����dz��CenterFusion
Summary
�Զ���ʻ�����ĸ�֪ϵͳһ���ɶ��ִ��������,��lidar��carmera��radar�ȵȡ�������˹�����ڴ��Ӿ����������и�֪֮��,������о��������ö��ִ������ں�������ϵͳ,����lidar��camera���ں��о��Ƚ϶ࡣ
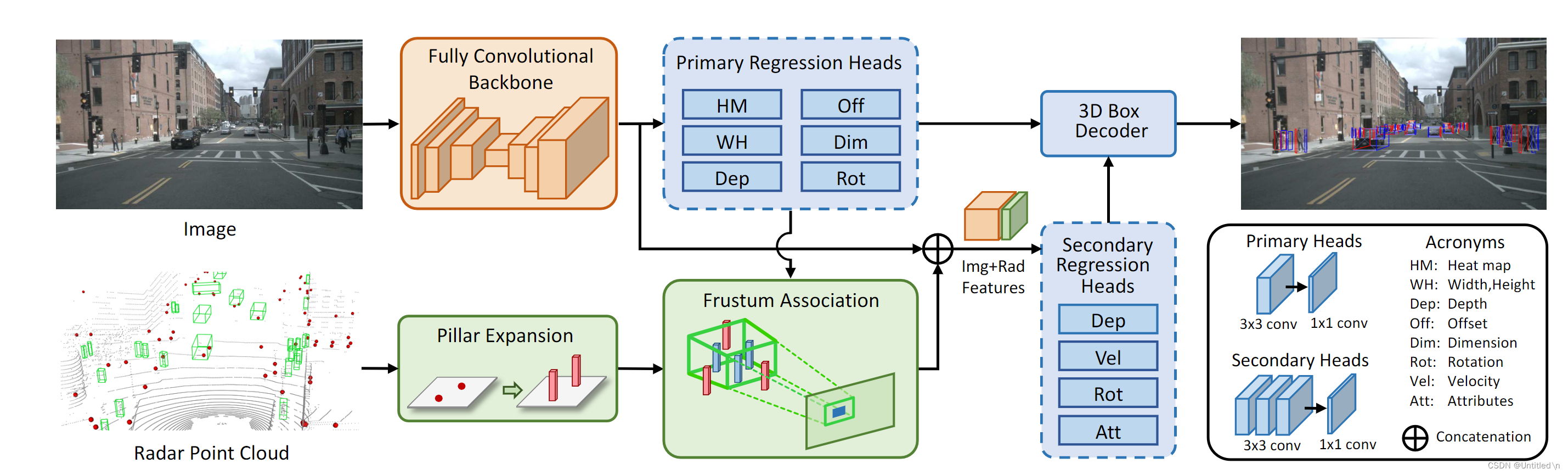
CenterFusion��ƪ���»���nuscenes���ݼ��о�camera��radar���������ں�,ͼ�ֲ��õ���CenterNet,radar���Ʋ��ֲ�����pillar expansion��ͨ��roi frustum����ͼ�����box����ƥ��,radar������ȡ��CenterNet����,����radar���Ƶ�vx��vy�Լ�depth�ֱ�heatmap����ͼ����������ƴ��������ںϡ��ٷ�����ֿ�����
����˼·���ǽ��״����Ͷ�䵽ͼ��������,���������ͨ��ƴ��,�����þ���������лع顣����Ϊ������,Primary Regression Heads�Ľ�����������,���������е������ݺ�box��ƥ��;Secondary Regression Heads����ƴ�����״�����,��������Primary Regression Heads��Ԥ����,ͬʱ�����������Ϣ,Ŀ���ٶȺ����Եȵȡ�
��Ҫ�������������:
| ���� | ���� |
|---|---|
| ���ײ��״���������кܶ��Ӳ�,����ʵ���徭����һ�Զ�Ĺ�ϵ,������ͼ��box����ƥ�� | ����3D���������˺�ɸѡ����,�ӿ�ƥ���ٶ�,ͬʱ������Ч�ĵ��� |
| һ��ĺ��ײ��״��������û�и߶���Ϣ,����ȷ��ͼ���е�box����ƥ�� | Pillar Expansion, ��������Ϊ3D pillar,����ƥ����� |
| ���ײ��״�������ݷdz�ϡ��,�����ڱ���������,�����������е�Ȩ�ؽϵ� | ������֮ƥ���box�������״���Ƹ��Ƿ�Χ,��һ����ת���һС���������,��ȡ����headmap��Ϊ�������� |
-
ͼƬ������ȡ��Primary Regression
����CenterNet��Head,����ȫ����backbone����������ȡ��ʱ��,����һ�������Ļع�,�õ�Ŀ���2D Box ��3D Box -
�״���ƺ�2Dͼ��Ŀ��ƥ��
-
3D ����
����Primary Regression Heads�õ���ÿ��3D Box�����depth���۲��alpha��3D��ߴ�dim,�ټ�������궨����������3D����(ÿ�����ܵ�Box������һ��),����Roi��ȡ,�ӿ�ƥ���ٶȵ�ͬʱ,������Ч�ĵ��ơ��۲�Ǻͱ궨������Ϊ�˼���yaw��
-
�״����Pillar Expansion
�״����û�и߶���Ϣ,����������Ϊ�̶���С��3D����,�������ƥ��ĸ���(����õ��ʾĿ����,�����ӱ�ʾ�ܹ�������3D�ռ��е����,��������ƥ��ĸ���) -
����ƥ��
pillarͶӰ��pixel����ϵ��2D box����ƥ��; pillarͶӰ���������ϵ�빹���3D����������ֵƥ��
-
-
�״����������ȡ
����ÿһ��������������״�Ŀ��,����ͼ����2D�����λ����������headmap,����heatmap concat��ͼƬ����������Ϊ����ͨ��,��������ں� -
�����ں���������Secondary Regression
���˹���Ŀ���ٶ�֮��,�����¹�����Ŀ�����ȺͽǶ�(������״�����,���Ƹ���ȷ) -
3D Box Decoder
�ۺ�Primary��Secondary Regression Heads�����,��ԭ��3DĿ������(λ�á���С����̬���ٶ�,�Լ���������),����dep��rot������heads�ﶼ��,��ֻ����ȷ�ȸ��ߵ�second regression heads
����֪ʶ
���û���˽���������,������˳������,CenterFusion��Ĵִ��붼��������CornerNet��CenterNet
- 3DĿ�������֪ʶ
- CornerNet:Ŀ�����㷨��˼·
- �ӵ�anchor!������CenterNet����Objects as Points���Ľ��
- CenterTrack��Ƚ���
�ص�����
����ṹ
Backbone������CenterNet��DLA-34, �����ɱ��ξ���DeformConv���롣��������ṹ���ݿɲο�CenterFusion(����CenterNet)Դ����Ƚ��: :DLA34
�״���ƺ�2Dͼ��Ŀ��ƥ��
��������ƥ��

-
3D������С��ƥ�䷶Χ,�����ӿ�ƥ���ٶ�
-
�����ֱ�ӽ��״����Ͷ�䵽2Dͼ��,3D���ܹ�����2Dͼ�����ص����ڵ���Ŀ��
-
ʹ�ò��� �� \delta �������� ROI ����Ĵ�С,����Ϊ�˽�����Ƶ����ֵ�IJ�ȷ��,��ΪROI��ƥ��ʱ,ʹ�õ����ֵ d ^ \hat{d} d^��ͨ��ͼ���������Ƴ����ġ����������С��Ŀ����Ϊ�˾����ܵĸ�ÿһ��box�ҵ�����һ���״������ƥ��,��ʹƥ�䵽�������,����ֱ��ȡ�����С�ĵ��������box�ڵĵ���ȥ�ء�����ΪBEV�ӽ�ʾ��ͼ

ֻ��infer���ò�����,ʵ�ʵ��ڵ����������ȷ�Χ, ���Ӵ˲�����Ŀ�ĸ����ǽ���©���ʡ�
��������
frustumExpansionRatio����ʾ���ڲ���,�����������ȷ�Χ����õ�һ��dist_thresh,
���� �� = d i s t _ t h r e s h ? f r u s t u m E x p a n s i o n R a t i o n \delta = dist\_thresh * frustumExpansionRation ��=dist_thresh?frustumExpansionRation, d ^ \hat{d} d^��primary head�����3D box depth��GT depth�� ͼ����ɫ�����Ǿ������ڵ��������ֵ��Χ,���ֵ�ڴ˷�Χ�ڵ��״����,�������Ӧ��boxƥ�䡣����roi frustum��dist_thresh�����������:# ��ÿһ��3D box,����roi frustum��8���ǵ�, roi frustumΪ3D box�İ�Χ��, # ��roi frustum��pixel����ϵ�µ�ͶӰΪ2D box def comput_corners_3d(dim, rotation_y): # dim: 3 # location: 3 # rotation_y: 1 # return: 8 x 3 c, s = torch.cos(rotation_y), torch.sin(rotation_y) # dim��ȫ������ϵ�µij�����,��������Ҳ��ȫ������ϵ�µ�3D box��8���ǵ� # �Զ���ʻ�����ڵ�������ʻ,һ��ֻ����ƫ����,����rotation_y������ת���� R = torch.tensor([[c, 0, s], [0, 1, 0], [-s, 0, c]], dtype=torch.float32) l, w, h = dim[2], dim[1], dim[0] x_corners = [l/2, l/2, -l/2, -l/2, l/2, l/2, -l/2, -l/2] y_corners = [0, 0, 0, 0, -h, -h, -h, -h] z_corners = [w/2, -w/2, -w/2, w/2, w/2, -w/2, -w/2, w/2] corners = torch.tensor( [x_corners, y_corners, z_corners], dtype=torch.float32) # ȫ�������µ�3D box��8���ǵ������ת����,�õ�roi frustum��8���ǵ�, # ��Ӧ��roi frustum��pixel����ϵ�µ�ͶӰ,�պ�Ϊ2D box corners_3d = torch.mm(R, corners).transpose(1, 0) return corners_3d def get_dist_thresh(calib, ct, dim, alpha): rotation_y = alpha2rot_y(alpha, ct[0], calib[0, 2], calib[0, 0]) corners_3d = comput_corners_3d(dim, rotation_y) dist_thresh = max(corners_3d[:, 2]) - min(corners_3d[:, 2]) / 2.0 return dist_thresh
�״����Ŀ���ͼ��2DĿ��һ���Ƕ��һ�Ĺ�ϵ,����������ж���״����,��ֻ���������С(�������)�ĵ���,����������״�������ݡ�ƥ��������:
-
top image: ���״��������Ϊ3D Pillar��ͶӰ��pixel����ϵ
-
middle image: ���ݵ��Ƶ����ֱ�ӽ�3D Pillar Ͷ�䵽2Dͼ����ȥ��ǰ
-
bottom image: ��ƥ���,ͬʱ���״���ƽ���������ȡ,������heatmap��Ͷ�䵽2Dͼ����ȥ�غ�

����ʹ�ò���������, TLNet��Frustum PointNet��anchor based��������������������anchor,��Ϊ���ܵ�anchor������ļ�����,2D������γɵ�3D�����Թ��˵����������ϵ�anchor��
 |  |
|---|---|
| TLNet | Frustum PointNet |
�״����������ȡ
��Ϊͼ���Ǿ���CenterNetת������heatmap,ͬʱ���״���ƺ�ͼ���е�BOX������һ��һ��ƥ��,Ϊ�˽�ͼ�����ݺ��״�������ݸ��õ��ں�,���Ľ��״��������ת��Ϊheatmap,������ͨ����ƴ��(concat)������ںϡ�
����Ϊ,���������ݵ���ȡ��ٶ�x����,�ٶ�y������Ϊ����ͨ������ÿһ�����״����ƥ���2D Box,��2D Box�ڲ��ֱ�������ͨ��ֵ���һ��Box(�ݳ�Ϊ�μ�Box),�μ�Box��������ԭʼ2D Box�������غ�,��С��ԭʼBox�ɱ���, ����ͨ�� �� \alpha ����������
ע: �״�������ٶ��Ǿ����ٶ�
F x , y , i j = 1 M i { f i �O x ? c x j �O �� �� w j ?and? �O y ? c y i �O �� �� h j 0 ?otherwise? , F_{x, y, i}^{j}=\frac{1}{M_{i}}\left\{\begin{array}{ll} f_{i} & \left|x-c_{x}^{j}\right| \leq \alpha w^{j} \quad \text { and } \\ & \left|y-c_{y}^{i}\right| \leq \alpha h^{j} \\ 0 & \text { otherwise } \end{array},\right. Fx,y,ij?=Mi?1?? ? ??fi?0? ?x?cxj? ?����wj?and? ?y?cyi? ?����hj?otherwise??,
����ͨ���ֱ�Ϊ ( d , v x v y ) \left(d, v_{x}\right. \left.v_{y}\right) (d,vx?vy?),����i���״������ͼͨ��,�� i �� 1 , 2 , 3 i\in 1,2,3 i��1,2,3, M i M_{i} Mi?��ÿ��ͨ���Ĺ�һ������, c x j , c y j c_{x}^{j}, c_{y}^{j} cxj?,cyj?����֮ƥ��ĵ� j j j��2D box����������, w j , h j w^{j}, h^{j} wj,hj�ǵ� j j j��2D box�Ŀ���, �� \alpha ����һ��������,���ڿ��ƴμ�Box�Ĵ�С��
����heatmap�ķֲ���CenterNet��Щ����,CenterNet��heatmap�������ĵ��ȡֵ���ɵĸ�˹�ֲ�,������heatmap����2D box���ĵ�����һ���ɱ�����С��Box,Box��ȡֵ��ͬ,Box��ȡֵΪ0��
����
Ŀ��Ƕ�in-bin regression
��������ѧϰ�Ķ�֪��,��һ����Ҫ�IJ��������������,ij����������ֱ����ϻ����Ч������ʱ,��Ҫ����һЩencoding����Ϊֱ�ӻع�Ƕȱ����е�����,�����ȴ����ж�λ���ĸ��Ƕ�����,Ȼ���������ڽ���offset�ع�
�����в�ֱ�ӻع�۲�� �� \alpha ��,���ǽ� �� \alpha ��ȡֵ��Χ����Ϊ����bins: [ ? 7 p i 6 , p i 6 ] , [ ? p i 6 , 7 p i 6 ] [\frac{-7pi}{6}, \frac{pi}{6}], [\frac{-pi}{6}, \frac{7pi}{6}] [6?7pi?,6pi?],[6?pi?,67pi?]��ÿ��bin����4������,ά�Ⱥϼ�Ϊ8������һ��bin,����ֵ����softmax����,��������ֵ��ÿ��bin�еĽǶ���ֵ��offset���лع顣������ʵ��������CenterNet�ĽǶȻع鷽ʽ����������:
def _add_rot(self, ret, ann, k, gt_det):
if 'alpha' in ann:
ret['rot_mask'][k] = 1
alpha = ann['alpha']
if alpha < np.pi / 6. or alpha > 5 * np.pi / 6.:
ret['rotbin'][k, 0] = 1
ret['rotres'][k, 0] = alpha - (-0.5 * np.pi)
if alpha > -np.pi / 6. or alpha < -5 * np.pi / 6.:
ret['rotbin'][k, 1] = 1
ret['rotres'][k, 1] = alpha - (0.5 * np.pi)
gt_det['rot'].append(self._alpha_to_8(ann['alpha']))
else:
gt_det['rot'].append(self._alpha_to_8(0))
def _alpha_to_8(self, alpha):
ret = [0, 0, 0, 1, 0, 0, 0, 1]
if alpha < np.pi / 6. or alpha > 5 * np.pi / 6.:
r = alpha - (-0.5 * np.pi)
ret[1] = 1
ret[2], ret[3] = np.sin(r), np.cos(r)
if alpha > -np.pi / 6. or alpha < -5 * np.pi / 6.:
r = alpha - (0.5 * np.pi)
ret[5] = 1
ret[6], ret[7] = np.sin(r), np.cos(r)
return ret
CentNet���ĵĸ�¼��������ϸ��ʽ,,Loss��Ϊ������:ǰ�벿����softmax����,�жϽǶ�λ���ĸ�bin,��ʧ����Ϊcross entropy ;��벿�ع�Ƕȹ��ڶ�Ӧbin����ȡֵ(���ǽǶ�ƽ��ֵ)��offset,��offsetȡ���һ�����ֵ��Ϊ�ǶȲв�,��������ǶȲв�GT��L1 loss
L
ori?
=
1
N
��
k
=
1
N
��
i
=
1
2
(
softmax
?
(
b
^
i
,
c
i
)
+
c
i
�O
a
^
i
?
a
i
�O
)
L_{\text {ori }}=\frac{1}{N} \sum_{k=1}^{N} \sum_{i=1}^{2}\left(\operatorname{softmax}\left(\hat{b}_{i}, c_{i}\right)+c_{i}\left|\hat{a}_{i}-a_{i}\right|\right)
Lori??=N1?k=1��N?i=1��2?(softmax(b^i?,ci?)+ci?�Oa^i??ai?�O)
����
c
i
=
1
(
��
��
B
i
)
,
a
i
=
(
sin
?
(
��
?
m
i
)
,
cos
?
(
��
?
m
i
)
)
c_{i}=\mathbb{1}\left(\theta \in B_{i}\right), a_{i}=\left(\sin \left(\theta-m_{i}\right), \cos \left(\theta-m_{i}\right)\right)
ci?=1(����Bi?),ai?=(sin(��?mi?),cos(��?mi?)), $ \hat{b}_{i}$��groud truth, ��ʾ�ýǶ����ڵڼ���bin,
m
i
m_{i}
mi?Ϊ��i��bin������ȡֵ��
�۲�ǿ���ͨ������Ĺ�ʽ�õ�,
j
j
j��classfication score�ϴ���Ǹ�bin��index����ͨ���Ƕ�����bin����ֵ,����һ�����Ǻ���offset,�õ��۲�Ƕȡ�
��
^
=
arctan
?
2
(
a
^
j
1
,
a
^
j
2
)
+
m
j
\hat{\theta}=\arctan 2\left(\hat{a}_{j 1}, \hat{a}_{j 2}\right)+m_{j}
��^=arctan2(a^j1?,a^j2?)+mj?
�����н��ǶȰ�Ԫ���ʾΪrot, ����ʱ��ת���ɹ۲��alpha�ͺ����yaw(�ֳ�rotaition_y)
def get_alpha(rot):
# rot: (B, 8) [bin1_cls[0], bin1_cls[1], bin1_sin, bin1_cos,
# bin2_cls[0], bin2_cls[1], bin2_sin, bin2_cos]
# return alpha[B, 0]
idx = rot[:, 1] > rot[:, 5]
alpha1 = torch.atan2(rot[:, 2], rot[:, 3]) + (-0.5 * 3.14159)
alpha2 = torch.atan2(rot[:, 6], rot[:, 7]) + (0.5 * 3.14159)
# return alpha1 * idx + alpha2 * (~idx)
alpha = alpha1 * idx.float() + alpha2 * (~idx).float()
return alpha
def alpha2rot_y(alpha, x, cx, fx):
"""
Get rotation_y by alpha + theta - 180
alpha : Observation angle of object, ranging [-pi..pi]
x : Object center x to the camera center (x-W/2), in pixels
rotation_y : Rotation ry around Y-axis in camera coordinates [-pi..pi]
"""
rot_y = alpha + np.arctan2(x - cx, fx)
if rot_y > np.pi:
rot_y -= 2 * np.pi
if rot_y < -np.pi:
rot_y += 2 * np.pi
return rot_y
Ϊʲô�������нǶȹ���
������ϵ��ǹ۲��alpha����ر���,�����Ҫͨ������ڲ�ת��Ϊ�����,��ôΪʲô��ֱ����Ϻ������?
��Ϊ��������������������ϵ��,���۲����������������ϵ�ġ�����������ϵ��ǹ۲��,��������������Ǻ���ǡ��������ԭ��֮��,Bounding box estimation using deep learning and geometry. In CVPR, 2017
��4.1��ָ��:��ͨ��Ŀ���ͼ�������ȫ��ƫ�����Dz����ܵ�,�������MultiBin Orientation Estimation,CenNetϵ�����ľ��ο��˴������
����ͼ���Կ���,Ŀ���ƫ���DZ��̶ֹ��������,����λ�Ƶĸı�,��ֲ�ͼ���Ͽ��ƺ���������ת,������ԽǶȷ����˱仯��"����ȥ"������������תһ�����������Զ���CNN���Լ��䲻��,��Ϊ�������ȫ��ƫ������Ϊground truth,CNN��Ҫ������ȥת�Dz�ͬ��ͼ��ӳ�䵽ͬһ������,�����һ���,����ȫ��ѵ����ȷ�Ľ����
 |  |
|---|
������IJ��þֲ���Խ�(Ŀ�곯������������)����ΪGT,��ͨ������ͼ�е� �� l \theta_{l} ��l?,��ͨ�����ι�ϵ��ӵõ�ȫ��ƫ����,ͼ��Ϊ �� \theta ������� �� l \theta_{l} ��l?,������MultiBin Orientation Estimation����,���ǶȻ���Ϊ��������,Ԥ�������ĸ�����,�Լ���������offset��CenterNetϵ����������ǹ۲�� �� \alpha ���ı���, �� \alpha ��������� �� l \theta_{l} ��l?���ڼ��ι�ϵ
��ģ̬����ʱ�����
ÿ�ִ����������Լ������ݲɼ�Ƶ��,��Ҫ����ͬ�������ڲ�ͬʱ����������ݽ��ж��롣
nuscenes���ݼ��Ѿ�ͨ���궨���ݽ�radar���ƺ�����ͼƬ����ʱ�����,ʵ�ʹ�������Ҫ�Լ������һ��Ҫ���衣���б�Ҫ,����Ҫ���е�radar�����ݵ���,����radar���Ƶij��ܶ�