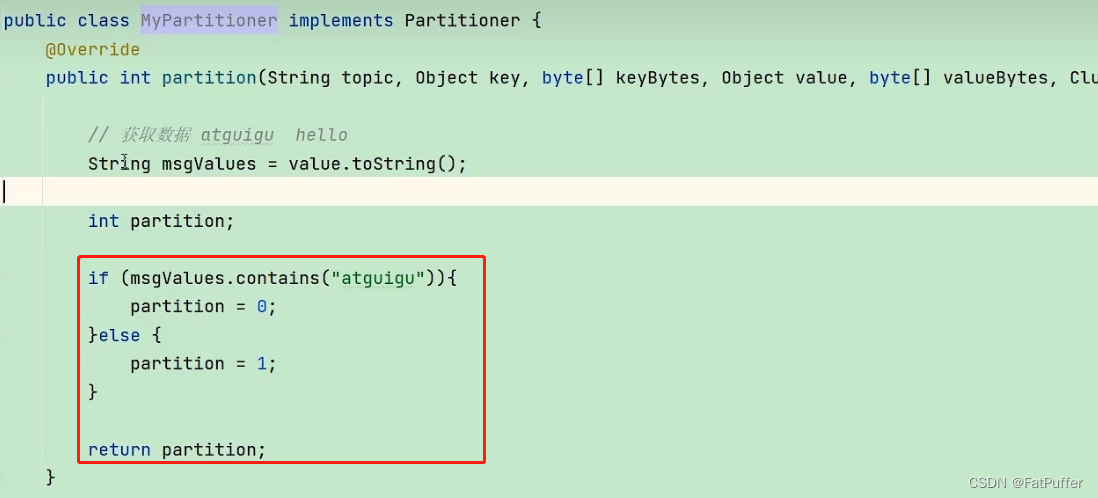
8.3.3�Զ��������
- ���ݷ����������ݽ��й���,����ͬ�������ݷ��͵���ͬ����

8.4���������
- 1.��Ҫ�漰���������ĵ���,��
linger.msʱ��,Խ�ӽ�batch.size:16kb,��Ч��Խ��- 1.
batch.size:������,16��32 - 2.
linger.ms:�ӳ�,5-10ms
- 1.
- 2.����ѹ��
compression.type:ѹ��snappy
- 3.RecordAccumulator:��������С,��Ϊ64M
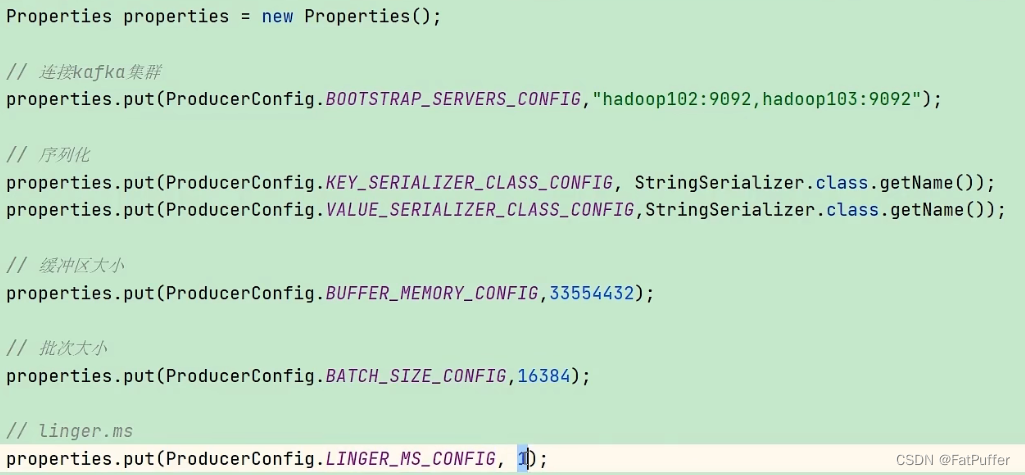

8.5���ݿɿ���
8.5.1�����߷��������ݾͲ�����:ack=0,�ɿ��Բ�,Ч�ʸ�
8.5.2�ɿ����ܽ�
acks=0,�����߷��������ݾͲ�����,�ɿ��Բ�,Ч�ʸ�acks=1,�����߷���������,Leader(����)Ӧ��,�ɿ����е�,Ч���е�acks=-1,�����߷���������,Leader��ISR�������������FollowerӦ��,�ɿ��Ը�,Ч�ʵ�- ����������,
acks=0����ʹ��;acks=1һ��ʹ�ô�����ͨ��־,����������;acks=-1һ�����ں�Ǯ��ص�����,�Կɿ���Ҫ��Ƚϸߵij�����

8.5.2�����ظ�
1.����ԭ��
acks=-1(all):�����߷�����������,Leader��ISR������������нڵ������Ӧ��- �ظ�ԭ�����:��Leader�յ���Ϣ,���Ѿ�������ISR�����е�Followerͬ�����,������Ӧ��������ʱ,Leader����,Kafka����ѡ�ٳ�Leader��������δ�յ�Ӧ��,���ٴη�������,�µ�Leader�õ����ݺ�,����ISR�����е�Follower������ȡһ������,��ʱ���ݾͳ������ظ���
2.���ݴ�������
- ����һ��(At Least Once):ACK��������Ϊ
-1+ �����������ڵ���2+ ISR��Ӧ�����С���������ڵ���2 - ���һ��(At Most Once):ACK��������Ϊ
0
3.�ܽ�
At Least Once:���Ա�֤���ݲ���ʧ,�������ܱ�֤���ݲ��ظ�At Most Once:���Ա�֤���ݲ��ظ�,�������ܱ�֤���ݲ���ʧ
4.��ȷһ��(Exact Once)
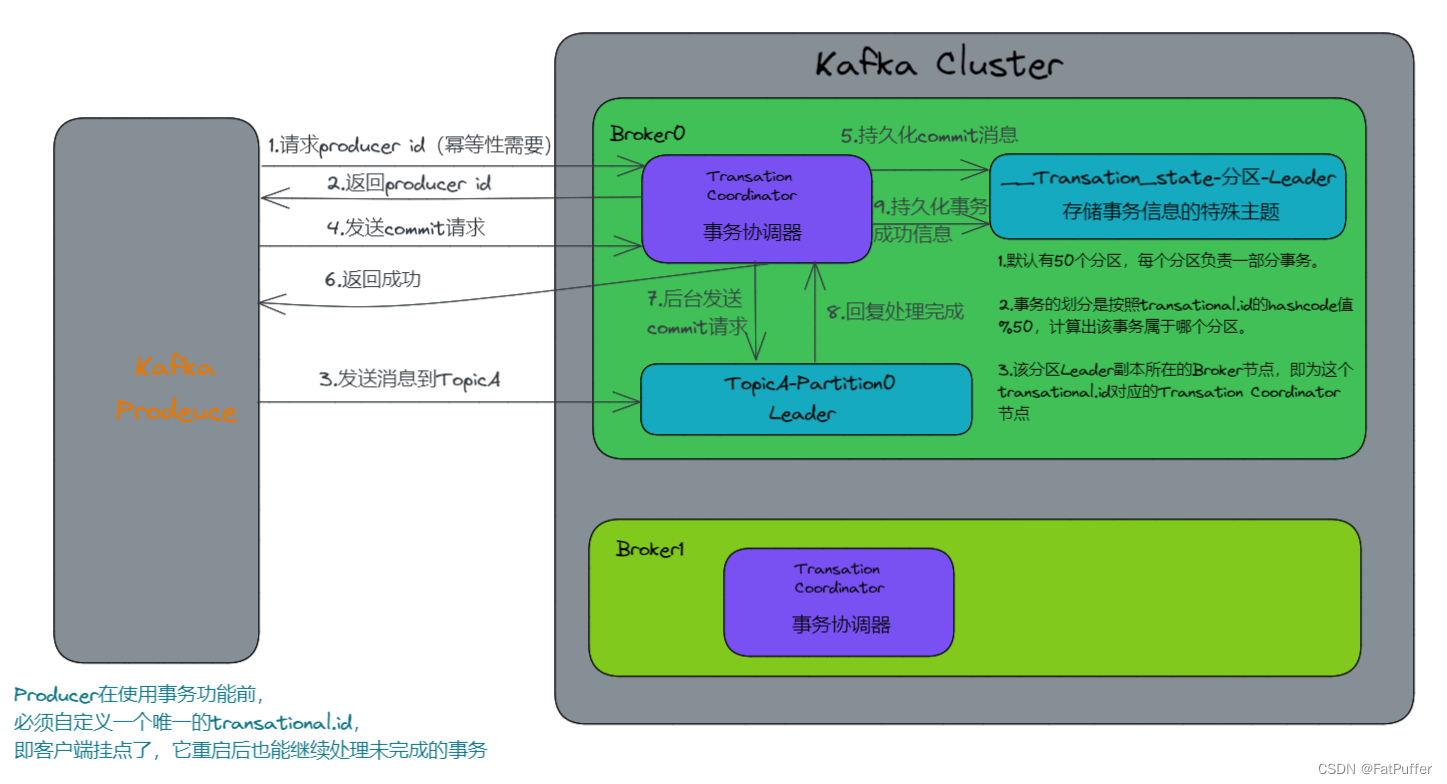
- ����һЩ�dz���Ҫ����Ϣ,�����Ǯ��ص�����,Ҫ������
�Ȳ����ظ�,Ҳ���ܶ�ʧ - Kafka 0.11�汾�Ժ�,������һ���ش�����:
�ݵ��Ժ�����
5.�ݵ���ԭ��
- �ݵ��Ծ���ָ
Producer������Broker���Ͷ��ٴ��ظ�����,Broker�˶�ֻ���־û�һ��,��֤�˲��ظ��� - ��ȷһ��(Exact Once)= �ݵ��� + ����һ��(At Least Once)(
ack = -1 + ���������� >= 2 + ISR�������� >= 2)
6.�ظ��жϵı�
- ����
<PID,Partition,SeqNumber>��ͬ��������Ϣ�ύʱ,Brokerֻ��־û�һ����PID��kafkaÿ�������������һ���µ�;Partition��ʶ������;Sequence Number�ǵ��������ġ�
- �����ݵ���
ֻ�ܱ�֤�����ڵ��������Ự�ڲ��ظ�
7.�����ݵ���
enable.idempotence,Ĭ��Ϊtrue,falseΪ�ر�
8.6����
1.ΪʲôҪʹ������
- �ݵ���ֻ�ܱ�֤�����������Ự�����ݲ��ظ�,һ��kafka�ҵ�,������
PID�ͻ�仯,��ʱ������֤���ݲ��ظ� - ��������ű仯,Ҳ��Ȼ����֤���ݲ��ظ�
2.����ԭ��
��������,���뿪���ݵ���
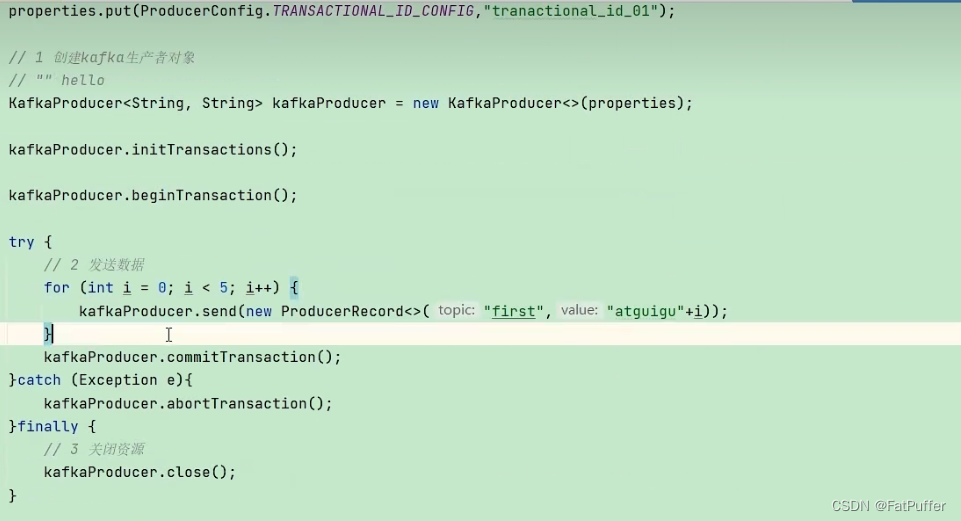
3.API����
8.7.��������
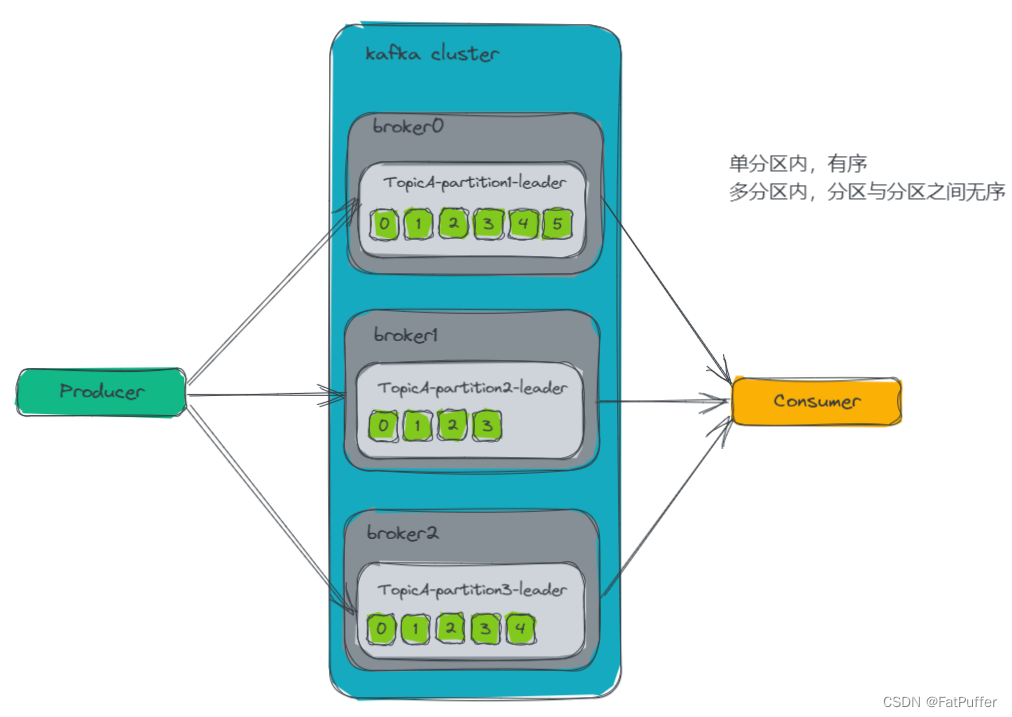
8.8.��������
- kafka��1.x�汾֮ǰ,��֤���ݵ���������,��������:
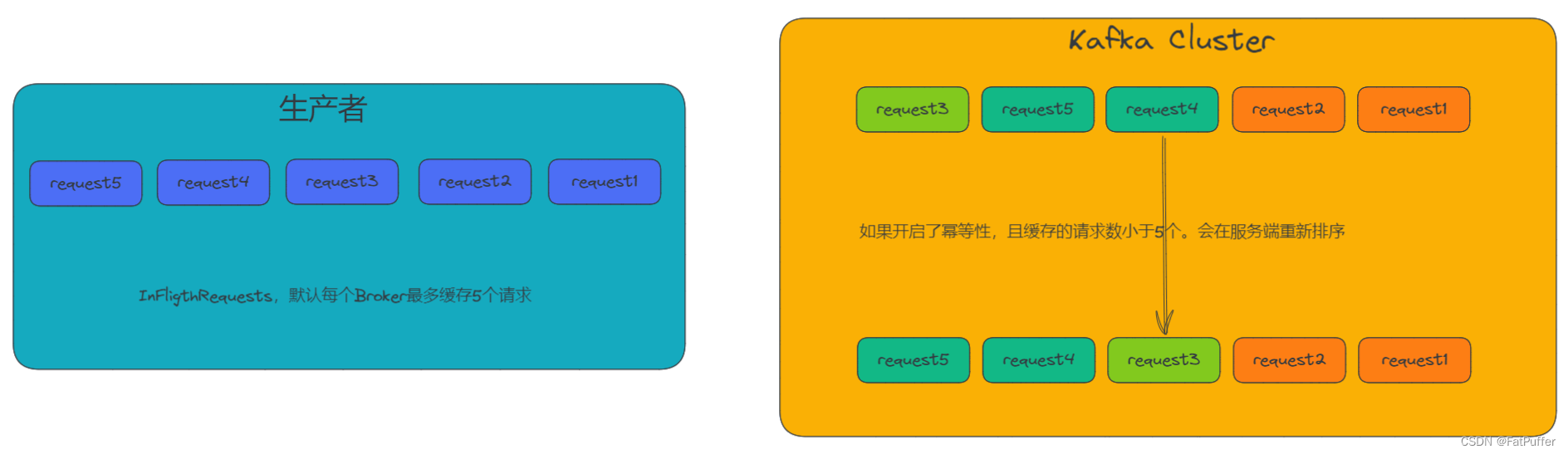
max.in.flight.requests.per.connection=1(����Ҫ�����Ƿ����ݵ���)
- kafka��1.x�汾֮��,��֤���ݵ���������,��������:
- 1.δ�����ݵ���
max.in.flight.requests.per.connection=1
- 2.�����ݵ���
max.in.flight.requests.per.connection��Ҫ����С�ڵ���5- ԭ��˵��:��Ϊ��kafka1.x֮��,�����ݵȺ�,kafka����˻Ỻ��producer���������5��request��Ԫ����,���������,�����Ա�֤�����5��request�������������(�������кŵ�������,�������,ֱ������,���������,�Ȼ����ڴ���)
- 1.δ�����ݵ���
9.Broker
9.1.1ZK�洢Kafka��Ϣ
9.2Broker��������
9.3�ڵ��������
9.3.1�����½ڵ�
- ���½ڵ�
- 1.������ʷ�ڵ��¡(��¡ǰ�ػ���¡Ŀ��ڵ�)
- 2.��IP��ַ
- 3.��������hostname
- 4.����������¡Ŀ��ڵ�Ϳ�¡�ڵ�
- 5.�Ŀ�¡��ڵ�kafka�����ļ��е�
broker.id - 6.ɾ����¡��ڵ�kafka�����ļ�(
datas��logs) - 7.����ԭ�м�Ⱥ
- 8.���������¿�¡�ڵ��kafka
- ִ�и��ؾ���(��ʷ���������,����������½ڵ���,������Ҫʹ�ø��ؾ�����Ǩ��)
- 1.����һ��Ҫ���������:
vim topics-to-move.json{ "topics": [ "topic": "demo1" ], "version": 1 } - 2.����һ�����ؾ���ƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate - 3.���������洢�ƻ�(���и����洢��broker0��broker1��broker2��broker3��):
vim increase-replication-factor.json- ��Դ�������������ɽ��:
Proposed partition reassignment configuration
{"version":1, "partitions":[{"topics":"demo1", "partition":0, "replicase":[3, 1], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":1, "replicase":[0, 2], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":2, "replicase":[1, 3], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":3, "replicase":[2, 0], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":4, "replicase":[3, 2], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":5, "replicase":[0, 3], "log_dirs":["any", "any"]}, {"topics":"demo1", "partition":6, "replicase":[1, 0], "log_dirs":["any", "any"]}]} - ��Դ�������������ɽ��:
- 4.ִ�и����洢�ƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --execute- ����
Successfully started...����ʾִ�гɹ�
- ����
- 5.��֤�����洢�ƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --verify
- 1.����һ��Ҫ���������:
9.3.1���۾ɽڵ�
- ִ�и��ؾ������(��Ҫ���۽ڵ�����Ǩ�Ƶ������ڵ�)
-
1.����һ��Ҫ���������:
vim topics-move.json{ "topics": [ "topic": "demo1" ], "version": 1 } -
2.����ִ�мƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate -
3.���������洢�ƻ�(���и����洢��broker0��broker1��broker2��):
vim increase-replication-factor.json{"version":1, "partitions":[{"topics":"demo1", "partition":0, "replicase":[2, 0, 1], "log_dirs":["any", "any", "any"]}, {"topics":"demo1", "partition":1, "replicase":[0, 1, 2], "log_dirs":["any", "any", "any"]}, {"topics":"demo1", "partition":2, "replicase":[1, 2, 0], "log_dirs":["any", "any", "any"]}]} -
4.ִ�и����洢�ƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --execute- ����
Successfully started...����ʾִ�гɹ�
- ����
-
5.��֤�����洢�ƻ�
/opt/module/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --verify
-
- ֹͣ���ۺ��kafka�ڵ�
kafka-server-stop.sh
9.4kafka����
9.4.1������Ϣ
- Kafka��������:������ݿɿ���
- KafkaĬ��1������,����������һ������2��,��֤���ݿɿ���,̫�ั�������Ӵ��̴洢�ռ�,�������紫��ʱ��,����Ч��
- Kafka������Ϊ
Leader��Follower��Kafka������ֻ������ݷ���Leader,Ȼ��Follower��Leader��������ͬ�� - Kafka�����е����и���ϵͳ��Ϊ
AR(Assigned Repllicas)AR = ISR + OSR
ISR:��ʶ��Leader����ͬ����Follwer����,���Follower��ʱ��δ��Leader����ͨ�������ͬ������,���Follower�����߳�ISR���С���ʱ�����ֵ��replica.lag.time.max.ms�����趨,Ĭ��30s��Leader�������Ϻ�,�ͻ��ISR��ѡ���µ�LeaderOSR:��ʶFollower��Leader����ͬ��ʱ,��ʱ����ĸ���
9.4.2ѡ������
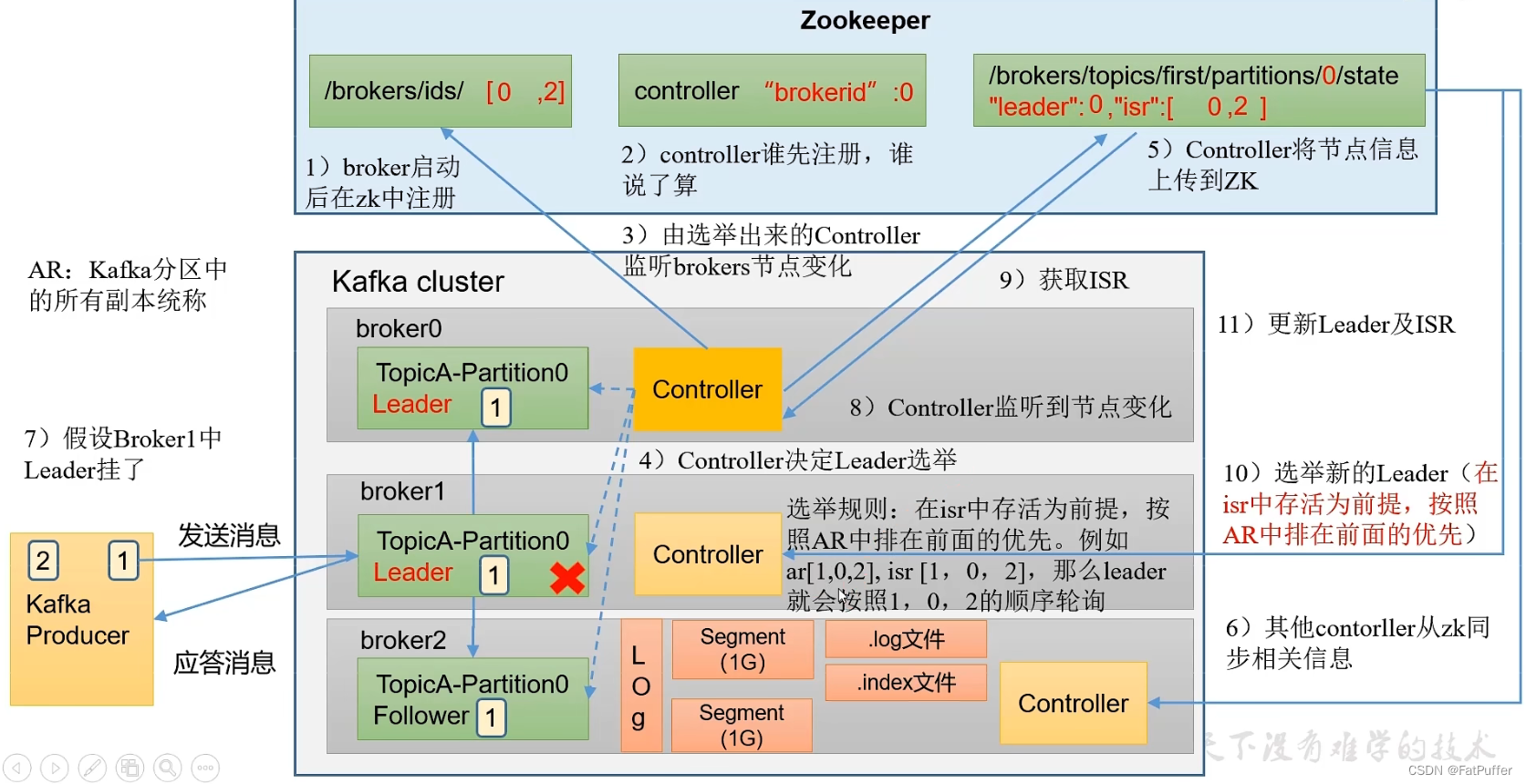
- Kafka����һ��Broker��
Controller�ᱻѡ��ΪController Leader,����������Ⱥbroker��������,����topic�ķ������������Leaderѡ�ٵȹ��� Controller����Ϣͬ��������������Zookeeper��- 1.����
Brokerʱ,��zookeeper��/kafka/brokers/ids�½���ע�� - 2.ÿ��
Broker�е�Controller����ע��zookeeper�е�/kafka/controller�ڵ�,˭������˭����controller leader - 3.
controller leader����/kafka/broker/ids�ı仯 - 4.
Broker�ڵ����������,Controller��ʼѡ��Leader- ѡ�ٹ���:��ISR�д��Ϊǰ��,����AR������ǰ������ȡ�����:ar[1, 0 ,2],isr[1, 0, 2],��ôleader�ͻᰴ��1,0,2��˳����ѯ
- 5.
Controllerѡ�ٳ�Leader��,��ʼ��zookeeper��/kafka/brokers/topics/demo1/partitions/0/state�ڵ�д����Ϣ - 6.����
Broker�ϵ�Controller��zookeeper��ͬ�������Ϣ,��ֹ��Ϊleader��Controller����ҵ� - 7.���״�ѡ�ٳ���leaderλ��
Broker1,��ʱ���Broker1�ϵ�Leader������� - 8.��ʱ
Controller��/kafka/brokers/ids�ϵı仯 - 9.
Controller��/kafka/brokers/topics/demo1/partitions/0/state�ڵ��ȡISR��Ϣ - 10.�ٴΰ���ѡ�ٹ���,��ʼ��һ��ѡ��
- 11.ѡ����ɺ����
/kafka/brokers/topics/demo1/partitions/0/state�ڵ���Ϣ(��Ҫ��leader,isr)
9.4.3�ֶ��������������洢
9.4.3.1ԭ��
- ������������,ÿ̨�����������ú����ܿ��ܲ�һ��,����kafkaֻ������Լ��Ĵ��������Ӧ�ķ�������,�ͻᵼ�¸������ܵ͵ķ������洢ѹ���ϴ�,������Ҫ�ֶ��������������Ĵ洢
- ����:����һ���µ�topic,4������,2������,����Ϊ
demo2,����topic�����и������洢��broker0��broker1��̨��������
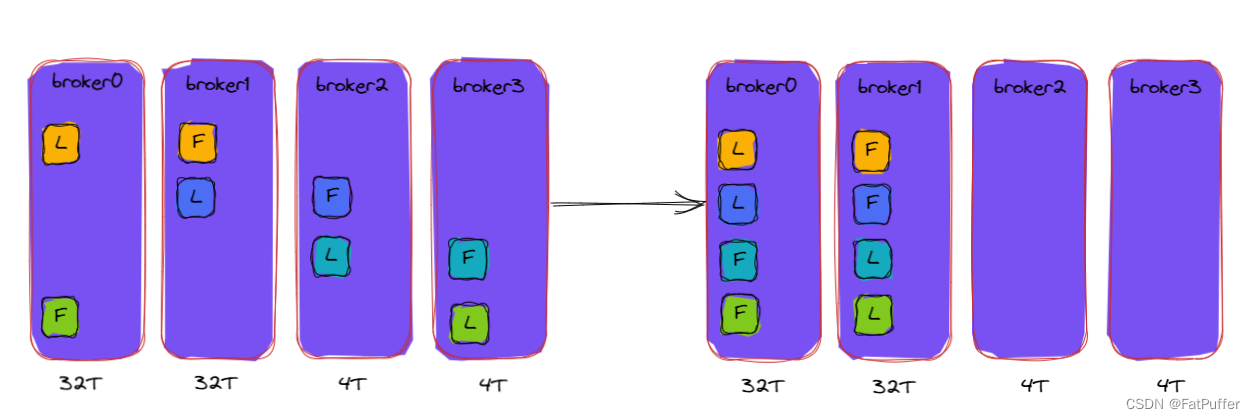
9.4.3.2����
- ����
demo2����kafka-topics.sh -bootstrap-server first-node:9092 --create --topic demo2 --partitions 4 --replication-factor 2 - �鿴���������洢���
kafka-topics.sh -bootstrap-server first-node:9092 --describe --topic demo2Topic: demo2 Topicld: -tfY5h@3Rg236b6sooxs7g PartitionCount: 4 ReplicationFactor: 2 configs; segment. bytes=1073741824 Topic: demo2 Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: demo2 Partition: 1 Leader: 3 Replicas: 3,2 Isr: 3,2 Topic: demo2 Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3 Topic: demo2 Partition: 3 Leader: 0 Replicas: 0,1 Isr: 0,1 - ���������洢�ƻ�(�����и�����ָ���洢��broker0��broker1��):
vim increase-replication-factor.json{ "version": 1, "partitions": [ {"topic": "demo2", "partition": 0, "replicas": [0, 1]}, {"topic": "demo2", "partition": 1, "replicas": [0, 1]}, {"topic": "demo2", "partition": 2, "replicas": [0, 1]}, {"topic": "demo2", "partition": 3, "replicas": [0, 1]}, ] } - ִ�и����洢�ƻ�
kafka-reassign-partitions.sh -bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --execute - ��֤�����洢�ƻ�
kafka-reassign-partitions.sh -bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --verify - �鿴���������洢���
kafka-topics.sh -bootstrap-server first-node:9092 --describe --topic demo2
9.4.4�Զ�ƽ��(Leader Partition)
- ���������,kafka������
�Զ���Leader Partitionƽ����ɢ�ڸ���������,����֤ÿ̨�����Ķ�д���������Ǿ��ȵġ��������ijЩbroker崻�,�ᵼ��Leader Partition���ڼ����������ٲ��ּ�̨broker��,��ᵼ��������̨broker�Ķ�д����ѹ������,����崻�broker��������follower partition,��д����ܵ�,��ɸ��ز����⡣ auto.leader.rebalance.enable:Ĭ����true���Զ�ƽ��(����������ܲ�һ��,�������ֶ����������洢,��ô�����齫������Ϊtrue)- Ƶ�������Զ�ƽ��,����Ҫ���Ĵ�����Դ��
leader.imbalance.per.broker.percentage:ÿ��broker�����IJ�ƽ��leader�ı���,Ĭ��10%,����������ֵ,�������ᴥ��leader��ƽ��leader.imbalance.check.interval.seconds:���leader�����Ƿ�ƽ��ļ��ʱ�䡣- ʾ������:

- ��ɫȦ�����IJ���,Leader��AR˳�����в���,˵����Ⱥ����broker��崻���
- ���broker0�ڵ�,����2��AR���ȸ�����0�ڵ�,����0�ڵ�ȴ����leader�ڵ�,���Բ�ƽ����+1,AR����������4
- ����broker0�ڵ�IJ�ƽ����Ϊ:1/4=25%,����10%,�ᴥ����ƽ��
- broker2��broker3�ڵ��broker0�ڵ㲻ƽ����һ��,Ҳ�ᴥ����ƽ��,broker1�IJ�ƽ����Ϊ0,����Ҫ��ƽ��
9.4.5���Ӹ�������
9.4.5.1ԭ��
- ������������,����ij���������Ҫ�ȼ���Ҫ����,���ǿ������Ӹ���,��������������Ҫ���ƶ��ƻ�,Ȼ����ݼƻ�ִ��
9.4.5.2����
-
����topic
kafka-topics.sh -bootstrap-server first-node:9092 --create --topic demo3 --partitions 3 --replication-factor 1 -
�ֶ����Ӹ����洢,���������洢�ƻ�(���и�����ָ���洢��broker0��broker1��broker2��):
vim increase-replication-factor.json{ "version": 1, "partitions": [ {"topic": "demo3", "partition": 0, "replicas": [0, 1, 2]}, {"topic": "demo3", "partition": 1, "replicas": [0, 1, 2]}, {"topic": "demo3", "partition": 2, "replicas": [0, 1, 2]} ] } -
ִ�и����洢�ƻ�
kafka-reassign-partitions.sh -bootstrap-server first-node:9092 --reassignment-json-file increase-replication-factor.json --execute
9.5�ļ��洢
9.5.1�ļ��洢����
-
Topic�����ϵĸ���,��partition�������ϵĸ���,
ÿ��partition��Ӧһ��log�ļ�,��log�ļ��д洢�ľ���producer���������ݡ�producer���������ݻᱻ�����ӵ���log�ļ�ĩ��,Ϊ��ֹlog�ļ����������ݶ�λЧ�ʵ���,kafka��ȡ�˷�Ƭ����������,��ÿ��partition��Ϊ���segment,ÿ��segment����:.indexƫ���������ļ�,.log��־�ļ�,��.timeindexʱ����������ļ�����Щ�ļ�λ��һ���ļ�����,���ļ��е���������Ϊ:topic����+������,����:demo1-0�� -
������������ɺ�ɾ������,����Ĭ�ϱ���7��,��
timeindex������ -
�鿴
.log�ļ�kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index Dumping ./00000000000000000000.indexStarting offset: 0 baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: 0 isTransactional: false isControl: false position: 75 CreateTime:1670918886067 size: 75 magic: 2 compresscodec: none crc: 73416945 isvalid: true -
�鿴
.index�ļ�kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log Dumping ./00000000000000000000.logoffset: 0 position: 0
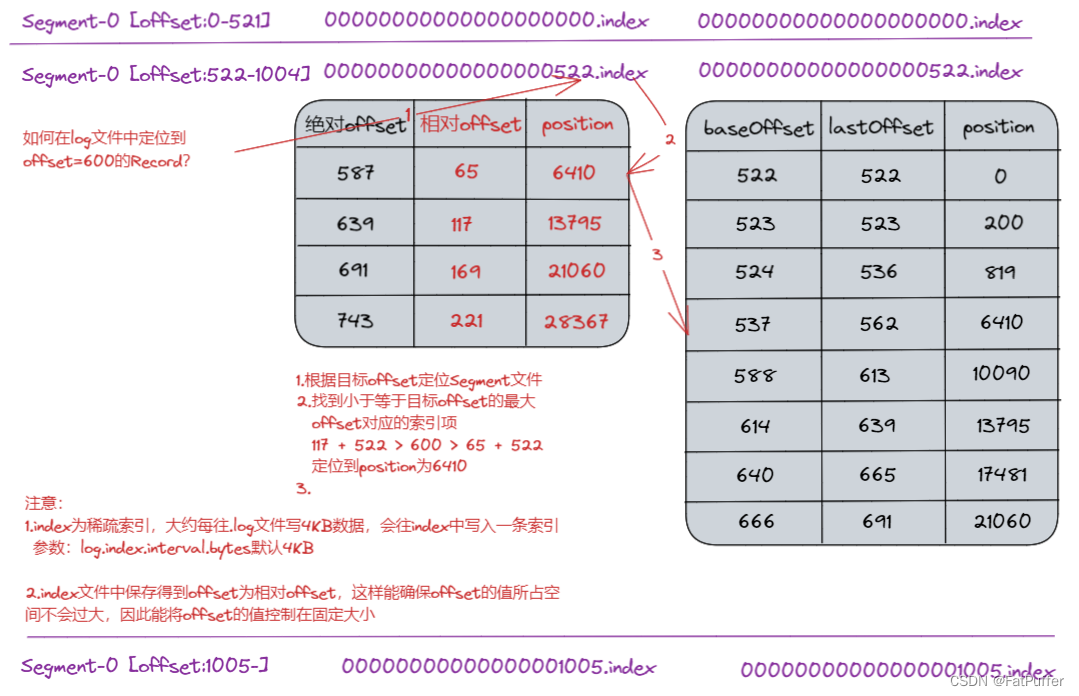
9.5.1�ļ��������
- Kafka��
Ĭ�ϵ���־����ʱ��Ϊ7��,����ͨ���������²����ı���ʱ��log.retention.hours,������ȼ�Сʱ,Ĭ��7��log.retention.minutes,����log.retention.ms,������ȼ�����log.retention.check.interval.ms,�������ü������,Ĭ��5����
- ��ô��־һ������������ʱ��,��ô����
- Kafka���ṩ����־����������
delete��compact����
- Kafka���ṩ����־����������
delete:��־ɾ��,����������ɾ��log.cleanup.policy=delete:������������ɾ������- ˼��:���һ��
segment����һ�������ݹ���,һ��������û�й���,��ô����?����ʱ��:Ĭ�ϴ�,��segment�����м�¼�е����ʱ�����Ϊ���ļ�ʱ���,������ʱ������7��,��ֱ��ɾ�����ڴ�С:Ĭ�Ϲر�,�������õ�������־�ܴ�С ,ɾ�������segmentlog.retention.bytesĬ�ϵ���-1,��ʶ�����
compact:��־ѹ��(������ͬ��key�IJ�ͬvalueֵ,ֻ�������µ�,������python�ֵ��е�update����)- ѹ����
offset�����Dz�������,������Щoffset��������Ϣʱ,�����õ������offset���offset��Ӧ����Ϣ,ʵ���ϻ��õ�offsetΪ7����Ϣ,�������λ�ÿ�ʼ���ѡ� - ���ֲ���ֻ�ʺ����ⳡ��,������Ϣ��key���û�id,value���û�����,ͨ������ѹ������,������Ϣ����ͱ������û����µ�����
- ѹ����
9.6�������
- Kafka�����Ƿֲ�ʽ��Ⱥ,���Բ��÷�������,���жȸ�
- �����ݲ���
ϡ������,���Կ��ٶ�λҩ���ѵ����� - ˳��д����
- kafka��producer��������,Ҫд��log�ļ���,д�Ĺ�����
һֱ�����ļ�ĩ��,Ϊ˳��д���ٷ����Խ��:˳��д�ܴﵽ600M/s,�����дֻ��100K/s��������̵Ļ�е�ṹ�й�,˳��д֮���Կ�,����Ϊ��ʡȥ�˴�����ͷѰַ��ʱ��
- kafka��producer��������,Ҫд��log�ļ���,д�Ĺ�����
- ҳ���� + �㿽��
�㿽��:kafka�����ݼӹ�������������kafka�����ߺ�kafka�����ߴ���,kafka brokerӦ�ò㲻���Ĵ洢������,���ԾͲ�����Ӧ�ò�,����Ч�ʸߡ�ҳ����(PageCache):kafka�ض������ײ����ϵͳ�ṩ��PageCache����,���ϲ���д����ʱ,����ϵͳֻ�ǽ�����д��PageCache�����Ȳ�������ʱ,�ȴ�PageCache�в���,����Ҳ���,��ȥ�����ж�ȡ��ʵ����PageCache�ǰѾ����ܶ�Ŀ����ڴ涼�����˴���ʹ��
10.������(consumer)
10.1Kafka���ѷ�ʽ
pull(��)ģʽ:kafka����- kafka���ô�broker��������ȡ����
- pullģʽ�IJ���֮��:���brokerû������,�����߿��ܻ�����ѭ����,һֱ���ؿ�
push(��)ģʽ:- kafkaû�в�ȡ���ַ�ʽ,��Ϊbroker������Ϣ��������,������Ӧ���������ߵ���������,�������͵��ٶ���:
50m/s,��Consumer�������������ֻ��20m/s,������������
- kafkaû�в�ȡ���ַ�ʽ,��Ϊbroker������Ϣ��������,������Ӧ���������ߵ���������,�������͵��ٶ���:
10.2Kafka�����߹�������
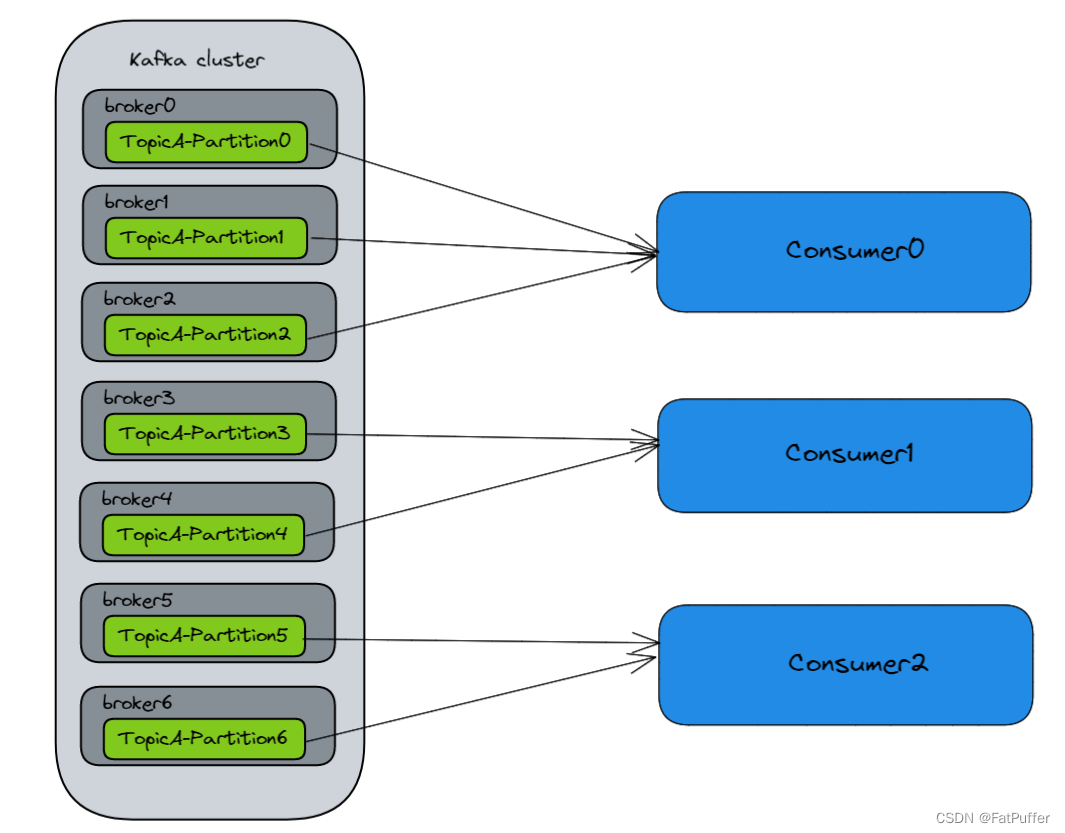
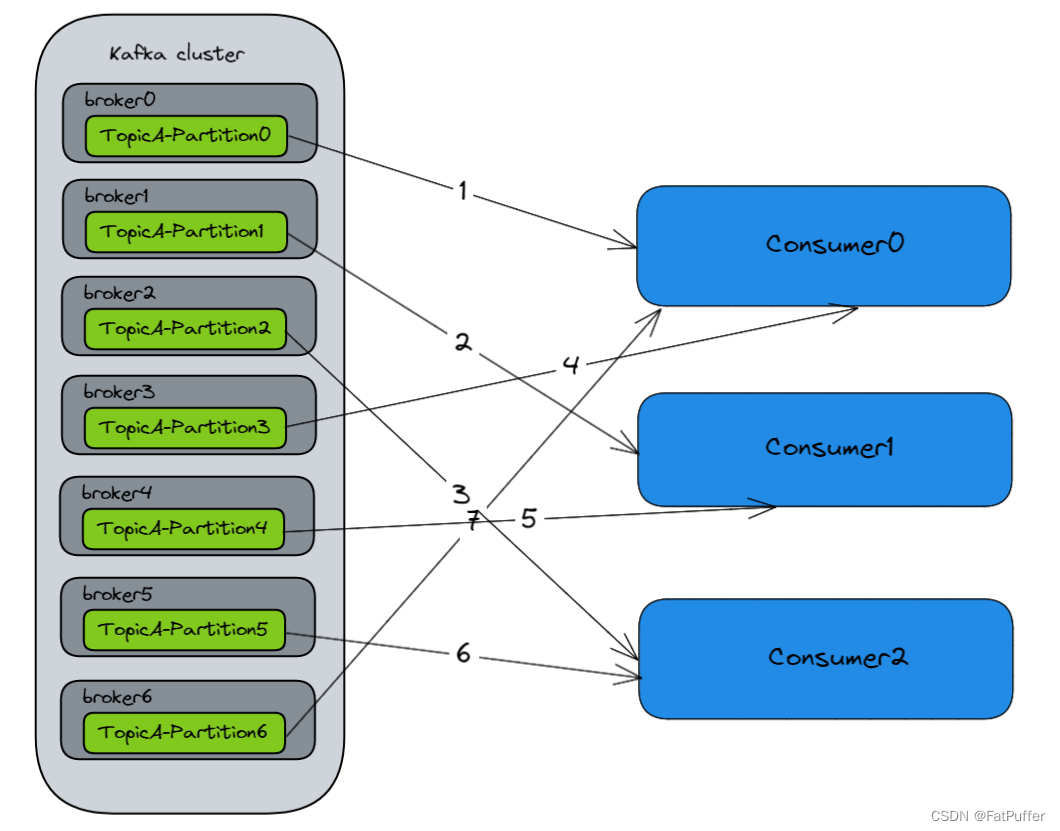
10.2.1��������������
- ������������Ϣ,������Ⱥ��ÿ��broker��topic��leader����,follower����ͬ������
- �����ߴ�topic�ϵ�leader������ȡ����,��������
ÿ�������߿��ԴӶ��������ȡ����,Ҳ���Զ�������ߴ�ͬһ����������������������߽�������,��ô�����ڵĶ�������߲���������һ������������
- ���һ������������demo1�����е�����,����ǰ�������߹���,��ʱ������������ô֪��demo1�����е��������ѵ�������?Ȼ���δ���ѵĵط���ʼ����,�����ٴδ�ͷ��ʼ,�����ظ�����
- �°��kafka��һ��Ĭ������:
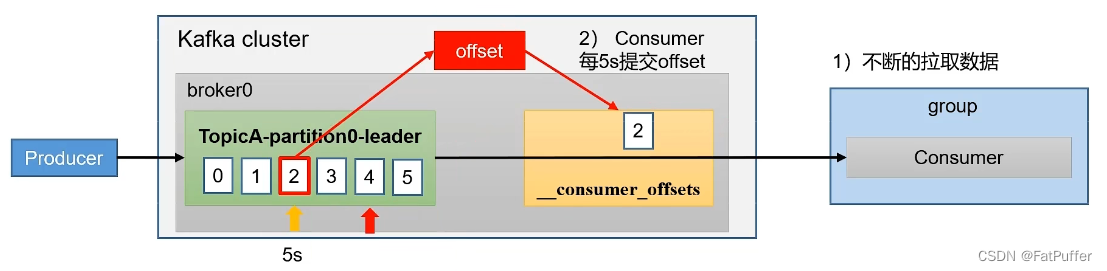
__consumer_offsets,����¼����������ƫ����Ϣ,��ʹijһ�������߹���,������������Ȼ���Դ�δ���ѵ�λ�ÿ�ʼ����
- �°��kafka��һ��Ĭ������:
10.2.2��������ԭ��
Consumer Group(CG):���������ɶ��consumer���,�γ�һ���������������,�����������ߵ�gropuid��ͬ���������ڵ�ÿ�������߸���ͬ����������,һ������ֻ�������ڵ�һ��������������������֮�以��Ӱ�졣���е������߶�����ij���������顣���������������ϵ�һ��������
10.2.3���������ʼ������
coordinator:����ʵ����������ij�ʼ���ͷ����ķ��䡣coordinator�ڵ��ѡ�� =groupid��hashcodeֵ%50- Ϊʲô��50,
__consumer_offsets�ķ������� = 50
- Ϊʲô��50,
- ����:groupid��hashcodeֵ=1,1%50=1,��ô
__consumer_offsets�����1�ŷ���,���ĸ�broker��,��ѡ������ڵ��coordinator��Ϊ�������������ϴ�,���������µ������������ύoffset��ʱ������������ȥ�ύoffset
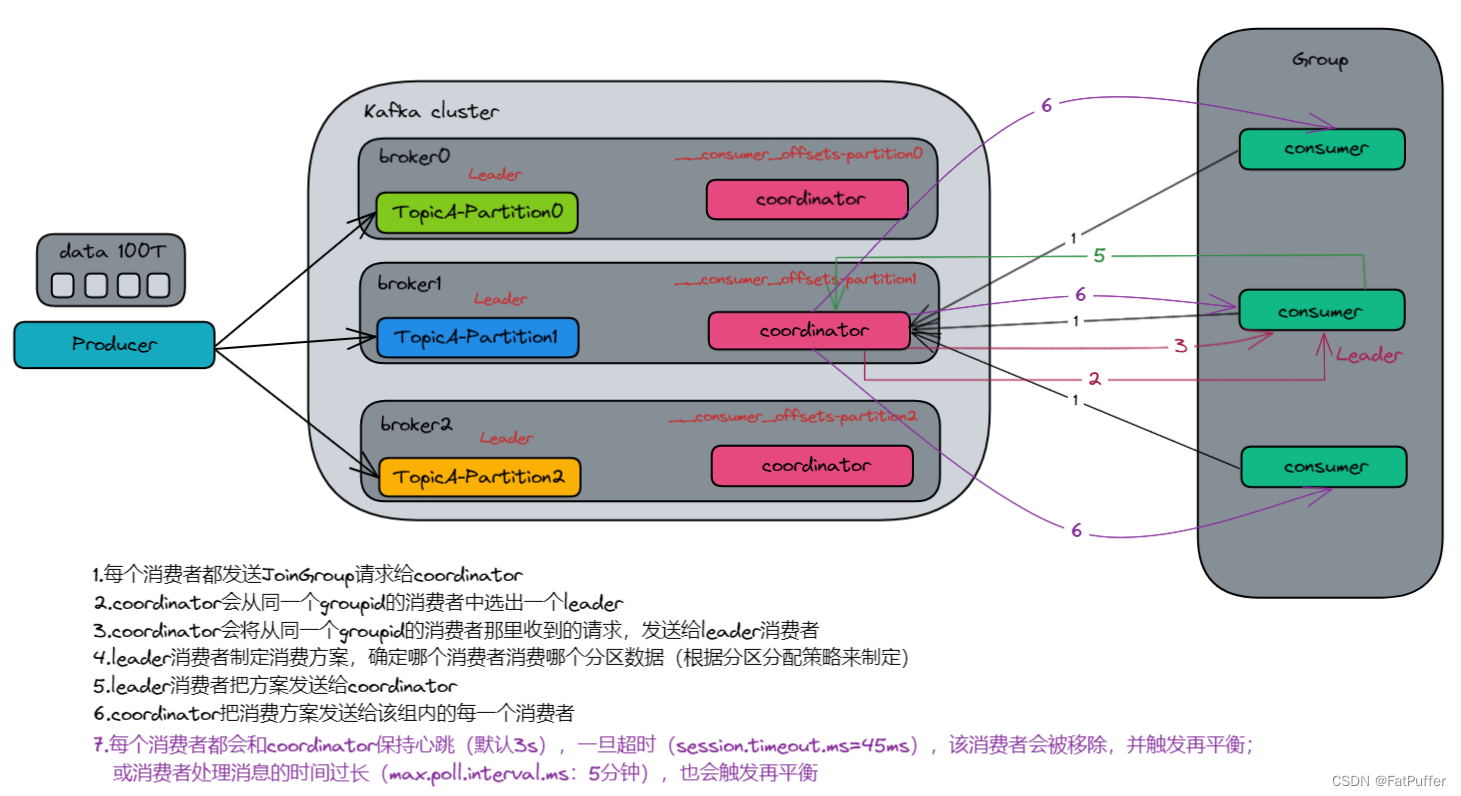
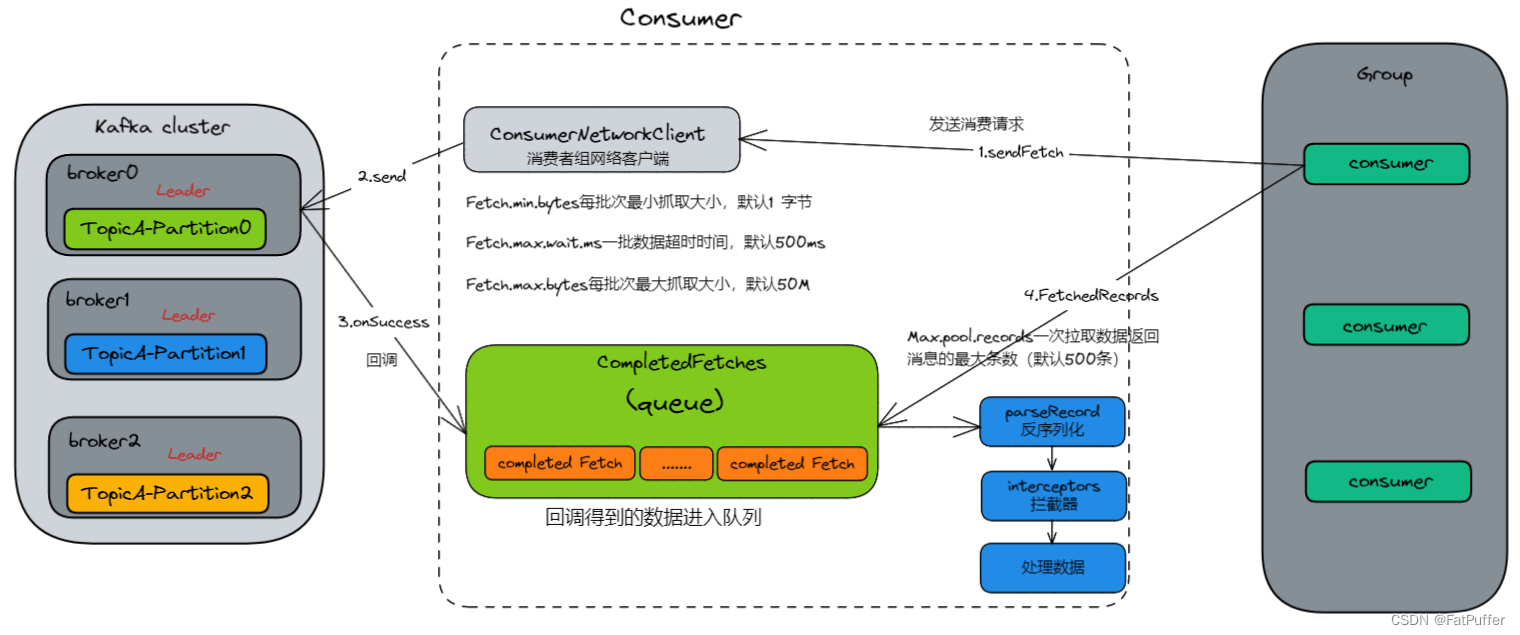
10.2.4����������ϸ��������
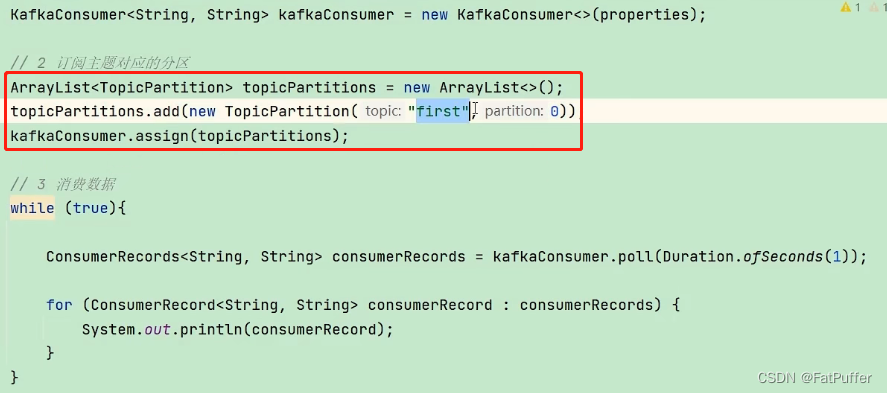
10.3Kafka������API
- ����������(��������)


- ����������(���ķ���)
- ��������
- ��
����������(��������)�����������ݼ���
- ��
10.4Kafka�����ķ����Լ���ƽ��
10.4.1����ƽ��
- һ��
consumer group���ж��consumer���,һ��topic�ж��partition���,���ڵ�������,���������ĸ�consumer�������ĸ�partition������
10.4.2����ƽ�����
RangeRoundRobinStickyCooperativeSticky- ����ͨ�����ò���:
partition.assignment.stratge,�ķ��������ò��ԡ�Ĭ�ϲ�����:Range + CooperativeSticky,kafka����ͬʱʹ�ö���������ò��ԡ�
10.4.3Range��������
Range�Ƕ�ÿ��topic����- ���ȶ�ͬһ��topic�����
����������Ž�������,���������߰�����ĸ˳������- ����������7������,3��������,�����ķ���������:
0,1,2,3,4,5,6,�����������:C0,C1,C2
- ����������7������,3��������,�����ķ���������:
- ͨ��
partitions�� / consumer��������ÿ��������Ӧ�����Ѽ������������������,��ôǰ�漸�������������һ��������- ����,7 / 3 = 2 �� 1,��ô������C0��������һ��������8 / 3 = 2 �� 2,��ôC0,C1�ֱ������һ������
ע��:���ֻ�����һ��topic����,C0�����߶�����һ������Ӱ�첻�Ǻܴ�,���������N���topic,��ô���ÿ��topic������C0����������һ������,topicԽ��,C0���ѵķ�������������������Զ�����N������,���ײ���������б��- ���C0�����߹���,��������45s��,����������Ϣ,��ȫ��ֱ�ӽ��ɴ����������е�ijһ��,�����Ǿ���
- C1:0��1��2��3��4 --------------> C2:4��5
- ����
- C1:3��4 --------------> C2:0��1��2��4��5
- ����45s��������δ���Ļ�,�ͻᴥ����ƽ��,��ʱ����ʣ��������߽���range����
- C1:0��1��2��3
- C2:4��5��6
10.4.4RoundRobin��������
- RoundRobin:��Լ�Ⱥ������topic����
- �����е�partition�����е�consumer���г���,Ȼ����hashcode��������,���ͨ��
��ѯ�㷨������partition�������������� - ��ʹC0��������߹���,��������45s��,��C0���������ѵķ���0��3��6,����������Ϣ,��ȫ��ֱ�ӽ�����������������(C1��C2),0����C1��3����C2��6����C1
- C1:0��1��4��6����
- C2:2��3��5����
- ����45s��������δ���Ļ�,�ͻ�
������ƽ��,��ʱ����ʣ��������߽���range����- C1:0��2��4��6
- C2:1��3��5
- ���÷����������

10.4.5Sticky�Լ���ƽ��
- ��Է�������:����Ľ������
��Ե�,����ִ��һ���µķ���ǰ,������һ�η���Ľ��,�����ٵĵ�������ı䶯,���Լ��ٴ����Ŀ��� - ��Է����Ǵ�kafka0.11�汾��ʼ�����,���Ȼᾡ������ķ��÷�������������,�ڳ���ͬһ���������������߳��������ʱ��,�ᱣ��ԭ�з���ķ�������仯
- ������
����������� - ��ʹC1��������߹���,��������45s��,����������Ϣ,��ȫ��ֱ�ӽ�����������������
- ��ʹC1��֮ǰ��������:
- C0:
0��1���� - C1:
4��5��6���� - C2:
2��3����
- C0:
- C1�������ݳ�ʱ��C0��C2�������
- C0:
0��1��4��6���� - C2:
2��3��5����
- C0:
- ��ʹC1��֮ǰ��������:
- ����45s��������C1��δ���Ļ�,�ͻ�
������ƽ��,��ʱ����ʣ��������߽���range����- C1:
0��1��4��6���� - C2:
2��3��5����
- C1:
- ���÷����������

10.5offset�
10.5.1����
- ��0.9�汾��ʼ,consumerĬ�Ͻ�offset������kafkaһ��
���õ�topic��,��topicΪ__consumer_offsets - 0.9�汾֮ǰ,consumerĬ�Ͻ�offset������zookeeper��(���������߶�Ҫ��zookeeper����,Ч�ʵ���)
__consumer_offsets�������������key��value�ķ�ʽ�洢����,key:group.id + topic + ������,value���ǵ�ǰoffset��ֵ��ÿ��һ��ʱ��,kafka�ڲ�������topic����compact(ѹ��:���Ǹ���),Ҳ����ÿ��roup.id + topic + �����žͱ�����������
10.5.2�鿴__consumer_offsets���ϵͳ����
- �������ļ�
/opt/module/kafka/config/consumer.properties����������exclude.internal.topics=false,Ĭ��Ϊtrue,��ʾ��������ϵͳ����,Ϊ�˲鿴ϵͳ��������,������Ҫ��Ϊfalse xsync�ַ��ű�- �鿴
__consumer_offsets��������kafka-console-consumer.sh --bootstrap-server first-node:9092 --topic __consumer_offsets --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
10.5.3�Զ��ύ
- Ϊʹ�����ܹ��ܹ�רע���Լ���ҵ����,kafka�ṩ���Զ��ύoffset�Ĺ���
- �Զ��ύoffset��ز���
enable.auto.commit:�Ƿ����Զ��ύoffset����,Ĭ����trueauto.commit.interval.ms:�Զ��ύoffset�ļ��ʱ��,Ĭ����5s

10.5.3�ֶ��ύ
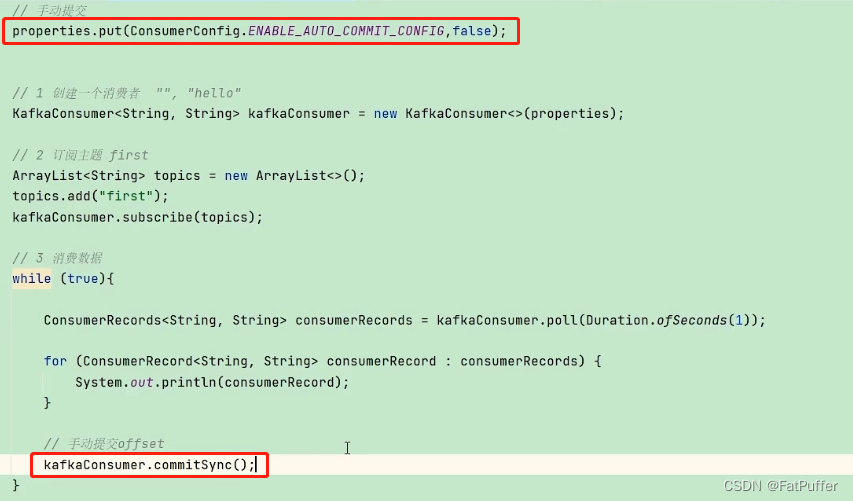
- ��Ȼ�Զ��ύ
offsetʮ�ֱ���,���������ǻ���ʱ���ύ��,������Ա������offset�ύ��ʱ��,���kafka���ṩ���ֶ��ύoffset��api - �ֶ��ύ
offset�ķ���������,�ֱ���:commitSync(ͬ���ύ)��commitAsync(�첽�ύ)�����ߵ���ͬ����,���Ὣ�����ύ��һ��������ߵ�ƫ�����ύ;��ͬ����,ͬ���ύ������ǰ�߳�,һֱ���ύ�ɹ�,���һ��Զ�ʧ�ܳ���(�ɲ��ɿ����ص���,Ҳ������ύʧ��);���첽�ύû��ʧ�����Ի���,���п����ύʧ����commitSync:����ȴ�offset�ύ���,��ȥ������һ�����ݡ�commitAsync:�������ύoffset�����,�Ϳ�ʼ������һ������

10.5.4ָ��offset����
- ��kafka��û�г�ʼƫ����(���������һ������)��������ϲ��ٴ��ڵ�ǰƫ����ʱ(����������ѱ�ɾ��),����ô��?
auto.offset.reset=earliest|latest|noneĬ����latestearliest:�Զ���ƫ��������Ϊ�����ƫ����,--from-beginningleast:�Զ���ƫ��������Ϊ����ƫ����none:���δ�ҵ������������ǰƫ����,�����������׳��쳣
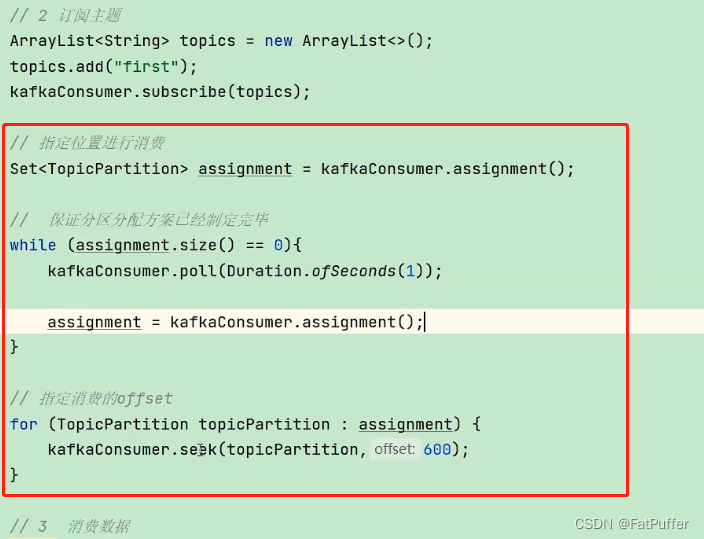
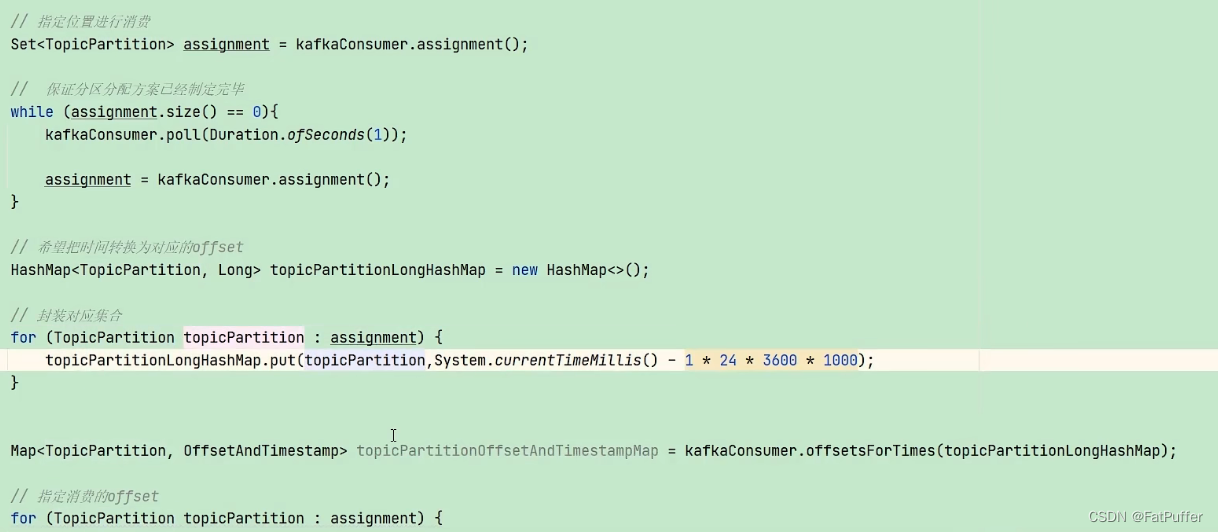
10.5.4ָ��ʱ������
- ����:������������,������������ѵļ���Сʱ�����쳣,�����°���ʱ�����ѡ�����Ҫ����ʱ������ǰһ�������

10.5.4©���Ѻ��ظ�����
-
�ظ�����:�Ѿ������˵�����(�Զ��ύoffset)
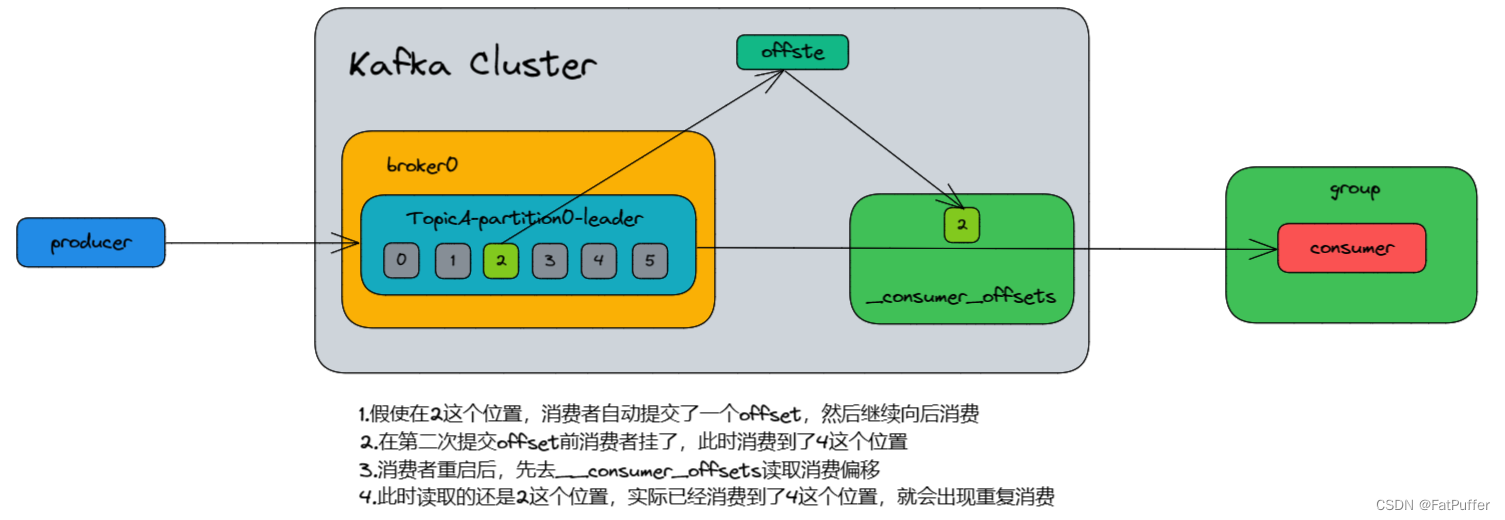
-
©����:���ύoffset������,�п��ܻ�������ݵ�©����(�ֶ��ύoffset)- �������ߴӷ������õ�Ҫ�������ݺ�,�������ύoffset,���ݻ������ڴ���,δ����,��ʱ����������ҵ�,��ôoffset�Ѿ��ύ,��������δ����,�����ⲿ���ڴ��е����ݶ�ʧ��
-
�������:
����������
10.6����������
10.6.1����
- ��������
Consumer�˵ľ�һ��������,��ô��Ҫkafka���Ѷ˽����ѹ��̺��ύoffset������ԭ�Ӱ�����ʱ������Ҫ��kafka��offset���浽֧��������Զ������(����Mysql)��
10.7���������ݻ�ѹ
10.7.1������������������
- ���kafka������������,����Կ���
��Topic�ķ�����,����ͬʱ���������������������,��������=��������(����ȱһ����) - ������������ݴ�������ʱ:
���ÿ������ȡ���ݵ�������������ȡ��������(��ȡ����/����ʱ�� < �����ٶ�),ʹ����������С������������,Ҳ��������ݻ�ѹ