Datawhale组队学习――数据分析入门(五)
本文为datawhale数据分析开源课程的学习笔记,课程链接
使用的数据为kaggle上的泰坦尼克数据
特征工程
import pandas as pd
import numpy as np
# 读取训练数集
train = pd.read_csv('train.csv')
train.shape
- 对分类变量缺失值:填充某个缺失值字符(NA)、用最多类别的进行填充
- 对连续变量缺失值:填充均值、中位数、众数
# 对分类变量进行填充
train['Cabin'] = train['Cabin'].fillna('NA')
train['Embarked'] = train['Embarked'].fillna('S')
# 对连续变量进行填充
train['Age'] = train['Age'].fillna(train['Age'].mean())
# 检查缺失值比例
train.isnull().sum().sort_values(ascending=False)
#将字符串转为独热编码
# 取出所有的输入特征
data = train[['Pclass','Sex','Age','SibSp','Parch','Fare', 'Embarked']]
data = pd.get_dummies(data)
建模
模型选择思路:
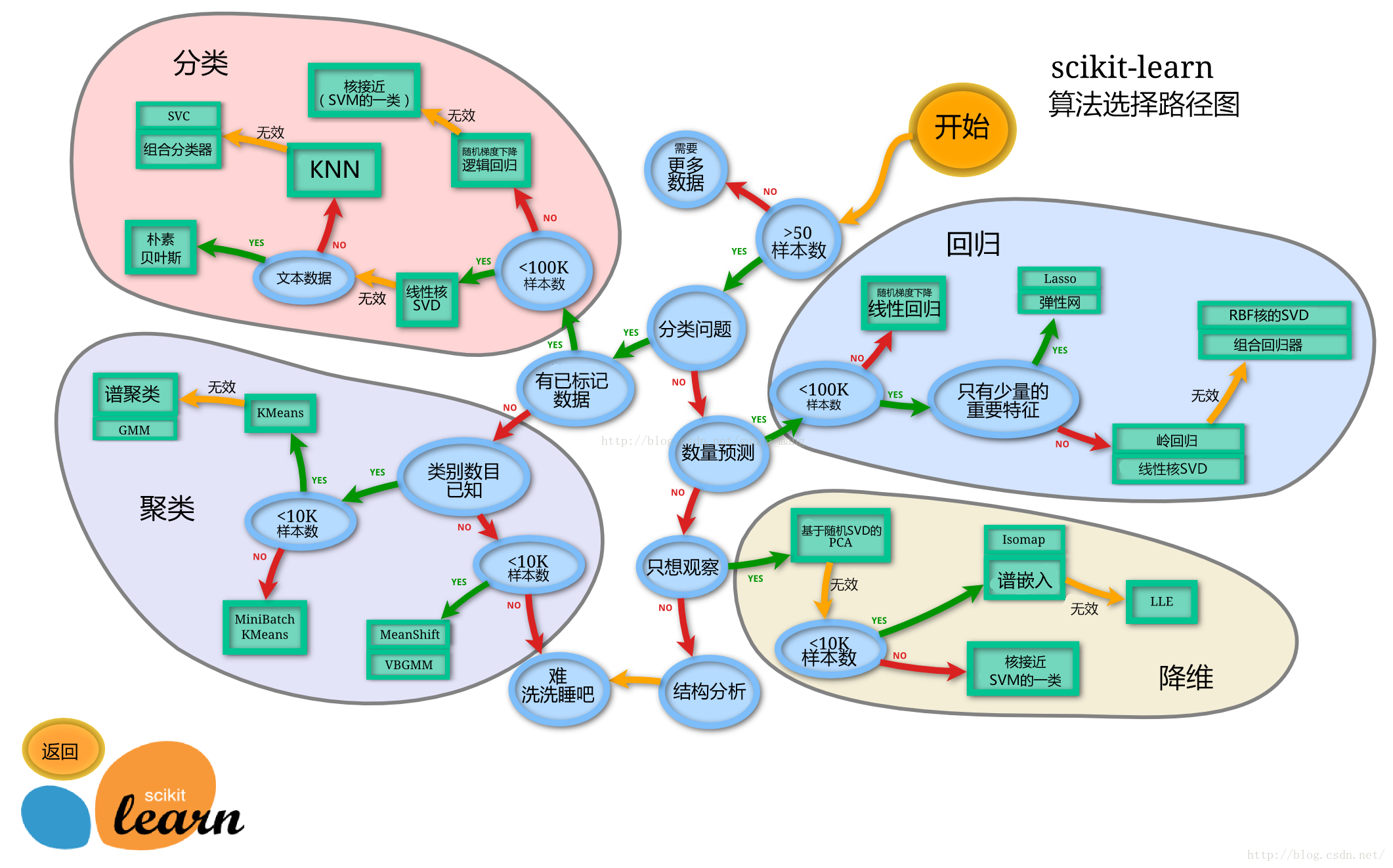
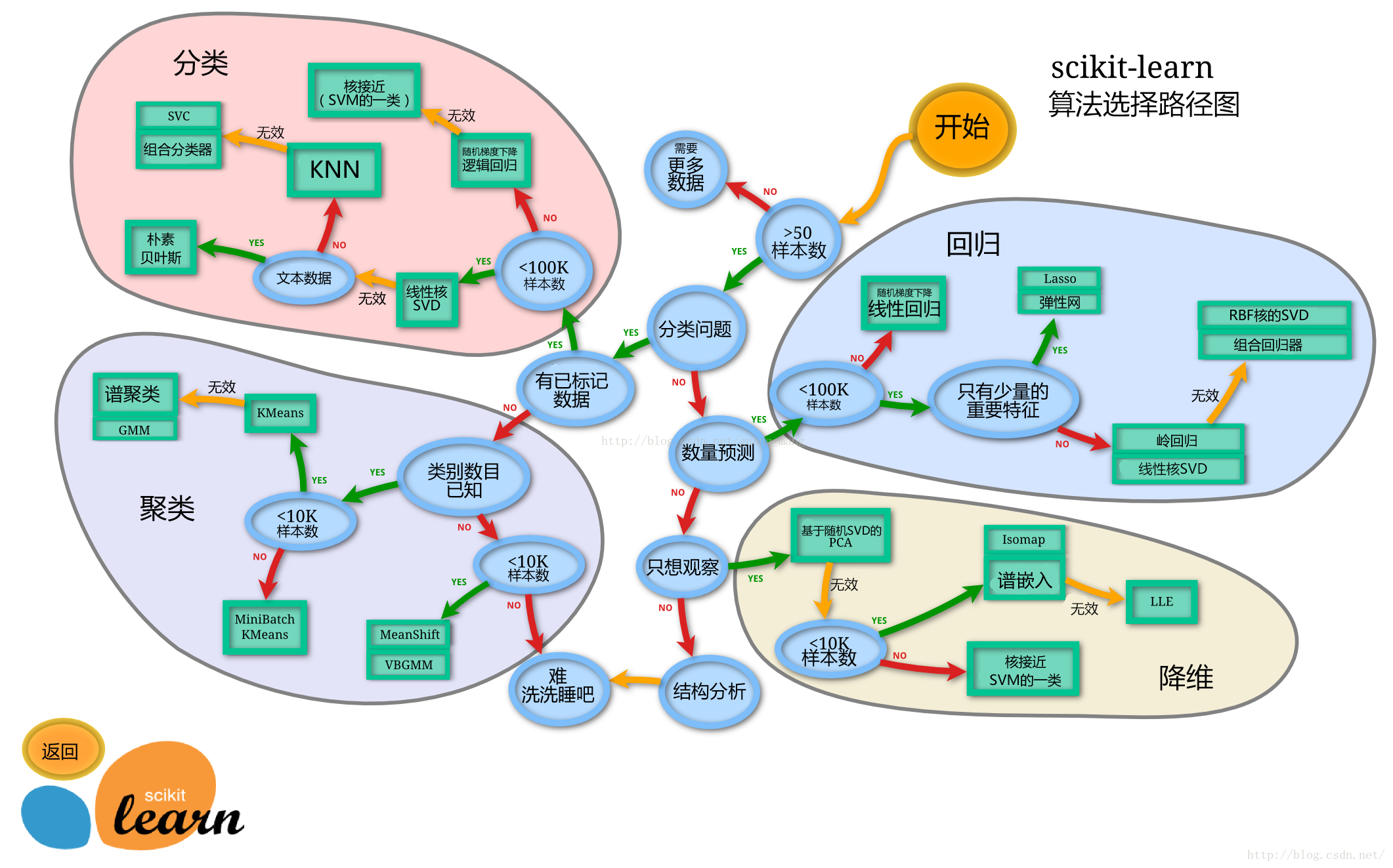
任务一:切割训练集和测试集
主要有以下步骤:
- 将数据集分为自变量(特征)和因变量(结果标签)
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
思考:分层抽样优缺点
分层抽样的优点:
1、当一个总体内部分层明显时,分层抽样能够提高样本的代表性,从而提高由样本推断总体的精确性;
2、分层抽样特别适用于既要对总体参数进行推断,也要对各子总体(层)的参数进行推断的情形;
3、分层抽样实施起来灵活方便,而且便于组织。
分层抽样的缺点:调查者必须对总体情况有较多的了解,否则无法进行恰当分层。抽样手续较简单随机,抽样还要繁杂。
切割数据集的方法为sklearn中切割数据集的方法为train_test_split,为了提高模型的泛化能力,需要随机选取数据集切割,除非数据本身分布是随机的。
# 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用
X = data
y = train['Survived']
# 对数据集进行切割
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 查看数据形状
X_train.shape, X_test.shape
任务二:数据建模
逻辑回归分类模型
from sklearn.linear_model import LogisticRegression
# 默认参数逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)
# 查看训练集和测试集score值
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))
# 调整参数后的逻辑回归模型
lr2 = LogisticRegression(C=100)
lr2.fit(X_train, y_train)
#打印训练分数
print("Training set score: {:.2f}".format(lr2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))
随机森林决策树模型
from sklearn.ensemble import RandomForestClassifier
# 调整参数后的随机森林分类模型
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc2.score(X_test, y_test)))
思考:为什么线性模型可以进行分类任务?
通过一个函数即将线性函数的结果转换为概率,就能实现分类任务
思考:对于多分类问题,线性模型是怎么进行分类的?
对于多分类的问题,可以利用逻辑回归训练多个分类器,把其中一个当做一类,其他的作为一类。
任务三:输出模型预测结果
# 预测标签
pred = lr.predict(X_train)
# 预测标签概率
pred_proba = lr.predict_proba(X_train)
思考:预测标签的概率对我们有什么帮助?
预测标签的概率能知道模型的准确性。
模型评估
- 模型评估是为了知道模型的泛化能力。
- 交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
- 在交叉验证中,数据被多次划分,并且需要训练多个模型。
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量的是正类样本中有多少被预测为正类
- f-分数是准确率与召回率的调和平均
简而言之,为了测试模型的准确性,需要进行评估,评估的方法为交叉验证,评估的标准有准确率、召回率、f-分数。
交叉验证
用10折交叉验证来评估之前的逻辑回归模型,计算交叉验证精度的平均值
from sklearn.model_selection import cross_val_score
lr = LogisticRegression(C=100)
scores = cross_val_score(lr, X_train, y_train, cv=10)
# k折交叉验证分数
scores
# 平均交叉验证分数
print("Average cross-validation score: {:.2f}".format(scores.mean()))
思考:k折越多的情况下会带来什么样的影响?
较大的K值的交叉验证结果倾向于更好。但同时也要考虑较大K值的计算开销
任务2 混淆矩阵
- 计算二分类问题的混淆矩阵
- 计算精确率、召回率以及f-分数
什么是二分类问题的混淆矩阵?
参考:https://blog.csdn.net/uncle_gy/article/details/80379960
计算:
from sklearn.metrics import confusion_matrix
# 训练模型
lr = LogisticRegression(C=100)
lr.fit(X_train, y_train)
# 模型预测结果
pred = lr.predict(X_train)
# 混淆矩阵
confusion_matrix(y_train, pred)
# 精确率、召回率以及f1-score
from sklearn.metrics import classification_report
print(classification_report(y_train, pred))
任务3 ROC曲线
绘制ROC曲线
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
ROC曲线相关知识点:https://www.jianshu.com/p/2ca96fce7e81