1List������
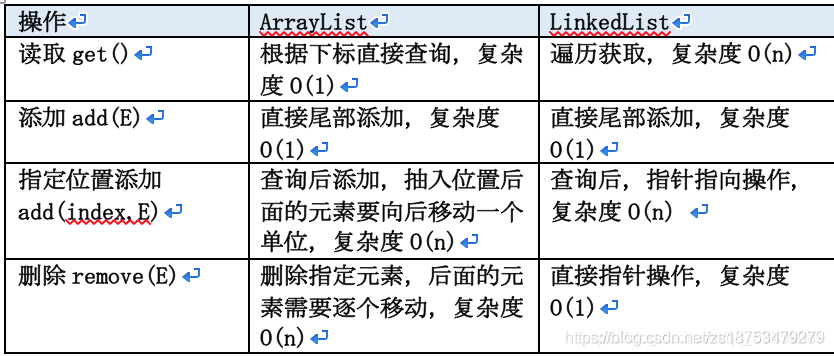
1ArrayList&&LinkedList������?
���ݽṹʵ��:ArrayList �Ƕ�̬��������ݽṹʵ��,�� LinkedList ��˫�����������ݽṹʵ�֡�
�������Ч��:ArrayList �� LinkedList ��������ʵ�ʱ��Ч��Ҫ��,��Ϊ LinkedList �����Ե����ݴ洢��ʽ,������Ҫ�ƶ�ָ���ǰ�������β��ҡ�
���Ӻ�ɾ��Ч��:�ڷ���β�����Ӻ�ɾ������,LinkedList Ҫ�� ArrayList Ч��Ҫ��,��Ϊ ArrayList ��ɾ����ҪӰ�������ڵ��������ݵ��±ꡣ
�ڴ�ռ�ռ��:LinkedList �� ArrayList ��ռ�ڴ�,��Ϊ LinkedList �Ľڵ���˴洢����,���洢����������,һ��ָ��ǰһ��Ԫ��,һ��ָ���һ��Ԫ�ء�
�̰߳�ȫ:ArrayList �� LinkedList ����֤�̰߳�ȫ��
�ۺ���˵,����ҪƵ����ȡ�����е�Ԫ��ʱ,���Ƽ�ʹ�� ArrayList,���ڲ����ɾ�������϶�ʱ,���Ƽ�ʹ�� LinkedList��
2 ������ʹ�õ�ʱ�����ҪΪ��������С,��ArrayList����,̸̸ArrayList����ôʵ�ֵ�?ΪʲôArrayList�Ͳ��ô�����С��?
new ArrayList()��ʱ��,Ĭ�ϻ���һ���յ�Object����,��СΪ0�������ǵ�һ��add�������ݵ�ʱ��,�����������ʼ��һ����С,�����СĬ��ֵΪ10��
����Ĵ�С�ǹ̶���,��ArrayList�Ĵ�С�ǿɱ�ġ���ΪArrayList��ʵ���˶�̬���ݵ�,ArrayList��ÿһ��add��ʱ��,��������ȥ����������鹻�����ռ�,����ռ��ǹ���,��ֱ������ȥ�ͺ��ˡ��������,�Ǿ͵�����,��Դ�����,�и�grow����,ÿһ����ԭ����1.5��,�ռ�������֮��,�����arraycopy����������п��������ճ�������,�������������ɾҪ��,��������ɾҲ��������List��β�����Ӿ�OK�ˡ�����β������Ԫ��,ArrayList��ʱ�临�Ӷ�Ҳ��O(1),ArrayList����ɾ�ײ���õ�copyOf()���Ż���,�ִ�CPU���ڴ���Կ����,ArrayList����ɾһ���Ҳ�����LinkedList����
3ArrayList �ڲ���������Dz���ȫ?
ArrayList �ڲ���������Dz���ȫ��,CopyOnWriteArrayList:д��ʱ����,�����������⡣
CopyOnWriteArrayListʹ�õ���Lock��,Ч�ʻ���Ӹ�Ч,����˼����:����ж��������(Callers)ͬʱҪ����ͬ����Դ(���ڴ�����Ǵ����ϵ����ݴ洢),���ǻṲͬ��ȡ��ͬ��ָ��ָ����ͬ����Դ,ֱ��ij����������ͼ����Դ����ʱ,ϵͳ�Ż���������һ��ר�ø���(private copy)���õ�����,���������������������������Դ��Ȼ���ֲ��䡣����̶������ĵ����߶�������(transparently)��
��������Ҫ���ŵ������������û������Դ,�Ͳ����и���(private copy)������,��˶��������ֻ�Ƕ�ȡ����ʱ���Թ���ͬһ����Դ������ʱ����Ҫ����,�������ʱ���ж���߳�������CopyOnWriteArrayList��������,�����ǻ�����ɵ�����,��Ϊд��ʱ����ס�ɵ�CopyOnWriteArrayList��
CopyOnWriteArrayList �����˼��:1 ��д����,����д�ֿ� 2 ����һ���� 3 ʹ������ٿռ��˼·,�����������ͻ��ȱ��Ҳ��,����ٿռ�ķ�ʽ:��Ҫռ��һ�����ڴ�ռ�;
4Vector������
Vector�ǵײ�ṹ������,һ�����������Ѿ��������ˡ������ArrayList,�����̰߳�ȫ��,�����ݵ�ʱ������ֱ�����������ġ�
2Map
1HashMap��ʵ��ԭ��
HashMap����: HashMap�ǻ��ڹ�ϣ����Map�ӿڵ��̲߳���ȫ��,����ʹ��nullֵ��null���������֤ӳ���˳��
HashMap�����ݽṹ: HashMapʵ������һ��������ɢ�С������ݽṹ,������������Ľ���塣
HashMap ���� Hash �㷨ʵ�ֵ�:
1 ��������HashMap��putԪ��ʱ,����key��hashCode����hash�������ǰ�����Ԫ���������е��±�
2 �洢ʱ,�������hashֵ��ͬ��key,��ʱ���������:
? (1)���key��ͬ,��ԭʼֵ;
? (2)���key��ͬ(���ֳ�ͻ),��ǰ��key-value����������;
3 ��ȡʱ,ֱ���ҵ�hashֵ��Ӧ���±�,�ڽ�һ���ж�key�Ƿ���ͬ,�Ӷ��ҵ���Ӧֵ��
4 HashMap�Ǿ�hash��ͻ���ľ���ʹ��������Ĵ洢��ʽ,Ȼ��ͻ��key�Ķ������������,һ�����ֳ�ͻ��������������һ���ĶԱȡ�
hashmap�������������:
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
������Ԫ�ظ�������8��ʱ��,�ͻ�ת��Ϊ�����;�������Ԫ�ظ���С��6��ʱ��,�ͻ�ת����������hashMap��ȷʵ����������������,�����Ǽ�ͨ��Ԫ�ظ������ж�������ת����
����ת��Ϊ�����:
����ת��Ϊ�����������Ŀ��,��Ϊ�˽����map��Ԫ�ع���,hash��ͻ�ϴ�,�����µĶ�дЧ�ʽ��͵����⡣��Դ���putVal������,�йغ�����ṹ���ķ�֧Ϊ:
//�˴���������
for (int binCount = 0; ; ++binCount) {
//�������������һ���ڵ�
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//�������Ԫ�ظ������ڵ���TREEIFY_THRESHOLD
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//�����ת����
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
�����ij��ȴﵽ8��ʱ��,��ת��Ϊ�����,����������treeifyBin����:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//���ж�table�ij����Ƿ�С�� MIN_TREEIFY_CAPACITY (64)
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//��64,������
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//����Ž�����ת��Ϊ�����
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
treeifyBin���ж�table�ij����Ƿ����64:���С��64,��ͨ�����ݵķ�ʽ�����,���������ṹ����
�����ݵķ�ʽ�������hash��ͻ,���ݺ��������ȱ��,��дЧ����Ȼ��ߡ�����,���������ת��Ϊ������ĺô����ڿ��Ա�֤���ݽṹ���� �ɴ˿ɼ��������������ȳ���8��һ����ת���ɺ����,�����ȳ������ݡ�
�����ת��Ϊ����
����˼���ǵ�������е�Ԫ�ؼ��ٲ�С��һ������ʱ,���л�����������Ԫ�ؼ������������:
1������map��remove����ɾ��Ԫ��
hashMap��remove����,����뵽removeNode��������>�ҵ�Ҫɾ���Ľڵ�,���ж�node�����Ƿ�ΪtreeNode����>Ȼ�����ɾ��������ڵ�����removeTreeNode������,�÷����йؽ��������ṹ�ķ�֧����:
//�ж��Ƿ�Ҫ��������������
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
ͨ����������ڵ㼰���ӽڵ��Ƿ�Ϊ�����жϺ����ת��Ϊ������
2��resize��ʱ��,�Ժ���������˲��
resize��ʱ��,�жϽڵ�����,���������,���������;�����TreeNode,��ִ��TreeNode��split�����ָ�����,��split�����н������ת��Ϊ�����ķ�֧����:
//����֮ǰ�����ǽ������ÿ���ڵ��hash��һ��bit����&����,
//������������������Ϊ���ú����,lc��ʾ����һ�����Ľڵ���
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
������õ��� UNTREEIFY_THRESHOLD ���ж�,��������ڵ�Ԫ��С�ڵ���6ʱ,�ŵ���untreeify����ת����������
�ܽ�
1��hashMap������������Ԫ�ظ�������8��һ����ת��Ϊ�����,�����ȿ�������,���ݴﵽĬ�����ƺ��ת��;
2��hashMap�ĺ������һ��С��6��ʱ��Ż�ת��Ϊ����,����ֻ����resize��ʱ��Ż���� UNTREEIFY_THRESHOLD ����ת����
Ĭ�ϳ�ʼ������:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
�����������:static final int MAXIMUM_CAPACITY = 1 << 30;
HashMap JDK1.8֮ǰ
JDK1.8֮ǰ���õ������������hash��ͻ��
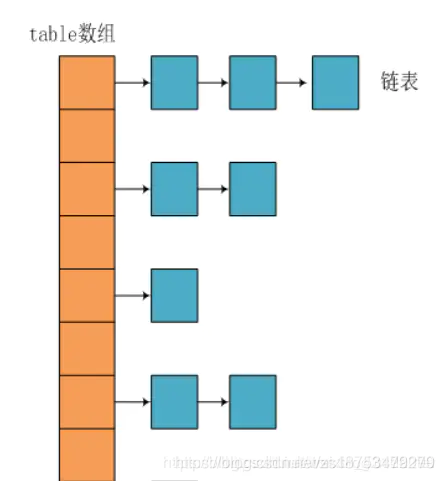
HashMap JDK1.8֮��
jdk1.8�ڽ����ϣ��ͻʱ���˽ϴ�ı仯,��������ת��Ϊ�������������ʱ,������ת��Ϊ�����,�Լ�������ʱ�䡣

2HashMap��put�����ľ�������?
1.�жϼ�ֵ������tab�Ƿ�Ϊ�ջ�Ϊnull,���Ϊ����ִ��resize()��������;���ݻ������ӨC>
2.���ݼ�key����hashֵ�õ�����i,���tab[i]==null,��ֱ���½��ڵ�����;
3.���tab[i]��Ϊ��,�ж�tab[i]����Ԫ�ص�key�ʹ���key�Ƿ���� && hashCode�Ƿ���ͬ,�����ֱͬ�Ӹ���value;
4.����,�ж�tab[i] �Ƿ�ΪtreeNode(�����),����Ǻ����,��ֱ�������в����½ڵ�;
5.����,����tab[i]�ж��Ƿ����������β��,�������β��,����β������һ���½ڵ�,Ȼ���ж����������Ƿ����8,�������8,��������ת��Ϊ�������������,����������������key�Ѿ�����,ֱ�Ӹ���value;
6����,����ɹ���,�ж�size�Ƿ�����ֵ(��ǰ����*��������),�������,�������ݡ�
public V put(K key, V value) {
//�Դ����key��hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// ����1:���tabΪ�������resize()�������д���
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// ����2:����index�±�,�����λ��Ϊnull,���ڵ�
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// ����3:���key���λ�ô��ڵĽڵ�key��ͬ����hashCode��ͬ,��ֱ�Ӹ���value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// ����4:�жϸýڵ��Ƿ�Ϊ�����,����Ǻ����,��ֱ���ڸ����в����ֵ������
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//����5:����������
for (int binCount = 0; ; ++binCount) {
//����������β,����һ���µĽڵ㲢����������β��
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//�ж����������Ƿ����8,�������8,������ת��Ϊ�����
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//����Ѵ���key��hashCode��ͬ,��ֱ�Ӹ���value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// ����6:������ֵ(��ǰ����*��������) ������
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
3HashMap����
ʲôʱ������?
jdk7���ݱ���������������:
1�� �����ֵ��ʱ��ǰ����Ԫ�صĸ���������ڵ�����ֵ
2�� �����ֵ��ʱ��ǰ������ݷ���hash��ײ(��ǰkey�����hashֵ��������������±�λ���Ѿ�����ֵ)
void addEntry(int hash, K key, V value, int bucketIndex) {��������
//1���жϵ�ǰ�����Ƿ���ڵ�����ֵ��������
//2����ǰ����Ƿ�����ϣ��ײ��������
//�������������������,��ô�����ݡ�������
if ((size >= threshold) && (null != table[bucketIndex])) {
������������//����,���Ұ�ԭ�������е�Ԫ�����·ŵ��������С�����������
������������resize(2 * table.length);������������
������������hash = (null != key) ? hash(key) : 0;������������
������������bucketIndex = indexFor(hash, table.length);��������
����} ��������
����createEntry(hash, key, value, bucketIndex);����
}
1)������hashmap�ڴ�ֵ��ʱ��(Ĭ�ϴ�СΪ16,��������0.75,��ֵ12),���ܴﵽ������16��ֵ��ʱ��,�ٴ����17��ֵ�Żᷢ����������,��Ϊǰ16��ֵ,ÿ��ֵ�ڵײ������зֱ�ռ��һ��λ��,��û�з���hash��ײ��
2)����ȻҲ�п��ܴ洢����ֵ(����16��ֵ,�����Դ�26��ֵ)����û�����ݡ�ԭ��:ǰ11��ֵȫ��hash��ײ,�浽�����ͬһ��λ��(��ʱԪ�ظ���С����ֵ12,��������),�������д����15��ֵȫ����ɢ������ʣ�µ�15��λ��(��ʱԪ�ظ������ڵ�����ֵ,����ÿ�δ����Ԫ�ز�û�з���hash��ײ,���Բ�������),ǰ��11+15=26,�����ڴ����27��ֵ��ʱ���ͬʱ����������������,��ʱ��Żᷢ����������
JDK8�е�hashMap����ֻ��Ҫ����һ������:
����ŵ���ֵ(ע�ⲻ���滻����Ԫ�ص�λ��ʱ)��ʱ�����е�Ԫ�ظ���������ֵ(����Ԫ�ص�����ֵ,��һ����ű�Ȼ�������ݻ���)
ע:
(1) ����һ���Ƿ�����ֵ��ʱ��,����ֵ�����滻��ǰ��λ�õ�����¡�
(2)���ݷ����ڴ��Ԫ��֮��,�����ݴ��֮��(�ȴ��,������), �жϵ�ǰ�������ĸ���,���������ֵ���������
?
����Ǩ��
JDK7��,HashMap���ڲ����ݱ���Ķ�������:�������µ������,map����������ÿ����Ͱ��,Ȼ�����Ͱ�е�ÿ��Entity,���¼�����hashֵ,�ҵ��������еĶ�Ӧλ��,��ͷ�巨�����µ�������
�����м���ע���:
1 ��Ϊ��ͷ�巨,����¾�������Ԫ��λ�ûᷢ��ת������
2 Ԫ��Ǩ�ƵĹ������ڶ��߳��龳���п��ܻᴥ����ѭ��(ѭ������)��
JDK8����Ϊ��������,�������˴�������:����ʹ�õ���2���ݵ���չ(ָ������Ϊԭ��2��),����,����rehash֮��,Ԫ�ص�λ��Ҫô����ԭλ��,Ҫô����ԭλ�����ƶ�2���ݵ�λ�á�
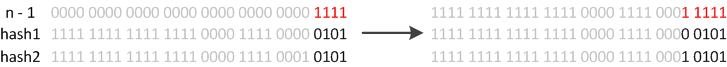
���λ��0�����겻��,���λ��1�������Ϊ��10000+ԭ���ꡱ,����ԭ����+ԭ���ꡱ������ͼ:
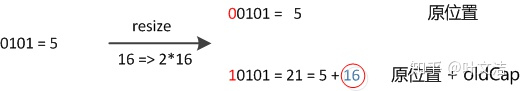
���,������ʱ,����Ҫ���¼���Ԫ�ص�hash��,ֻ��Ҫ�ж����λ��1����0�ͺ��ˡ�
JDK8��HashMap��������ϸ��:
1 JDK8��Ǩ��Ԫ��ʱ�������,�����������ת�õķ�����
2 ���ij��Ͱ�ڵ�Ԫ�س���8��,��Ὣ����ת���ɺ����,�ӿ����ݲ�ѯЧ�ʡ�
hashmap����Ϊʲô��2����?
HashMapΪ�˴�ȡ��Ч,Ҫ����������ײ,����Ҫ���������ݷ������,ÿ���������ȴ�����ͬ,���ʵ�־��ڰ����ݴ浽�ĸ������е��㷨:ȡģ,hash%length������,��Ҷ�֪���������㲻��λ����졣���,Դ���������Ż�hash&(length-1)��Ҳ����˵hash%length==hash&(length-1)��Ϊʲô��2��n�η���?��Ϊ2��n�η�ʵ�ʾ���1����n��0,2��n�η�-1,ʵ�ʾ���n��1�����糤��Ϊ8ʱ��,3&(8-1)=3 2&(8-1)=2 ,��ͬλ����,����ײ��������Ϊ5��ʱ��,3&(5-1)=0 2&(5-1)=0,����0��,������ײ�ˡ�����,��֤�ݻ���2��n�η�,��Ϊ�˱�֤����(length-1)��ʱ��,ÿһλ����&1 ,Ҳ���Ǻ�1111����1111111���������㡣
HashMap�ij�ʼ������2��n����,����Ҳ��2������ʽ��������,����Ϊ������2��n����,����ʹ�����ӵ�Ԫ�ؾ��ȷֲ���HashMap�е�������,����hash��ײ,�����γ������Ľṹ,ʹ�ò�ѯЧ�ʽ���!
4HashMap�̰߳�ȫ����
���һ:����ֱ�Ӹ���
�߳�A ���߳�B ͬʱ��ͬһ��HashMap����PUT����,����A��B�����Key-Value��key��hashcode����ͬ��,��˵���ü�ֵ�Խ�����뵽Table��ͬһ���±��,Ҳ���ǻᷢ����ϣ��ײ,��ʱHashMap����ƽʱ���������γ�һ������(�������˸��ڵ����Ǻ����),�������Dz�����±�Ϊnull(Table[i]==null)����������IJ���,��ʱ�߳�A���е�����һ����������,��ʱ���߳�A����;�߳�B�������ʱ��,����ͬ������,Ҳ��Table[i]==null ,��ʱ��ֱ������������PUT����,�ɹ���Ԫ�ز��롣����߳�A�������ʱ�����������жϼ�������,������Table[i]==null�IJ���(��ʱ��ʵӦ����Table[i]!=null�IJ���,��Ϊǰ���߳�B�Ѿ�������һ��Ԫ����),�����ͻ�ֱ�Ӱ�ԭ���߳�B���������ֱ�Ӹ�����,���һ����������̲߳���ȫ���⡣
����һ���Ƚ����Ե��̲߳���ȫ��������HashMap��get����������Ϊresize��������ѭ��(cpu100%),�����������:
1�ʼhash��size=2,key=3,7,5,����table[1]��;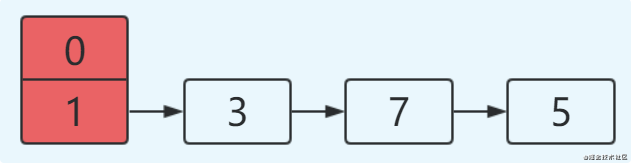
2Ȼ�����resize,ʹsize���4;����ڵ��̻߳�����,���Ľ������:

����ڶ��̻߳�����,�����������߳�A��B���ڽ���put������
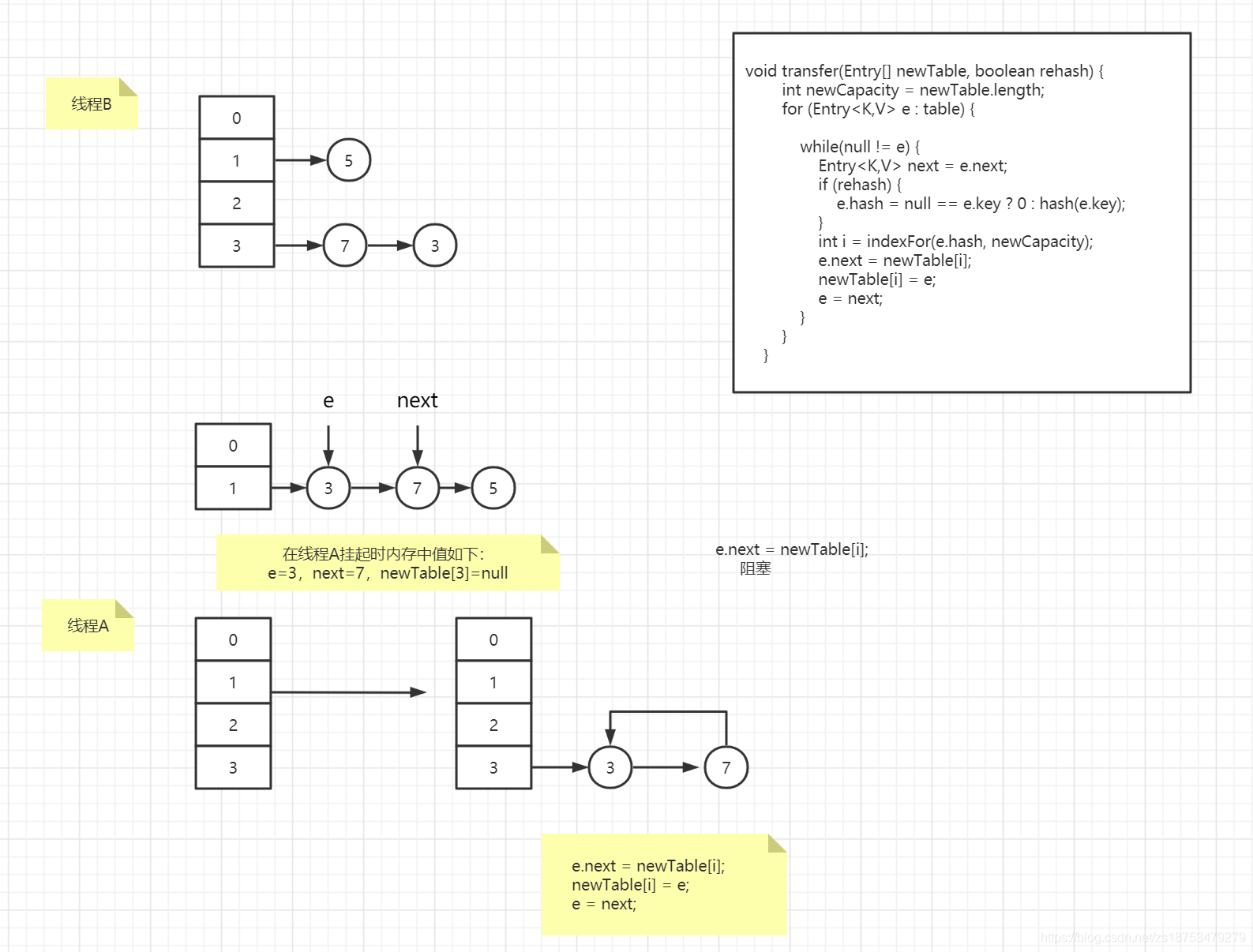
5ConcurrentHashMap���HashMap���̰߳�ȫ����
1 ʹ��Collections.synchronizedMap(Map)�����̰߳�ȫ��map����
2 Hashtable
3 ConcurrentHashMap
���������̲߳����ȵ�ԭ��,�Ҷ�������ǰ����ʹ������ConcurrentHashMap,�������ܺ�Ч�����Ը���ǰ���ߡ�
1 Collections.synchronizedMap����ôʵ���̰߳�ȫ�������˽��ô?
��SynchronizedMap�ڲ�ά����һ����ͨ����Map,�����ų���mutex:
Collections.synchronizedMap(new HashMap<>(16));
�����ڵ������������ʱ�����Ҫ����һ��Map,���Կ���������������,����㴫����mutex����,�����ų�����ֵΪ����Ķ���
���û��,�����ų�����ֵΪthis,������synchronizedMap�Ķ���,���������Map��
������synchronizedMap֮��,�ٲ���map��ʱ��,�ͻ�Է�������,��ͼȫ��🔐

2��һ��Hashtableô?
��HashMap���Hashtable���̰߳�ȫ��,�ʺ��ڶ��̵߳������ʹ��,����Ч�ʿɲ�̫�ֹ�,���ڶ����ݲ�����ʱ������,����Ч�ʱȽϵ��¡�
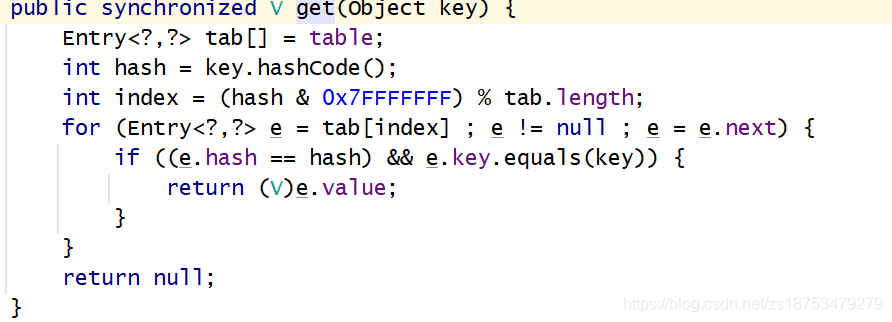
3HashTable&&HashMap������?
1 Hashtable �Dz���������ֵΪ null ��,HashMap �ļ�ֵ����Ϊ null;


���֮��,����Ϊϣ��ÿ�� key ����ʵ�� hashCode �� equals ����,�� null ��Ȼû��;����,��Ҷ���ʶ�� null ֵ����Ҫ��,���� HashMap ���� null ֵ�� key �� value���� key Ϊ null ʱ,HashMap ����� key-value pair �����һ�������λ��,���� ��һ����λ �
2 ��ʼ��������ͬ:HashMap �ij�ʼ����Ϊ:16,Hashtable ��ʼ����Ϊ:11,���ߵĸ�������Ĭ�϶���:0.75��
3 ���ݻ��Ʋ�ͬ:�������������������� * ��������ʱ,HashMap ���ݹ���Ϊ��ǰ��������,Hashtable ���ݹ���Ϊ��ǰ�������� + 1��
4ConcurrentHashMap������?
ConcurrentHashMap �ײ��ǻ��� ���� + ���� ��ɵ�,������ jdk1.7 �� 1.8 �о���ʵ�����в�ͬ��
JDK1.7:
�������ж����,ÿһ������һ������,�����ڶ��̷߳���ʱ��ͬ�ε�����ʱ,�Ͳ��������������,�� ���������Ч����߲���Ч�ʡ�
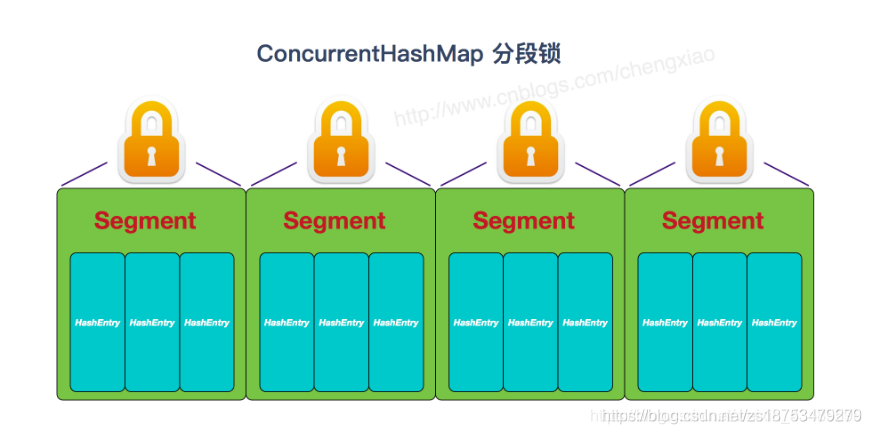

ÿһ��segment����һ��HashEntry<K,V>[] table, table�е�ÿһ��Ԫ�ر����϶���һ��HashEntry�ĵ�����С�
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// ������hashmap�ֳɼ���С��map,ÿ��segment����һ����;��hashtable���,��ô��Ƶ�Ŀ���Ƕ���put, remove�Ȳ���,���Լ��ٲ�����ͻ,�Բ�����ͬһ��Ƭ�εĽڵ���Բ�������,������������
final Segment<K,V>[] segments;
// ������Segment�����һ��С��hashmap,����table����洢�˸����ڵ������,�̳���ReentrantLock, ������Ϊ������ʹ��
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// �����ڵ�,�洢Key, Valueֵ
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
HashEntry��HashMap����,���Dz�ͬ����:��ʹ��volatileȥ��������������Value������һ���ڵ�next��
������˵˵�������ȸߵ�ԭ��ô?
ԭ������˵,ConcurrentHashMap �����˷ֶ�������,���� Segment �̳��� ReentrantLock�������� HashTable ���������� put ���� get ��������Ҫ��ͬ������,������ ConcurrentHashMap ֧�� CurrencyLevel (Segment ��������)���̲߳���,ÿ��һ���߳�ռ��������һ�� Segment ʱ,����Ӱ�쵽������ Segment��
PUT:
���ȵ�һ����ʱ��᳢�Ի�ȡ��,�����ȡʧ�ܿ϶����������̴߳��ھ���,������ scanAndLockForPut() ������ȡ��:1 ����������ȡ����2 ������ԵĴ����ﵽ�� MAX_SCAN_RETRIES ���Ϊ��������ȡ,��֤�ܻ�ȡ�ɹ���
GET:
get ���Ƚϼ�,ֻ��Ҫ�� Key ͨ�� Hash ֮��λ������� Segment ,��ͨ��һ�� Hash ��λ�������Ԫ���ϡ����� HashEntry �е� value �������� volatile �ؼ������ε�,��֤���ڴ�ɼ���,����ÿ�λ�ȡʱ��������ֵ��ConcurrentHashMap �� get �����Ƿdz���Ч��,��Ϊ�������̶�����Ҫ������
����������ķ�ʽ,����ȥ��ѯ��ʱ��,���ñ�������,�ᵼ��Ч�ʺܵ͡�
JDK1.8:
����������ԭ�е� Segment �ֶ���,�������� CAS + synchronized ����֤������ȫ��;HashEntry�ij���Node,�������ò���,��ֵ��next������volatileȥ����,��֤�˿ɼ���,����Ҳ�����˺������
̸̸��ȡ����ô?�Լ�����ô��֤�̰߳�ȫ��?
ConcurrentHashMap�ڽ���put�����Ļ��DZȽϸ��ӵ�,���¿��Է�Ϊ���²���:
1 ���Ȼ�ȥ�жϱ�����Щ��ֵ�Ե������Dz��dz�ʼ����,���û�г�ʼ�����ȵ���initTable()���������г�ʼ������;
2 Ȼ��ͨ������hashֵ��ȷ������������ĸ�λ��:
���û��hash��ͻ��ֱ��CAS����,
���hash��ͻ�Ļ�,��ȡ������ڵ���,���ȡ�����Ľڵ��hashֵ��MOVED(-1)�Ļ�,���ʾ��ǰ���ڶ���������������:���Ƶ��µ�����,��ǰ�߳�Ҳȥ��������,
���һ���������,�������ڵ㲻Ϊ��,Ҳ��������,��ͨ��synchronized������,�������Ӳ���,Ȼ���жϵ�ǰȡ���Ľڵ�λ�ô�ŵ�������������,
3 ����������Ļ�,�������������,�����еĽڵ�key��Ҫ��ŵ�key���бȽ�:���key��� && key��hashֵҲ��ȵĻ�,��˵����ͬһ��key,�ǵ�value,����Ļ������ӵ�������ĩβ;
��������Ļ�,�����putTreeVal���������Ԫ�����ӵ�����ȥ,������������֮��,����addCount()����ͳ��size,�ж��ڸýڵ㴦���ж��ٸ��ڵ�(ע��������ǰ�ĸ���),����ﵽ8�������˵Ļ�,�����treeifyBin���������Խ���������תΪ��,������������;
����̸̸CAS��ʲô?��������ʲô?��>
����̸̸ConcurrentHashMap��get����������ô���ӵ���?
1 ���ݼ�������� hashcode Ѱַ,�������Ͱ����ôֱ�ӷ���ֵ��
2 ����Ǻ�����ǾͰ������ķ�ʽ��ȡֵ��
3 �Ͳ������ǾͰ��������ķ�ʽ������ȡֵ��